Linux系统安装hadoop3.1.3实现全分布式
工具
Linux系统:CentOS,版本7.0以上
JDK:jdk1.8,1.8版本还分为不同的版本,但必须使用1.8版本的(注意:官网下载Linux版本的jdk)
Hadoop:hadoop3.1.3,使用3.0版本以上的应该都没有问题,2.0以上的版本配置可能会有点不相同
虚拟机:VMware workstations,即使是物理机安装Linux也可以
JDK安装
默认你虚拟机安装好了Linux系统
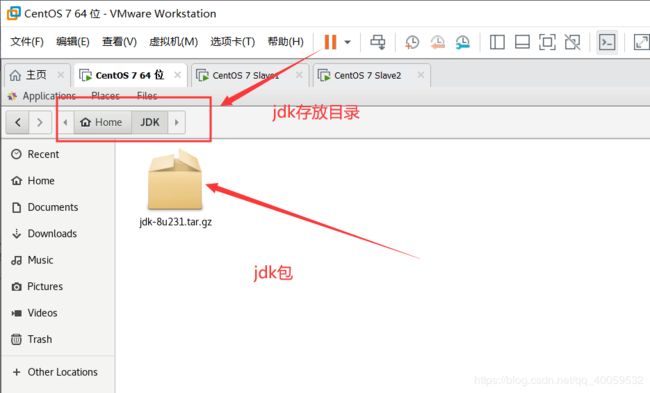
第一步:下载好jdk,在Linux系统上新建一个JDK文件夹,把jdk放到该文件夹里面。(这里是为了方便所以把压缩包放这里,后面jdk安装的真实路径不在这里,你也可以安装在这里,按照你的需求修改路径就行)
注意:
1、下载的jdk是一个.tar.gz压缩包,我们在Linux系统上进行解压,不用在window上解压(window上解压再放到Linux不知道行不行,应该没问题吧)
2、我的版本的Linux系统可以直接将window上的复制的东西放到Linux上,下载的版本不同可能会不支持该功能(可以通过其他软件将文件 上传的Linux,如Xshell-6+FTP)
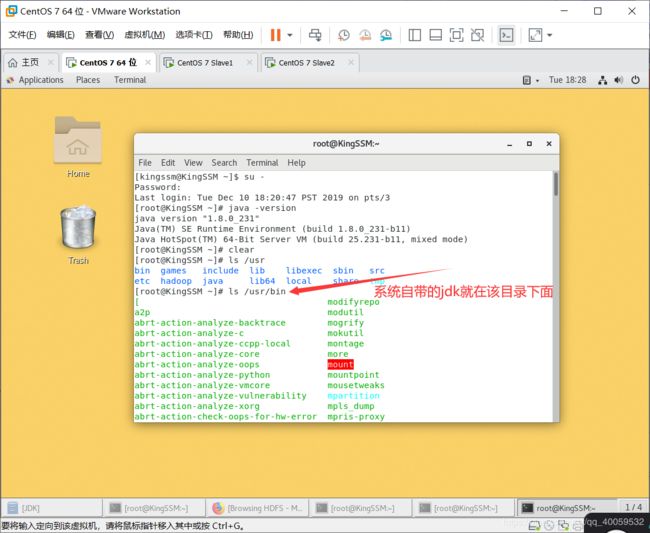
第二步:安装jdk。Linux系统自带了jdk(我的自带了两个jdk版本,1.7和1.8),打开控制台,输入java -version可以看到Linux自带的jdk版本,建议使用root权限输入命令,后面对于配置文件的修改需要获得root权限。

如果想要用系统自带的jdk也可以,不过你需要知道它的安装路径(注意一下蓝色的字,其中的java是自己创建的,后面安装jdk就安装在该目录下)

在java文件里面才可以看到jdk,这里被我删了进不去
安装步骤:
1、解压文件:进入jdk压缩包的目录,在该目录下打开终端,输入解压命令tar -zvxf jdk-8u231.tar.gz,这样就会把解压后的文件放在该目录下面,如果是在桌面打开的终端,那你想把解压后的文件放到该目录下,你就需要在压缩包后面添加路径,如tar -zvxf jdk-8u231.tar.gz /home/kingssm/JDK/,注意:kingssm是我的用户名,在home目录下面隐藏着以用户名为目录的目录,我们打开home就可以看到JDK,事实上home和JDK之间还有一层目录。

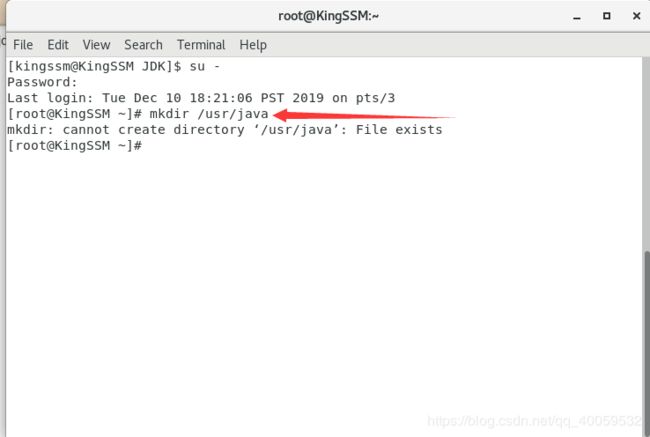
2、把jdk放到安装目录。如果你想把jdk直接安装在上一步中的目录,那么这一步就不用操作了。在/usr目录下面创建java文件夹,要把jdk放到该文件夹中,我的文件夹已经存在了,所以没有创建成功
把上面得到的解压包放到该文件夹下面,有两种方法:一是复制一份到该文件夹,二是把它移动到该文件夹。在终端输入命令即可
复制:cp -rf /home/kingssm/JDK/jdk1.8.0_231 /usr/java/
移动:mv /home/kingssm/JDK/jdk1.8.0_231 /usr/java
3、配置系统环境。终端输入命令(以root权限进去)vi ~/.bash_profile,然后会打开一个文件,按i就可以对该文件进行编辑,编辑结束后先按esc键,然后输入==:wq==即可保存退出。需要添加下面的配置代码(注意jdk安装路径):
export JAVA_HOME=/usr/java/jdk1.8.0_221
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
如下:

4、替换原来的jdk。目前配置已经是完成了,你可以在终端输入java -version,查看是不是新安装的jdk版本。如果是,那这一步也不用操作了;如果不是(一般都不是(二班表示也不是(三班表示也不是(四班还是表示也不是(五班总结以下六点…)))))那我们就需要替换掉原来的jdk,把原来的删掉,链接到我们的jdk。终端输入以下代码:
rm -rf /usr/bin/java
rm -rf /usr/bin/javac
ln -s $JAVA_HOME/bin/javac /usr/bin/javac
ln -s $JAVA_HOME/bin/javac /usr/bin/java
自此,jdk安装完成!!!
(小总结:jdk的安装主要就是在配置上,前面的路径只是为了方便、规范而已,只要知道jdk放在哪里,那把配置文件中JAVA_HOME的路径写对那就不会有问题)
Hadoop安装
安装步骤和jdk的完全一样,为了方便也可以像我一样在、/usr/下面建立一个hadoop文件夹,然后把下载解压的hadoop放到该文件夹下面。最主要的也还是配置文件,如果配置文件里面的路径正确那就可以。配置代码如下:
export HADOOP_HOME=/usr/hadoop/hadoop-3.1.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
安装完之后可以在终端输入hadoop命令查看:

------------------------------------------------jdk和hadoop安装完成-----------------------------------------------
Hadoop全分布式配置
在配置之前先创建几个文件:
终端输入mkdir /usr/hadoop/hadoop-3.1.3/tmp创建tmp文件夹
终端输入mkdir /usr/hadoop/hadoop-3.1.3/data/namenode创建namenode文件夹
终端输入mkdir /usr/hadoop/hadoop-3.1.3/data/datanode创建datanode文件夹
在终端输入cd /usr/hadoop/hadoop-3.1.3/etc/hadoop/ 注意自己的路径,后面需要修改的文件都在这个目录下面,这里先进入该目录
配置core-site.xml:输入vi core-site.xml 打开文件后添加
(全分布式中我使用三台虚拟机,KingSSM是我的主机名,还有两台分别是Slave1和Slave2)
fs.defaultFS
hdfs://KingSSM:9000
hadoop.tmp.dir
/usr/hadoop/hadoop-3.1.3/tmp
配置hdfs-site.xml:输入vi hdfs-site.xml 打开文件后添加
dfs.replication
1
dfs.namenode.name.dir
/usr/hadoop/hadoop-3.1.3/data/namenode
dfs.datanode.data.dir
/usr/hadoop/hadoop-3.1.3/data/datanode
dfs.permissions
false
配置mapred.site.xml:输入vi mapred-site.xml 打开文件后添加
mapreduce.framework.name
yarn
mapred.job.tracker
KingSSM:9001
配置yarn-site.xml:输入yarn-site.xml打开文件后添加
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
KingSSM
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
配置hadoop-env.sh:输入vi hadoop-env.sh 打开文件后添加
(这一步可能不是必须的,可以先不配置,如果后面无法运行再配置)
export JAVA_HOME=/usr/java/jdk1.8.0_231
export HADOOP_HOME=/usr/hadoop/hadoop-3.1.3
export PATH=$PATH:/usr/hadoop/hadoop-3.1.3/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/usr/hadoop/hadoop-3.1.3/pids
配置yarn-env.sh:输入vi yarn-env.sh 打开文件后添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
配置workers:输入vi workers 打开文件后添加,这里换成你的主机名和IP地址(KingSSM是当前正在操作的虚拟机主机名,其他两个是等下要克隆的两台虚拟机的主机名,IP地址要在虚拟机中修改)

在终端输入cd /usr/hadoop/hadoop-3.1.3/sbin/ 进入新的目录
配置start-dfs.sh:输入vi start-dfs.sh打开文件后添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置stop-dfs.sh:输入vi stop-dfs.sh打开文件后添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
---------------------------------------------到这里Hadoop的配置算是完成了----------------------------------------------
配置虚拟机
关闭防火墙
一般都会有防火墙,如果没有那就不用关闭了。重新打开一个终端,输入下面的命令:
systemctl stop firewalld.service //临时关闭
systemctl disable firewalld.service //设置开机不自启
修改主机名
查看主机名:终端输入hostname
修改主机名:终端输入hostnamectl --static set-hostname KingSSM
设置静态IP
终端输入ip route查看网关

输入vi /etc/sysconfig/network-scripts/ifcfg-ens33修改文件:修改或添加下面的内容,IP地址自己选择,但是注意要和网关对应,如网关是192.168.33.2,那IP地址前面就得是192.168.33,后面那部分自己随意,NDS1和网关一样,子网掩码是255.255.255.0

添加虚拟机之间的映射
终端输入vi /etc/hosts,添加

SSH免密登录
终端输入ssh-keygen -t rsa 然后一直回车;
等可以再次输入时输入下面命令将公钥发布出去:
ssh-copy-id KingSSM
ssh-copy-id Slave1
ssh-copy-id Slave2
--------------------------------------------到这里虚拟机的配置也完成了--------------------------------------------
克隆虚拟机
把当前正在使用的KingSSM虚拟机关闭,然后克隆两台虚拟机。
点击虚拟机------>右键------>管理------>克隆------>完全克隆
等克隆完之后,三台虚拟机都打开,然后对克隆出来的两台分别设置主机名Slave1和Slave2,并修改IP地址
启动集群
三台虚拟机都需要先格式化
打开终端,以root身份操作,三台都要输入hadoop namenode -format进行格式化
格式化完成后,在KingSSM中启动集群,输入start-all.sh启动集群,(如果关闭,输入stop-all.sh)
启动完后输入jps查看启动状态,KingSSM和Slave应该有以下信息


访问网页查看结果:KingSSM:9870

访问网页查看结果:KingSSM:8088

能访问这两个地址说明成功
参考文章:https://www.zhangshengrong.com/p/zAaOK6Z3ad/
下一篇文章会介绍怎么使用hadoop