大数据学习三之伪分布式集群安装部署
大数据学习三之 伪分布式集群安装部署
ip:168.192.59.200
hostname:bigdata-lmt02.hpsk.com
我的环境搭建是基于前两篇博客的基础之上的:
大数据学习一Linux基础配置
大数据学习二HADOOP框架安装部署
在搭建HADOOP环境之前先准备好hadoop-2.7.3.tar.gz安装包
Apache Software Foundation Distribution Directory
http://archive.apache.org/dist/
hadoop-2.7.3
http://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/
在上一篇博客中我们规划了目录结构
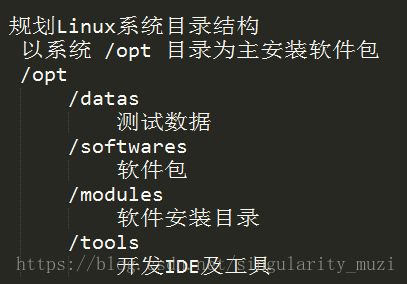
在这里我们将准备好的hadoop-2.7.3.tar.gz安装包上传到/opt/softwares/目录下:
上传后解压(使用rz上传文件的前提是安装了Linux系统自带上传下载软件$ sudo yum install -y lrzsz)
$ rz
$ chmod u+x hadoop-2.7.3.tar.gz
$ tar -zxf hadoop-2.7.3.tar.gz -C /opt/modules/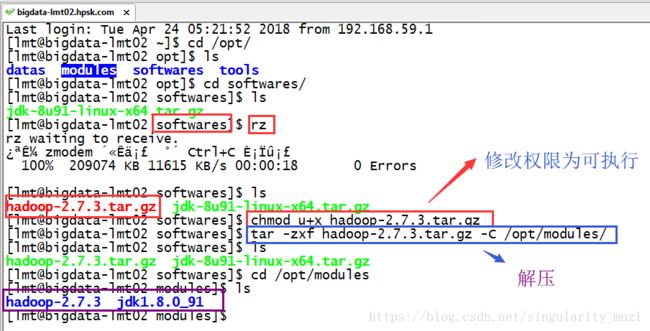
配置HADOOP
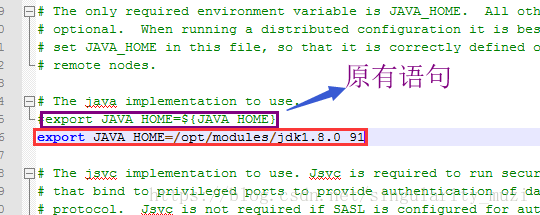
配置 *-env.sh 环境变量文件
hadoop-env.sh ; yarn-env.sh ; mapred-env.sh
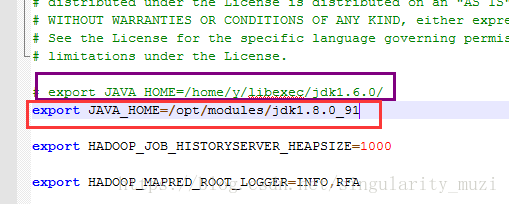
设置值:export JAVA_HOME=/opt/modules/jdk1.8.0_91
hadoop-env.sh
yarn-env.sh
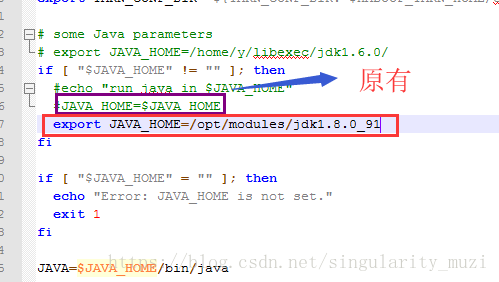
mapred-env.sh
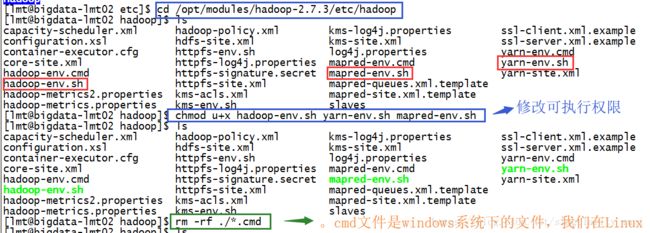
赋以执行权限: $ chmod u+x hadoop-env.sh yarn-env.sh mapred-env.sh
依据HADOOP三个模块来进行配置
- HDFS
存储数据
- YARN
管理资源
- MapReduce
分析数据
配置HDFS环境
core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://bigdata-lmt02.hpsk.com:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/modules/hadoop-2.7.3/data/tmpDatavalue>
property>
创建对应文件夹:
$ cd /opt/modules/hadoop-2.7.3
$ mkdir -p data/tmpData修改配置文件hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>1value>
property>配置slaves文件:指定DataNode运行在哪些机器上,此文件中一行表示一个主机名称,会在此主机上运行DataNode

启动HDFS服务
对于文件系统来说,第一次使用,要进行格式文件系统(注意:系统格式化只能进行一次,在之后的使用中就不能再次格式化了,否则会出现问题)
$ cd /opt/modules/hadoop-2.7.3
$ bin/hdfs namenode -format启动服务
主节点:
$ sbin/hadoop-daemon.sh start namenode 从节点:
$ sbin/hadoop-daemon.sh start datanode
- 验证:
方式一:查看进程
$ jps 方式二:通过WEB UI界面查看,浏览器出现如下界面即为配置成功。
http://hostname:50070

测试HDFS
查看帮助文档
$ bin/hdfs dfs创建目录
$ bin/hdfs dfs -mkdir -p /datas/tmp 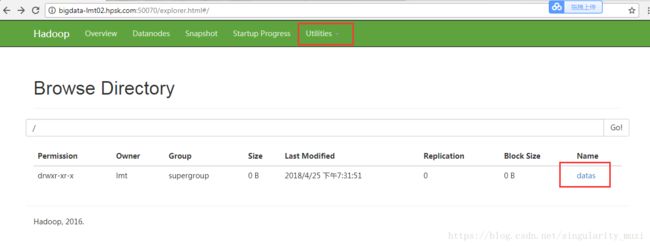
上传文件
$ bin/hdfs dfs -put etc/hadoop/core-site.xml /datas/tmp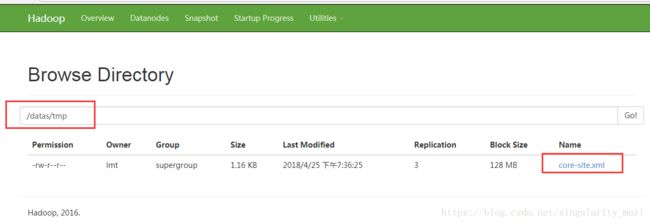
列举目录文件
$ bin/hdfs dfs -ls /datas/tmp 
查看文件的内容
$ bin/hdfs dfs -text /datas/tmp/core-site.xml
配置YARN集群
对于分布式资源管理和任务调度框架来说:
在YARN上面运行多种应用的程序
- MapReduce
并行数据处理框架
- Spark
基于内存分布式计算框架
- Storm/Flink
实时流式计算框架
- Tez
分析数据,速度MapReduce快
主节点:
ResourceManager
从节点:
NodeManagers
配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>bigdata-lmt02.hpsk.comvalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>配置slaves文件
指定NodeManager运行的主机名称,由于NM与DN同属一台机器,前面已经配置完成。
启动YARN服务
RM 主节点:
$ sbin/yarn-daemon.sh start resourcemanagerNM 从节点:
$ sbin/yarn-daemon.sh start nodemanager验证

查看所有与Java相关的进程
$ ps -ef|grep java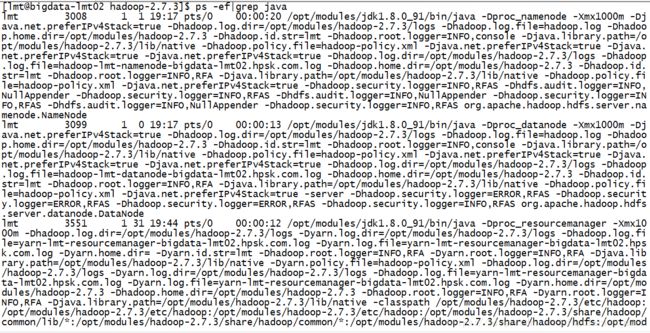
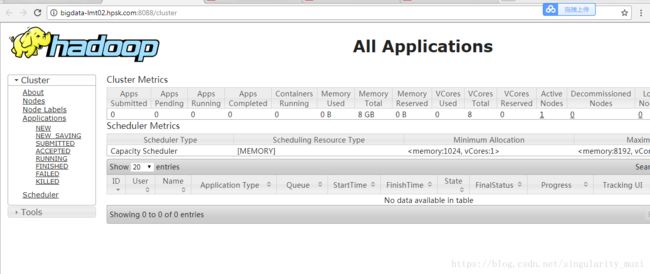
通过WEB UI界面查看
http://hostname:8088/cluster
运行MapReduce程序
并行计算框架(Hadoop 2.x)
思想:分而治之
核心:
Map: 分
并行处理数据,将数据分割,一部分一部分的处理
Reduce: 合
将Map处理的数据结果进行合并,包含一些业务逻辑在里面
大数据计算框架中经典案例:
词频统计(WordCount)
统计某个文件中单词的出现次数
配置MapReduce相关属性:
拷贝(.template的文件表示模板文件)
$ cp mapred-site.xml.template mapred-site.xml修改
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>提交MapReduce程序,到YARN上运行
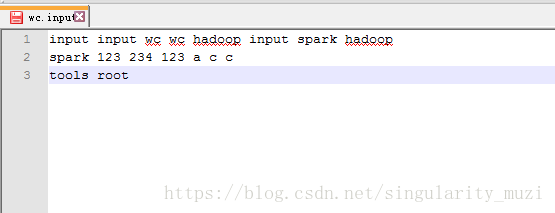
准备测试数据
创建放置待分析文件的input
$ bin/hdfs dfs -mkdir -p /user/huadian/mapreduce/wordcount/input下创建wc.input 文件,在里面输入任意的文本内容,将其提交到input目录中
$ bin/hdfs dfs -put /opt/datas/wc.input /user/huadian/mapreduce/wordcount/input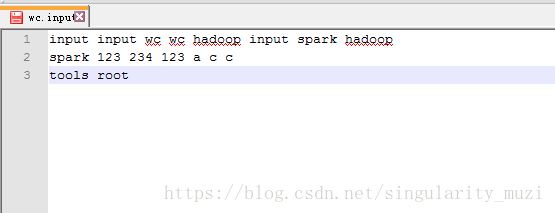

提交运行
官方自带MapReduce程序JAR包
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount <in> <out>参数说明:
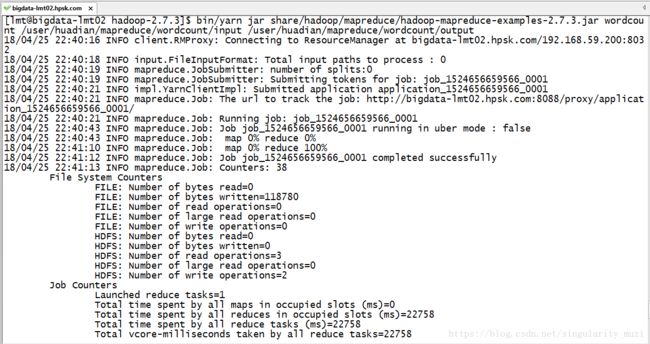
这里是测试信息
18/04/25 22:40:16 INFO client.RMProxy: Connecting to ResourceManager at bigdata-lmt02.hpsk.com/192.168.59.200:8032
18/04/25 22:40:18 INFO input.FileInputFormat: Total input paths to process : 0
18/04/25 22:40:19 INFO mapreduce.JobSubmitter: number of splits:0
18/04/25 22:40:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1524656659566_0001
18/04/25 22:40:21 INFO impl.YarnClientImpl: Submitted application application_1524656659566_0001
18/04/25 22:40:21 INFO mapreduce.Job: The url to track the job: http://bigdata-lmt02.hpsk.com:8088/proxy/application_1524656659566_0001/
18/04/25 22:40:21 INFO mapreduce.Job: Running job: job_1524656659566_0001
18/04/25 22:40:43 INFO mapreduce.Job: Job job_1524656659566_0001 running in uber mode : false
18/04/25 22:40:43 INFO mapreduce.Job: map 0% reduce 0%
18/04/25 22:41:10 INFO mapreduce.Job: map 0% reduce 100%
18/04/25 22:41:12 INFO mapreduce.Job: Job job_1524656659566_0001 completed successfully
18/04/25 22:41:13 INFO mapreduce.Job: Counters: 38
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=118780
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=0
HDFS: Number of read operations=3
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched reduce tasks=1
Total time spent by all maps in occupied slots (ms)=0
Total time spent by all reduces in occupied slots (ms)=22758
Total time spent by all reduce tasks (ms)=22758
Total vcore-milliseconds taken by all reduce tasks=22758
Total megabyte-milliseconds taken by all reduce tasks=23304192
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=0
Reduce shuffle bytes=0
Reduce input records=0
Reduce output records=0
Spilled Records=0
Shuffled Maps =0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=181
CPU time spent (ms)=1140
Physical memory (bytes) snapshot=152403968
Virtual memory (bytes) snapshot=2093871104
Total committed heap usage (bytes)=86507520
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=0我们可以通过浏览器查看分析结果
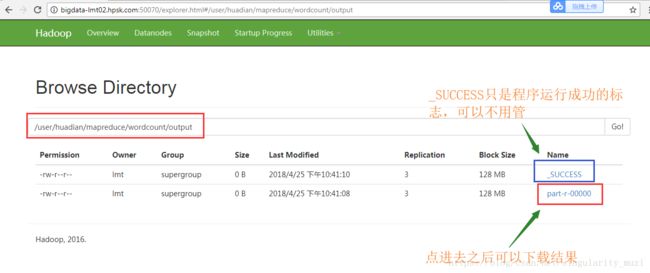
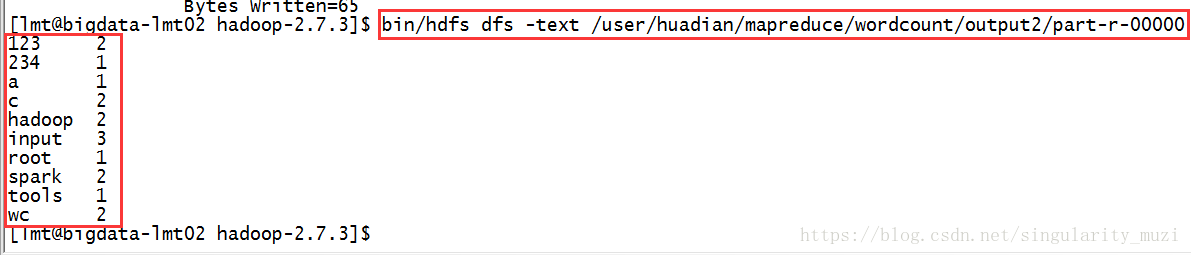
也可以下载分析结果
bin/hdfs dfs -text
启动HDFS服务或YARN服务,会产生日志文件
${HADOOP_HOME}/logs

配置MapReduce历史服务器MRHistoryServer
查看监控已经运行完成MapReduce作业执行情况

配置mapred-site.xml:
<property>
<name>mapreduce.jobhistory.addressname>
<value>bigdata-lmt02.hpsk.com:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>bigdata-lmt02.hpsk.com:19888value>
property>启动服务:
$ sbin/mr-jobhistory-daemon.sh start historyserver
Aggregation is not enabled
日志聚集功能:
当MapReduce程序在YARN上运行完成以后,将产生的日志文件上传到HDFS的目录中,以便后续监控查看
配置yarn-site.xml:
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>重启YARN和JobHistoryServer服务
为了重新读取配置属性
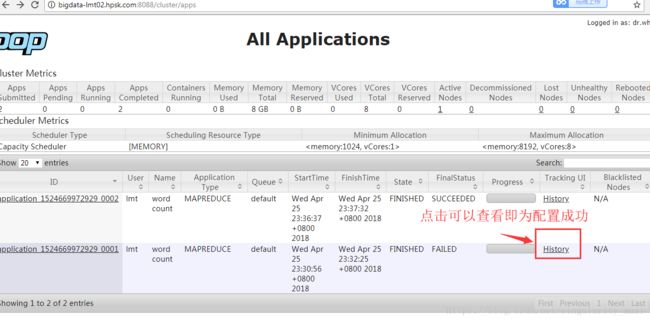
注意:重启YARN和JobHistoryServer服务后不会有进程信息,需要进行提交、运行才能查看History。