大数据学习五-Hadoop分布式环境部署
Hadoop分布式环境部署
一. Linux规划
准备三台虚拟机,ip、hostname分别为
192.168.59.223 bigdata-training02.hpsk.com
192.168.59.224 bigdata-training03.hpsk.com
192.168.59.225 bigdata-training04.hpsk.com
/etc/hosts配置

配置完成后重启网络服务
$ service network restart之后主机名、ip均可以互相ping通即为配置正确。下面就可以正式开始Hadoop分布式环境部署了。
Hadoop分布式环境部署要求每一台虚拟机的配置都一样,所以这里以一台虚拟机为例,不一样的地方再另作说明,安装部署好一台之后再将配置部署分发给另外两台即可。
二.分布式部署
- Linux环境配置
(1). ip、主机名、本地映射(/etc/hosts),DNS(按照前面规划进行配置)
(2). 关闭防火墙,selinux
(3)在Linux中创建统一的用户,统一的目录(我使用的huadian/huadian)
(4)修改句柄数
(5)ssh免密钥登
-每台机器为自己创建公私钥
$ cd /home/huadian/
$ ssh-keygen -t rsa 之后的提示一直“Enter”即可出现如下结果即为成功
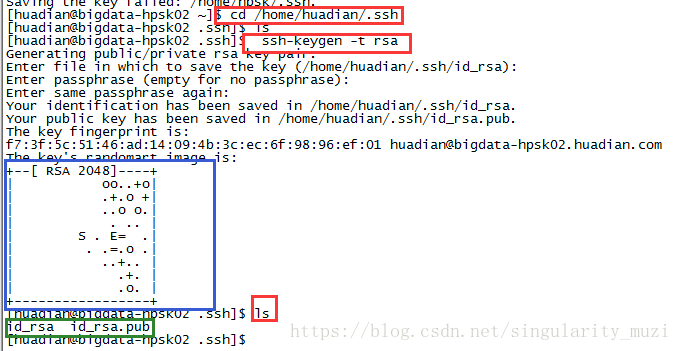
-将自己以及其他机器的公钥拿过来
$ ssh-copy-id bigdata-hpsk02.huadian.com
$ ssh-copy-id bigdata-hpsk03.huadian.com
$ ssh-copy-id bigdata-hpsk04.huadian.com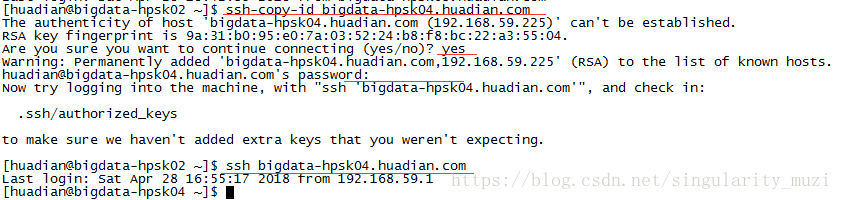
我这里是使用bigdata-hpsk02拿公钥,所以bigdata-hpsk02切换到其他机器时不需要密码了,而其他机器切换还需要密码,想要互切都免密,需要在另外的机器上也配置一遍。
2. NTP时间同步
通过ntp服务实现每台机器的 时间一致
实现时间同步的方式有多种
(1). 通过Linux crontab实现
(2).直接使用ntp服务同步外网时间服务器
(3).选择一台机器作为中间同步服务A,A与外网进行同步,B,C同步A
这里我选择的是(3)
配置bigdata-hpsk02.huadian.com sudo vim /etc/ntp.conf
删除默认配置:

添加
配置A允许哪些机器与我同步

配置A跟谁同步

配置本地同步
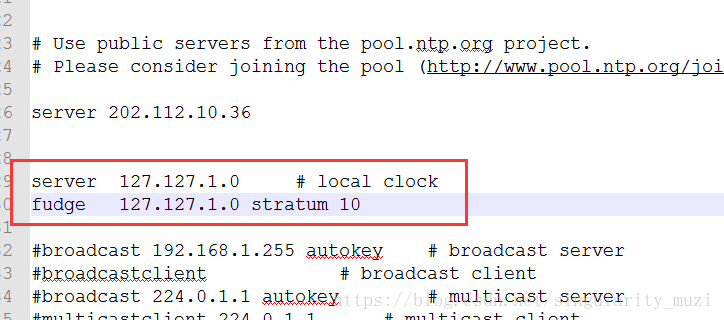
启动ntp服务
sudo service ntpd start配置B,C同步
sudo vim /etc/ntp.conf
server 192.168.59.223手动同步
sudo ntpdate 192.168.59.223开启ntp服务
sudo service ntpd start时间同步可能会比较慢,一段时间后可以使用查看是否成功(开始后可以不用管它,继续后续操作)

3. 部署Hadoop
(1)节点分布:
node1 datanode nodemanager namenode(工作)
node2 datanode nodemanager
node3 datanode nodemanager resourcemanager(工作)(2)安装jdk
Linux系统有自带的jdk但最好重新安装一下,关于jdk的卸载安装在前面的博客中有详细介绍,详情请参考
https://blog.csdn.net/singularity_muzi/article/details/80076015
我的jdk版本

(3)安装hadoop
- 下载解压安装(这一步在我前面的博客中有详细的过程,就不过多说明)
- 修改配置文件
首先,我们需要了解的是配置文件都有其不一样的功能,我们可以通过其后缀名进行简单的区分,知道了其配置功能就可以根据自己的需求找到对应文件进行配置。
-》env.sh:配置环境变量
-》site.xml:配置用户自定义需求
-》yarn-site:用于配置yarn的属性
-》slaves:配置所有从节点的 地址
下面开始修改配置文件
- env.sh-》配置JAVA_HOME,每个文件对应位置都会有“JAVA_HOME”关键字及模板格式的提醒,我们只需要找到对应位置修改或添加即可。
hadoop-env.sh
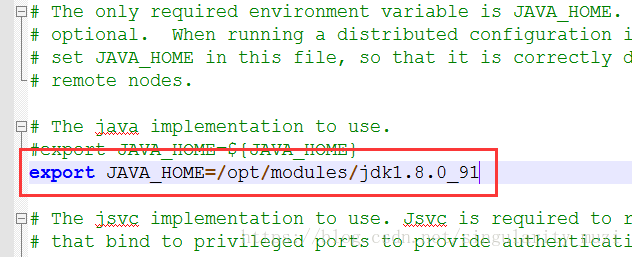
mapred-env.sh
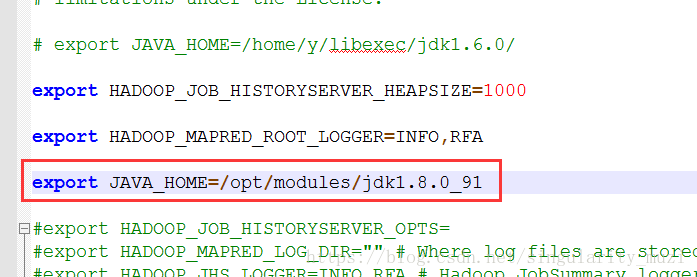
yarn-env.sh
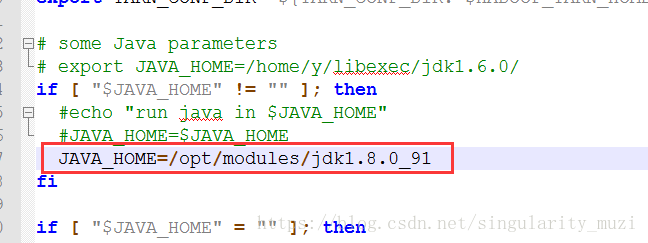
- site.xml:配置用户自定义需求
core-site:配hadoop全局的一些属性
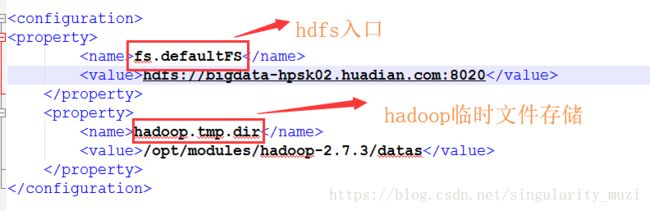
hdfs-site:配置hdfs的属性

mapred-site:用于配置MapReduce的属性
在配置mapred-site.xml的时候我们会发现系统中并没有这个文件,而是有一个mapred-site.xml.template文件,“.template”为后缀的文件是模板文件,我们只需要复制一个重命名或者直接重命名为xml文件即可。

yarn-site:用于配置yarn的属性

slaves:配置所有从节点的地址
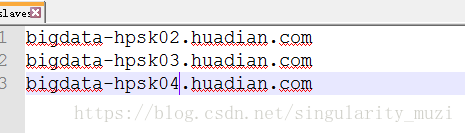
分发:不要忘掉
分发可以有两种方法:
1. 本机传给其他主机
scp -r hadoop-2.7.3 hpsk@bigdata-hpsk03.huadian.com:/opt/modules/
2. 其他主机到本机下载
scp -r hpsk@bigdata-hpsk04.huadian.com:/opt/modules/hadoop-2.7.3 /opt/modules/注意:我这里是将整个/opt/modules文件都传了过去,里面包括jdk和hadoop,而jdk的环境变量配置在每一台主机上都要进行一次。
启动测试
-格式化文件系统(重点强调,格式化只能在配置完成之后执行一次,之后就不要在重复执行了)
bin/hdfs namenode -format-启动对应的进程
1.hadoop的启动方式
(1).单个进程启动:用于启动
sbin/hadoop-daemon.sh start namenode(2)分别启动yarn和hdfs:用于关闭
sbin/start-dfs.sh
-》namenode
-》datanode
-》secondarynamenode
sbin/start-yarn.sh
-》resourcemanager
-》所有的nodemanager(3)一次性启动所有进程
sbin/start-all.sh