python 自动抓取分析房价数据——安居客版

引言
中秋回家,顺便想将家里闲置的房子卖出去。第一次卖房,没经验,于是决定委托给中介。中介要我定个价。最近几年,房价是涨了不少,但是长期在外,也不了解行情。真要定个价,心里还没个数。网上零零散散看了下,没有个系统的感知。心想,身为一代码农,为何要用这种低效的方式去了解房价。于是,就有了今天这篇专栏,也是继上篇《python 自动抓取分析文章阅读量——掘金专栏版》json 爬虫的一个补充。这次要抓取的房价来自安居客,西双版纳房价数据(其他房产相关的垂直平台还未覆盖)。之所以说是上一篇的补充,因为,这次数据来自 html 。废话不多说,撸起袖子开始干。
1. 准备工作
1.1 用到技术
- python3
- requests: http 爬取 html
- beautifulsoup4: 从 html 字符串中提取需要的数据
- pandas: 分析,保存数据
- matplotlib: 数据可视化分析
1.2 安装
如已安装,请跳过。
pip install requests
pip install beautifulsoup4
pip install pandas
pip install matplotlib
1.3 导入
import requests
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
# %matplotlib inline
2. 页面分析
2.1 打开页面
使用 Chrome 浏览器打开页面 https://bannan.anjuke.com/community/?from=navigation

2.2 定位目标元素选择器
在开发者工具中,找到楼盘列表容器 dom 元素选择器。这里看到的是,id 为 list-content。记下此 id。

2.3 详细了解目标元素 dom 结构
在开发者工具控制台(Console)中,输入 document.getElementById('list-content') 回车。逐次展开 dom 树,找到目标数据所在的元素。下图标注出了本文目标数据字段所在的 dom 元素:
- name: 楼盘名称
- price: 价格
- address 地址
- latitude: 地图位置 纬度
- longitude: 地图位置 经度

2.4 http 请求头
为了模拟(伪装)用户访问页面,最重要的就是获取浏览器正常请求页面数据的 http 请求头,并在 requests 中设置一样的请求头。其中最重要的请求头部字段就是 user-agent 用户代理。它是服务端用来辨别用户当前访问的设备,操作系统版本,浏览器厂商等信息的重要依据。另外部分网站,也会设置 cookie 字段,存储用户本次访问的会话信息,其中可能也包含了数据访问的权限信息,这种情况下,为了能正确抓取到数据,就必须提供此字段。如果不想做那么多分析,可以简单粗暴的直接将整个 header 复制使用。
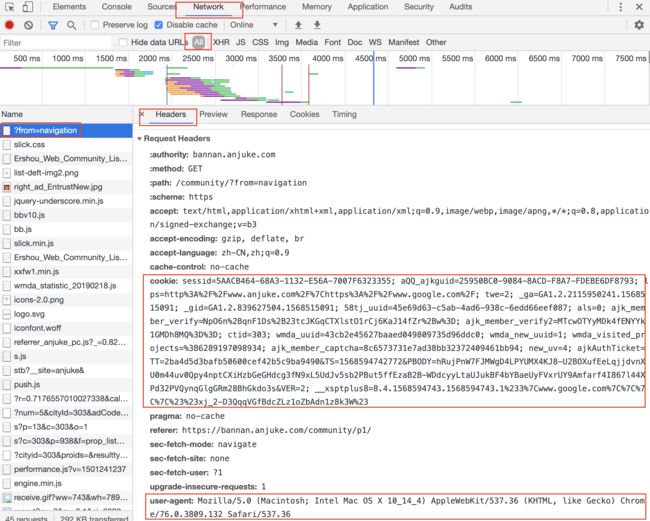
3. 抓取数据
3.1 根据分页和 cookie 生成 http 请求头
经过第 2 小节的分析,发现,http 请求头中包含了分页信息和 cookie 。因此,我需要提供一个函数,动态生成 headers 。
def get_headers(page, cookie):
headers = {
'authority': 'bannan.anjuke.com',
'method': 'GET',
'path': '/community/p{}/'.format(page),
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'cookie': cookie,
'pragma': 'no-cache',
'referer': 'https://bannan.anjuke.com/community/p1/',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
return headers
3.2 抓取分页 html
def get_html_by_page(page, cookie):
headers = get_headers(page, cookie)
url = 'https://bannan.anjuke.com/community/p{}/'.format(page)
res = requests.get(url, headers=headers)
if res.status_code != 200:
print('页面不存在!')
return None
return res.text
3.3 使用 beautifulsoup 从 html 提取原始数据
def extract_data_from_html(html):
soup = BeautifulSoup(html)
list_content = soup.find(id="list-content")
if not list_content:
return None
items = list_content.find_all('div', class_='li-itemmod')
if len(items) == 0:
return None
return [extract_data(item) for item in items]
def extract_data(item):
name = item.find_all('a')[1].text.strip()
address = item.address.text.strip()
if item.strong is not None:
price = item.strong.text.strip()
else:
price = None
finish_date = item.p.text.strip().split(':')[1]
latitude, longitude = [d.split('=')[1] for d in item.find_all('a')[3].attrs['href'].split('#')[1].split('&')[:2]]
return name, address, price, finish_date, latitude, longitude
3.4 自动抓取所有分页数据
需要按照 2.4 节的方法,拿到 cookie 字段。
def crawl_all_page(cookie):
page = 1
data_raw = []
while True:
try:
html = get_html_by_page(page, cookie)
data_page = extract_data_from_html(html)
if not data_page:
break
data_raw += data_page
print('crawling {}th page ...'.format(page))
page += 1
except:
print('maybe cookie expired!')
break
print('crawl {} pages in total.'.format(page-1))
return data_raw
cookie = 'sessid=5AACB464-68A3-1132-E56A-7007F6323355; aQQ_ajkguid=25950BC0-9084-8ACD-F8A7-FDEBE6DF8793; lps=http%3A%2F%2Fwww.anjuke.com%2F%7Chttps%3A%2F%2Fwww.google.com%2F; twe=2; _ga=GA1.2.2115950241.1568515091; _gid=GA1.2.839627504.1568515091; 58tj_uuid=45e69d63-c5ab-4ad6-938c-6edd66eef087; als=0; ajk_member_verify=NpO6n%2BqnF1Ds%2B23tcJKGqCTXlstO1rCj6KaJ14fZr%2Bw%3D; ajk_member_verify2=MTcwOTYyMDk4fENYYk1GMDh8MQ%3D%3D; ctid=303; wmda_uuid=43cb2e45627baaed049809735d96ddc0; wmda_new_uuid=1; wmda_visited_projects=%3B6289197098934; ajk_member_captcha=8c6573731e7ad38bb32372409461bb94; wmda_session_id_6289197098934=1568603284258-3d374e88-7575-dd0d; new_session=1; init_refer=https%253A%252F%252Fwww.anjuke.com%252Fcaptcha-verify%252F%253Fcallback%253Dshield%2526from%253Dantispam%2526serialID%253Dabc4a77486bb629207f53adfd9fd41d8_8635cc4b8554447d8ff882870fd38edf%2526history%253DaHR0cHM6Ly9iYW5uYW4uYW5qdWtlLmNvbS9jb21tdW5pdHkvP2Zyb209bmF2aWdhdGlvbg%25253D%25253D; new_uv=7; __xsptplusUT_8=1; ajkAuthTicket=TT=2ba4d5d3bafb50600cef42b5c9ba9490&TS=1568603284903&PBODY=GHpJ_2vcmP0mvWXGapl7PxF_tEdjOJPOhfneYajD8eY_73T9SP5GP7Y57yd2WFECnSK9nMzV8jySm1lE9_I8r86kK5rOr0dDDKJn6KdQpbMXbhdr3I67d56f3XJmGJArmuqIoBoMcoDw_5cDDPVVfkCNYdMlQ97YfVtb2DxtizU&VER=2; __xsptplus8=8.7.1568603285.1568603285.1%233%7Cwww.google.com%7C%7C%7C%7C%23%23PcwYzNJmsyogWc2ohLkJ8TYAknaOVFpc%23'
data_raw = crawl_all_page(cookie)
crawling 1th page ...
crawling 2th page ...
crawling 3th page ...
crawling 4th page ...
crawling 5th page ...
crawling 6th page ...
crawling 7th page ...
crawling 8th page ...
crawling 9th page ...
crawl 9 pages in total.
4. 分析数据
4.1 创建 pandas.DataFrame 对象
columns = ['name', 'address', 'price', 'finish_date', 'latitude', 'longitude']
df = pd.DataFrame(data_raw, columns=columns)
print('{} records.'.format(df.shape[0]))
df.tail()
253 records.
| name | address | price | finish_date | latitude | longitude | |
|---|---|---|---|---|---|---|
| 248 | 彼岸山水 | [景洪市-龙舟广场]港口路8号 | None | 暂无数据 | 22.018101 | 100.809965 |
| 249 | 半岛至尊 | [景洪市-龙舟广场]清泉路 | None | 2011 | 22.007566 | 100.765688 |
| 250 | 缤纷公寓 | [景洪市-龙舟广场]港口路,近景亮路 | None | 暂无数据 | 22.02065 | 100.809476 |
| 251 | 碧水花园 | [景洪市-龙舟广场]坝吉路32号 | None | 暂无数据 | 21.98705 | 100.805573 |
| 252 | 安厦雨林圣堤亚纳 | [景洪市-龙舟广场]勐泐大道,近菩提大道 | None | 2012 | 21.969016 | 100.804316 |
4.2 随机取样分析
使用 sample() 方法,传入随机取样的数量。相对于使用 head() 和 tail() 方法,更能从统计学上了解数据的特点。
df.sample(5)
| name | address | price | finish_date | latitude | longitude | |
|---|---|---|---|---|---|---|
| 142 | 阳光城 | [景洪市-龙舟广场]宣慰大道122号 | 8000 | 暂无数据 | 22.005098 | 100.793373 |
| 213 | 福光小区 | [景洪市-龙舟广场]曼它拉路522号 | None | 暂无数据 | 21.486319 | 101.570071 |
| 245 | 大曼么小区 | [景洪市-龙舟广场]勐海路92号 | None | 暂无数据 | 21.997218 | 100.778 |
| 51 | 梦云南雨林澜山 | [景洪市-龙舟广场]榕林大道 | 15007 | 暂无数据 | 21.977488 | 100.830815 |
| 133 | 雨林佳苑(别墅) | [勐腊县-雨林广场]相思路,近山榕路 | 15862 | 暂无数据 | 21.455503 | 101.557166 |
4.3 房价数据清洗
通过随机取样,发现房价字段 price 有不少缺失数据(None),影响到下一步的数据统计分析。因此,需要对数据进行清洗和预处理。
4.3.1 查看房价缺失数据数量
df[df['price'].isna()].shape[0]
73
4.3.2 删除房价缺失的数据记录
df.dropna(subset=['price'], inplace=True)
print('{} records after drop missing-data.'.format(df.shape[0]))
180 records after drop missing-data.
4.3.3 转换数值数据类型为浮点型
df = df.astype({'price': 'float64', 'latitude': 'float64', 'longitude': 'float64'})
df.sample(5)
| name | address | price | finish_date | latitude | longitude | |
|---|---|---|---|---|---|---|
| 129 | 冠城时代广场 | [勐海县-景管路]景管路400号 | 8870.0 | 暂无数据 | 21.961283 | 100.442164 |
| 29 | 阳光假日 | [景洪市-龙舟广场]勐泐大道46号 | 7708.0 | 2017 | 22.005886 | 100.796546 |
| 82 | 世纪新城 | [景洪市-龙舟广场]勐渤大道71号 | 10540.0 | 暂无数据 | 21.991023 | 100.801773 |
| 73 | 兴豪门 | [景洪市-龙舟广场]澜沧江路5号 | 7773.0 | 2014 | 22.021178 | 100.812162 |
| 16 | 绿城春江明月 | [景洪市-龙舟广场]勐泐大道75号 | 11079.0 | 暂无数据 | 21.987411 | 100.801050 |
4.4 统计分析
4.4.1 最高房价
df['price'].max()
35748.0
4.4.2 最低房价
df['price'].min()
3858.0
4.4.3 平均房价
df['price'].mean()
9450.638888888889
4.4.4 房价中位数
df['price'].median()
8793.0
4.4.5 房价分布标准差
df['price'].std()
3626.466118872251
5. 数据可视化
绘制房价分布直方图:
fig, ax = plt.subplots()
df.plot(y='price', ax=ax, bins=20, kind='hist', label='房价频率直方图', legend=False)
ax.set_title('房价分布直方图')
ax.set_xlabel('房价')
ax.set_ylabel('频率')
plt.grid()
plt.show()
6. 命令行运行
6.1 代码封装
将以下代码保存到文件 crawl_anjuke.py:
#!/usr/local/bin/python
import requests
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
import time
import argparse
def get_headers(page, cookie):
headers = {
'authority': 'bannan.anjuke.com',
'method': 'GET',
'path': '/community/p{}/'.format(page),
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'cookie': cookie,
'pragma': 'no-cache',
'referer': 'https://bannan.anjuke.com/community/p1/',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
return headers
def get_html_by_page(page, cookie):
headers = get_headers(page, cookie)
url = 'https://bannan.anjuke.com/community/p{}/'.format(page)
res = requests.get(url, headers=headers)
if res.status_code != 200:
print('页面不存在!')
return None
return res.text
def extract_data_from_html(html):
soup = BeautifulSoup(html)
list_content = soup.find(id="list-content")
if not list_content:
return None
items = list_content.find_all('div', class_='li-itemmod')
if len(items) == 0:
return None
return [extract_data(item) for item in items]
def extract_data(item):
name = item.find_all('a')[1].text.strip()
address = item.address.text.strip()
if item.strong is not None:
price = item.strong.text.strip()
else:
price = None
finish_date = item.p.text.strip().split(':')[1]
latitude, longitude = [d.split('=')[1] for d in item.find_all('a')[3].attrs['href'].split('#')[1].split('&')[:2]]
return name, address, price, finish_date, latitude, longitude
def crawl_all_page(cookie):
page = 1
data_raw = []
while True:
try:
html = get_html_by_page(page, cookie)
data_page = extract_data_from_html(html)
if not data_page:
break
data_raw += data_page
print('crawling {}th page ...'.format(page))
page += 1
except:
print('maybe cookie expired!')
break
print('crawl {} pages in total.'.format(page-1))
return data_raw
def create_df(data):
columns = ['name', 'address', 'price', 'finish_date', 'latitude', 'longitude']
return pd.DataFrame(data, columns=columns)
def clean_data(df):
df.dropna(subset=['price'], inplace=True)
df = df.astype({'price': 'float64', 'latitude': 'float64', 'longitude': 'float64'})
return df
def visual(df):
fig, ax = plt.subplots()
df.plot(y='price', ax=ax, bins=20, kind='hist', label='房价频率直方图', legend=False)
ax.set_title('房价分布直方图')
ax.set_xlabel('房价')
ax.set_ylabel('频率')
plt.grid()
plt.show()
def run(cookie):
data = crawl_all_page(cookie)
df = create_df(data)
df = clean_data(df)
visual(df)
df.sort_values('price', inplace=True)
df.reset_index(drop=True, inplace=True)
# 保存 csv 文件
filename = time.strftime("%Y-%m-%d", time.localtime())
csv_file = filename + '.csv'
df.to_csv('anjuke_banna_house_price.csv', index=False)
def get_cli_args():
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--cookie', type=str, help='cookie.')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_cli_args()
run(args.cookie)
6.2 命令行运行
cookie 获取方式,参考 2.4 小节。
python crawl_anjuke.py --cookie "sessid=5AACB464-68A3-1132-E56A-7007F6..."
warm tips: 数据保存可参考 python 自动抓取分析文章阅读量——掘金专栏版 第 5 小节.
猜你喜欢
- [1] python 数据分析工具包 pandas(一)
- [2] python 数据可视化工具包 matplotlib
坚持写专栏不易,如果觉得本文对你有帮助,记得点个赞。感谢支持!
- 个人网站: https://kenblog.top
- github 站点: https://kenblikylee.github.io
- 掘金: https://juejin.im/user/5bd2b8b25188252a784d19d7
- 知乎: https://www.zhihu.com/people/kenbliky/posts
- CSDN: https://blog.csdn.net/weixin_37543731

微信扫描二维码 获取最新技术原创