「完结」你对深度学习模型的理解是否足够深刻,这12篇文章了解下
2020-05-28 18:07:49
文/编辑 | 言有三
好的模型结构是深度学习成功的关键因素之一,不仅是非常重要的学术研究方向,在工业界实践中也是模型是否能上线的关键。对各类底层深度学习模型设计和优化技术理解的深度是决定我们能否在深度学习项目中游刃有余的关键,因此我们在修行之路专栏的《不惑境界》中,着重于深入讲解主流的网络结构设计思想,包括对网络深度,宽度的理解,残差网络和分组网络的设计,多尺度与注意力机制的设计,以及深度学习模型压缩之模型剪枝,量化,蒸馏,还有AutoML技术,本次来给大家进行总结。
数据与人工智能技术发展
深度学习成功源于三驾马车,模型,数据和硬件,深度学习正是因为学会了从数据中抽象知识,才能够完成各种各样的任务。不知道什么样的数据能够完成手中的任务,就不算真正的入门深度学习。深度理解从有监督特征工程到无监督特征学习的进展,从学习特征,到学习模型,到学习整个系统的技术发展路线非常重要,我们一定要非常重视。
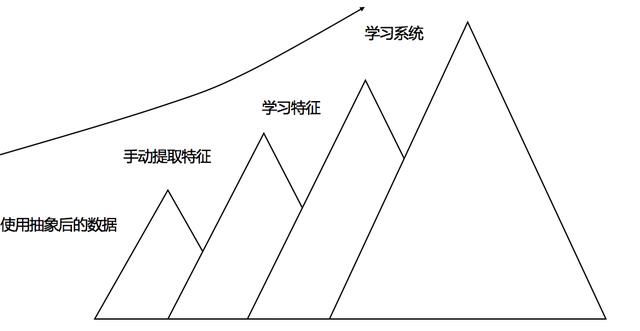
「AI不惑境」数据压榨有多狠,人工智能就有多成功
网络深度对模型的影响
深度学习模型之所以在各种任务中取得了成功,足够的网络深度当居首功。更深的模型意味着更好的非线性表达能力,可以学习更加复杂的变换,从而可以拟合更加复杂的特征输入。那么是不是模型越深,性能就越好呢?对这个问题,我们要认真思考。
「AI不惑境」网络深度对深度学习模型性能有什么影响?
网络宽度对模型的影响
在一定程度上,网络越深,性能越好,这一点同样适用于网络宽度,它指的是每一层的通道(channel)的数量。更宽的网络可以让每一层学习到更加丰富的特征,比如不同方向,不同频率的纹理特征。那越宽就一定越好吗?我们又该如何去平衡宽度和成平方量级增加的计算量问题。

「AI不惑境」网络的宽度如何影响深度学习模型的性能?
学习率和批处理大小
作为一对相互之间有紧密关系的模型优化相关因子,学习率和批处理大小(batchsize)对模型性能的影响有一些简单,但又有些神秘。不适当的参数往往让模型处于收敛与不收敛之间,但又可能对模型性能的影响非常微小。因此我们特意在这个系列中提起这个问题,希望引起大家的重视。
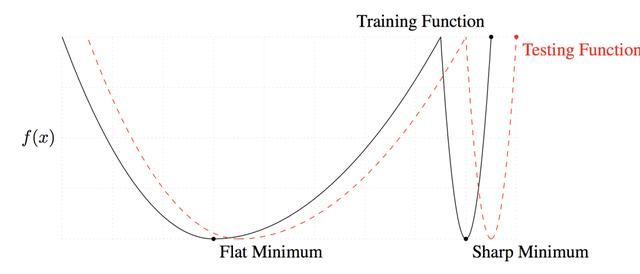
「AI不惑境」学习率和batchsize如何影响模型的性能?
残差网络原理和发展
在近几年的深度学习模型发展史中,残差网络是影响最大的模型,相信大家对此没有异议。残差网络因其简单而有效的结构解决了深层模型训练的难题,成为各类任务的基准模型,那么它缘起何处,又将走向何方?
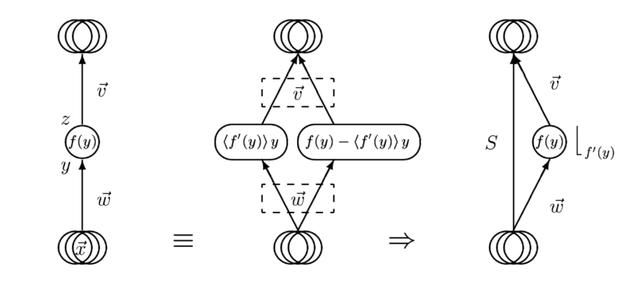
「AI不惑境」残差网络的前世今生与原理
分组模型原理与发展
模型落地才是深度学习在工业界发挥作用的关键,在移动端高效的模型设计中,卷积拆分和分组几乎是不可缺少的思想,那么它们究竟是如何高效,本身又有哪些发展呢。
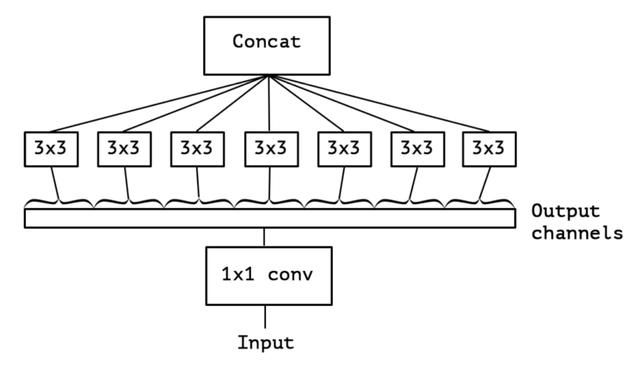
「AI不惑境」移动端高效网络,卷积拆分和分组的精髓
多尺度设计思想
多尺度可以说是图像处理领域中的精髓,实际上就是对信号的不同粒度的采样,在不同的尺度下我们可以观察到不同的特征,从而完成不同的任务。尺度始终是计算机视觉领域中的一个大问题,小物体与超大尺度物体往往都会严重影响性能,那么研究人员如何克服困难呢?

「AI不惑境」深度学习中的多尺度模型设计
注意力机制原理与设计
注意力机制(Attention)是聚焦于目标重要信息的处理机制,比如图像中的显著区域,是符合人类信息处理的机制。在计算机视觉,自然语言处理等领域中都发挥着重要的作用,那注意力机制都有哪些设计呢?

「AI不惑境」计算机视觉中注意力机制原理及其模型发展和应用
模型剪枝核心技术与展望
模型剪枝是一项历史非常悠久的模型压缩技术,当前已经有了比较大的进步和发展,那么当前模型剪枝的核心技术有哪些,发展现状如何,未来还可以做哪些工作呢?
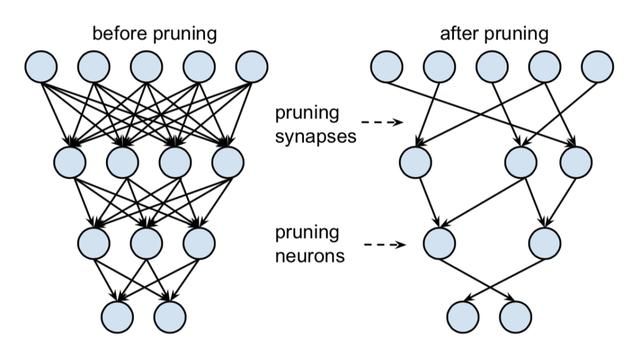
【AI不惑境】模型剪枝技术原理及其发展现状和展望
模型量化核心技术与展望
模型量化是非常实用的模型压缩技术,当前已经在工业界发展比较成熟,那么当前模型量化的核心技术有哪些,发展现状如何,未来还可以做哪些工作呢?
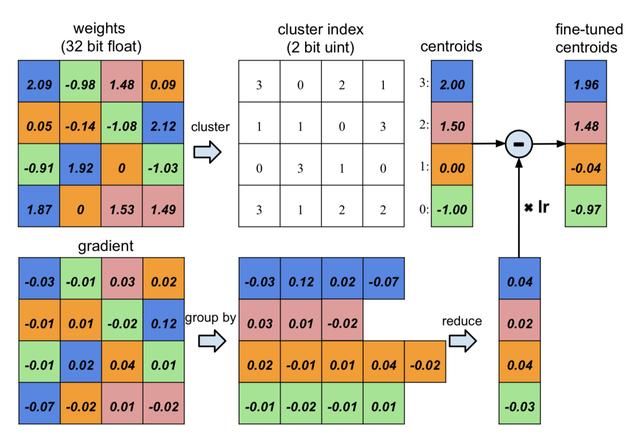
「AI不惑境」模型量化技术原理及其发展现状和展望
模型蒸馏核心技术与展望
模型知识蒸馏是非常经典的基于迁移学习的模型压缩技术,在学术界的研究非常活跃,工业界也有许多的应用和较大的潜力,那么当前模型蒸馏的核心技术有哪些,发展现状如何,未来还可以做哪些工作呢?
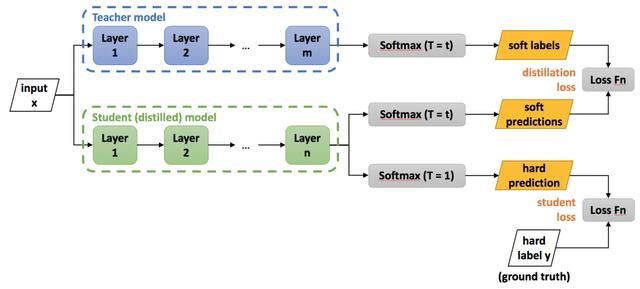
「AI不惑境」模型压缩中知识蒸馏技术原理及其发展现状和展望
AutoML与模型设计和优化
自从2017年Google提出使用强化学习搜索模型结构之后,AutoML/NAS便迅速成为了学术界和工业界的宠儿,在这几年也是非常火热的领域。AutoML可以用于数据的使用,特征的选择,模型架构的设计和优化,优化参数的搜索等,现在发展究竟如何了呢?

「AI不惑境」AutoML在深度学习模型设计和优化中有哪些用处?