Keras预测股票走势
众所周知,股票预测是一个玄学问题,没有经验和方法,一不留神就可能被割韭菜了。当然本文仅针对单纯的数据进行预测,不具备实际操作性,主要用于学习技术。如果想将预测数据用于实际操作,则仅供娱乐,不要太注重结果。
为方便下载和应用,本文涉及的全部代码和数据集放在这里:https://github.com/Stevengz/Stock_predict。
需要用到的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import RobustScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
from datetime import timedelta
# 画图中避免中文乱码的设置
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
数据预处理
因为股票的数值波动比较大,在一整年内,一支股票的价格所经历的最高值和最低值的差距会非常大。
而训练所需数据量要足够多,因此数据的分布会非常不均匀,在这个情况下不利于得出优秀的模型。因此需要对数据进行归一化/标准化,不仅能节约时间,还利于得出更好的结果。
导入数据
df = pd.read_excel('股票数据.xlsx', sheet_name='Sheet1')
# 索引
df.set_index('时间', inplace=True)
# 删除其它数据
df.drop(['开盘', '最高', '最低', '成交量'], axis=1, inplace=True)
# 按比例调整收盘价用于反向转换
close_robust = RobustScaler()
close_robust.fit(df[['收盘']])
# 归一化
scaler_robust = RobustScaler()
df = pd.DataFrame(scaler_robust.fit_transform(df),
columns=df.columns,
index=df.index)
RobustScaler()缩放数据使极端异常值几乎没有影响,并能提高训练时间和整体模型性能。
数据分割
将数据分成两个序列,适当地格式化数据,一个是已知值,另一个是预测值,当然预测值是空的。
先设置一个函数:
def split_series(seq, in_num, out_num):
X, y = [], []
for i in range(len(seq)):
# 查找当前序列的结尾
end = i + in_num
o_end = end + out_num
# 超出长度则跳出循环
if o_end > len(seq):
break
# x 过去的价格和指标,y 未来的价格
seq_x, seq_y = seq[i:end, :], seq[end:o_end, 0]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
通过这个函数,就可以随意更改序列的长度。
例如使用过去100天的值来预测未来15天的价格, split_sequence()函数会将数据格式转化为适当的 X 和 y 变量,其中 X 包含过去100天的收盘价和指标,y 包含接下来15天的收盘价。
代码如下:
# 过去天数
real_day = 100
# 预测的天数
predict_day = 15
# 特征
shape = df.shape[1]
# 将数据分成适当的顺序
X, y = split_series(df.to_numpy(), real_day, predict_day)
模型构建
这里使用 LSTM(长短时记忆网络)进行预测,相比一般的神经网络来说,它能够处理序列变化的数据,且解决了长序列训练过程中的梯度消失和梯度爆炸问题。
定义了两个隐藏层:
# 实例化模型
model = Sequential()
# 输入层
model.add(LSTM(90,
activation="tanh",
return_sequences=True,
input_shape=(real_day, shape)))
# 隐藏层
model.add(LSTM(30, activation="tanh", return_sequences=True))
model.add(LSTM(60, activation="tanh"))
# 输出层
model.add(Dense(predict_day))
# 模型汇总
model.summary()
# 使用选定的规范编译数据
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
# 适配与训练
res = model.fit(X, y, epochs=50, batch_size=128, validation_split=0.1)
进行预测
接下来就是带入数据进行预测
这里需要将数据的维度进行变化,增加一个维度,形如(samples,timesteps,input_dim)的3D张量,这三部分的解释:假如我们输入有10个句子,每个句子都由5个单词组成,而每个单词用64维的词向量表示。那么 samples=10,timesteps=5,input_dim=64。
因此需要增加一个 samples,数据不是太多,因此设定为 1 批就行了,下面第一行代码的 reshape 就是将数据划分。
# 进行预测
y_pre = model.predict(np.array(df.tail(real_day)).reshape(1, real_day, shape))
# 预测值转回原始格式
y_pre = close_robust.inverse_transform(y_pre)[0]
# 创建预测价格
preds = pd.DataFrame(y_pre,
index=pd.date_range(start=df.index[-1] +
timedelta(days=1),
periods=len(y_pre),
freq="B"),
columns=[df.columns[0]])
# 实际值转为原始价格
actual_data = pd.DataFrame(close_robust.inverse_transform(df[["收盘"]].tail(real_day)),
index=df.收盘.tail(real_day).index,
columns=[df.columns[0]]).append(preds.head(1))
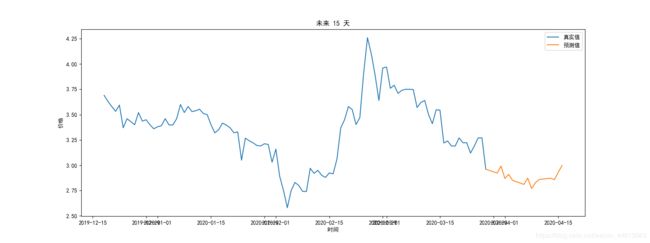
画图
将真实值和预测值用不同颜色表示:
#绘图
plt.figure(figsize=(16, 6))
plt.plot(actual_data, label="真实值")
plt.plot(preds, label="预测值")
plt.ylabel("价格")
plt.xlabel("时间")
plt.title(f"未来 {len(y_pre)} 天")
plt.legend()
plt.show()
结果: