Redis:集群
Redis主从复制解决了读写分离,实现负载均衡的目的。哨兵机制解决了主从复制架构中当主节点宕机后,需要人为介入进行故障恢复的问题。但是随之而来的是另一个问题,Redis的每个节点都存储了所有的数据,从而导致整个架构中总数据的存储能力取决于可用存储容量最小的那个节点。于是对Redis进行集群部署,实现水平扩容也变得尤为重要。
实现水平扩容的一种方案是启动多个Redis节点,然后由客户端决定每个键由哪个Redis节点存储,下次客户端读取该键时直接到该节点读取。这样当我们把整个数据分布存储在N个节点中时,每个节点平均来说只存放总数据量的1/N。但对于该方案,如果我们想要增加更多的节点时,就需要对数据进行手工迁移,同时在迁移过程中为了保证数据的一致性,还不得不将服务停止。可见由客户端进行分片的维护成本是很高的,且增加、移除节点较为繁琐。
1. 搭建集群架构
为了演示集群的应用场景以及故障恢复等操作,这里我们搭建一个3主3从的集群架构。服务器列表如下:
| 服务器ip | 端口 |
|---|---|
| 192.168.1.19 | 6379 |
| 192.168.1.19 | 6380 |
| 192.168.1.20 | 6379 |
| 192.168.1.20 | 6380 |
| 192.168.1.21 | 6379 |
| 192.168.1.21 | 6380 |
(1)首先我们将逐个启动6个Redis服务,启动过程同单个节点,这里就不一一演示。但是需要注意的是:
- 使用集群功能,我们需要在配置文件中打开
cluster-enabled选项。 - 集群会将当前节点记录的集群状态持久化存储在指定文件中,这个文件默认为当前工作目录下的nodes.conf,因此每个节点对应的文件必须不同,否则会造成启动失败。我们可以通过
cluster-config-file选项修改持久化文件的名称。
每个节点启动成功之后会输出类似下面的内容:
![]()
(2)通过info cluster命令来判断集群是否正常启用。

(3)在任意一台服务器上使用下面命令来初始化集群。
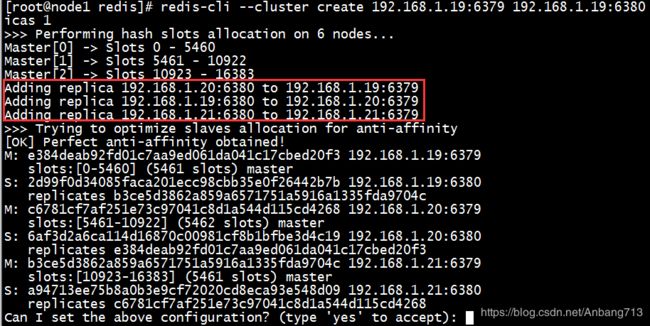
redis-cli --cluster create 192.168.1.19:6379 192.168.1.19:6380 192.168.1.20:6379 192.168.1.20:6380 192.168.1.21:6379 192.168.1.21:6380 --cluster-replicas 1
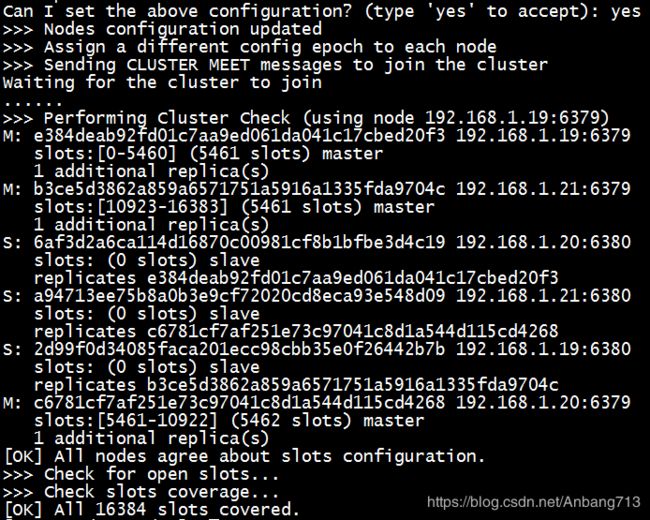
执行之后,Redis会自动分配主节点和从节点,并分配slots,并提示我们进行确认。
当我们确认配置时,Redis开始初始化集群,至此集群搭建完成。
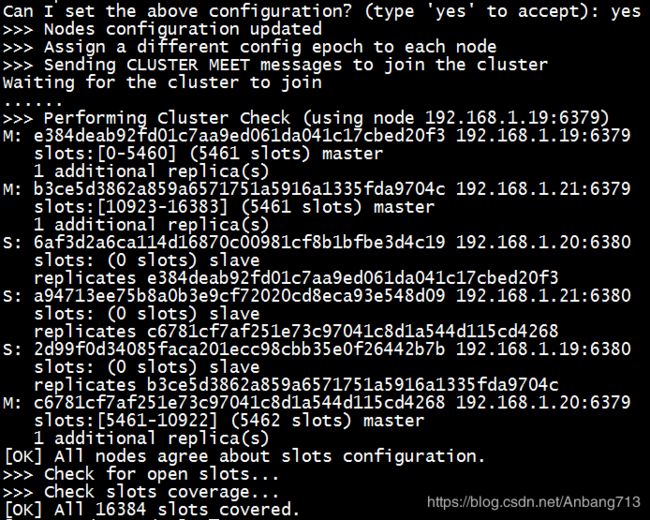
2. 验证集群
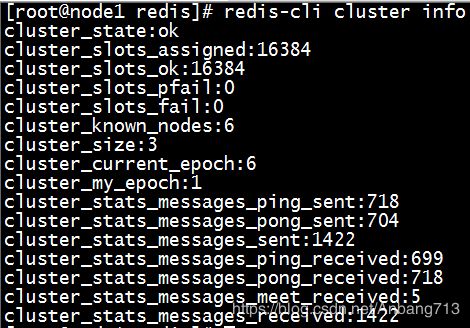
(1)查看集群信息,命令如下:
redis-cli cluster info
(2)查看集群节点信息,命令如下:
redis-cli cluster nodes

从上面的输出中可以看到所有节点的运行ID、地址和端口、角色、、状态以及负责的插槽等信息。
(3)启动和验证增删改查
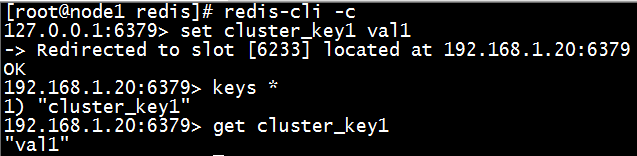
在验证增删改查之前,我们需要使用redis-cli -c命令启动集群。启动之后,进入Redis客户端。此时对数据的增删改查就和单节点的Redis操作一样了,只不过对于集群来说,Redis会根据key来重定向到其它的节点。
3. 故障转移
之前我们使用哨兵对一主多从的主从架构系统实现主节点服务停止后故障转移,现在我们来看看集群架构的故障转移。
(1)首先使用redis-cli cluster nodes查看集群节点信息,可以看到192.168.1.19:6379这个Redis节点作为192.168.1.20:6380这个节点的主节点。

(2)停止192.168.1.19:6379这个主节点,观察192.168.1.20机器上的故障转移提示信息。在多次尝试连接到192.168.1.19:6379节点失败后,开始故障转移,此时192.168.1.20:6380升级为新的主节点。

(3)启动192.168.1.19:6379节点,启动之后会和192.168.1.20:6380主节点建立连接,并开始同步数据。
(4)再次查看集群节点信息,发现主从角色已经完成切换。

在一个集群中,每个节点都会定期向其它节点发送ping命令,并通过有没有收到回复来判断目标节点是否已经下线。具体来说,集群中的每个节点每隔1s就会随机选择其它5个节点,然后选择其中最久没有响应的节点发送ping命令。
如果在一定时间内目标节点没有响应,则发起ping命令的节点会认为目标节点疑似下线。这一点和哨兵模式是类似的,同样的,要使整个集群中的所有节点都认为某一节点已经下线,需要一定数量的节点都认为该节点疑似下线才可以。
在集群中,如果是一个主节点出现故障,就会出现一部分插槽无法写入的问题,这时如果该主节点至少有一个从节点时,集群就开始进行故障恢复来将其中一个从节点转变为主节点来保证集群的完整。选择哪个从节点作为主节点的过程与哨兵中选择领头哨兵的过程是一样的,过程如下:
(1)某个从节点(A)发现其对应的主节点无法连接,此时A会向集群中的每个节点发送请求,要求对方选自己成为主节点。
(2)如果收到请求的节点没有选过其它节点,则会同意将A设置为主节点。
(3)如果A发现有超过集群节点总数一半的节点同意选自己为主节点,则A成功成为主节点。
(4)当有多个从节点同时竞选时,则会出现没有任何节点当选的可能。此时每个参选的节点将等待一个随机时间重新发起参选请求,进行下一轮选举,直到选举成功。
当某个从节点当选为主节点后,会通过slaveof no one将自己转换成主节点,并将旧的主节点的插槽转换给自己负责。
如果一个没有任何从节点且至少负责一个插槽的主节点出现故障,这种情况下,集群无法进行故障恢复,此时集群默认会进去下线状态无法继续工作。如果想要在这种情况下使集群仍能正常工作,我们可以将配置cluster-require-full-coverage设置为no。
4. 添加和删除节点
(1)添加节点
想要向集群中加入新的节点,只需要使用cluster meet命令即可。比如我们想要把节点A加入集群,那么可以这样:
cluster meet ip port
ip和port是集群中任意一个节点的地址和端口号,A接收到客户端发来的命令后,会与该地址和端口号的节点建立连接,使A能够被认作为集群中的一员。
(2)删除节点
删除集群中某个节点也很简单,我们只需要连接到任意一个Redis服务,然后执行cluster forget 命令就可以将某个节点移出集群。
5. 插槽的分配
新的节点加入集群后有两种选择,要么使用cluster replicate命令复制每个主节点来以从节点的形式运行;要么向集群申请分配插槽(slot)来以主节点的形式运行。
在一个集群中,所有的键都会被分配给16384个插槽,而每个主节点会负责处理其中的一部分插槽。我们在初始化集群的时候,就会看到如下的日志输出,以下就是插槽分配的情况: