基于Jsoup实现搜狗微信搜索文章获取链接、搜索公众号信息、微信登录以及登出
2020-03-20更新
已上传至GitHub:https://github.com/Aquarius-Seven/demo-jsoup.git,相比CSDN资源,CommonUtil增加了一个处理需要请求cookie flash的方法(貌似叫劫持),如果有遇到的可以试试管不管用。
原文
最近有这么一个业务需求,需要用到搜狗微信去搜索公众号信息、搜索文章并拿到链接,然后通过抓包工具fiddler、微信PC端打开这个链接去获取阅读量,恩,核心部分就是这么个流程,其中我就负责了分析搜狗微信这块的流程,也就是文章标题所述。
其实做开发有几年了,平时负责的工作基本是安卓移动端的内容,但有幸之前接触过JSOUP这个框架,用网上的资源做播放器(看视频、听音乐),仅学习用,不作商业用途,最后没成想还能在这用上。
好了,废话不多说,下面开搞,我会将我之前分析的流程都记录下来,供大家参考,希望大家不要用来做坏事啊。
首次分析
- 首先,打开Firefox浏览器(网络-持续日志勾上)或Chrome浏览器(Network-Preserve log勾上),并按F12;
- 直接输入链接https://weixin.sogou.com/打开搜狗微信的页面,这个页面后面会用来分析实现微信登录,这里先跳过,先分析搜文章、搜公众号的流程,下面我将用Firefox浏览器将一些重要步骤截图记录;
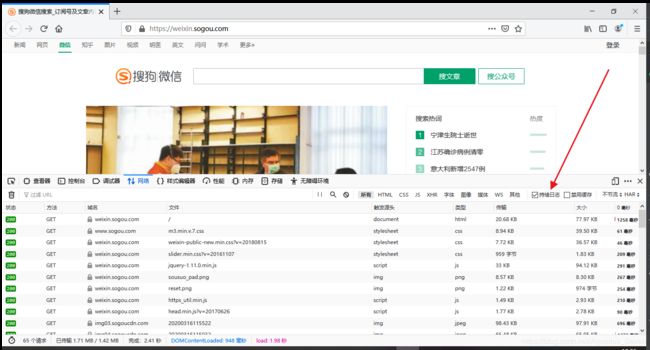
- 看上图可以发现只是输入了一个链接,这边就有那么多的请求,不管它,我们先输入关键词,可以先清空日志,再点击搜文章,这样感觉清爽些;

- 可以看到第一个请求的信息,我们需要的是什么呢,当然是请求的网址啦,以及所需的参数啥的,如下图所示,我们可以拿到地址,分析下可以知道参数type是指搜索的类型,2是文章,那你们猜1是啥?没错,就是公众号。那query参数就很明显了,就是我们的关键词经过UTF-8编码处理后所得,其他参数可以不管了,当作是固定参数就好了;https://weixin.sogou.com/weixin?type=2&query=%E7%96%AB%E6%83%85&ie=utf8&s_from=input&_sug_=y&_sug_type_=

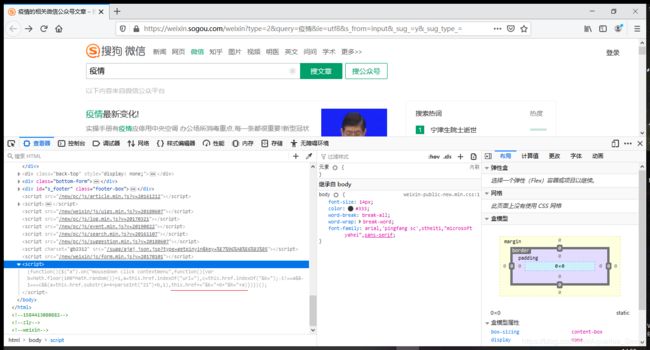
- 好了,现在搜索文章的接口有了,怎么拿到文章的链接呢?这时候就需要用到我们的查看器来分析了,看看给我们返回的页面究竟是怎样的,我们知道我们在网页上点击标题就会跳转到文章,那么是不是html里面已经给我们这个链接了呢?我们可以点击选取页面中的元素也可以用快捷键选取我们第一条文章的标题,结果如下图:
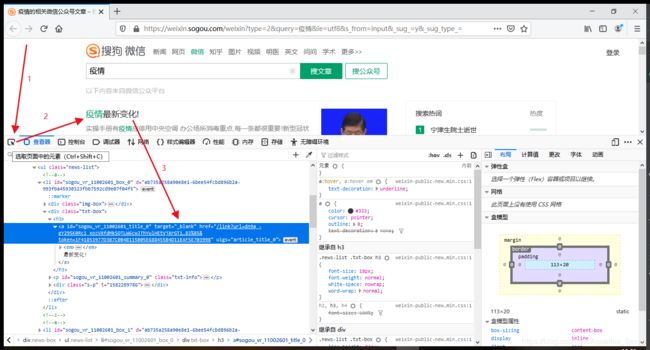
- 咦~好像是有个链接哦,我们提取出来访问试试,右键点击链接处,选择新建标签页打开链接或者复制链接地址自己新建个标签页打开(可以看到就是在html显示的地址前补全了地址https://weixin.sogou.com),结果直接触发了反爬页面,需要输入验证码,害~微信怎么可能那么简单就让你拿到链接呢,是吧?

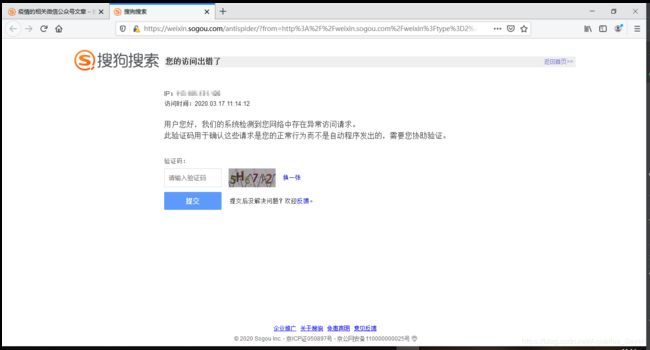
- 既然直接打开这个链接不行,那么我们就来分析下,搜狗是怎么打开的?来,我们改改这个html,然后直接点击标题,在当前标签页跟踪一下:双击_blank,然后删除掉,ENTER,然后切到网络清空下日志先,再点击标题:

- 成功在当前标签页下打开页面,真正的链接是这个,那它是咋来的呢?
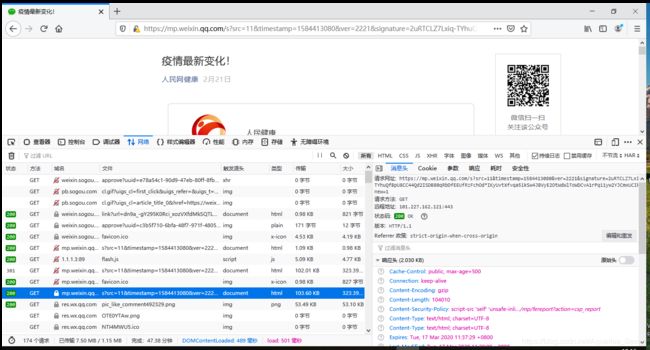
- 往前看,这个请求的响应原来就有真正的链接,哈~踏破铁鞋无觅处得来全不费工夫,我们再来分析下这个请求,咦~这跟前面html里的链接那么像,我们复制下来跟前面的对比下?
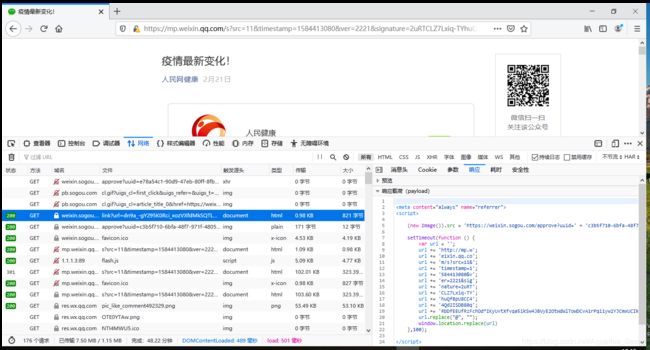

- 后退,提取元素,右键复制链接,可以看到,相比起来点击标题的链接多了k和h两个参数,那这俩货是哪来的呢?我们可以在查看器里找找script标签看看有没有什么收获;

- 呐呐呐,果不其然哈,就在最底下,那么我们现在是不是可以撸代码了?(Talk is cheap. Show me the code.)
Show me the code ~ part 1
- 分析关于文章的信息
public class Article {
/**
* 初始链接
*/
private String originalUrl;
/**
* 标题
*/
private String title;
/**
* 公众号名称
*/
private String oaName;
/**
* 拼接k ,h
*/
private String urlWithSuffix;
/**
* 转换后的链接
*/
private String realUrl;
public String getOriginalUrl() {
return originalUrl;
}
public void setOriginalUrl(String originalUrl) {
this.originalUrl = originalUrl;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getOaName() {
return oaName;
}
public void setOaName(String oaName) {
this.oaName = oaName;
}
public void setUrlWithSuffix(String urlWithSuffix) {
this.urlWithSuffix = urlWithSuffix;
}
public String getUrlWithSuffix() {
return urlWithSuffix;
}
public void setRealUrl(String realUrl) {
this.realUrl = realUrl;
}
public String getRealUrl() {
return realUrl;
}
@Override
public String toString() {
return "Article{" +
"originalUrl='" + originalUrl + '\'' +
", title='" + title + '\'' +
", oaName='" + oaName + '\'' +
", urlWithSuffix='" + urlWithSuffix + '\'' +
", realUrl='" + realUrl + '\'' +
'}';
}
}- 利用JSOUP模拟访问过程
package com.cyf.demo;
import com.cyf.demo.entity.Article;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Demo {
private static final int TIME_OUT = 10000;
public static void main(String[] args) {
String keywords = "疫情";
try {
searchArticle(keywords);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
private static void searchArticle(String keywords) throws IOException, InterruptedException {
String url = "https://weixin.sogou.com/weixin?type=2&query="
+ URLEncoder.encode(keywords, "UTF-8")
+ "&ie=utf8&s_from=input&_sug_=y&_sug_type_=";
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Host", "weixin.sogou.com");
headers.put("Upgrade-Insecure-Requests", "1");
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
Connection connection = Jsoup.connect(url)
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response res = connection.execute();
Document doc = res.parse();
System.out.println(doc);
List articles = getArticles(doc);
articles.forEach(System.out::println);
getRealUrl(articles, res);
}
private static void getRealUrl(List articles, Connection.Response res) throws IOException, InterruptedException {
for (Article article : articles) {
String urlWithSuffix = getKH(article.getOriginalUrl());
article.setUrlWithSuffix(urlWithSuffix);
convertUrl(article, res);
Thread.sleep(5000);
}
}
private static void convertUrl(Article article, Connection.Response res) throws IOException {
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", res.url().toString());
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
headers.put("Upgrade-Insecure-Requests", "1");
Connection connection = Jsoup.connect(article.getUrlWithSuffix())
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
Document doc = resp.parse();
System.out.println(doc);
Elements elements = doc.select("script");
for (Element e : elements) {
if (e.html().contains("var url =")) {
String temp = e.html().substring(e.html().indexOf("{"), e.html().indexOf("}") + 1);
String[] tmp = temp.split(";");
String tempUrl = "";
for (String key : tmp) {
if (key.contains("url +=")) {
tempUrl += key.substring(key.indexOf("\'") + 1, key.length() - 1);
}
}
String realUrl = tempUrl.replace("@", "");
article.setRealUrl(realUrl);
break;
}
}
}
private static List getArticles(Document doc) {
List articles = new ArrayList<>();
Elements elements = doc.select("div[class=txt-box]");
for (Element e : elements) {
Article article = new Article();
Element a = e.selectFirst("h3").selectFirst("a");
article.setOriginalUrl("https://weixin.sogou.com" + a.attr("href"));
article.setTitle(a.text());
a = e.selectFirst("div[class=s-p]").selectFirst("a[class=account]");
article.setOaName(a.text());
articles.add(article);
}
return articles;
}
private static String getKH(String url) {
int b = (int) (Math.floor(100 * Math.random()) + 1);
int a = url.indexOf("url=");
String temp = url.substring(a + 4 + 21 + b, a + 4 + 21 + b + 1);
return url + "&k=" + b + "&h=" + temp;
}
}
part 1代码运行后分析
- 代码运行后,第一个请求结果可以顺利拿到文章的一些信息
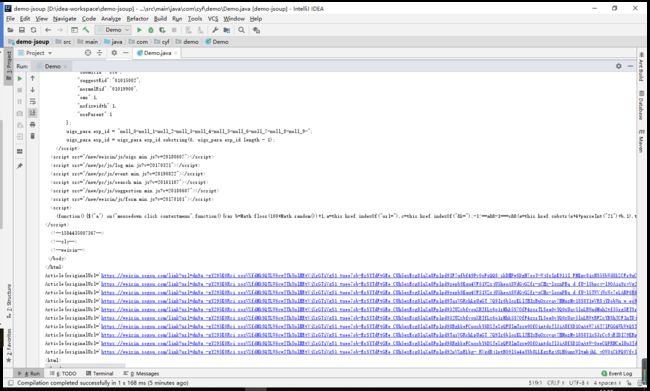
- 但在转化真正的URL的时候出错了,让我们康康返回的是啥东西,貌似跟cookie有关呐

- 那我们把第一个请求返回的cookie塞到第二个试试?通过res.cookies()拿到并塞进转化URL的请求里,然后再次运行代码:
private static void convertUrl(Article article, Connection.Response res) throws IOException {
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", res.url().toString());
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
headers.put("Upgrade-Insecure-Requests", "1");
Connection connection = Jsoup.connect(article.getUrlWithSuffix())
.headers(headers)
.cookies(res.cookies())
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
Document doc = resp.parse();
System.out.println(doc);
Elements elements = doc.select("script");
for (Element e : elements) {
if (e.html().contains("var url =")) {
String temp = e.html().substring(e.html().indexOf("{"), e.html().indexOf("}") + 1);
String[] tmp = temp.split(";");
String tempUrl = "";
for (String key : tmp) {
if (key.contains("url +=")) {
tempUrl += key.substring(key.indexOf("\'") + 1, key.length() - 1);
}
}
String realUrl = tempUrl.replace("@", "");
article.setRealUrl(realUrl);
break;
}
}
} - 结果如下:成功转化了2条URL之后又出现之前的结果,这是为啥呢?cookie不是有了嘛?

再次分析
根据part 1的运行结果,分析是cookie造成的,那我们再重新按照首次分析的步骤,再来一次,要有耐心哦~
- 这次我们直接复制第一个请求地址直接访问,建议最好清除浏览器缓存重新打开浏览器(我也忘了我当时为什么这么做了~我的浏览器设置了关闭浏览器自动清除所有缓存),可以看到搜索接口的响应cookie如下
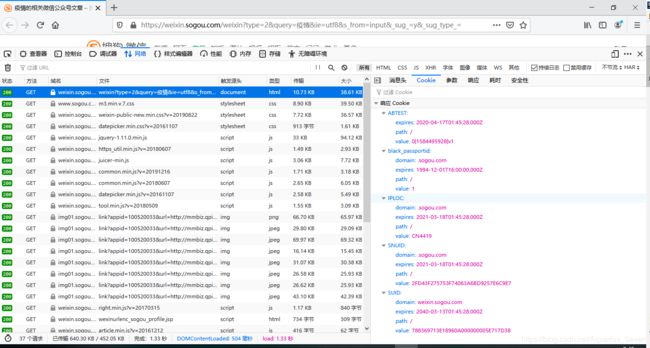
- 参照首次分析步骤,清除html的_blank,再点击标题康康,这次我们不清除日志了,找到这个请求,可以看到,相比起第一个请求的响应cookie,多了JSESSIONID和SUV,那这俩货咱去哪找呢?
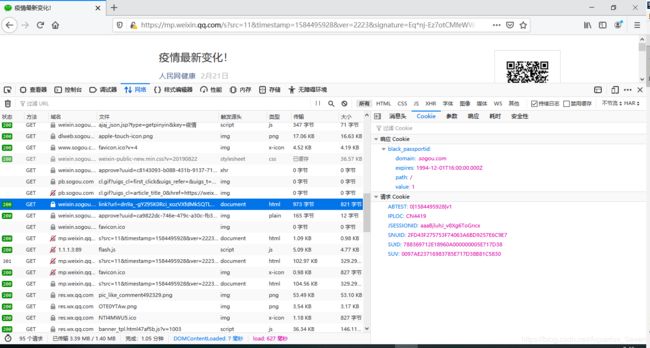
- 往前找找呗,还能咋滴?多找找总会有的(???写完这句话,怎么会突然想到自己是single dog)
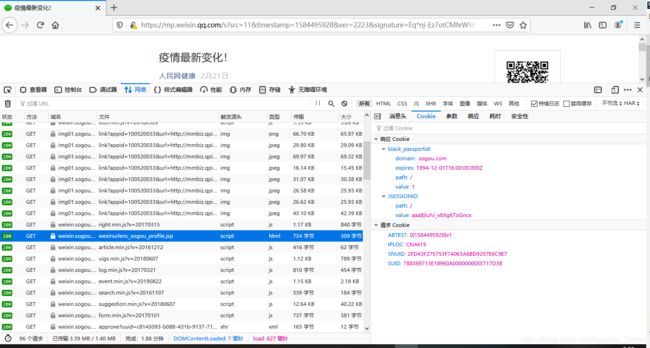

- 来源找到了,让我们来康康这俩请求需要哪些参数,第一个很简单,不需要参数;第二个,哎呦我去,一堆参数呐~

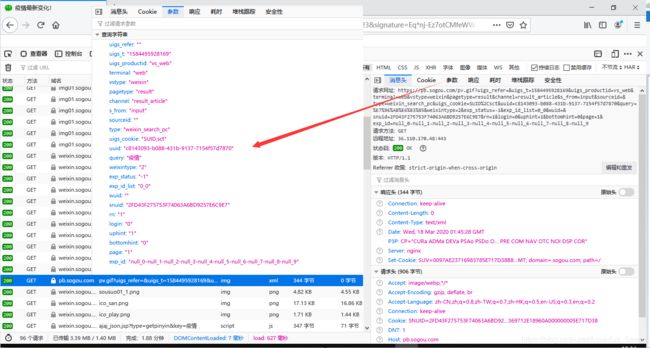
- 不过不虚,咱回到第一次请求的html找找线索康康,果不其然,藏着不少好东西呐~又可以继续撸代码了~
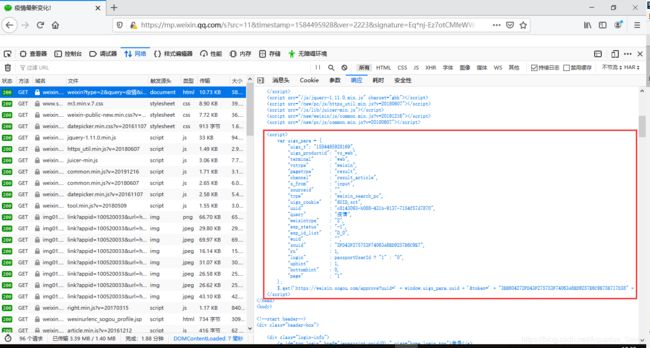
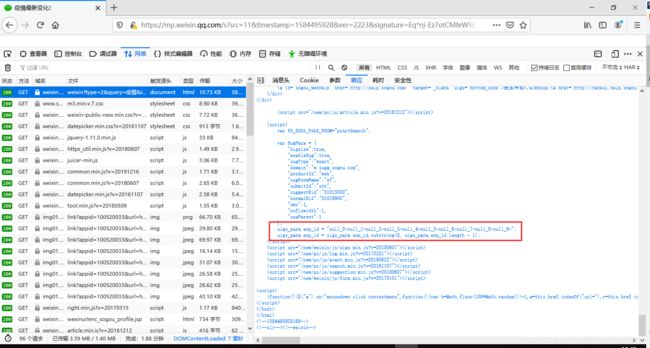
Show me the code ~ part 2
- 搜索文章时,拿到uigs参数,然后再去请求那俩分析的接口,拿到JSESSIONID和SUV参数拼接出完整的cookie
private static void searchArticle(String keywords) throws IOException, InterruptedException {
String url = "https://weixin.sogou.com/weixin?type=2&query="
+ URLEncoder.encode(keywords, "UTF-8")
+ "&ie=utf8&s_from=input&_sug_=y&_sug_type_=";
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Host", "weixin.sogou.com");
headers.put("Upgrade-Insecure-Requests", "1");
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
Connection connection = Jsoup.connect(url)
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response res = connection.execute();
Document doc = res.parse();
System.out.println(doc);
List articles = getArticles(doc);
articles.forEach(System.out::println);
Map params = getUigsPara(doc, false);
System.out.println(params);
Map cookies = getCookies(res, params);
System.out.println(cookies);
getRealUrl(articles, res);
} - 再来改改转换URL的cookie使用
private static void convertUrl(Article article, Connection.Response res) throws IOException {
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Cookie", "ABTEST=" + res.cookies().get("ABTEST") +
";SNUID=" + res.cookies().get("SNUID") +
";IPLOC=" + res.cookies().get("IPLOC") +
";SUID=" + res.cookies().get("SUID") +
";JSESSIONID=" + res.cookies().get("JSESSIONID") +
";SUV=" + res.cookies().get("SUV"));
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", res.url().toString());
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
headers.put("Upgrade-Insecure-Requests", "1");
Connection connection = Jsoup.connect(article.getUrlWithSuffix())
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
Document doc = resp.parse();
System.out.println(doc);
Elements elements = doc.select("script");
for (Element e : elements) {
if (e.html().contains("var url =")) {
String temp = e.html().substring(e.html().indexOf("{"), e.html().indexOf("}") + 1);
String[] tmp = temp.split(";");
String tempUrl = "";
for (String key : tmp) {
if (key.contains("url +=")) {
tempUrl += key.substring(key.indexOf("\'") + 1, key.length() - 1);
}
}
String realUrl = tempUrl.replace("@", "");
article.setRealUrl(realUrl);
break;
}
}
} part 2代码运行后分析
可以发现,参数拿到了,cookie也对了,结果还是跟之前一样,转换了2条URL之后,又转换不了了,我们到底还缺少啥?
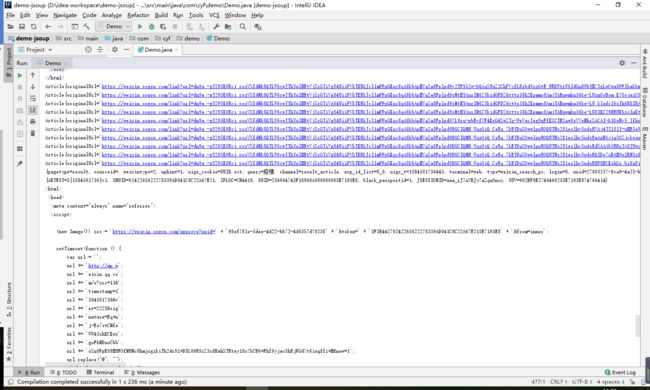
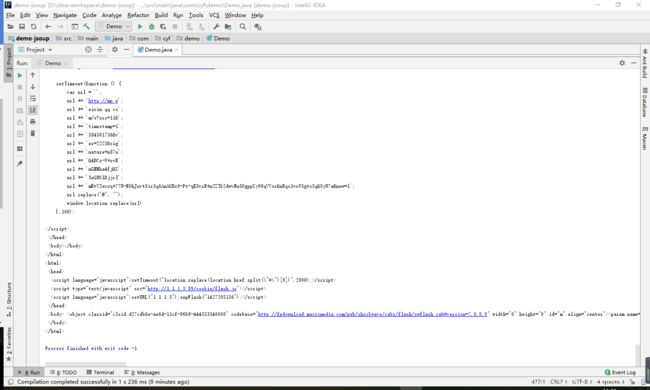
再再次分析(头脑风暴)
- 从结果来看,这一串貌似有点可疑呐~
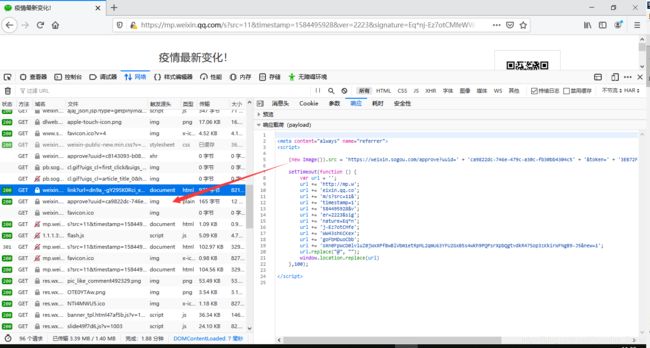
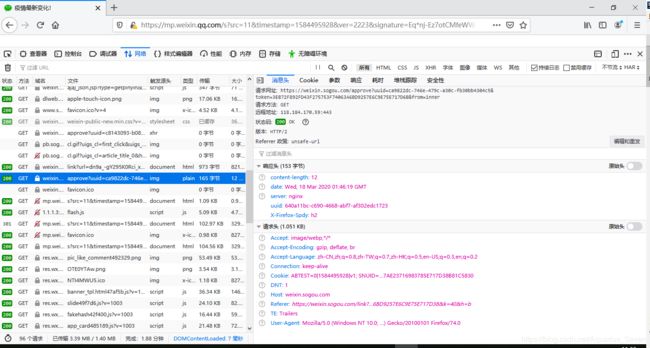
- 好像前面也有呐~
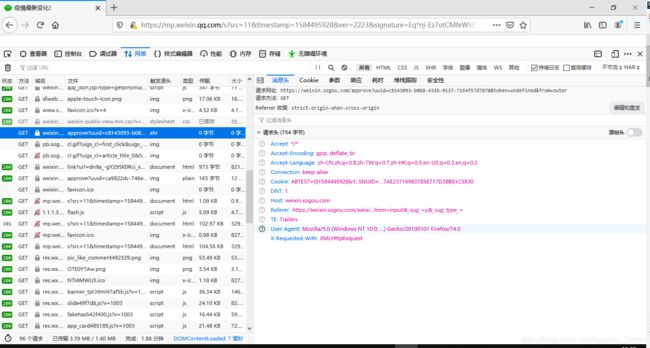
- 再前面,还有~

approve:翻译结果为批准 / 认可 / <古>证明 / 显示
- 感觉是要调用这个来证明搜索、转换URL的意思呐~
- 继续发散思维,我们好像没有打开真正URL的页面,只是拼接了URL就没有接下来的操作了,而真实情况是,我们点击了标题之后就会跳转到真正URL的页面,所以我们是不是应该加上打开真正URL的步骤呢?
- 这一波分析好像差不多了,来来来,继续改造代码试试~
Show me the code ~ part 3
- 这次改造的地方有点多,就不单独一一拿出来了,直接来个完整的。
- 从转换结果截取出来的URL是http的,我们直接在setRealUrl时将它改成https的。
- 还有一些接口需要参数的截取,譬如token,uuid,还有一些延时2s、5s、100ms的操作。
- 还有就是留意每一个请求的Referer。
package com.cyf.demo.entity;
public class Article {
/**
* 初始链接
*/
private String originalUrl;
/**
* 标题
*/
private String title;
/**
* 公众号名称
*/
private String oaName;
/**
* 拼接k ,h
*/
private String urlWithSuffix;
/**
* 转换后的链接
*/
private String realUrl;
public String getOriginalUrl() {
return originalUrl;
}
public void setOriginalUrl(String originalUrl) {
this.originalUrl = originalUrl;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getOaName() {
return oaName;
}
public void setOaName(String oaName) {
this.oaName = oaName;
}
public void setUrlWithSuffix(String urlWithSuffix) {
this.urlWithSuffix = urlWithSuffix;
}
public String getUrlWithSuffix() {
return urlWithSuffix;
}
public void setRealUrl(String realUrl) {
this.realUrl = realUrl.replace("http://","https://");
}
public String getRealUrl() {
return realUrl;
}
@Override
public String toString() {
return "Article{" +
"originalUrl='" + originalUrl + '\'' +
", title='" + title + '\'' +
", oaName='" + oaName + '\'' +
", urlWithSuffix='" + urlWithSuffix + '\'' +
", realUrl='" + realUrl + '\'' +
'}';
}
}
package com.cyf.demo;
import com.cyf.demo.entity.Article;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Demo {
private static final int TIME_OUT = 10000;
public static void main(String[] args) {
String keywords = "疫情";
try {
searchArticle(keywords);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
private static void searchArticle(String keywords) throws IOException, InterruptedException {
String url = "https://weixin.sogou.com/weixin?type=2&query="
+ URLEncoder.encode(keywords, "UTF-8")
+ "&ie=utf8&s_from=input&_sug_=y&_sug_type_=";
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Host", "weixin.sogou.com");
headers.put("Upgrade-Insecure-Requests", "1");
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
Connection connection = Jsoup.connect(url)
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response res = connection.execute();
Document doc = res.parse();
System.out.println(doc);
List articles = getArticles(doc);
articles.forEach(System.out::println);
Map params = getUigsPara(doc, false);
System.out.println(params);
Map cookies = getCookies(res, params);
System.out.println(cookies);
String token = getToken(doc);
approveSearch(res, params, token);
Thread.sleep(2000); // 延时2000ms,模拟搜索之后等一会再点击标题
getRealUrl(res, params, articles);
}
private static void getRealUrl(Connection.Response res, Map params, List articles) throws IOException, InterruptedException {
for (Article article : articles) {
approveOuter(res, params);
String urlWithSuffix = getKH(article.getOriginalUrl());
article.setUrlWithSuffix(urlWithSuffix);
convertUrl(article, res);
Thread.sleep(5000); // 延时5000ms,模拟打开一篇文章后再点开另一篇
}
articles.forEach(System.out::println);
}
private static String getToken(Document doc) {
Elements elements = doc.select("script");
String token = "";
for (Element e : elements) {
if (e.html().contains("var uigs_para =")) {
String temp = e.html().substring(
e.html().indexOf("$.get(") + "$.get(".length(),
e.html().lastIndexOf(")"))
.replace("+", "")
.replace("\'", "")
.replace("\"", "");
token = temp.substring(temp.indexOf("&token=") + "&token=".length(), temp.lastIndexOf("&")).trim();
}
}
return token;
}
private static void approveSearch(Connection.Response res, Map params, String token) throws IOException {
String approve_url = "https://weixin.sogou.com/approve?"
+ "uuid=" + params.get("uuid")
+ "&token=" + token
+ "&from=search";
Map headers = new HashMap();
headers.put("Accept", "*/*");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Cookie", "ABTEST=" + res.cookies().get("ABTEST")
+ ";SNUID=" + res.cookies().get("SNUID")
+ ";IPLOC=" + res.cookies().get("IPLOC")
+ ";SUID=" + res.cookies().get("SUID")
+ ";JSESSIONID=" + res.cookies().get("JSESSIONID"));
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", res.url().toString());
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
headers.put("X-Requested-With", "XMLHttpRequest");
Connection connection = Jsoup.connect(approve_url)
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
System.out.println("search = " + resp.statusCode());
}
private static Map getCookies(Connection.Response res, Map params) throws IOException {
getJSESSIONID(res);
getSUV(res, params);
return res.cookies();
}
private static void getSUV(Connection.Response res, Map params) throws IOException {
String url = "https://pb.sogou.com/pv.gif";
Map headers = new HashMap();
headers.put("Accept", "image/webp,*/*");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Cookie", "SNUID=" + res.cookies().get("SNUID") + ";IPLOC=" + res.cookies().get("IPLOC") + ";SUID=" + res.cookies().get("SUID"));
headers.put("Host", "pb.sogou.com");
headers.put("Referer", "https://weixin.sogou.com/");
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
Connection connection = Jsoup.connect(url)
.headers(headers)
.data(params)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
Map respCookies = resp.cookies();
if (respCookies.containsKey("SUV")) {
res.cookies().put("SUV", respCookies.get("SUV"));
}
}
private static void getJSESSIONID(Connection.Response res) throws IOException {
String url = "https://weixin.sogou.com/websearch/wexinurlenc_sogou_profile.jsp";
Map headers = new HashMap();
headers.put("Accept", "*/*");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Cookie", "ABTEST=" + res.cookies().get("ABTEST") + ";SNUID=" + res.cookies().get("SNUID") + ";IPLOC=" + res.cookies().get("IPLOC") + ";SUID=" + res.cookies().get("SUID"));
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", res.url().toString());
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
Connection connection = Jsoup.connect(url)
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
Map respCookies = resp.cookies();
if (respCookies.containsKey("JSESSIONID")) {
res.cookies().put("JSESSIONID", respCookies.get("JSESSIONID"));
}
}
private static Map getUigsPara(Document doc, boolean hasLogin) {
Elements elements = doc.select("script");
Map params = new HashMap<>();
for (Element e : elements) {
if (e.html().contains("var uigs_para =")) {
String json = e.html()
.substring(e.html().indexOf("{"), e.html().indexOf("}") + 1)
.replace("passportUserId ? \"1\" : \"0\"", hasLogin ? "\"1\"" : "\"0\"");
Map para = new Gson().fromJson(json, new TypeToken>() {
}.getType());
params.putAll(para);
} else if (e.html().contains("uigs_para.exp_id")) {
String[] vars = e.html().split(";");
String exp_id = vars[2];
String value = exp_id.substring(exp_id.indexOf("\"") + 1, exp_id.lastIndexOf("\""));
if (value.length() > 1) {
value = value.substring(0, value.length() - 1);
}
params.put("exp_id", value);
}
}
return params;
}
private static void approveOuter(Connection.Response res, Map params) throws IOException {
String approve_url = "https://weixin.sogou.com/approve?uuid=" + params.get("uuid") + "&token=undefined&from=outer";
Map headers = new HashMap();
headers.put("Accept", "*/*");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Cookie", "ABTEST=" + res.cookies().get("ABTEST")
+ ";SNUID=" + res.cookies().get("SNUID")
+ ";IPLOC=" + res.cookies().get("IPLOC")
+ ";SUID=" + res.cookies().get("SUID")
+ ";SUV=" + res.cookies().get("SUV")
+ ";JSESSIONID=" + res.cookies().get("JSESSIONID"));
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", res.url().toString());
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
headers.put("X-Requested-With", "XMLHttpRequest");
Connection connection = Jsoup.connect(approve_url)
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
System.out.println("outer = " + resp.statusCode());
}
private static void convertUrl(Article article, Connection.Response res) throws IOException, InterruptedException {
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Cookie", "ABTEST=" + res.cookies().get("ABTEST") +
";SNUID=" + res.cookies().get("SNUID") +
";IPLOC=" + res.cookies().get("IPLOC") +
";SUID=" + res.cookies().get("SUID") +
";JSESSIONID=" + res.cookies().get("JSESSIONID") +
";SUV=" + res.cookies().get("SUV"));
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", res.url().toString());
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
headers.put("Upgrade-Insecure-Requests", "1");
Connection connection = Jsoup.connect(article.getUrlWithSuffix())
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
Document doc = resp.parse();
System.out.println(doc);
Elements elements = doc.select("script");
for (Element e : elements) {
if (e.html().contains("var url =")) {
String approve = e.html()
.substring(e.html().indexOf("(new Image()).src =") + "(new Image()).src =".length(),
e.html().indexOf("'&from=inner';") + "'&from=inner';".length())
.trim();
String[] split = approve.split("\\+");
String approveUuid = split[1].replace("\'", "").trim();
String approveToken = split[3].replace("\'", "").trim();
String temp = e.html().substring(e.html().indexOf("{"), e.html().indexOf("}") + 1);
String[] tmp = temp.split(";");
String tempUrl = "";
for (String key : tmp) {
if (key.contains("url +=")) {
tempUrl += key.substring(key.indexOf("\'") + 1, key.length() - 1);
}
}
String realUrl = tempUrl.replace("@", "");
article.setRealUrl(realUrl);
approveInner(res, approveUuid, approveToken, article.getUrlWithSuffix());
Thread.sleep(100); // 仿照搜狗微信的js延时100ms再打开文章
openPage(article);
break;
}
}
}
private static void openPage(Article article) throws IOException {
Map headers = new HashMap();
headers.put("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Host", "mp.weixin.qq.com");
headers.put("Referer", article.getUrlWithSuffix());
headers.put("Upgrade-Insecure-Requests", "1");
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
Connection connection = Jsoup.connect(article.getRealUrl())
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response res = connection.execute();
System.out.println("openPage:" + res.statusCode());
}
private static void approveInner(Connection.Response res, String approveUuid, String approveToken, String urlWithSuffix) throws IOException {
String approve_url = "https://weixin.sogou.com/approve?uuid=" + approveUuid + "&token=" + approveToken + "&from=inner";
Map headers = new HashMap();
headers.put("Accept", "image/webp,*/*");
headers.put("Accept-Encoding", "gzip, deflate, br");
headers.put("Accept-Language", "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2");
headers.put("Connection", "keep-alive");
headers.put("Cookie", "ABTEST=" + res.cookies().get("ABTEST")
+ ";SNUID=" + res.cookies().get("SNUID")
+ ";IPLOC=" + res.cookies().get("IPLOC")
+ ";SUID=" + res.cookies().get("SUID")
+ ";SUV=" + res.cookies().get("SUV")
+ ";JSESSIONID=" + res.cookies().get("JSESSIONID"));
headers.put("Host", "weixin.sogou.com");
headers.put("Referer", urlWithSuffix);
headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
Connection connection = Jsoup.connect(approve_url)
.headers(headers)
.timeout(TIME_OUT)
.method(Connection.Method.GET);
Connection.Response resp = connection.execute();
System.out.println("inner = " + resp.statusCode());
}
private static List getArticles(Document doc) {
List articles = new ArrayList<>();
Elements elements = doc.select("div[class=txt-box]");
for (Element e : elements) {
Article article = new Article();
Element a = e.selectFirst("h3").selectFirst("a");
article.setOriginalUrl("https://weixin.sogou.com" + a.attr("href"));
article.setTitle(a.text());
a = e.selectFirst("div[class=s-p]").selectFirst("a[class=account]");
article.setOaName(a.text());
articles.add(article);
}
return articles;
}
private static String getKH(String url) {
int b = (int) (Math.floor(100 * Math.random()) + 1);
int a = url.indexOf("url=");
String temp = url.substring(a + 4 + 21 + b, a + 4 + 21 + b + 1);
return url + "&k=" + b + "&h=" + temp;
}
}
part 3代码运行后分析
- 很明显哈,结果就是成功的转换了第一页的所有URL
总结
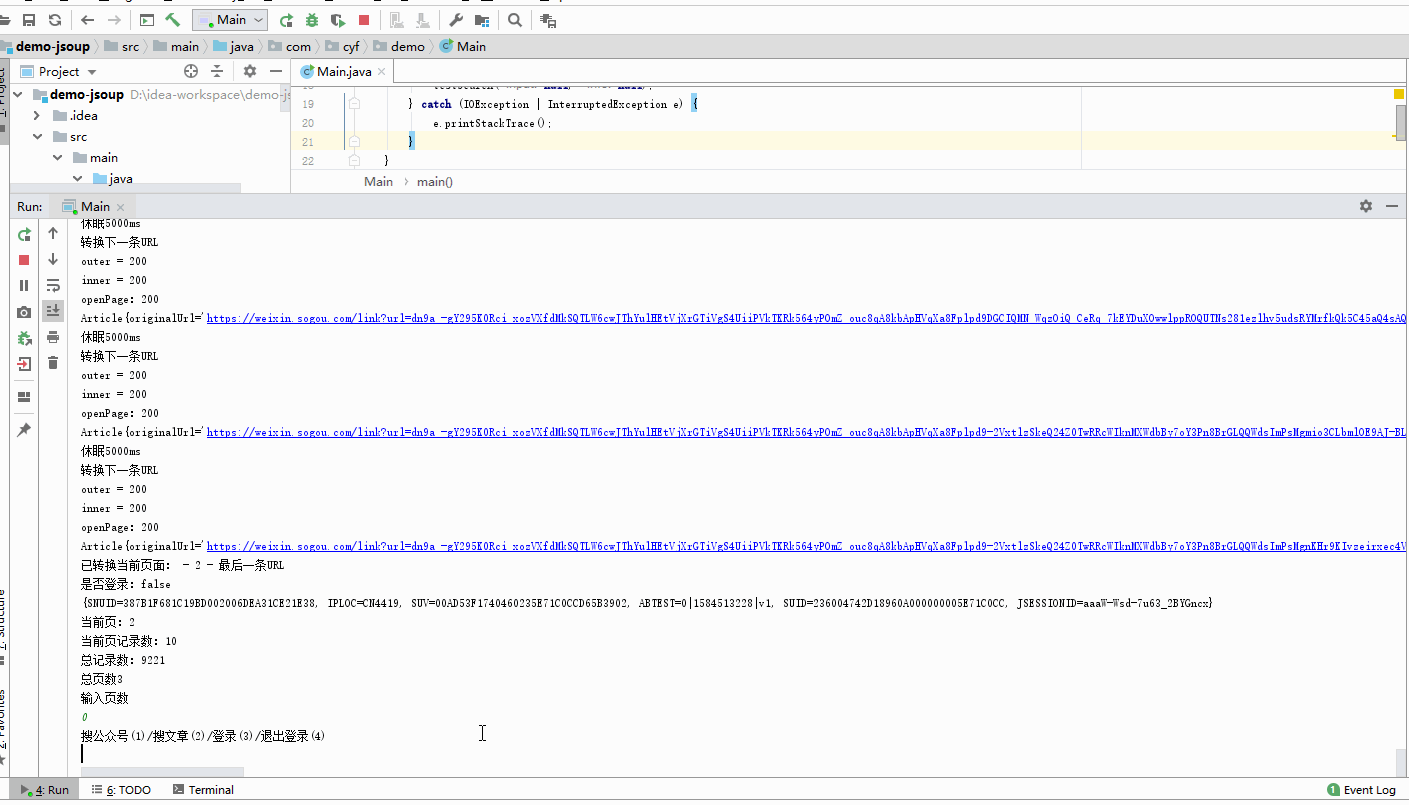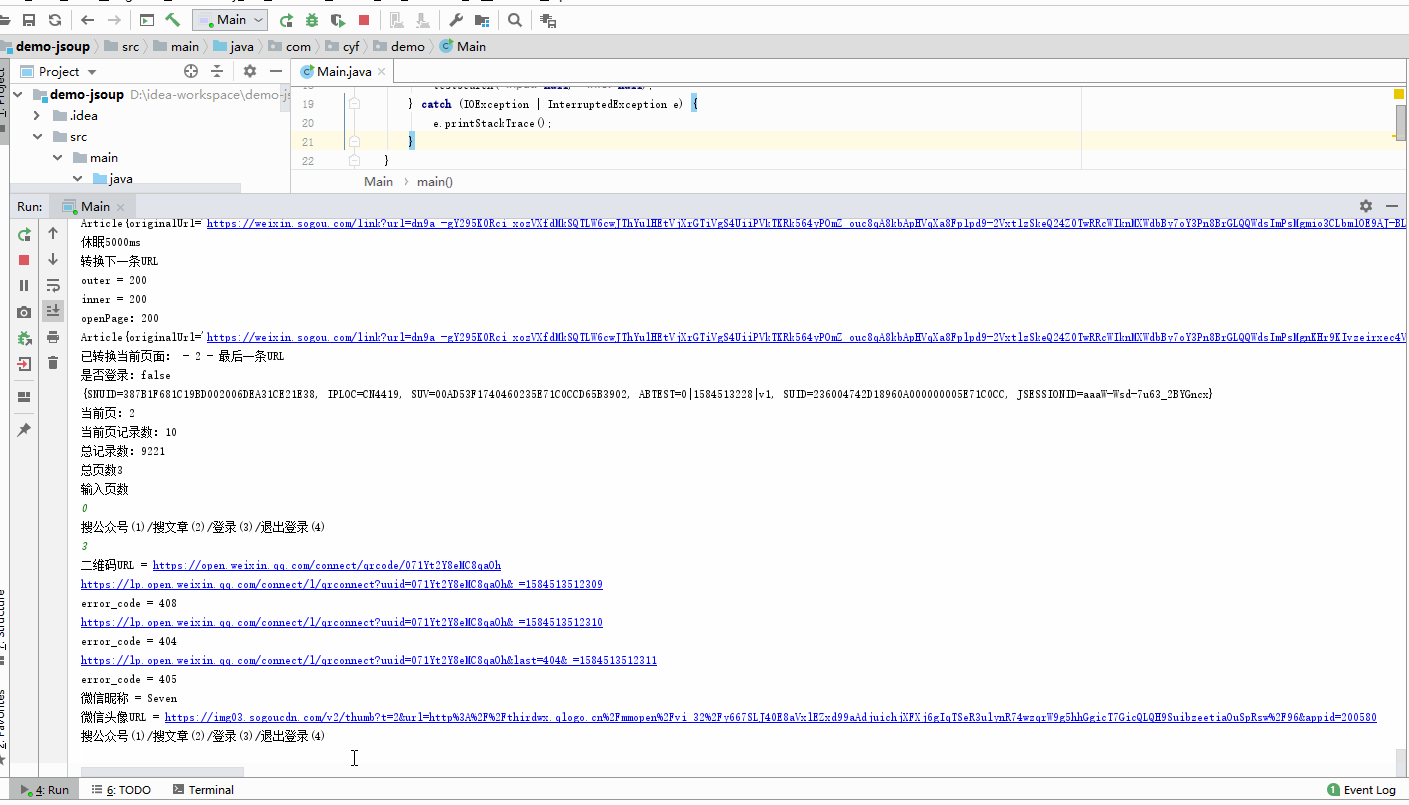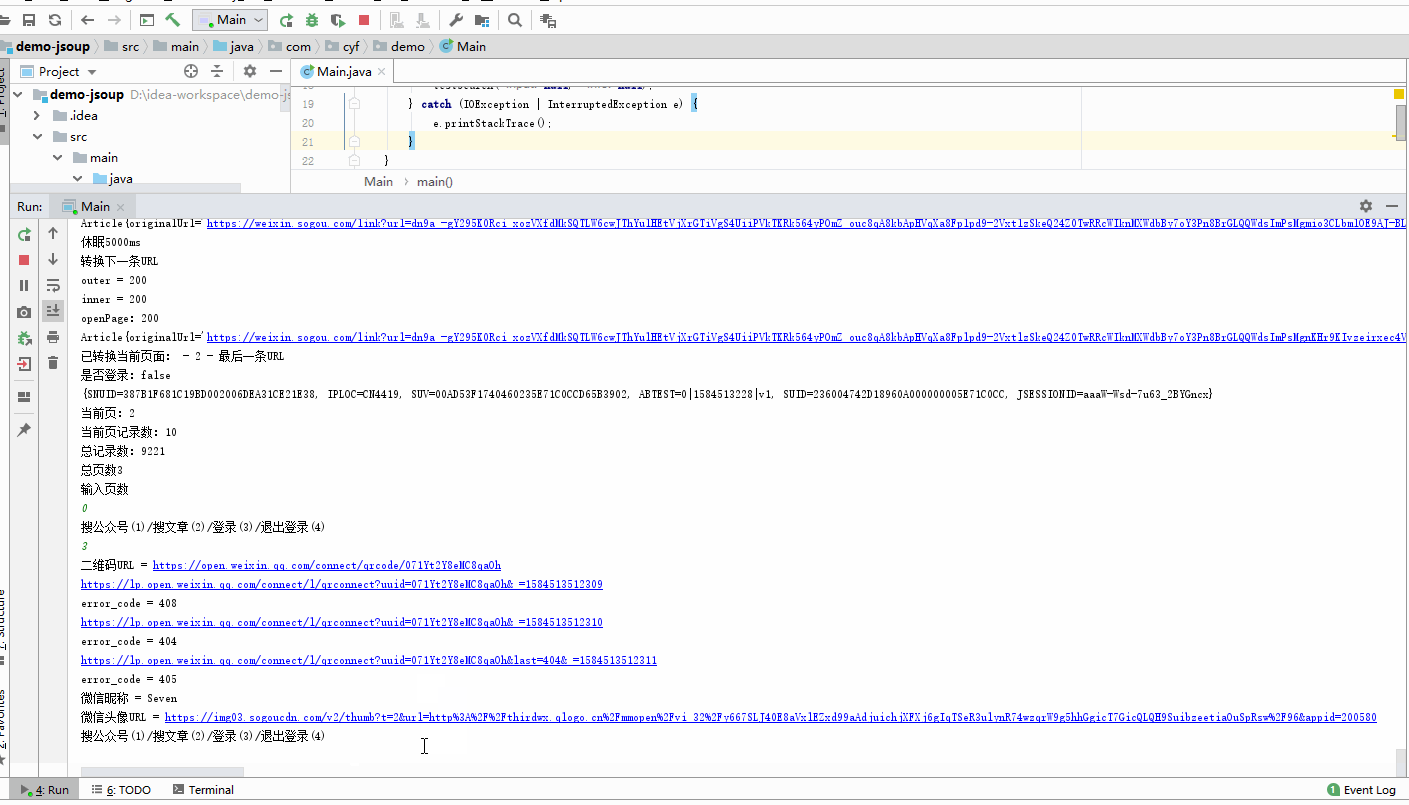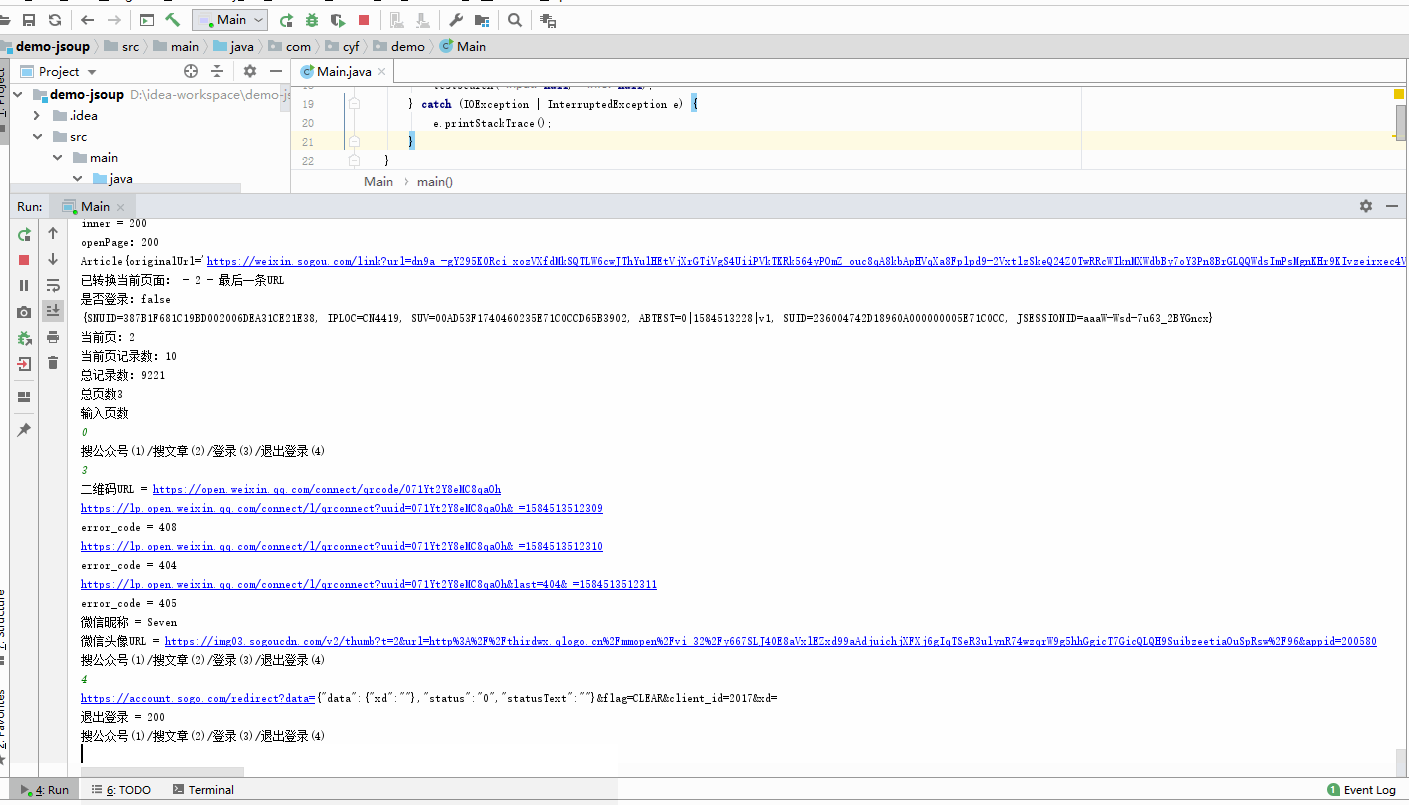
- 通过以上流程的分析,咱们已经实现了获取文章链接的功能(是临时链接哦),继续分析还可以做翻页,未登录最多可以翻10页(如果有这么多数据的话),登录之后就不限制10页,不过最多可以翻多少页不清楚(登录后的cookie不一样);
- 至于搜索公众号信息,以及微信登录,咱这就不分析咯,这一篇分析的篇幅够长了,有兴趣的可以自己按照这篇分析的流程自己摸索一哈,搜索公众号信息的差不太多,至于微信登录,就跟我开头说的,在微信搜狗那个页面清除日志,然后点击右上角的登录,弹出二维码的页面之后就可以分析了;
- 在爬虫领域,还有很多有意思的事情,譬如图片验证码、拖动拼图验证,有反爬,有反反爬,数据分析,市面上也有很多公司是专门做这个的,大数据时代,数据就是基石,利用数据,可以做很多有意义的事情,而Python语言在这方面真的是得天独厚,相比起JAVA来,代码量可以减少很多去实现同样的功能,我在前期调研需求的时候发现,文章基本都是用Python来实现的,我虽然也自学过Python,但是,才学了一些基本的东西就因为各种原因搁置了,想想也是浪费。。
- 最后,我要录个gif图,来演示一下我写的demo,然后打包上传一份代码,如果各位看这篇文章的时间不算久远的话,应该是还能用起来的。
- 搜公众号信息
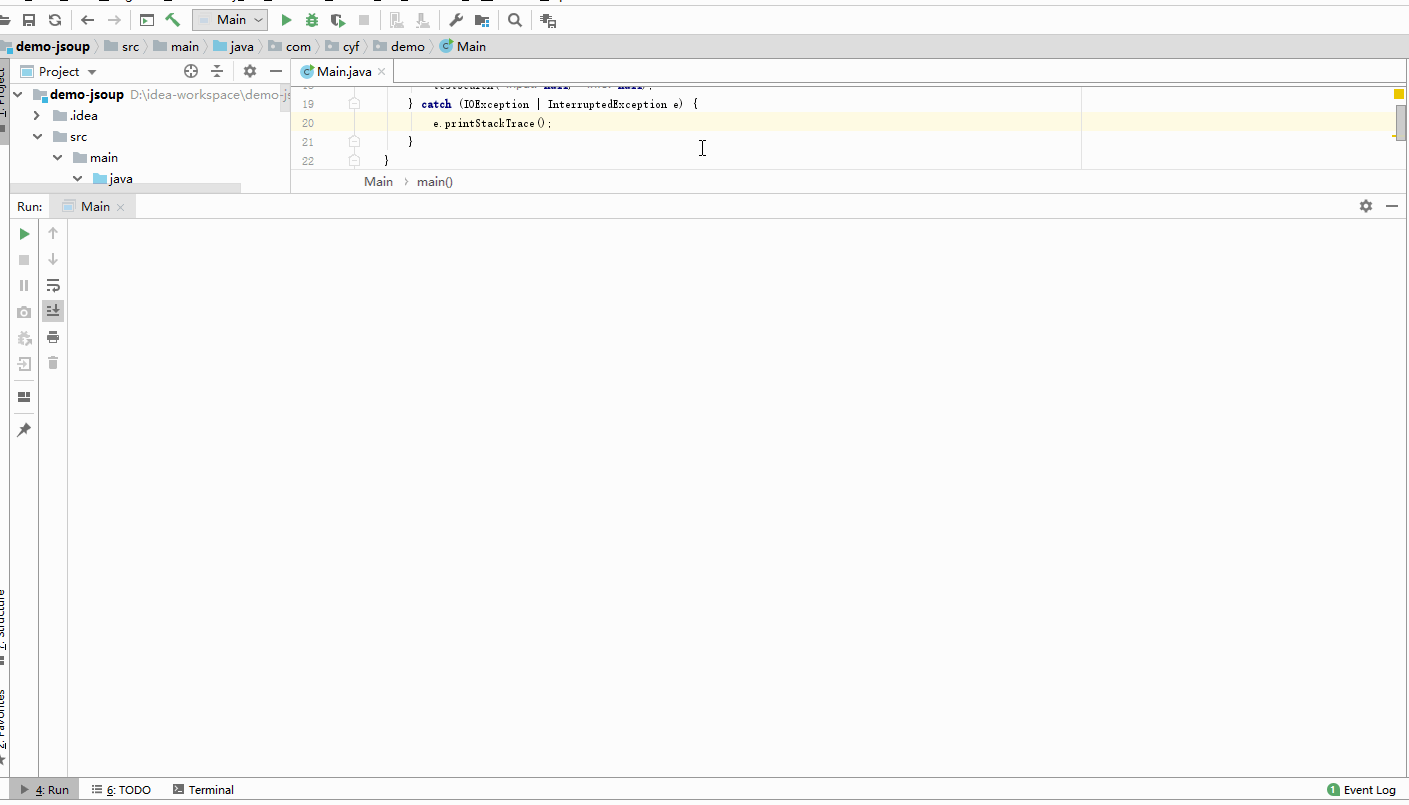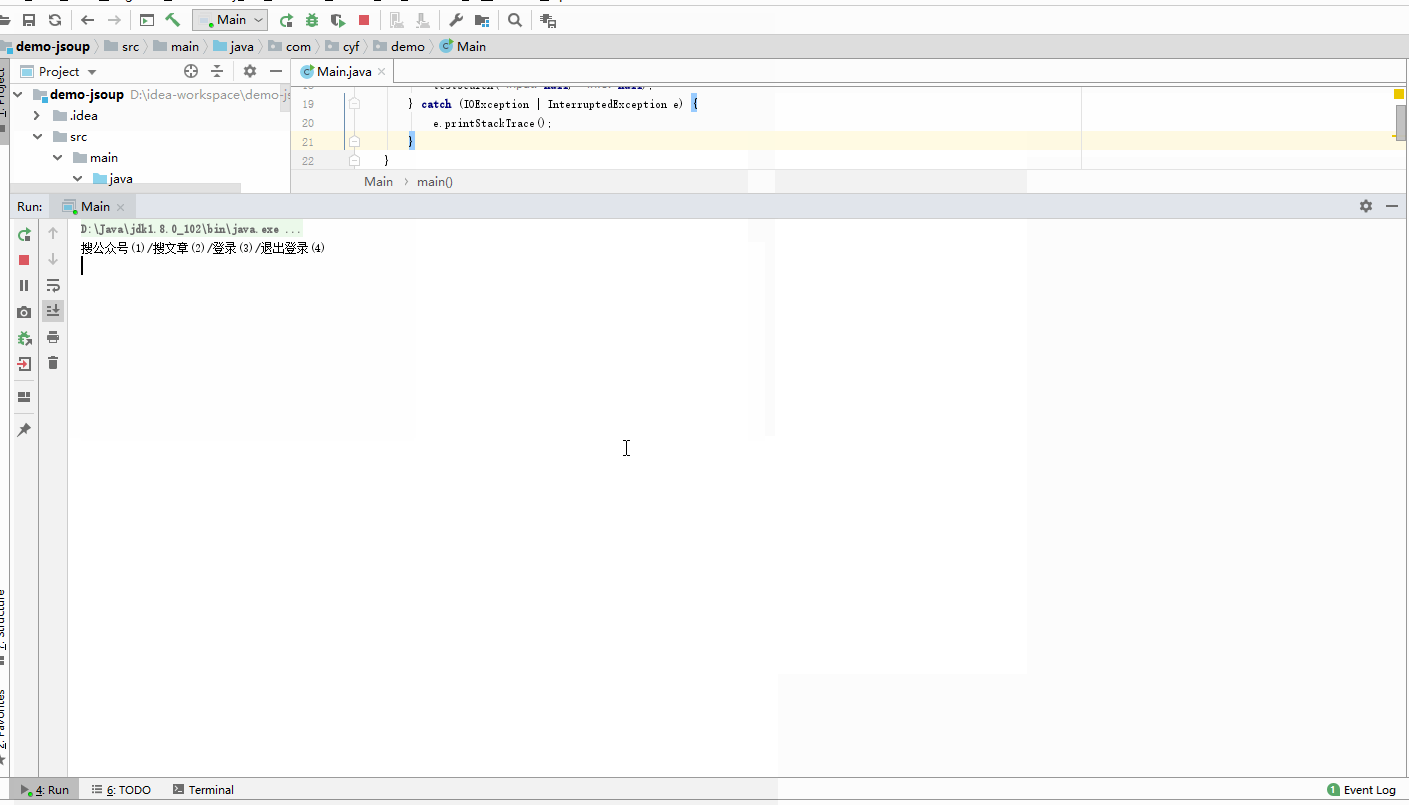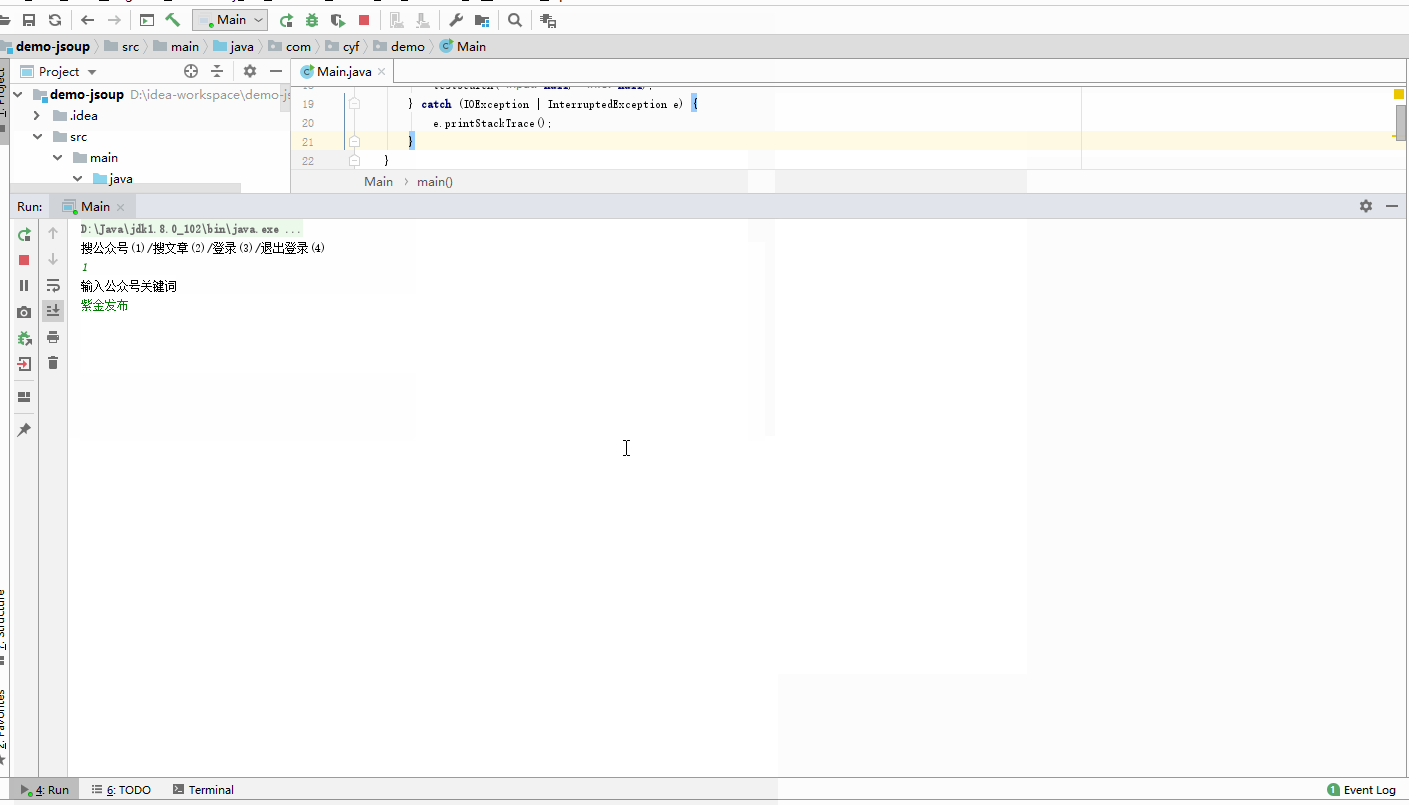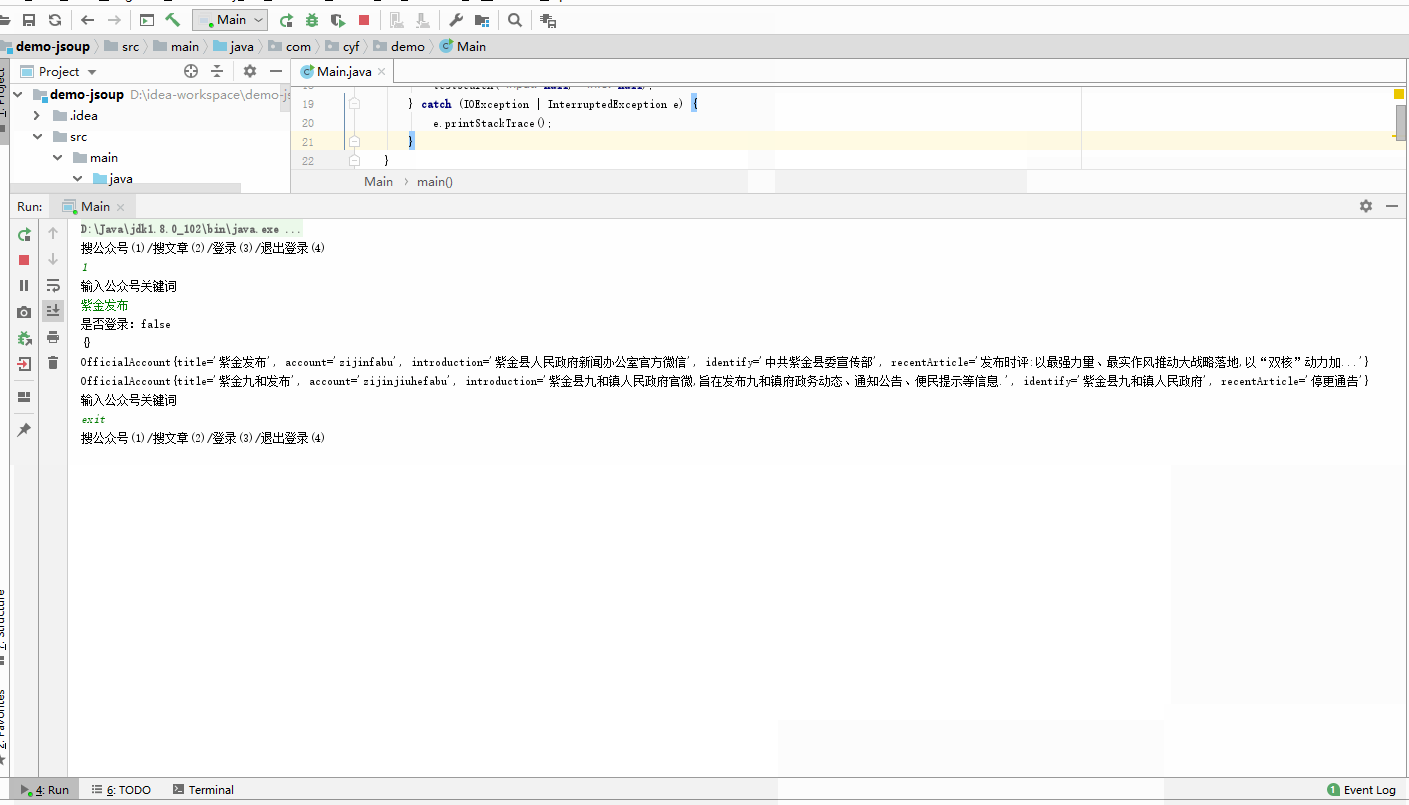
- 搜文章(翻页)
- 登录、登出