三维城市:深度学习三维应用
在这篇文章中,我们将继续探索深度学习模型如何应用于从三维空间数据中,并从中提取信息的方式,特别是在大型地理区域,3D建筑模型重建情况下 - 从个别城市到整个区域。
地理信息系统的三维信息并不新鲜:多年来,有一些领域,空间坐标都被认为是必不可少的:气候学,海洋学,地质学,建筑学,公用事业网络等。如今,城市的3D模型也是如此。 这些模型正在迅速被采用,并被认为是城市设计,活动规划,维护,安全和保障,灾害响应,人群控制和保险等决策的宝贵资源。
那么,哪些原始数据源可用于重建城市的3D模型? 有哪些工具和工作流程? 在哪个方向进一步探索? 我们将在下面探讨并找到这些问题的答案。
与之前的多个深度学习项目一样,我们与NVIDIA合作进行了以下实验,NVIDIA提供了具有32GB内存的高端QUADRO GV100卡 - 适合大型小批量生产,用于高效训练大规模Mask R-CNN和PointCNN网络。
Realism & Cubism
在深入研究技术细节之前,让我们宏观梳理,看看主体的需求和方法的概览。
理想情况下,我们希望数字模型与真实的城市变得无法区分:从汽车到建筑物的细节和纹理的高端保真度,道路裂缝,每棵树上的树叶,理想的定位和每个烟囱管道的高度以及每个天窗窗把手。 然而,在第二个想法中,由于计算要求,获取所需的时间以及维持模型现状的未来资源消耗,这种详细程度虽然在理论上是可能的,但似乎是不实际的。
因此,出于所有实际目的,3D建筑模型通常分为两大类:高保真和框架图。 进入高保真类别主要是历史建筑的模型,这些模型看起来是固定的,受法规保护,甚至被列入联合国教科文组织世界遗产名录。 高保真建筑模型需要大量的初始投资,但一旦创建,只需要很少和稀疏的更新来反映对原始模型的偶尔修复。

另一方面,城市的所有其他部分:商业,住宅,工业区,经常进行开发,重建,扩建,重新分区,即每天发生变化。 这些变化必须定期反映在城市的数字模型中,并在准确性,速度和成本之间进行合理的权衡 - 试图最大化速度/成本比,同时不要让精度下降。 这是我们将放在这篇文章的其余部分的重点。
但是,为什么我们需要对原理图类别的建筑模型进行快速,定期和经济有效的更新? 一个特别突出的原因是,这个城市的这些地方经常在商业和夜间容纳大多数人口。 如果遇到灾难,如地震,快速更新模型,并将其与事件发生之前的状态进行比较,将为救援人员提供一个强大的工具,以查看损害发生的最严重程度,以及有多少人在 通过计算倒塌楼层的数量,丢失的平方英尺,估计碎片数量等来影响受影响的区域。
Data Sources
有两种主要数据源可用于采集各种尺度的3D建筑模型:使用机载或地面激光雷达,以及通过Structure-From-Motion算法计算的3D三角网格和使用倾斜图像的摄影测量过程。 前者是一种较老的,成熟的技术,通常需要相当昂贵的传感器。 LiDAR扫描的产物是未分类的三维点云,其中每个点还可能包含许多其他属性,如强度,红绿蓝值等。后一种技术,结构从运动中获得,允许重建连续的3D网格。 网格是由飞机或无人机飞过城市拍摄的一系列倾斜图片计算得出的,并保留了详细的轨迹信息。 这种连续网格通常由数百万个互连的三角形构成,并具有相关的高分辨率RGB纹理。
You can construct 3D meshes using Drone2Map for ArcGIS extension. To learn more: https://doc.arcgis.com/en/drone2map/
两个来源都有一个共同的问题:不知道哪些点(在LiDAR点云中)或三角形(在网格中)属于建筑物,地面,树木,水体,汽车等......它们是 只是原始未分类的XYZ点,或具有RGB纹理的大量连接三角形。
LiDAR Point Clouds

我们进行实验的航空LiDAR点云具有相对较高的密度:平均每平方米约15-20个点。 需要这样的点密度以在输入数据中获得足够强的信号,因此可以更快地训练神经网络并且具有更少数量的示例以获得更高的准确度。 原因在于源点云的局部邻域中的统计特性携带有价值的信号,对于神经网络而言,该信号是允许其区分云中存在的各种对象类的关键。 因此,云越分散,信号变得越模糊,迅速导致需要指数级更大数量的训练样本来学习。
光栅化点云中的实例分割
我们写了关于我们在2018年与迈阿密 - 戴德县进行的试点项目。在该项目中,我们尝试优化现有的和完善的重建3D建筑模型工作流程的一个步骤,这需要手工数字化建筑部分。 栅格化点云中七种不同的屋顶类型。
简而言之,传统的工作流程很简单:
1.点云被转换为光栅,其颜色通道存储每个像素的LiDAR点的平均高度。
GIS工程师在步骤#1栅格顶部手动数字化屋顶段多边形:平面,山墙,尾部,棚屋,圆顶,拱顶和楼宇。
ArcGIS 3D Analyst扩展工具和CityEngine程序规则用于从屋顶段多边形中提取原理图类型的建筑模型。
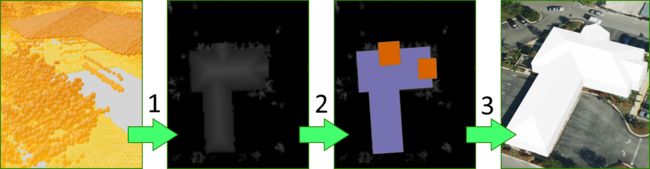
Overview of the Miami-Dade project: https://www.esri.com/arcgis-blog/products/product/3d-gis/restoring-3d-buildings-from-aerial-lidar-with-help-of-ai/
More technical details with code snippets: https://medium.com/geoai/reconstructing-3d-buildings-from-aerial-lidar-with-ai-details-6a81cb3079c0
GIS工程师正在使用的原始栅格化点云手动数字化屋顶段,使用LAS数据集转栅格地理处理工具计算,单元格大小为每像素2.25平方英尺。 结果是单通道二维光栅,其中伪彩色通道表示每个像素的高度,因此称为数字表面模型(DSM)。 您可以在此处找到有关从点云创建此类曲面的更多详细信息。
从数字表面模型数字化各种屋顶部分的手动过程非常缓慢且是工作流程中最昂贵的部分,因此想法很简单:训练Mask R-CNN神经网络,至少帮助屋顶部分 从DSM栅格中提取。
但在我们开始训练模型之前,需要对输入数据进行一些额外的预处理。 原始DSM对包括地面高程的高度值进行编码,因此,如果按原样馈送到掩码R-CNN,则需要大量的训练示例以使网络地形不变。 不幸运的是,我们没有这么多的例子,所以我们将原始的DSM转换成了所谓的标准化数字表面模型(nDSM)栅格,其中减去了地面高程(数字地形模型,DTM):
进一步阐述这个公式
1、我们按照上面的描述计算了DSM。
2、源点云通过Classify LAS Ground地理处理工具将其点分类为地面/非地面。
3、LAS数据集到栅格工具用于从仅使用Ground类过滤的分类点云创建数字地形模型。
4、通过运行Spatial Analyst's Minus工具计算标准化DSM(nDSM):nDSM = DSM - DTM。
一旦nDSM准备就绪,我们导出训练数据,使用深度学习地理处理工具来创建由nDSM和屋顶段多边形组成的训练集,这些多边形由Miami-Dade GIS工程师手动数字化。 虽然独特训练图块的数量仅约为18,000,但数据增强和额外的伪颜色转换使Mask R-CNN获得了令人印象深刻的效果,显着提高了传统工作流程的效率(您可以阅读有关数据增强和伪的更多信息,上述第二篇文章中的颜色转换)。
将Mask R-CNN结果导入ArcGIS Pro之后,我们需要用来回到传统工作流程的唯一附加工具是规则化建筑物足迹,以几何方式转换预测的屋顶段多边形,使它们具有正确的 和人造结构典型的对角线角度。
在正规化之后,基于程序规则的生成的结果可以在下面的实时3D WebScene中看到。 需要强调的是,没有对任何输入或中间数据进行手动编辑,也不对最终的建筑外壳进行手动编辑。 同样重要的是,下面的WebScene所涵盖的区域属于所谓的测试区域,即模型处于训练中时Mask R-CNN模型未看到的区域。
Resulting schematic building models: https://arcg.is/1jvDO00
正如您可能已经注意到的那样,这些模型并不总是完美的,但这是生产力的巨大跳跃,并且降低了DSM级别需要手工劳动的基线工作流程的成本:现在,GIS工程师可以执行剪裁 - 根据需要调整所提出的3D模型,而不是手动数字化每个屋顶部分。
而且,正如在深度学习的世界中经常发生的那样,您可以通过提供更多的训练样本来更好地进行Mask R-CNN预测。
Semantic Segmentation in Raw Point Clouds
在上一个带有栅格化点云的示例中,由于多种原因,我们被绑定到预定义的工作流:一个是在将深度学习引入流程之前和之后比较。 但我们是否可以在原始点本身内执行类似的实验,而无需初步转换为DSM? 我们能找到一个类似的工作流程,它可以为我们提供一个比较和改进的良好基线吗?
事实证明我们有一个:使用RANSAC算法从原始点云重建3D建筑模型的另一个完善的过程。 如果在ArcGIS Pro中执行,整个工作流程将逐步显示如下:
首先,我们为统计上看起来像地面的点(第2类)和建筑屋顶(第6类)分配适当的标签:
- ClassifyLASGround, if ground has not been already classified.
- ClassifyLASBuilding.
接下来,我们将点云光栅化并将其矢量化为6级(建筑物)点下的多边形。 然后,我们应用建筑物足迹正则化算法,将最合适的形状与右角和对角线拟合到初始多边形中:
- LASPointStatisticsAsRaster,在第6类(建筑物)上过滤LAS层,并使用“最常用的类代码”选项.
4.关闭“简化多边形”选项的 RasterToPolygon.
5.EliminatePolygonPart去除小孔(可以通过步骤#3栅格上的形态操作来完成).
6.RegularizeBuildingFootprint以理顺事物.
最后,我们使用2级(地面)点计算局部地形栅格,并运行RANSAC在建筑物覆盖区,DEM和6级(建筑物)点之上构建三维壳体:
LASDatasetToRaster在第2类(地面)点上过滤输入LAS层以制作DEM.
LASBuildingMultipatch构建实际的shell.

乍一看,结果看起来很不错。 但是,一旦我们检查出最近的建筑物外壳,我们可能会发现相当高的噪音水平和大量的微小三角形对每个外壳造成影响,这使得这些建筑模型不适合进行进一步的手动微调/编辑。
但这个三角形噪音来自哪里? 其中一些可归因于不均匀的点云密度和LiDAR扫描仪灵敏度,另一个可归因于上述步骤#1和#2中发生的点的错误分类,尤其是在分类LAS建筑物工具内部。
Classify LAS Buildings工具必须执行一项非常复杂的任务,即确定点云的哪些点看起来是来源于建筑,哪些不是。 在完美的世界中,当它是一个平坦的四面立方结构,在一个完美平坦的地面上很容易......但在现实世界中,建筑物往往有复杂的屋顶形状,屋顶窗,烟囱管,舞台地板等附近 树木覆盖了结构的一部分,所有这些都位于复杂的阶梯状地形上。
在如此复杂的环境中,难怪Classify LAS Buildings工具经常错过建筑点或将它们与实际属于树木,灌木丛,地面,停放在附近的汽车等的其他点混合在一起。
与此同时,原始的LiDAR点云包含数十亿个需要按照这种方式进行分类的点 - 所有这一切听起来像神经网络要完成的完美任务,不是吗? 或者,为了更加精确和实用,我们是否可以训练深度学习模型来比现有的确定性算法更有效地标记未分类的点云?

好吧,当我们在如云的稀疏无序空间中谈论深度学习时,存在一些严峻的挑战 - 我们不能将传统的和众所周知的卷积神经网络应用于它们:
...点云是不规则和无序的,因此直接将内核与点相关联的特征进行卷积,将导致形状信息的抛弃和与点排序的差异。
https://arxiv.org/abs/1801.07791
尽管如此,虽然比传统的计算机视觉领域探索得更少,但点云深度学习分析受益于最近机器人技术,自动驾驶汽车和SLAM的爆炸式增长,其中LiDAR传感器起着关键作用。 另一个帮助来自Graph Convolutions,它被设计用于类似图形的数据结构,如社交网络 - 在某些条件下可以减少点云以适应这种结构。
在对该主题的最新出版物进行一些研究之后,我们决定为实验选择PointCNN实现,因为在许多常见基准测试中,这一实现可以达到最先进的结果。 PointCNN背后的核心思想围绕多点感知器在点云内局部固定大小邻域上的多次通过应用,将最初的稀疏特征提升为密集的潜在特征空间,传统的卷积可用于进一步处理。
虽然相当紧凑,只有大约350万个可训练参数,但在使用32GB GPU内存的单个NVIDIA QUADRO GV100进行6.5小时训练后,PointCNN模型在验证集上达到了0.97的准确度。 训练集由荷兰开放式LiDAR数据集的一个子集(仅覆盖阿姆斯特丹,总共1.8B点)构建,每平方米平均密度约为18个点。 测试是在附近的乌得勒支市进行的,来自同一个数据源。
虽然荷兰点云最初被分类的方式对我们来说是未知的(甚至是算法,还是手工劳动?),我们训练的PointCNN模型在区分建筑和非建筑类时表现出了令人印象深刻的结果。 测试集,在大多数情况下超过传统的分类LAS建筑工具的结果。
同样令人着迷的是,PointCNN仅在XY-Zs上训练(没有强度或RGB,也没有任何其他属性),这意味着该模型能够有效地学习特定于不同类别对象的空间分布的属性,并且至少是,类之间的界限。



[图片上传失败...(image-1f6a8-1552904798019)]
这是从Utrecht测试装置标记风车的PointCNN模型的另一个令人惊讶的例子。 我们不确定是否训练集中有风车,但即使有一些风车,与其他建筑类型相比,训练数据中的风车数量可以忽略不计。 换句话说,从分类的角度来看,存在巨大的阶级不平衡,这将困扰传统的分类器,如Mask R-CNN。 这个非凡的案例展示了PointCNN学习复杂空间分布属性的能力,这些属性特定于特定大小和比例的一般人造物体(例如,测试集中的汽车被正确地从建筑类中丢弃,因为不够高)和 显然,风车符合学习标准。
一个很好的例子说明了PointCNN模型如何依赖于点邻域的高度以及它与近垂直平面的相似程度,可以在Utrecht测试集的下面部分错误分类的高大船上看到:
好吧,在我们成功训练了一个PointCNN模型并用它标记了乌特勒支测试点云的地面和建筑点之后 - 它如何影响最终的建筑模型重建? 这是答案 -
上面的动画显示了在同一点云上执行的两个相同工作流程(如本章开头所述的步骤)的结果。 唯一的区别在于步骤#1和#2:在第一种情况下,建筑物和地面点由传统的确定性算法标记,而在第二种情况下 - 由PointCNN模型标记。 如您所见,后一种建筑外壳的噪音水平要低得多,特别是在靠近建筑物的植被区域。
3D Meshes
看起来我们对PointCNN和LiDAR Point云有一些令人鼓舞的结果,不是吗? 但是前面提到的原始3D数据的另一个来源是来自Structure-From-Motion算法,并且由于获得的成本要低得多,因此它正在普及。 这个数据源的另一个显着优点是它带有高分辨率RGB纹理,可以立即精确地连接到三角网格上! 所以,问题是:我们能否将之前的成功扩展到三维连续网格中?

Semantic Segmentation in 3D Meshes
原始3D网格的主要问题是它代表一个连续的三角形表面 - 数百万个三角形相互连接。 对于人类,尤其是当高分辨率RGB纹理应用于网格时,很明显哪些三角形属于建筑物,哪些三角形属于地面,树木,灯柱,汽车等。但是我们没有这些属性与 来自Structure-From-Motion管道的三角形面,当我们谈论建筑物的平方英尺估计时,这使得原始网格无用。 同样,要么采用复杂的确定性算法,要么通常采用手动分割来解决这个问题。
然而,看起来我们有很好的机会在这里取得成功......,使用相同的PointCNN! 这个想法很简单:用固定分布(甚至蒙特卡罗似乎正在工作)对网格进行采样以生成合成点云,然后只要求PointCNN标记它。 最后,将生成的标签应用回源网格的三角形面,就是这样:我们得到一个分段的3D网格!
有人可能会说在实践中工作听起来太好了,但这里有一些合成点云的例子,它是通过蒙特卡罗点采样从网格中产生的:
当然,结果并不理想,但这里是最令人惊讶的部分:分割是由相同的PointCNN模型进行的,该模型在阿姆斯特丹真正的LiDAR点云上进行训练,点密度非常不同,每个点的点分布特性不同, 即使是不同的建筑风格(这是来自荷兰以外的城市)。
这确实令人鼓舞,因为几乎可以保证PointCNN模型首先在合成点云上进行训练,将使用相同的采样技术对采样的网格进行分割。 此外,从三角网格中采样的合成点云将具有RGB等附加属性,以及采样的面法线向量,这将有助于PointCNN学习正确的分割规则。
Mask R-CNN and PointCNN: be careful with…
由于它经常发生在深度学习的复杂世界中,Mask R-CNN和PointCNN网络都倾向于从训练数据中学习一些不期望的语义,导致偏差并使它们更难以转移到其他地理位置或传感器模型。 与传统的确定性算法相比,这是它们的缺点。
我们通过将训练的模型移动到其他数据源和地理位置完成了一些实验,这里是一个简短的偏差列表,通常由两个网络在上述工作流程中使用时选取。 并不是一个完整的清单,但仍然是最值得关注的事情:
MASK R-CNN灵敏度/偏差:
建筑风格。
LiDAR扫描仪:点密度。
PointCNN灵敏度/偏差:
LiDAR扫描仪:点密度,强度,RGB一致性。
分割3D网格时的采样技术。
并且,正如之前已经提到的,减少神经网络中的偏差的最佳方法是将更多的训练样本带到桌面上 - 只要网络的“心智能力”(可训练参数和架构的数量)允许。 甚至是合成数据:例如,如果我们没有足够的LiDAR覆盖范围用于给定的地理,建筑风格或传感器类型 - 可以使用ArcGIS Pro和CityEngine程序生成的3D内容构建合成训练样本,其中包含有价值的内容 我们试图教导模型提取的信号。
Voxels and future work
我们不断尝试各种深度学习架构,以便找到最适合各种行业,用例和环境的架构。 另一个令人兴奋的DL模型系列在我们正在积极探索的体素空间中工作。 以下是Esri数据科学家David Yu的最新消息:
虽然通常通过将不同的倾斜视图拼接在一起来创建3D场景,但是探索的一个想法是从单个2D图像生成3D模型的可能性。 这可以实现,并且已经过DCGANS的有限成功测试,DCGANS将变分自动编码器生成输入嵌入层。 这种方法需要为每类3D物体(例如汽车,树木,灯柱,栅栏等)安装一个独特的模型,以使输出具有足够的变化,但也保持了该类的一般形式的保真度。 通过这种方法,3D DCGAN与来自俯视镜头的潜在矢量相结合足以在3D中重建对象的独特属性。

选择对象的体素表示,因为虽然可以将生成模型的输出表示为网格(AtlasNet)或甚至点云(PC-GAN)。 直观地扩展原始GAN网络以产生3d网格输出(体素)而无需重新设计网络。 来自ShapeNet等图书馆的体素训练数据的高可用性使这一过程变得简单而轻松。 此外,当涉及表示不规则和非均匀填充的对象时,体素形状是没有显式坐标的点的集合具有某些优点,例如置换不变性和存储效率(与网格相比)。 然而,当涉及简单对象或更高分辨率的对象时,体素表示非常占用内存,这就是为什么它更适合生成特定类别的对象而不是整个场景的原因。

在架构方面,该模型有效地合并了两个众所周知的网络:变分自动编码器(VAE)用于从3D对象的开销镜头生成1D嵌入向量。 然后,在充当GAN发生器的输入之前,将该潜在矢量与噪声连接。 生成器生成其自己的体素模型并将其传递给鉴别器,鉴别器尝试将生成的输入与实际输入区分开,然后将错误传播到生成器。 截至目前,这种架构能够产生不错的结果,但未来的扩展可能包括将颜色编码结合到体素输出以及将标准化流引入噪声之前,以便模拟更不易受模式影响的更复杂的分布坍方。
以下列出了我们目前正在开展的其他相关举措 - 我们会及时向您通报最新进展情况。
1、PointCNN不仅可以用于建筑物分类,还可以用于其他更复杂的点分类任务,例如标记电力线和相关设备,铁路设备,隧道内的电信设备等。换句话说,在使用确定性的区域 标记算法是有限的,或根本不存在。
2、Mask R-CNN方法需要大量的训练样本。 我们正在制作CityEngine脚本,这将有助于合成培训样本创建的自动化。
3、Building Footprint Regularization tool 将得到改进。
4、RANSAC重建壳的简化工具。
译自:3D cities: Deep Learning in three-dimensional space