分布式一致性原理
1.CAP定理:一个分布式系统不可能同时满足一致性(C),可用性(A)和分区容错性(P)这三个基本需求,最多只能同时满足其中的两项。
2.2PC:
Prepare(投票);Commit(事务提交),中断Rollback(事务回滚)
优点:原理简单,实现方便
缺点:同步阻塞,单点问题,脑裂(主从数据不一致)、保守(协调者超时机制判断是否要中断事务)等
案例:
1.引申:淘宝TCC 分布式事务框架(Try-Commit-Cancel)
2.应用:交易柔性分布式事务处理框架(Horcrux)。基于 Try-Commit 阶段 RPC 处理;Commit-Failure 与Cancel-Failure 采用超时机制(Activity 表超时处理);对于 Cancel 与Timeout 采用 Spark Streaming/Storm+MQ+Dubbo 实现异步补偿与回滚。
3.3PC:事务询问(CanCommit);执行事务预提交(PreCommit);执行提交(DoCommit),中断 Rollback。
存在问题:协调者故障,或者协调者与参与者之间网络故障,此时通过参与者超时机制,继续提交事务。
优点是降低了参与者的阻塞范围,能够在先单点故障后继续达成一致。
缺点是在参与者接收到预提交消息后,如果网络出现分区,此时协调者所在的节点和参与者无法进行正常的网络通信,在这种情况下,该参与者依然会进行事务提交,这必然出现数据的不一致性。
Paxos描述
参见链接:Paxos定于与描述
ZAB协议
1.ZAB架构设计
Architecture of ZAB – ZooKeeper Atomic Broadcast protocol
2.ZAB 与 Paxos比较
ZAB vs Paxos
ZAB集群机器越多,写性能会有所降低、读性能得到水平扩展。然而基于Paxos实现的Chubby读写相对ZK复杂。
同时ZK的每一个操作都具有隐形事务要求,通过强一致性保证数据节点的数据的顺序性(FIFO)。Paxos协议无法实现多个写操作的顺序性,或者通过串行操作实现,如此则以牺牲效率为代价。
ZooKeeper应用
1.ZK可以实现发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
发布/订阅模式:
在处理自定义事件时,观察者模式和发布/订阅模式经常使用,起初不了解这两个模式的实现时,在网上看一些资料,很多介绍都将两种模式混淆在一起,认为他们是同一个模式、一样的实现。后来看了一些设计模式的书籍,感觉两种模式还是有本质的区别,具体如下:
观察者模式至少需要维护两个对象
顾名思义:有观察者对象,肯定也得有观察者需要关注的目标对象,在观察者模式实习的时候,观察者对象需要定义一个统一的接口,在目标对象发生某些改变时,调用(触发)观察者的对应的方法,通知观察者到底发生了那些变化。
而发布订阅模式,只需要注册订阅器上的一个事,而订阅器发生某些事件,则会触发事件通道里面的函数,触发器并不会关心其他任何对象和任何接口
在实现自定义事件方面我觉得使用发布/订阅模式更为合适,简单、耦合性比较低。使用发布订阅模式时,我们关注那个对象,只需要在这个注册这个对象的对应的事件即可,降低了订阅者和发布者直接的耦合。
负载均衡:
本质是利用zookeeper的配置管理功能
步骤为:
服务提供者把自己的域名及IP端口的映射注册到zk中
服务消费者通过域名从zk中获取到对应的IP及端口,这个IP及端口有多个,只是获取其中一个
当服务宕机时,对于的域名与IP的对于就会减少一个映射
命名服务:
Zookeeper 的 Name Service 与 JNDI 能够完成的功能是差不多的,它们都是将有层次的目录结构关联到一定资源上。也许你并不需要将名称关联到特定资源上,你可能只需要一个不会重复名称,就像数据库中产生一个唯一的数字主键一样。
分布式协调/通知:
通过watcher的通知机制实现
通过 watcher 实现分布式数据的发布/订阅功能
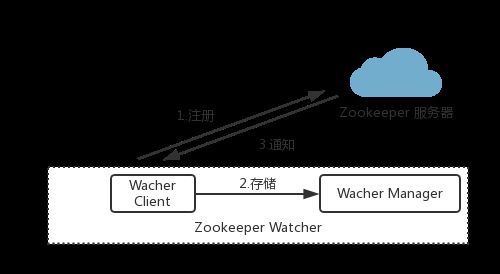
watcher 包括客户端线程,客户端 WatcherManager , Zookeeper 服务器三个部分
客户端在向 zk 服务器注册 watcher 的同时,会将 watcher对象存储在客户端的WatcherManager 中,当 Zookeeper 服务器端触发 Watcher 事件后,会向客户端发送通知,客户端线程从 WatcherManager 中取出对应的 Watcher 对象来执行回调逻辑。
分布式锁:共享锁,排他锁
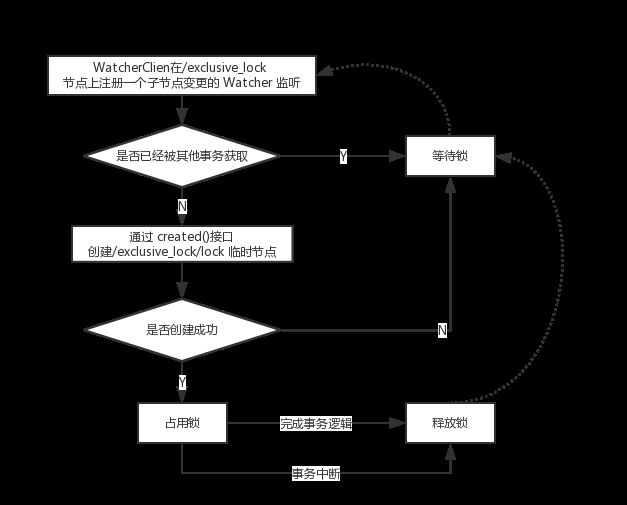
排他锁(Exclusive Locks)
引申:又成为写锁或独占锁,Java 中使用 synchronized 机制和 JDK5提供的 ReentrantLock 定义锁,数据对一个事务可见。
Zookeeper 使用数据节点(ZNode)表示一个锁,即只存在/exclusive_lock/lock。
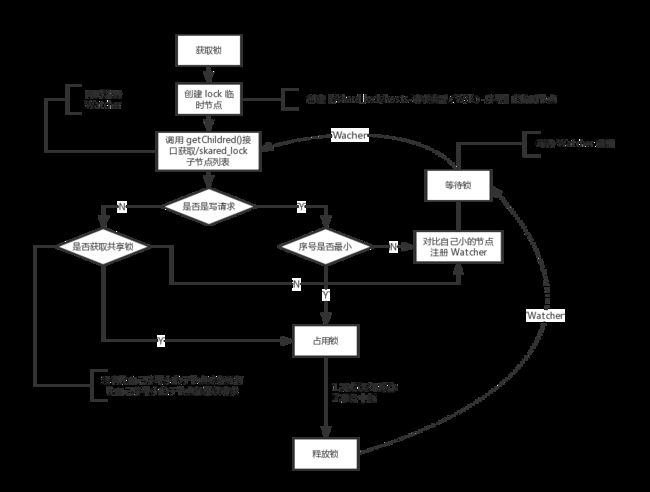
共享锁(Shared Locks)
引申:又成为读锁,数据对所有事务可见。
存在/shard_lock/lock_no1,/shard_lock/lock_no2等多个临时顺序节点
读写请求:
读请求:如果没有比自己序号小的子节点,或者所有比自己序号小的子节点都是读请求,表明自己获取到了共享锁,开始读取逻辑。如果比自己序号小的子节点中有写请求,则进入等待
写请求:如果自己不是序号最小的子节点,则进入等待
如图,可以避免 ZooKeeper 发送节点变更 Watcher 通知给所有机器,即『羊群效应』。
分布式事务
案例:
1.引申:基于MQ的分布式事务补偿机制
2.应用:交易和资金对资源回滚不做同步 RPC调用,而是通过MQ(事务 MQ 或 Mysql+Canal+RocketMQ)交互,通过将消息发送到MQ,然后由资源应用自己去监听MQ的事件
集群管理
通过管理 zk 临时节点的顺序子节点,实现集群管理
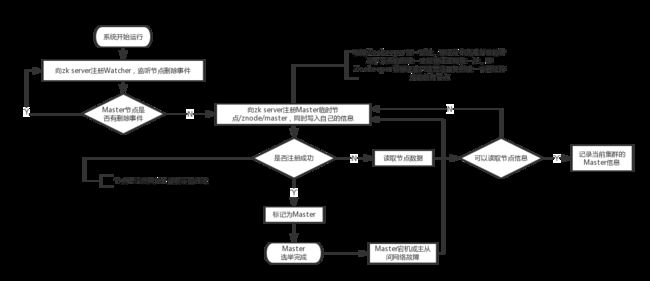
Master选举
原理:
服务器争抢创建标志为Master的临时节点
服务器监听标志为Master的临时节点,当监测到节点删除事件后展开新的一轮争抢
某个服务器成功创建则为Master
分布式队列
业界参考Alibaba RocketMQ
FIFO队列:利用zk的共享锁机制实现
分布式系统协调:如合并计算结果等
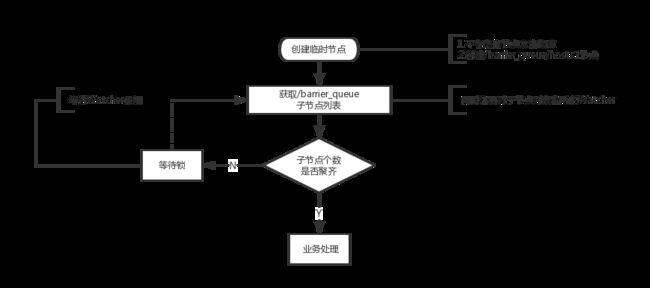
2.ZK可以保证顺序一致性、原子性、单一视图、可靠性、实时性的功能。
3.Zookeeper并发控制
Zookeeper 版本号机制,通过乐观锁进行并发控制
乐观锁又成为乐观并发控制,适用于数据并发竞争不大,事务冲突较少的应用中
悲观所适用于数据更新竞争十分激烈的场景,如分布式 DB SequenceID 申请
乐观锁事务分为三个阶段:数据读取,写入校验,数据写入
写入校验阶段是乐观锁的关键,事务会检查数据在读取阶段后是否有其他事务对数据进行过更新,以确保数据更新的一致性。通过 JDK 中的 CAS 乐观锁实现
4.Zookeeper角色
Leader(设计模式:责任链模式)
事务请求的唯一调度和处理者,保证集群事务处理的顺序性
集群内部各个服务器的调度者
Follower(设计模式:责任链模式)
处理客户端非事务请求,转发事务请求给Leader服务器
参与事务请求Proposal投票
参与Leader选举投票
Observer
只提供非事务服务,事务请求(Proposal投票与Leader选举)会转发给Leader服务器
用于不影响集群事务处理能力条件下提升集群的非事务处理能力
5.集群间消息通信
6.znode的类型
persistent znode,如/path,只能通过zk的api删除(delete)
ephemeral znode,当创建该节点的客户端崩溃或关闭了与zk的连接时,这个节点就会被删除。
有序节点:一个有序znode节点被分配唯一一个单调递增的整数。
8.zk服务器端运行在两种模式下:独立模式(standalone)和仲裁模式(quorum)。standalone下zk状态无法复制,quorum下会有一组zk服务器,即zk集合,可以进行状态复制。