9.1-9.7 预习笔记
1. 正则介绍
- 正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串
- 给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
1. 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)
2. 可以通过正则表达式,从字符串中获取我们想要的特定部分。

2. grep工具
用来过滤指定关键词
- 其最简单的用法为 # grep 'keywork' filename
注:过滤的关键字最好用单引号框起来
我们拷贝/etc/passwd到一个新建目录/root/grep/下,用来做实验
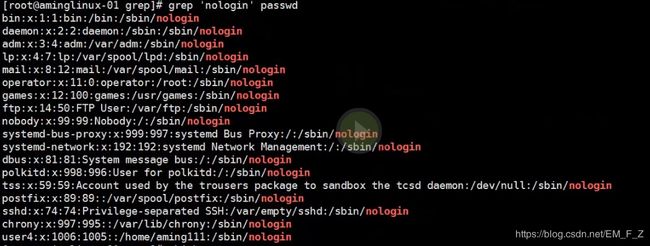
例子,在grep/目录下,如果想要过滤出passwd文件中nologin关键字,可以写成# grep 'nologin' passwd,结果如图所示
可以看到关键字nologin被标红highlight
- 加-c参数,可以用来显示过滤的结果的行数
还是使用上面的例子做实验,# grep -c 'nologin' passwd, 如下图所示,结果显示18行
![]()
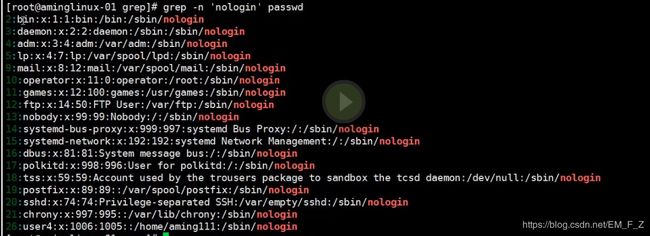
- 加-n参数,可以用来显示出过滤结果的行号
# grep -n 'nologin' passwd,图中绿色的部分就表示行号
- 加-i参数,表示过滤结果不区分大小写
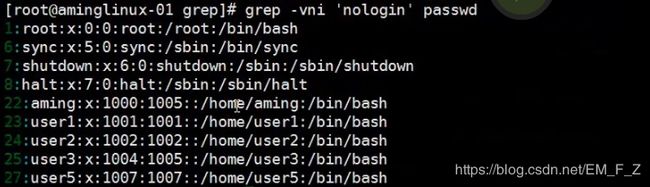
- 加-v参数,表示取反,也就是会显示除了过滤结果之外的内容
例如,# grep -vni 'nologin' passwd, 结果会显示不带nologin的内容
- 加-r参数,可以遍历所有的子目录
例如,# grep -r 'root' /etc/, 就可以过滤出/etc/下所有子目录中带有root关键字的内容
如下图所示,第一例紫色的部分就是过滤出内容的文件路径
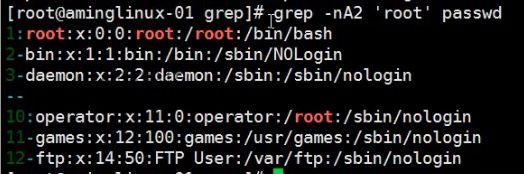
- 加-A参数,后面加数字,可以过滤出符合要求的行以及下面的n行
例如# grep -A2 'root' passwd, 就过滤出含有root关键字的那一行以及那行下面的2行
结果如下图
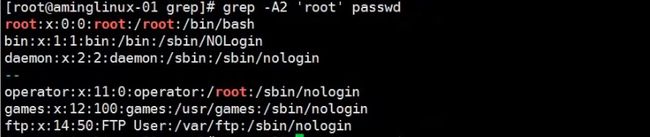
加-n, 更加直观
- 加-B参数,后面加数字,可以过滤出符合要求的行以及上面的n行
- 加-B参数,后面加数字,可以过滤出符合要求的行以及上下的n行
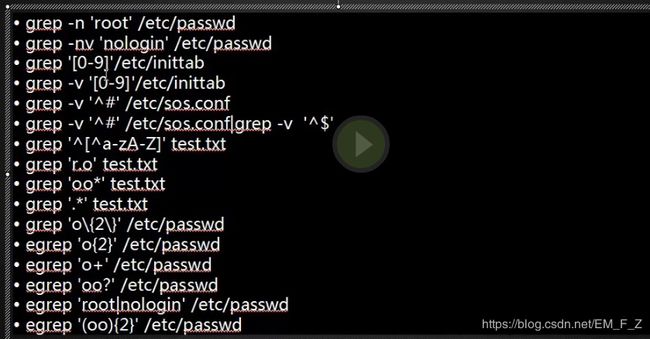
- grep正则表达式
grep '[0-9]' /etc/inittab,[0-9]表示要过滤出数字,[]表示方括号里的任意字符
grep -v '^#' /etc/sos.conf, ^符号表示以...开头,这个正则表示反取在/etc/sos.conf中以#号开头的内容
grep 'nologin$' passwd, $符号表示匹配以...结尾的行
grep '[^a-zA-Z]' test.txt, 用来过滤非方括号里面的内容,这个例子用来过滤数字或特殊符号的内容
grep '^[^a-zA-Z]' test.txt, 用来过滤以非方括号里面内容为开头的,这个例子用来过滤以数字或特殊符号开头的内容
[^] 匹配非方括号里面的内容。就是:只要不是方括号里面的内容都打印出来。
^[^] 匹配非方括号里面的内容开头的所有字符。 只要不是方括号里面的内容所开头的,都打印出来。
grep 'r.o' test.txt, .号表示任意字符,这个例子表示过滤出匹配r任意字符o的内容
grep 'oo*' test.txt, *号表示匹配重复其左边字符0-n次
grep '.*' test.txt, 匹配所有字符(任意字符)
grep 'o\{2\}' test.txt, {}在grep中的使用表示{}前面字符的重复范围,且使用时需要用\符号来脱译,因此这个例子匹配的是出现两次o
{}号中可以添加次数范围,写成\{0,3\}表示0到3都匹配
egrep 'o{2}' test.txt的作用和grep 'o\{2\}' test.txt相同
grep -E和egrep是一个意思,grep -E 'o{2}' test.txt的结果也是一样的
grep -E '(oo){2}' test.txt,把{}前面的字符()起来表示一个整体,例子就是匹配oo出现两次
grep '0\+' test.txt & egrep '0+' test.txt, +表示匹配其左边字符的1次或多次
grep -E/ egrep 'oo?' test.txt, ?表示匹配重复其前面字符的0次或1次
egrep 'root|nologin' /etc/passwd, |表示或者
3. sed命令
可以实现grep的用法,但是过滤结果不highlight。sed主要用来替换指定字符
1)匹配的用法
语法:# sed -n '/匹配的字符/'p 文件名
如下图所示
使用-r参数可以使//中的匹配字符进行脱译,例如# sed -rn '/o+t/'p test.txt
注://中可以加grep介绍中提到的特殊符号./^/[]/{}/+/*/?来指定匹配字符,但是有时需要进行脱译
- 如果要匹配的字符不分大小写,可以# sed -n '/字符/'Ip 文件名,也就p前面加I (大写的i)
2)打印指定的行
语法: # sed -n ‘数字’p 文件名, 就可以打印出特定的行数
如下图所示,# sed -n '2'p test.txt, 就可以打印出test.txt中的第二行
![]()
- 如果打印出一定范围的行,可以# sed -n 'n1,n2'p filename, 表示打印出n1到n2的行
$符号表示最后一行,如下图,# sed -n '25,$'p test.txt, 就可以显示出test.txt文件中的第25行到最后一行

- 加-e选项
-e选项可以支持sed进行多点编辑处理,也就是说-e可以叠加匹配内容
如下图所示,# sed -e '1'p -e'/bus/'p -n test.txt, 表示既匹配第一行,又匹配关键字bus

如果-e后面的匹配有重合,重合的部分也会打印出来,
例如# sed -e '1'p -e '/root/'p -n test.txt, test.txt中的第一行也包含root,所以第一行出现两次

3)删除指定的行
实际应用删除大的日志文件中半年的内容
- 语法# sed 'n1,n2'd 文件名,但是这个命令并没有删除文件内容,只是在屏幕显示上不列出指定的行数范围
而想用# sed来删除文件指定的行数,则# sed -i 'n1,n2'd 文件名
- sed不仅可以删除指定的行数,可以删除含有匹配字符的行
语法# sed '/指定字符/'d 文件名
4)替换作用
语法 # sed '指定替换范围s/被替换的字符/替换成的字符/g' 文件名
注:语法中的s表示替换作用的关键词;g表示全局替换
- 加-r,可以使特殊字符脱译
例如# sed -r '1,10s/ro+/r/g' test.txt
4. awk
awk工具比sed更丰富的功能是其支持分段,例如/ect/passwd/文件内容很有规律,每行的内容为7段,那么我们就可以用awk工具针对每一段来做匹配
为了方便做实验我们先新建一个awk的目录,再把/ect/passwd拷贝到awk目录下并且把名字改为test.txt
1) awk 匹配段的功能
- awk -F ':' '{print $段数}' filename
-F参数表示指定分隔符,如下所示如果我们想要指定awk/test.txt中的第一段字符,可以写成# awk -F ':' '{pring $1}' test.txt(因为当前目录为awk,所以文件写相对路径就可以)
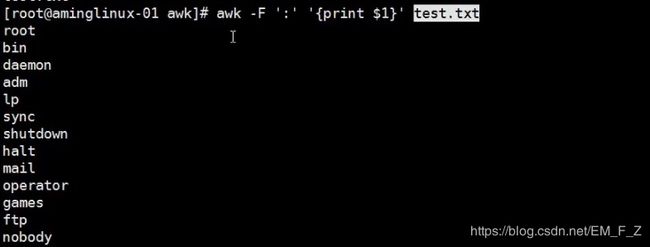
注:如我我们想要打印所有的段,那么可以写成# awk -F ':' '{print $0}', $0可以用来匹配出所有的段
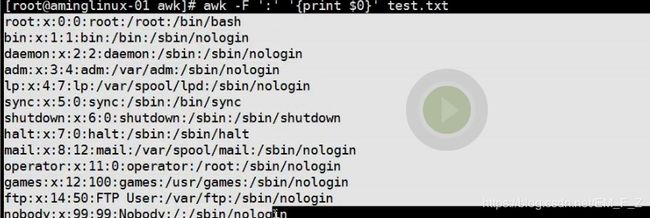
如果想用awk显示出所有的内容则无需用-F指定分隔符,可以写成#awk {pring$0} test.txt; 在awk的使用过程中如果没有使用-F来制定分隔符,那么默认使用空格或者空白字符为分隔符
- awk -F ':' '{print $n1,$n2,$n3...}' filename
如果我们想要指定多个段,就可以如下图例子用逗号来做分割
# awk -F ':' '{print $1,$3,$4}' test.txt
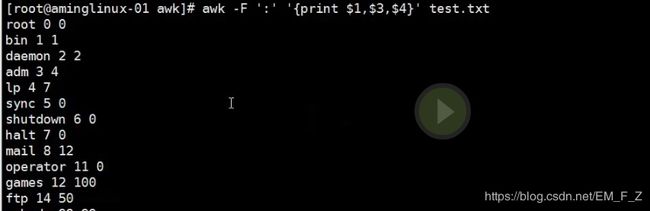
注:我们可以指定匹配打印出来的多个段数内容之间的连接符号,例如我们想要使打印内容之间使用#作为分割就可以写成
# awk -F ':' '{print $1"#"$3"#"$4}' test.txt, 指定段数之间用“符号”表示
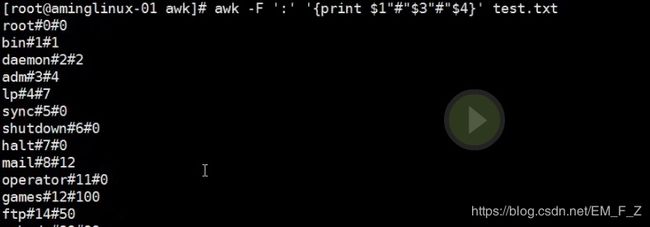
2)awk匹配内容的功能
语法 awk ‘/匹配的内容/’ filename
例如我们想要匹配出awk/test.txt中带有oo的内容,就如下图所示 # awk '/oo/' test.txt

3) awk匹配段和内容功能的结合使用
- 语法 awk -F ':' ‘$n1 ~ /匹配的内容/’ filename
例如我们想要打印出awk/test.txt下第一段含有oo字符的内容,就可以写成# awk -F ':' '$1 ~ /oo/' test.txt
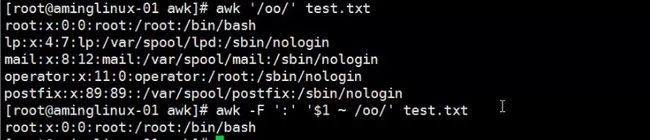
- awk同样支持所有的正则表达式,且不需要加任何的脱译字符,也支持多个表达式一起写
例如# awk -F ':' '/root/ {print $1,$3} /user/ {print $1,$3}' test.txt
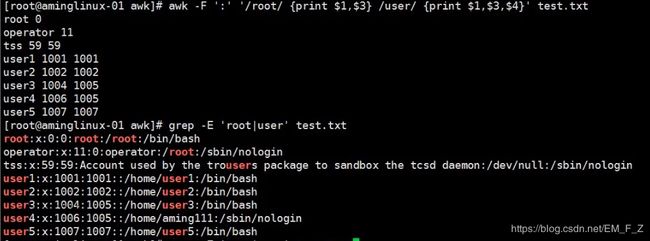
也可以写成# awk -F ':' '/root|user/ {print $1,$3}' test.txt
- 针对数学运算表达式的用法
语法 awk -F ':' '$n1 ==(>=/<=/!=)数值 {print $n2}' filename
意味着可以打印出来文件中第n1段等于、大于、小于某个数值的第n2段的内容
例如我们想要打印出test.txt中第三段大于等于1000的第一段的内容,# awk -F ':' '$3>=1000 {print $1}' test.txt

注:==必须为两个不然相当于给n1赋值
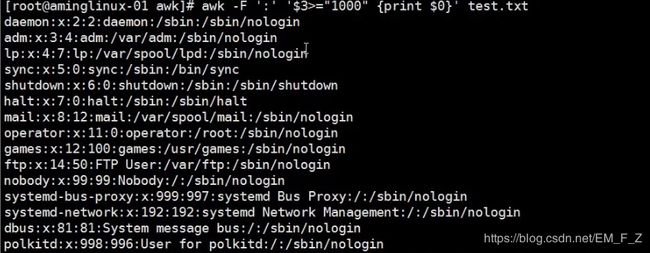
数值加“”的话,打印结果会按照阿斯玛的顺序排列,而不会吧“”里面的内容当做数字而会当做字符处理,所以如果想要针对数字匹配的话一定不要加“”;如下图所示 # awk -F ':' '$3>="1000" {print $1}' test.txt的结果与上文完全不同
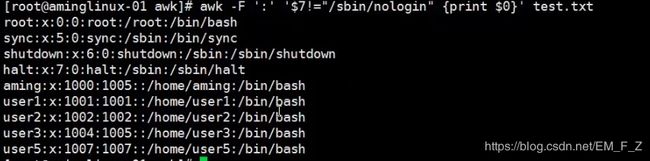
相反如果想要针对字符串的话,就一定要加“”,如下图所示 # awk -F ':' '$7!="/sbin/nologin" {print $0}' test.txt, /sbin/nologin为字符串就要加“”
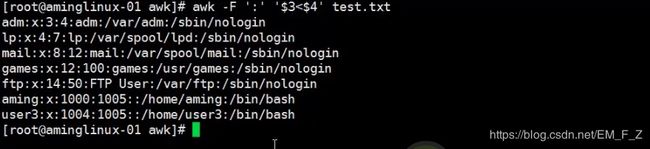
- 针对两个字段的比较
语法 awk -F ':' '$n1>/
还是用test.txt文件做实验,如果我们想要打印出test.txt文件中第三段小于第四段的内容
#awk -F ':' '$3<$4' test.txt
- 也可以两个条件并列用 awk -F ':' '$n1 /== "字符" && $n1 /== "字符"‘ filename
如下图,我们想要打印出test.txt中第三段大于5小于7的内容
# awk -F ':' '$3>"5" && $3<"7"' test.txt,因为加上了“”,所以这个5和7就会认为是普通字符。 比较大小就是按ASCII码排序了。
比如,2 和 11,是两个字符,2是比11大的,因为它比较时,是一位一位地比较,它会比较2大还是1大。所以59大于5但是小于7。
![]()
- 也可以或者条件,awk -F ':' '$n1 /== "字符" || $n12/== "字符"‘ filename
如下图,我们需要打印出test.txt中第三段数值大于1000或者第7段内容为/sbin/nologin的内容
# awk -F ':' '$3>1000 || $7=="/sbin/nologin"' test.txt
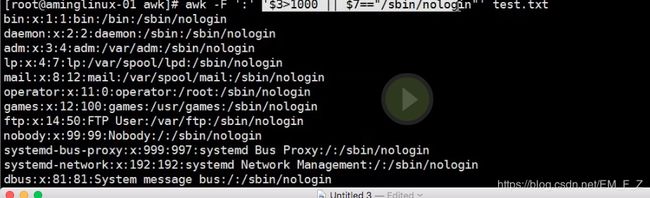

注:并列或者需求的指定即可为匹配也可以为数学运算表达
- OFS参数可以用来指定print时的分隔符
语法 awk -F '分隔符' ’{OFS="分隔符"} 并列或或者条件 {print $n1,$n2,$n3...} filename
这里-F指定的是匹配前也就是分段前的分隔符,OFS指定的是print时的分隔符;OFS要写在最前
如下图,如我我们想要打印出test.txt中第三段数值大于1000或者第7段内容匹配bash的第一段第三段第七段,并且打印结果用#来分隔
# awk -F ':' '{OFS="#"} $3>1000 || &7~ /bash/ {print $1,$3,$7}' test.txt

- if 条件
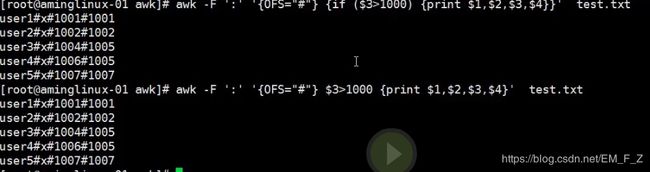
语法 awk -F ':' '{OFS="#"} {if (条件) {print $n1,$n2,$n3}}' filename
# awk -F ':' '{OFS="#"} {if ($3>1000) {print $1,$2,$3,$4}}' test.txt = #awk -F ':' '{OFS="#"} $3>1000 {print $1,$2,$3,$4}’ test.txt
- 内置变量- NR&NF
NR-显示行数
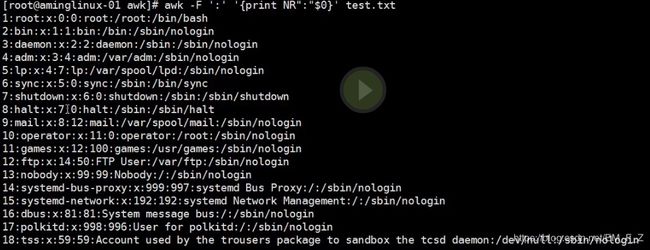
语法 awk -F '分隔符' '{print NR "符号" $n1}' filename
NR后面的“符号”比表示print的时行号与匹配内容之间的分隔符
例如下图,显示文件中所有段的内容并标明行数,且行数和内容用:分隔
#awk -F ':' '{print NR ":" $0}' test.txt
NF-段数
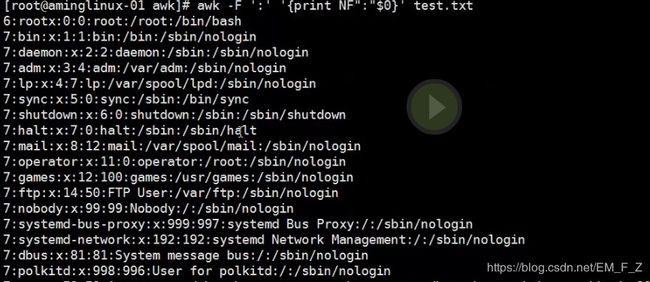
语法 awk -F '分隔符' '{print NF "符号" $n1}' filename
因为test.txt中的内容为copy了/etc/passwd,所以所有行的段数为7,为了做实验,我们把第一行的root用户的配置行改为6段,如下图,显示文件中所有段的内容并标明每行的段数,且段数和内容用:分隔,就可以看出段数用:分隔标注在行首,第一行段数为6,其他行为7
#awk -F ':' '{print NF ":" $0}' test.txt
NR/NF可以作为判断条件
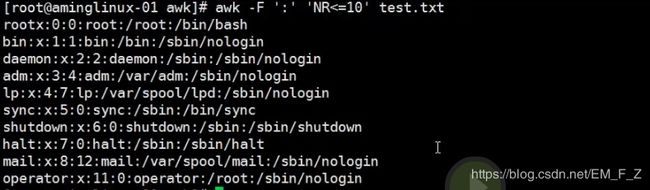
语法 awk -F '分隔符' ‘NR/NF/==数值’ filename
如下图,我们要打印前十行的内容
# awk -F ':' 'NR<=10' test.txt
同时我们也可以指定并列条件
如下图我们指定并列条件为第一段匹配root或者sync
# awk -F ':' 'NR<=10 && $1 ~ /root|sync/' test.txt

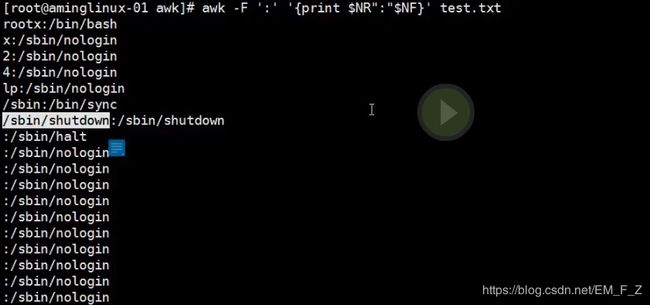
awk -F ':' '{print $NR ":" $NF}' test.txt
可以对角线显示,$NF为最后一段,如下图显示test.txt文件中第一行的第一段:最后一段,第二行的第二段:最后一段,第三行的第三段:最后一段,第四行的第四段:后一段,第五行的第五段:最后一段,第六行的第六段:最后一段,第七行的第六段:最后一段,因为文件里总共只有7段,所以无法继续显示第八行的第八段,之后的打印内容就为:最后一段
- =和==的区别
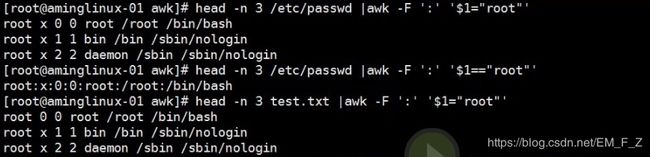
=可以赋值
例如 head -n3 test.txt |awk -F ':' '$1="root"' vs. head -n3 test.txt |awk -F ':' '$1=="root"'
我们可以发现=时,第一段全被赋值为root,而两个==时就是精确匹配第一段为root的行
- tot (total)
可以计算出所有行中某一段的总和
语法 awk -F ':' '{(tot=tot+$n1)}; END {print tot}' filename
{(tot=tot+$n1)}; END为一个循环,每次循环都会加上$n1的值,也就是第一次循环为0+第一行的第n段,第二次循环为第一次的循环结果+第二行的第n段,第三次循环为第二次的结果+第三行第n段,以此类推,所以可以算出所有行中某一段的总和
如下图,计算test.txt所有行的第三段的总和
# awk -F ':' '{(tot=tot+$3)}; END {print tot}' test.txt
![]()