机器学习中树模型算法总结之 决策树(上)
写在前面
最近在写小论文的时候接触到了XGBoost,才发现这算法真的是神一般的存在,去网上搜了一下居然绝大多数竞赛winner用的也是这个算法(这算不算开挂haha~)。发现这么好用的算法如果只是会用的话真是可惜,所以决定放下手头的论文,先仔细地研究研究。但是在网上看XGBoost资料的时候觉得自己以前看的树模型算法都忘得差不多了,所以就趁着这个机会把机器学习里的树模型算法重新再过一遍,主要包括决策树、随机森林、提升树、XGBoost等等。
1.决策树模型
决策树(decision tree)是一种常见的机器学习方法,可用于分类和回归问题。决策树模型成树形街否,由结点和有向边组成,其中结点包括内部节点(表示一个特征或属性)和叶节点(表示一个分好的类)。
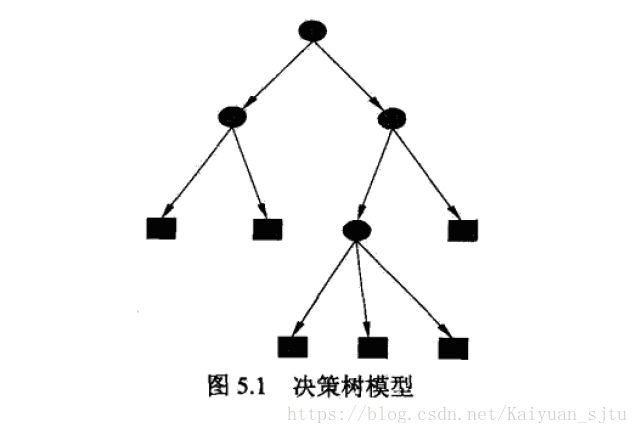
决策树分类过程:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点;每个子节点对应着该特征的一个取值。如此递归对实例进行测试并分配,直至达到叶节点,叶节点即表示一个类。
决策树学习的目标是根据给定的训练数据集构建一个模型,使得与训练数据矛盾较小且存在较好的泛化能力。在决策树学习中,利用损失函数(通常是正则化的极大似然函数)来表述这一目标,最终的策略就是以损失函数为目标函数的最小化。
决策树的学习主要包括三个步骤:特征选择、决策树生成和决策树修剪。
2.特征选择
为了构建一颗合适的决策树,选择分类的最优特征成为了关键因素,即如何选择最优划分属性。通常特征选择的准则是信息增益或信息增益比。
为了便于说明,先了解熵和条件熵的定义。
熵(entropy)是表示随机变量不确定性的度量,熵越大,随机变量的不确定性就越大。
这里设X是一个有限个值的离散随机变量,其概率分布为:
![]()
则随机变量X的熵定义为:
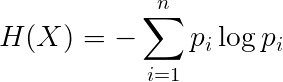
条件熵:设随机变量(X,Y),其联合概率分布为:
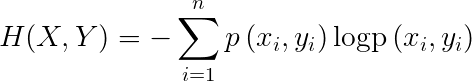
条件熵表示在已知随机变量X的条件下随机变量Y的不确定性。随机变量X给定的条件下随机变量Y的条件熵H(Y|X),定义为X给定条件下Y的条件概率分布对X的数学期望:
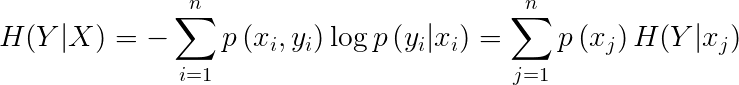
2.1 信息增益
信息增益(information gain)表示得知特征X的信息而使得Y类的信息的不确定性减少的程度。
定义:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差:
![]()
对于数据集D而言,信息增益依赖于特征,信息增益大的特征表示使用该特征导致结果不确定性减小的大,故该特征具有更强的分类能力。
根据信息增益准则选择特征的决策树算法主要有ID3:对训练数据集D计算其每个特征的信息增益,并比较他们的大小,选择信息增益大的特征进行分支,如此递归地进行下去。
下面给出具体的信息增益算法

其中:

2.2 信息增益率
以信息增益为划分训练数据的特征,存在偏向于选择取值较多的特征的问题。而使用信息增益率可以有效进行校正。
定义:特征A对训练数据集D的信息增益比gr(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值得熵HA(D)之比:
根据信息增益准则选择特征的决策树算法主要有C4.5,:对训练数据集D计算其每个特征的信息增益,并比较他们的大小,选择信息增益大的特征进行分支,如此递归地进行下去。
关于信息增益率具体算法与前述信息增益相似,就不再赘述。
需要注意的是,增益率准则对可取值数目较少的特征有所偏好,C4.5算法并不是直接选择增益率最大的特征划分属性,而是使用了一个启发式算法:先从候选划分特征中找出信息增益高于平均水平的特征,再从中选择信息增益率最高的用于划分。
2.3 基尼指数
与上相似,基尼指数(Gini index)也可用于划分属性。
在分类问题中,假设有K个类,样本点属于第k类的概率为Pk,则概率分布的基尼指数定义为:
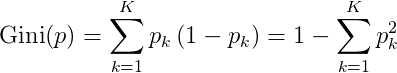 `$$`
`$$`
若对于给定的样本集合D,其基尼指数为:
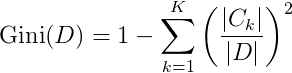
在特征A的条件下,集合D的基尼指数定义为:

基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经特征A分割后集合D的不确定性。因此,基尼指数越大,样本的不确定性也就越大,这一点与熵类似。于是,我们在候选特征集合中,选择那个使得划分后基尼指数最小的特征作为最优划分特征。
基尼指数这一特征选择的算法主要用于CART模型,后续会在CART生成算法中细述。
为了加深印象,在这里贴一个例子(李航统计学习方法P62)
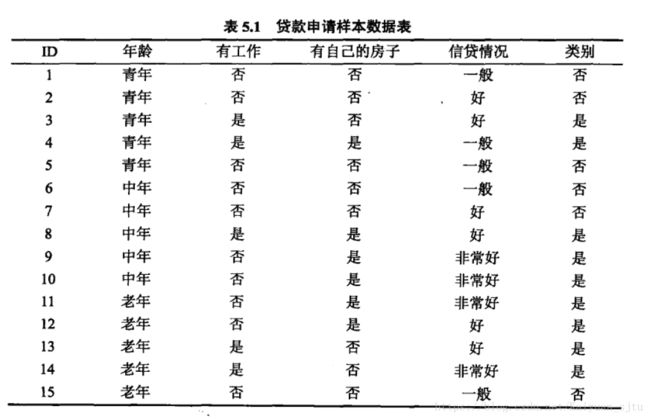

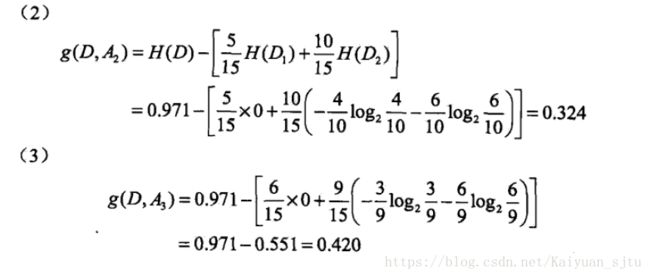

小结
今天主要记录了一些决策树的基本概念以及三大特征选择算法。
在这三大算法之外,人们还设计了许多其他的准则用于决策树的划分选择,但是好像...泛化性能影响不大....
本质上,各种特征选择的方法均可以用于决策树的划分属性选择。具体特征选择详解可参考周志华的《机器学习》第11章节。
以上~
To be continued~
2018.04.17