基本数据结构(树和堆)
编程基础文章目录:
| 五大基础算法 | 基础数据结构(栈和队列) | 散列表 |
| 常见C++知识 | 基础数据结构(数组、串、广义表) | 四大比较排序算法 |
| 基础数据结构(线性表) | 基础数据结构(树和堆) |
微博:LinJM-机器视觉 Blogger:LinJM
前面文章中介绍了线性结构和表结构,但是这些数据结构一般不适合于描述具有分支结构的数据。在这种数据之间可能有祖先—后代,上级—下级、整体—部分等分支的关系。下文介绍的树形结构则是以分支关系定义的层次结构,是一类重要的非线性数据结构,在计算机领域有着广泛应用。例如,在文件系统和数据库系统中,树是组织信息的重要形式之一;在编译系统中,树用来表示源程序的语法结构;在算法设计与分析中,树还是刻画程序动态性质的工具。
树的基本概念
为了完整的建立有关树的基本概念,以下给出两种树的定义,即自由树和有根树

术语
节点的度:一个节点含有的子树的个数称为该节点的度;
树的度:一棵树中,最大的节点的度称为树的度;
叶节点或终端节点:度为零的节点;
非终端节点或分支节点:度不为零的节点;
双亲节点或父节点:若一个结点含有子节点,则这个节点称为其子节点的父节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次;
堂兄弟节点:双亲在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
森林:由m(m>=0)棵互不相交的树的集合称为森林;
二叉树
二叉树是树形结构的一个重要类型。许多实际问题抽象出来的数据结构往往是二叉树的形式,即使是一般的树也能简单地转换为二叉树,而且二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。
二叉树(BinaryTree)是n(n≥0)个结点的有限集,它或者是空集(n=0),或者由一个根结点及两棵互不相交的、分别称作这个根的左子树和右子树的二叉树组成。
这个定义是递归的。由于左、右子树也是二叉树, 因此子树也可为空树。
二叉树的性质:
满二叉树(FullBinaryTree)性质1 二叉树第i层上的结点数目最多为2^i-1(i≥1)
性质2 深度为k的二叉树至多有2^k-1个结点(k≥1)
性质3 在任意-棵二叉树中,若叶子结点(即度为0的结点)的个数为n0,度为1的结点数为n1,度为2的结点数为n2,则no=n2+1。
一棵深度为k且有2^k-1个结点的二又树称为满二叉树。
满二叉树的特点:
(1)每一层上的结点数都达到最大值。即对给定的高度,它是具有最多结点数的二叉树。(2)满二叉树中不存在度数为1的结点,每个分支结点均有两棵高度相同的子树,且树叶都在最下一层上。
若一棵二叉树至多只有最下面的两层上结点的度数可以小于2,并且最下一层上的结点都集中在该层最左边的若干位置上,则此二叉树称为完全二叉树。
特点:
(1)满二叉树是完全二叉树,完全二叉树不一定是满二叉树。
(2)在满二叉树的最下一层上,从最右边开始连续删去若干结点后得到的二叉树仍然是一棵完全二叉树。
(3)在完全二叉树中,若某个结点没有左孩子,则它一定没有右孩子,即该结点必是叶结点。

二叉树遍历及其应用
二叉树遍历(Binary Tree Traversal)就是遵从某种次序,遍访二叉树中的所有结点,使得每个结点被访问一次,而且只访问一次。这里,“访问”的意思就是对结点实施某些操作。
令L,R,V分别代表遍历一个结点的左子树、右子树、和访问该结点的操作,则遍历二叉树有6种规则:
VLR,LVR,LRV,VRL,RVL,RLV
若规定先左后右,则仅剩下前面三种,即:VLR(前序遍历),LVR(中序遍历),LRV(后序遍历)

堆
数据集合如果有序,将为各种操作带来便利。但是有些应用并不要求数据全部有序,或者在操作开始前就完全有序。在许多应用中,通常需要先收集一部分数据,从中挑选具有最小或最大关键码的记录开始处理,接着,可能会收集更多数据,并处理当前数据集具有最大或最小关键码的记录。对于这类应用,我们期望的数据结构应能支持插入操作,并能方便地从中取出具有最大或最小关键码的记录,这样的数据结构即为优先级队列(priority queue)。从外表看来,优先级队列颇似队列和栈,但要构建高效率的优先级队列,需要比实现队列和栈考虑更多的因素。在优先级队列的各种实现中,堆(heap)是最高效的一种数据结构。
最小堆和最大堆
假定在各个数据记录中存在一个能够标识数据记录的数据项,并将依据该数据项对数据进行组织,则可称这些数据项为关键码(key)。
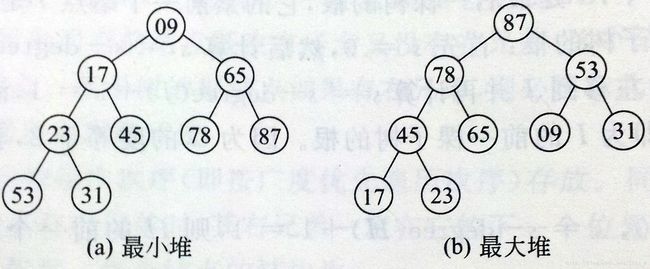
如果有一个关键码的集合K={k0,k1,k2,k3,...,kn-1},把它的所有元素按完全二叉树的顺序存储方式存放在一个一维数组中,并且满足
k_i <= k_2i+1且k_i <= k_2i+2(或k_i >= k_2i+1且k_i >= k_2i+2) i=0,1,...,[(n-2)/2]
则称这个集合为最小堆(或最大堆)。
下图给出了最小堆和最大堆的例子。前者任一结点的关键码均小于或等于它的左、右子女的关键码,位于堆顶的结点是整个集合中最小的,所以称它为最小堆。
本文地址:http://blog.csdn.net/linj_m/article/details/17587565
参考文献:
[1] 殷人昆. 数据结构 (用面向对象方法与 C++ 语言描述)[M]. 2007.
[2] Cormen T H, Leizerson C E, Rivest R L. 算法导论[M]. 2006.
[3] 维基百科