Hadoop伪分布式安装步骤
Hadoop伪分布式安装步骤
目录
Hadoop伪分布式安装步骤
一.永久关闭防火墙
二.配置主机名
1.编辑network文件:vim /etc/sysconfig/network
2.将HOSTNAME属性改为指定的主机名,
3.让network文件重新生效:source /etc/sysconfig/network
三.配置hosts文件,将主机名和ip地址进行映射
1.编辑hosts文件:vim /etc/hosts
2.将主机名和ip地址对应,
四.配置ssh进行免密互通
1.生成自己的公钥和私钥,生成的公私钥将自动存放在/root/.ssh目录下:ssh-keygen
2.把生成的公钥拷贝到远程机器上,
五.重启Linux让主机名的修改生效:reboot
六.安装JDK
七.上传或者下载Hadoop安装包到Linux中
八.解压安装包tar -xvf hadoop-2.7.1_64bit.tar.gz
九.adoop的安装目录的子目录etc/hadoop
十.配置hadoop-env.sh
1.编辑hadoop-env.sh:vim hadoop-env.sh
2.修改JAVA_HOME的路径,修改成具体的路径。
1. cat /etc/profile 查看所有的配置文件路径
3.修改HADOOP_CONF_DIR的路径,修改为具体的路径,
4.保存退出文件
5.重新加载生效:
十一.配置 core-site.xml
1.编辑core-site.xml:vim core-site.xml
2.添加如下内容:
3.保存退出
十二.配置 hdfs-site.xml
1.编辑hdfs-site.xml:
2.添加如下配置:
3.保存退出
十三.配置 mapred-site.xml
1.将mapred-site.xml.template复制为mapred-site.xml
2.编辑mapred-site.xml
3.添加如下配置:
4.保存退出
十四.配置 yarn-site.xml
1.编辑yarn-site.xml
2.添加如下内容:
3.保存退出
十五.配置slaves
1.编辑slaves:vim slaves
2.添加从节点信息,
3.保存退出
4.配置hadoop的环境变量
十六.编辑profile文件:vim /etc/profile
1.添加Hadoop的环境变量,例如:
2.保存退出
3.重新生效:source /etc/profile
4.格式化namenode:hadoop namenode -format
5.启动hadoop:start-all.sh
一.永久关闭防火墙
已经关闭,忽略

二.配置主机名
需要注意的是Hadoop的集群中的主机名不能有_。如果存在_会导致Hadoop集群无法找到这群主机,从而无法启动!
1.编辑network文件:vim /etc/sysconfig/network

2.将HOSTNAME属性改为指定的主机名,
![]()
3.让network文件重新生效:source /etc/sysconfig/network
![]()
三.配置hosts文件,将主机名和ip地址进行映射
1.编辑hosts文件:vim /etc/hosts

2.将主机名和ip地址对应,
四.配置ssh进行免密互通
1.生成自己的公钥和私钥,生成的公私钥将自动存放在/root/.ssh目录下:ssh-keygen

2.把生成的公钥拷贝到远程机器上,

格式为:ssh-copy-id [user]@host,例如:ssh-copy-id root@hadoop01
五.重启Linux让主机名的修改生效:reboot
六.安装JDK
七.上传或者下载Hadoop安装包到Linux中

八.解压安装包tar -xvf hadoop-2.7.1_64bit.tar.gz
九.adoop的安装目录的子目录etc/hadoop
配置Hadoop:cd hadoop2.7.1/etc/hadoop
十.配置hadoop-env.sh
1.编辑hadoop-env.sh:vim hadoop-env.sh
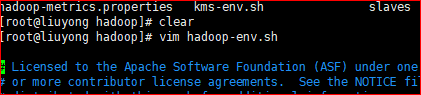
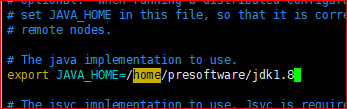
2.修改JAVA_HOME的路径,修改成具体的路径。
1. cat /etc/profile 查看所有的配置文件路径
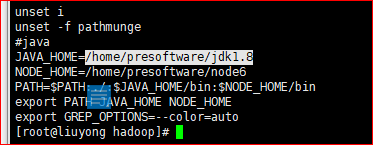
//home/presoftware/jdk1.8
例如:export JAVA_HOME=/home/software/jdk1.8
3.修改HADOOP_CONF_DIR的路径,修改为具体的路径,
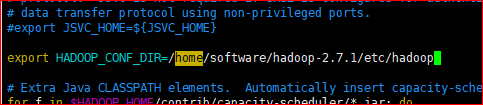
例如:export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
4.保存退出文件
:wq
5.重新加载生效:
source hadoop-env.sh
十一.配置 core-site.xml
1.编辑core-site.xml:vim core-site.xml
2.添加如下内容:
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop01:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/software/hadoop-2.7.1/tmpvalue>
property>
3.保存退出
十二.配置 hdfs-site.xml
1.编辑hdfs-site.xml:
vim hdfs-site.xml
2.添加如下配置:
<property>
<name>dfs.replicationname>
<value>1value>
property>
3.保存退出
十三.配置 mapred-site.xml
1.将mapred-site.xml.template复制为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
2.编辑mapred-site.xml
vim mapred-site.xml
3.添加如下配置:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
4.保存退出
十四.配置 yarn-site.xml
1.编辑yarn-site.xml
vim yarn-site.xml
2.添加如下内容:
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
3.保存退出
十五.配置slaves
1.编辑slaves:vim slaves
2.添加从节点信息,
例如:liuyong
3.保存退出
4.配置hadoop的环境变量
十六.编辑profile文件:vim /etc/profile
1.添加Hadoop的环境变量,例如:
在最后一行添加
export HADOOP_HOME=/home/software/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.保存退出
3.重新生效:source /etc/profile
4.格式化namenode:hadoop namenode -format
第一次配置需要初始化
5.启动hadoop:start-all.sh
配置最好手敲,复制遇坑,后果自负