eclipse+hadoop环境搭建及注意事项
废话不多说直接上干货。
一、工具准备
(1)win 10-64位
(2)jdk1.7-64位
(3)eclipse-luna-64,下载地址:https://www.eclipse.org/downloads/packages/release/Luna/SR2

(4)hadoop-eclipse-plugin-1.2.1.jar,下载地址:http://files.cnblogs.com/alex-blog/hadoop-eclipse-plugin-1.2.1.zip
(5)hadoop.1.2.1.gz.zip
二、环境搭建
(1)安装jdk1.7,具体步骤不赘述。这里给一篇比较好的博客。
http://blog.csdn.net/u012934325/article/details/73441617
(2)安装eclipse-luna-64。
直接解压该版本,放在你想要安装的目录下。
(3)将hadoop-eclipse-plugin-1.2.1.jar放在eclipse目录下的plugin文件夹里面,但是注意:hadoop-eclipse-plugin-1.2.1.jar需要改名为hadoop-eclipse-plugin-1.0.0.jar放到eclipse/plugin下面,否则不行,经多次实验得知。
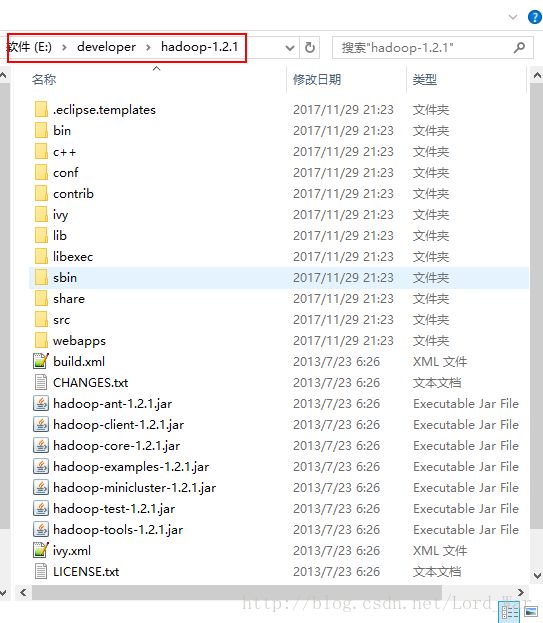
(4)将下载的hadoop.1.2.1.gz.zip解压,我将hadoop.1.2.1.gz.zip安装在E:\developer\hadoop-1.2.1。如下图
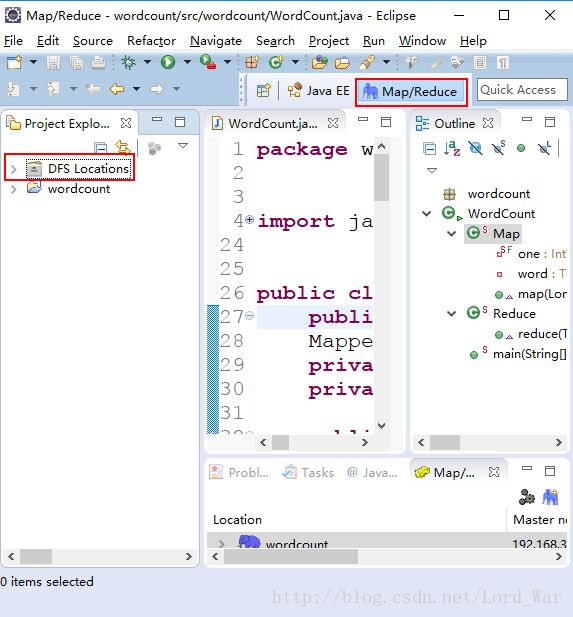
(5)启动eclipse,查看eclipse是否加载到了hadoop-eclipse插件。

同时在主界面也会出现DFS Location,说明这里存在一个连接HDFS的端口
(6)新建hadoop location

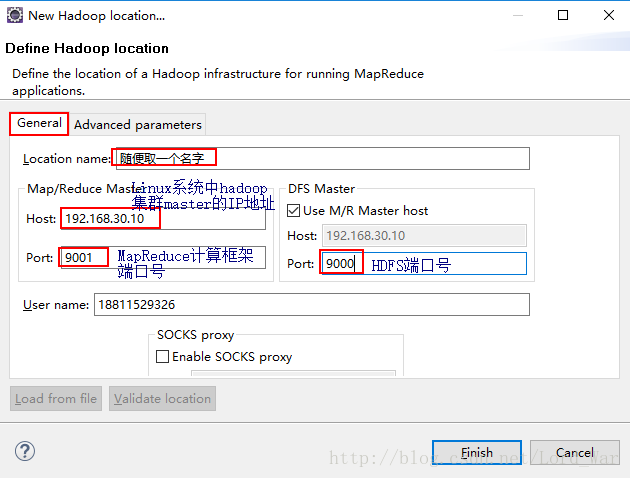
9001是在mapred-site.xml中配置的的端口。
9000是在core-site.xml中配置的的端口。
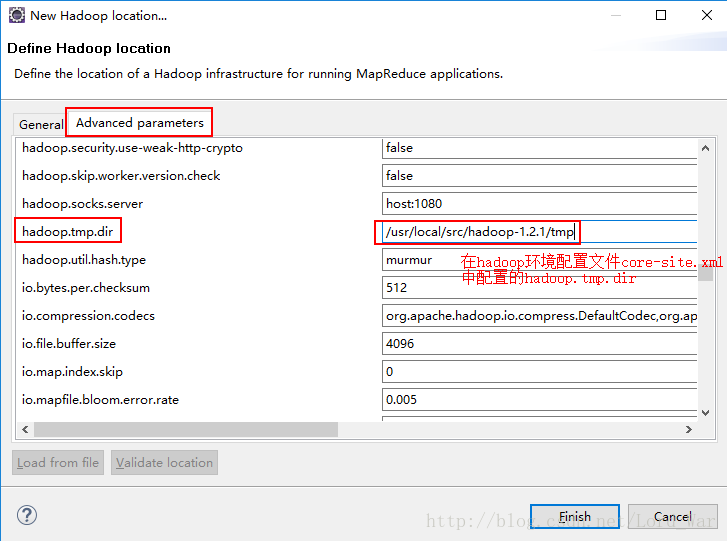
(7)eclipse连接虚拟机hadoop集群
首先启动虚拟机上的hadoop集群。
查看DFS Location动态,发现目录下出现了很多文件夹
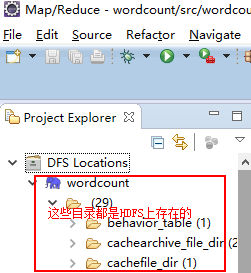
连接成功!!!!!
当我stop-all.sh 关闭hadoop集群时,eclipse 下的DFS Location状态转为如下结果,eclipse无法连接hadoop集群了。

(8)创建文件夹与上传文件。
开始我在DFS Location目录下的wordcount下面的那个文件夹右键创建新文件夹是无法实现的,也无法上传文件,而且显示缺乏权限。
报错:org.apache.hadoop.security.AccessControlException:Permission denied:user=xxxxxxx,access=WRITE,inode=”tmp”:root:supergroup:rwxr-xr-x
原因:
hadoop的默认的hdfs的文件目录是用权限
为了使Eclipse能正常对Hadoop集群的HDFS上的文件能进行修改和删除,需要对HDFS的权限进行修改。
强调内容
修改hadoop的配置,在conf/hdfs-site.xml中加入
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>这样就可以直接在eclipse上对hadoop进行操作。

新建了eclipse_build_dir文件夹,并将wc.txt文件上传到了该目录下。
(9)wordcount实践
Java开发MapReduce程序,然后在hadoop集群上执行,一般有两种方式:
● 生成jar包放到Linux的hadoop集群执行
● 通过eclipse执行运行MapReduce程序
一下一一为大家讲解。。。。。。。
9.1生成jar包放到Linux的hadoop集群执行
第一步:新建MapReduce工程,新建package(org.apache.hadoop.examples),从hadoop安装包下的src\examples\org\apache\hadoop\examples文件夹下将WordCount.java拷贝到package下,如图:

WordCount.java代码如下:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//Map
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
//Reduce类
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 第二步:导出jar包,右键工程==》export==》生成hadoop-examples.jar包

第三步:将hadoop-examples.jar拷贝到Linux集群上,执行MapReduce程序。
hadoop jar hadoop-example.jar org.apache.hadoop.examples.WordCount /wc_input /wc_output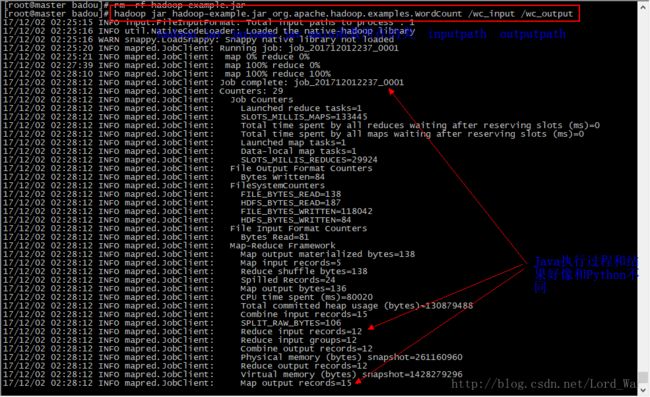
9.2通过eclipse执行运行MapReduce程序
第一步:同9.1中第一步的执行过程,代码也一样。
第二步:右键工程==》run as ==》run configuration==》如下配置参数==》run
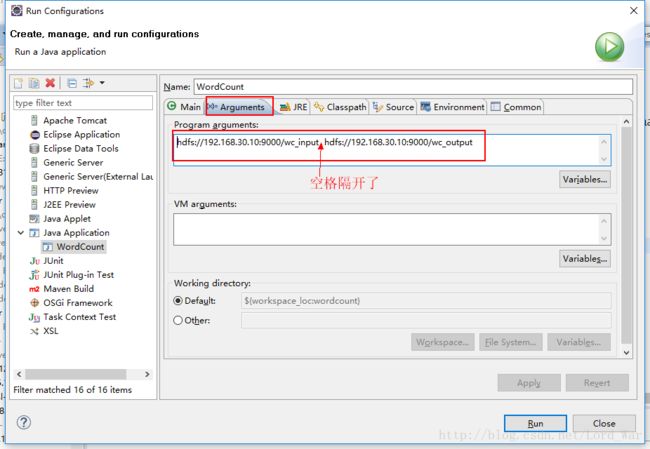
但是事与愿违,程序报错了:
Java.io.IOException: Failed to set permissions of path:
\tmp\Hadoop-Administrator\mapred\staging\Administrator-519341271.staging
to 0700
解决方案:查看《Eclipse中编译FileUtil.java》
原本以为上面就解决问题了,但是麻烦事又来了,有报错了。。。。
FATAL conf.Configuration: error parsing conf file:
com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException:
1 字节的 UTF-8 序列的字节 1 无效。 INFO mapred.JobClient: Cleaning up the
staging area
file:/tmp/hadoop-xxx/mapred/staging/xxx61669871573/.staging/job_local1669871573_0001
从错中得知是编码的问题导致程序无法识别,中间找了很多方案查找错误,但是依然得不到答案,后来在http://blog.csdn.net/majian_1987/article/details/23941663中找到了答案。
解决方案:

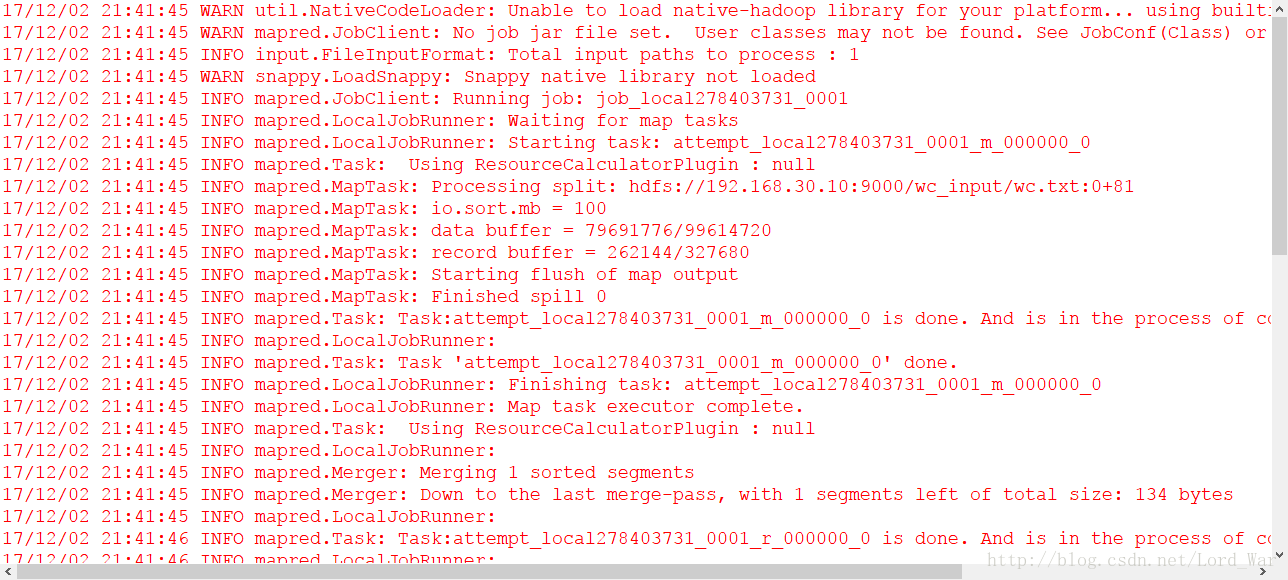
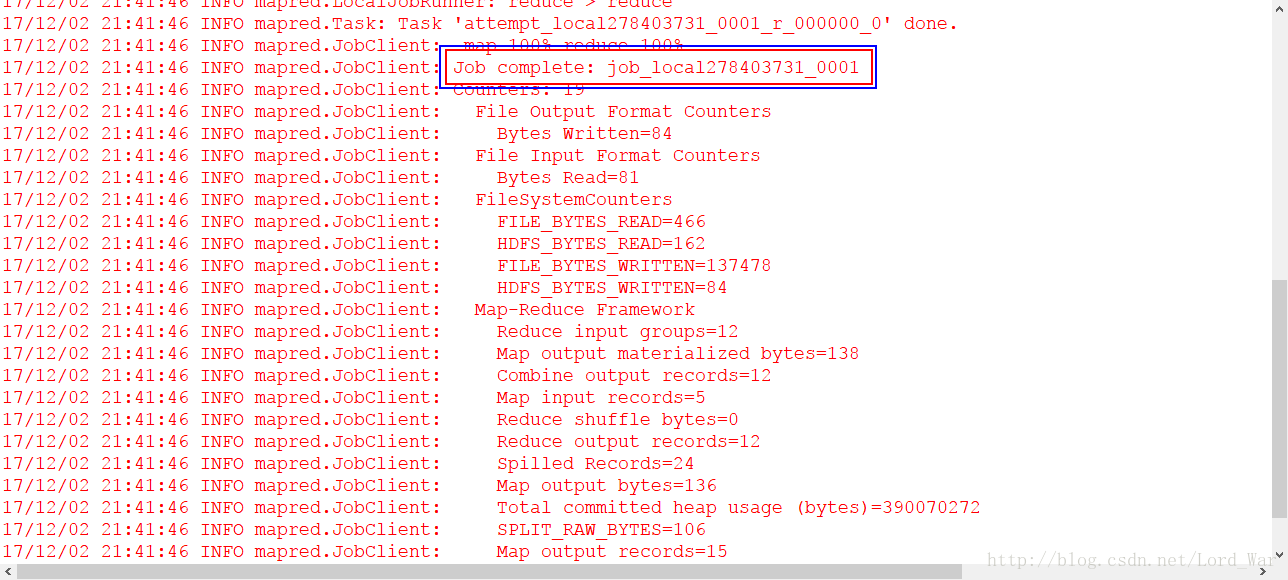
最后如愿以偿,程序执行成功!!!