大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装
大数据时代之hadoop(二):hadoop脚本解析
大数据时代之hadoop(三):hadoop数据流(生命周期)
大数据时代之hadoop(四):hadoop 分布式文件系统(HDFS)
hadoop的核心分为两块,一是分布式存储系统-hdfs,这个我已经在上一章节大致讲了一下,另一个就是hadoop的计算框架-mapreduce。
mapreduce其实就是一个移动式的基于key-value形式的分布式计算框架。
其计算分为两个阶段,map阶段和reduce阶段,都是对数据的处理,由于其入门非常简单,但是若想理解其中各个环节及实现细节还是有一定程度的困难,因此我计划在本文中只是挑几个mapreduce的核心来进行分析讲解。
1、MapReduce驱动程序默认值
编写mapreduce程序容易入手的其中一个原因就在于它提供了一些了的默认值,而这些默认值刚好就是供开发环境设置而设定的。虽然容易入手,但还是的理解mapreduce的精髓,因为它是mapreduce的引擎,只有理解了mapreduce的核心,当你在编写mapreduce程序的时候,你所编写的程序才是最终稳重的,想要的程序。废话少说,见下面代码:
public int run(String[] args) throws IOException {
JobConf conf = new JobConf();
/**
*默认的输入格式,即mapper程序要处理的数据的格式,hadoop支持很多种输入格式,下面会详细讲解,
*但TextInputFormat是最常使用的(即普通文本文件,key为LongWritable-文件中每行的开始偏移量,value为Text-文本行)。
**/
conf.setInputFormat(org.apache.hadoop.mapred.TextInputFormat.class);
/**
*真正的map任务数量取决于输入文件的大小以及文件块的大小
**/
conf.setNumMapTasks(1);
/**
*默认的mapclass,如果我们不指定自己的mapper class时,就使用这个IdentityMapper 类
**/
conf.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);
/**
* map 任务是由MapRunner负责运行的,MapRunner是MapRunnable的默认实现,它顺序的为每一条记录调用一次Mapper的map()方法,详解代码 --重点
*/
conf.setMapRunnerClass(org.apache.hadoop.mapred.MapRunner.class);
/**
* map任务输出结果的key 和value格式
*/
conf.setMapOutputKeyClass(org.apache.hadoop.io.LongWritable.class);
conf.setMapOutputValueClass(org.apache.hadoop.io.Text.class);
/**
* HashPartitioner 是默认的分区实现,它对map 任务运行后的数据进行分区,即把结果数据划分成多个块(每个分区对应一个reduce任务)。
* HashPartitioner是对每条 记录的键进行哈希操作以决定该记录应该属于哪个分区。
*
*/
conf.setPartitionerClass(org.apache.hadoop.mapred.lib.HashPartitioner.class);
/**
* 设置reduce任务个数
*/
conf.setNumReduceTasks(1);
/**
*默认的reduce class,如果我们不指定自己的reduce class时,就使用这个IdentityReducer 类
**/
conf.setReducerClass(org.apache.hadoop.mapred.lib.IdentityReducer.class);
/**
* 任务最终输出结果的key 和value格式
*/
conf.setOutputKeyClass(org.apache.hadoop.io.LongWritable.class);
conf.setOutputValueClass(org.apache.hadoop.io.Text.class);
/**
* 最终输出到文本文件类型中
*/
conf.setOutputFormat(org.apache.hadoop.mapred.TextOutputFormat.class);/*]*/
JobClient.runJob(conf);
return 0;
}
我要说的大部分都包含在了代码的注释里面,除此之外,还有一点:由于java的泛型机制有很多限制:类型擦除导致运行过程中类型信息并非一直可见,所以hadoop需要明确设定map,reduce输入和结果类型。
上面比较重要的就是MapRunner这个类,它是map任务运行的引擎,默认实现如下:
public class MapRunner
implements MapRunnable {
private Mapper mapper;
private boolean incrProcCount;
@SuppressWarnings("unchecked")
public void configure(JobConf job) {
//通过反射方式取得map 实例
this.mapper = ReflectionUtils.newInstance(job.getMapperClass(), job);
//increment processed counter only if skipping feature is enabled
this.incrProcCount = SkipBadRecords.getMapperMaxSkipRecords(job)>0 &&
SkipBadRecords.getAutoIncrMapperProcCount(job);
}
public void run(RecordReader input, OutputCollector output,
Reporter reporter)
throws IOException {
try {
// allocate key & value instances that are re-used for all entries
K1 key = input.createKey();
V1 value = input.createValue();
while (input.next(key, value)) {
// map pair to output
//循环调用map函数
mapper.map(key, value, output, reporter);
if(incrProcCount) {
reporter.incrCounter(SkipBadRecords.COUNTER_GROUP,
SkipBadRecords.COUNTER_MAP_PROCESSED_RECORDS, 1);
}
}
} finally {
mapper.close();
}
}
protected Mapper getMapper() {
return mapper;
}
}
要相信,有些时候还是看源码理解的更快!
2、shuffle
shuffle过程其实就是从map的输出到reduce的输入过程中所经历的步骤,堪称mapreduce的“心脏”,分为3个阶段,map端分区、reduce端复制、reduce排序(合并)阶段。
2.1、map端分区
由于在mapreduce计算中,有多个map任务和若干个reduce任何,而且各个任务都可能处于不同的机器里面,所以如何从map任务的输出到reduce的输入是一个难点。
map函数在产生输出时,并不是简单的写到磁盘中,而是利用缓冲的形式写入到内存,并出于效率进行预排序,过程如下图:
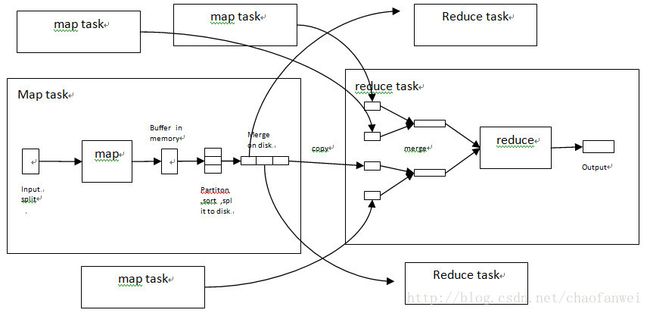
在写磁盘之前,线程首先根据reduce的个数将输出数据划分成响应的分区(partiton)。在每个分区中,后台线程按键进行内排序,如果有个一combiner,它会在排序后的输出上运行。
2.2、reduce端复制阶段
由于map任务的输出文件写到了本地磁盘上,并且划分成reduce个数的分区(每一个reduce需要一个分区),由于map任务完成的时间可能不同,因此只要一个任务完成,reduce任务就开始复制其输出,这就是reduce任务的复制阶段。如上图所示。
2.3、reduce端排序(合并)阶段
复制完所有map输出后,reduce任务进入排序阶段(sort phase),这个阶段将合并map输出,维持其顺序排序,如上图所示。
3、输入与输出格式
随着时间的增加,数据的增长也是指数级的增长,且数据的格式也越来越多,对大数据的处理也就越来越困难,为了适应能够处理各种各样的数据,hadoop提供了一系列的输入和输出格式控制,其目的很简单,就是能够解析各种输入文件,并产生需要的输出格式数据。
但是不管处理哪种格式的数据,都要与mapreduce结合起来,才能最大化的发挥hadoop的有点。
这部分也是hadoop的核心啊!
3.1、输入分片与记录
在讲HDFS的时候,说过,一个输入分片就是由单个map任务处理的输入块,一个分片的大小最好与hdfs的块大小相同。
每个分片被划分成若干个记录,每个记录就是一个键值对,map一个接一个的处理每条记录。
在数据库常见中,一个输入分片可以对应一个表的若干行,而一条记录对应一行(DBInputFormat)。
输入分片在hadoop中表示为InputSplit接口,有InputFormat创建的。
InputFormat负责产生输入分片并将他们分割成记录,其只是一个接口,具体任务有具体实现去做的。
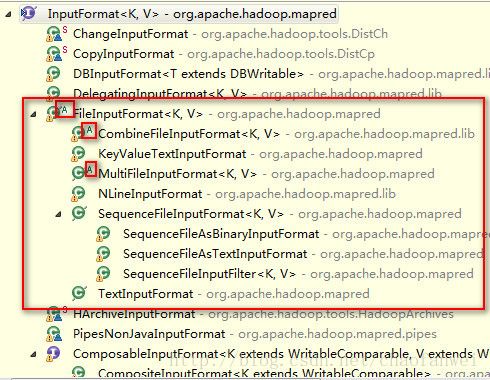
3.2、FileInputFormat
FileInputFormat是所有使用文件作为其数据源的InputFormat实现的基类,它提供了两个功能:一个定义哪些文件包含在作业的输入中;一个为输入文件产生分片的实现。把分片割成基类的作业有其子类实现,FileInputFormat是个抽象类。
FileInputFormat实现了把文件分区的功能,但它是怎么来实现了呢?需要先说三个参数:
属性名称 |
类型 |
默认值 |
描述 |
mapred.min.split.size |
Int |
1 |
一个文件分片的最小字节数 |
mapred.max.split.size |
Long |
Long.MAX_VALUE |
一个文件分片的最大字节数 |
dfs.block.size |
long |
64M |
HDFS中块大小 |
分片的大小有一个公式计算(参考FileInputFomat类的computeSplitSize()方法)
max(minimumSize,min(maximumSize,blockSize))
默认情况下: minimumSize < blockSize < maximumSize
FileInputFormat只分割大文件,即文件大小超过块大小的文件。
FileInputFormat生成的InputSplit是一整个文件(文件太小,未被分区,整个文件当成一个分区,供map任务处理)或该文件的一部分(文件大,被分区)。
3.3、常用的InputFormat实现
小文件与CombineFileInputFormat
虽然hadoop适合处理大文件,但在实际的情况中,大量的小文件处理是少不了的,因此hadoop提供了一个CombineFileInputFormat,它针对小文件而设计的,它把多个文件打包到一个分片中一般每个mapper可以处理更多的数据。
TextInputFormat
hadoop默认的InputFormat,每个记录的键是文件中行的偏移量,值为行内容。
KeyValueInputFormat
适合处理配置文件,文件中行中为key value格式的,如key=value类型的文件 ,key即为行中的key,value即为行中的value。
NLineInputFormat
也是为处理文本文件而开发的,它的特点是为每个map任务收到固定行数的输入,其他与TextInputFormat相似。
SequenceFileInputFormat(二进制输入)
hadoop的顺序文件格式存储格式存储二进制的键值对序列,由于顺序文件里面存储的就是map结构的数据,所以刚好可以有SequenceFileInputFormat 来进行处理。
DBInputFormat
顾名思义,用于使用jdbc从关系数据库中读取数据。
多种输入
MultipleInputs类可以用来处理多种输入格式的数据,如输入数据中包含文本类型和二进制类型的,这个时候就可以用 MultipleInputs来指定某个文件有哪种输入类型和哪个map函数来解析。
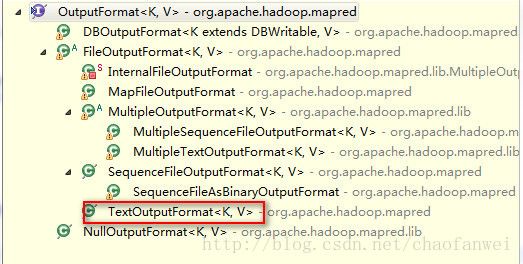
3.4、输出格式
既然有输入格式,就有输出格式,与输入格式对应。
默认的输出格式是TextOutputFormat,它把记录写成文本行,键值对可以是任意类型, 键值对中间默认用制表符分割。
3.5、hadoop特性
除了上面几点之外,还有计数器、排序、连接等需要关注,详细待后续吧。。。