实体-关系联合抽取:Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
论文地址:https://www.aclweb.org/anthology/P17-1113.pdf
文章标题:Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme(基于新标注方案的实体与关系联合抽取)ACL2017 Outstanding Paper
文章出处:中国科学院
作者对本文的报告PPT:http://t.cn/RXmunzm
Abstract
实体和关系联合抽取是信息抽取中的重要任务。为了解决这个问题,我们首先提出了一种新的标注方案,可以将联合提取任务转换为标注问题。然后,基于我们的标注方案,我们研究了不同的端到端模型来直接提取实体及其关系,而不是分别识别实体和关系。对远程监督方法产生的公开数据集进行实验,实验结果表明基于标注的方法优于现有的多数流水线和联合学习方法。此外,本文提出的端到端模型在公开数据集上取得了最好的效果。
一、Introduction
实体和关系的联合提取是从非结构化文本中同时检测实体提及并识别它们的语义关系,如图1所示。不同于从给定句子中提取关系词的开放式信息抽取(Open IE)(Banko et al., 2007),在本任务中,从一个可能不出现在给定句子中预定关系集中提取关系词。知识库的提取和自动构建是一个重要的问题。
传统方法以流水线的方式处理这个任务,即首先提取实体(Nadeau和Sekine,2007),然后识别它们之间的关系(Rink,2010)。这个分离的框架使得任务易于处理,并且每个组件可以更灵活。但它忽略了这两个子任务之间的相关性,每个子任务是一个独立的模型。实体识别的结果可能会影响关系分类的性能并导致错误传播(Li和Ji,2014)。
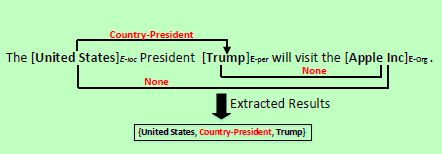
图一:任务的标准例句。“Country-President”是预定义关系集中的关系。
与流水线方法不同的是,联合学习框架是使用单一模型将实体和关系一起提取出来。它可以有效地整合实体和关系的信息,在这个任务中取得了较好的效果。然而,大多数现有的联合方法是基于特征的结构化系统(Li和Ji,2014; Miwa和Sasaki,2014; Yu和Lam,2010; Ren等,2017)。他们需要复杂的特征工程,并严重依赖其他NLP工具包,这也可能导致错误传播。为了减少特征提取的人工工作,最近(Miwa和Bansal,2016)提出了一种基于神经网络的端到端实体和关系提取方法。虽然联合模型可以在一个模型中同时表示实体和共享参数之间的关系,但它们也可以分别提取实体和关系,产生冗余信息。例如,图1中的句子包含三个实体:“United States”,“Trump”和“Apple Inc”。但只有“United States”和“Trump”才有固定的关系“Country-President”。实体“Apple Inc”与这个句子中的其他实体没有明显的关系。因此,从这个句子中提取的结果是{United Statese1,Country-Presidentr,Trumpe2},这里叫三元组。
在本文中,我们重点提取由两个实体和这两个实体之间的一个关系组成的三元组。因此,我们可以直接对三元组进行建模,而不是分别提取实体和关系。基于这个动机,我们提出了一个标注方案,并配以端到端的模型来解决这个问题。我们设计了一种新颖的标注方案,它包含实体信息和它们所持有的关系。基于这种标注方案,实体和关系的联合提取可以转化为标记问题。这样,我们也可以很容易地使用神经网络来建模任务,而不需要复杂的特征工程。
最近,基于LSTM(Hochreiter and Schmidhuber,1997)的端到端模型已经成功应用于各种标签任务:命名实体识别(Lample等,2016),CCG Supertagging(Vaswani等,2016),词块分割(Zhai等,2017)等。LSTM能够学习长期依赖性,这对序列建模任务是有利的。因此,基于我们的标注方案,我们研究了不同种类的基于LSTM的端到端模型来共同提取实体和关系。我们还修改了解码方法,增加了一个偏置损失,使其更适合我们的特殊标注。
我们提出的方法是一个监督学习算法。然而,实际上,手工标注具有大量实体和关系的训练集的过程耗费太大,并且容易出错。因此,我们通过远程监督方法(Ren et al., 2017)产生的公开数据集进行实验来验证我们的方法。实验结果表明我们的标注方案在这个任务中是有效的。另外,我们的端到端模型可以在公共数据集上取得最好的结果。
本文的主要贡献是:(1)提出了一种新的标注方案,联合提取实体和关系,可以很容易地将提取问题转化为标注任务。(2)基于我们的标注方案,我们研究了不同类型的端到端模型来解决问题。基于标记的方法比大多数现有的流水线和联合学习方法要好。(3)此外,我们还开发了具有偏置损失函数的端到端模型,以适应新型标注,它可以增强相关实体之间的关联。
二、Related Works
实体与关系抽取是构建知识库的重要步骤,可为许多NLP任务带来益处。两个主要框架已被广泛用于解决提取实体及其关系的问题。一个是流水线方法,另一个是联合学习方法。
流水线方法将这个任务视为两个分离的任务,即命名实体识别(NER)(Nadeau和Sekine,2007)和关系分类(RC)(Rink,2010)。经典的NER模型是线性统计模型,如隐马尔可夫模型(HMM)和条件随机场(CRF)(Passos等,2014; Luo等,2015)。最近,几个神经网络体系结构(Chiu和Nichols,2015; Huang等,2015; Lample等,2016)已经成功应用于NER,这被认为是一个连续的分词标记任务。现有的关系分类方法也可以分为基于手工特征的方法(Rink,2010; Kambhatla,2004)和基于神经网络的方法(Xu,2015a; Zheng et al., 2016; Zeng,2014; Xu,2015b; dos Santos ,2015)。
联合模型使用单一模型提取实体和关系。大多数联合方法是基于特征的结构化系统(Ren等,2017; Yang和Cardie,2013; Singh等,2013; Miwa和Sasaki,2014; Li和Ji,2014)。最近,(Miwa和Bansal,2016)使用基于LSTM的模型来提取实体和关系,这可以减少人工工作。
与上述方法不同的是,本文提出的方法是基于一种特殊的标记方式,使得我们可以很容易地使用端到端模型来提取结果而不需要NER(命名实体识别)和RC(关系分类)。端到端的方法是将输入句子映射成有意义的向量,然后返回产生一个序列。它广泛应用于机器翻译(Kalchbrenner和Blunsom,2013; Sutskever等,2014)和序列标注任务(Lample等,2016; Vaswani等,2016)。大多数方法使用双向LSTM来对输入句子进行编码,但是解码方法总是不同的。例如,(Lample等,2016)使用CRF层来解码标注序列,而(Vaswani等,2016; Katiyar和Cardie,2016)应用LSTM层来产生标注序列。
三、Method
我们提出了一种新的标注方案和一个具有偏置目标函数的端到端模型来共同提取实体及其关系。在本节中,我们首先介绍如何将提取问题转换为基于本文标注方法的标注问题。然后我们将详细说明用来提取结果的模型。
3.1、The Tagging Scheme(标注方案)

图二: “CP”是“Country-President”的简称,“CF”是“Company-Founder”的简称,是一个基于我们标注方案的例句的标准黄金标注方案。
图2是标注结果的示例。每个单词都被分配一个标签,用于提取结果。标签“O”代表“Other”标签,这意味着相应的单词与提取结果无关。除了“O”之外,其他标签由三部分组成:实体中的单词位置、关系类型和关系角色。我们使用“BIES”(Begin, Inside, End, Single)符号来表示单词在实体中的位置信息。关系类型信息是从一组预定义的关系中获得的,关系角色信息由数字“1”和“2”表示。提取的结果由三元组表示:(Entity1,RelationType,Entity2)。“1”表示该词属于三元组中的第一个实体,而“2”则属于该关系类型后面的第二个实体。因此,标签总数为Nt = 2 * 4 * | R | + 1,其中| R |是预定义的关系集的大小。
图2是一个说明我们的标注方法的例子。输入句子包含两个三元组:{United States, Country-President, Trump}和{Apple Inc, Company-Founder, Steven Paul Jobs},其中“Country-President”和“Company-Founder”是预定义的关系类型。United”,“States”,“Trump”,“Apple”,“Inc” ,“Steven”, “Paul”和“Jobs”等词都与最终提取的结果有关。因此,他们根据我们的特殊标签进行标注。例如“United”这个词是“United States”实体的第一个词,与“Country-President”关系有关,所以它的标签是“B-CP-1”。对应于“United States”的另一个实体“Trump”被标记为“S-CP-2”。此外,与最终结果无关的其他字词标记为“O”。
3.2、From Tag Sequence To Extracted Results(从标记序列到提取结果)
根据图2中的标注序列,我们知道“Trump”和“United States”具有相同的关系类型“Country-President”,“Apple Inc”和“Steven Paul Jobs”具有相同的关系类型“Company-Founder”。我们将具有相同关系类型的实体合并为一个三元组来获得最终结果。因此,“Trump”和“United States”可以合并为关系类型为“Country-President”的三联体。因为,“Trump”的关系角色是“2”,“United States”是“1”,最终的结果是{United States, CountryPresident, Trump}。这同样适用于{Apple Inc, Company-Founder, Steven Paul Jobs}。
此外,如果一个句子包含两个或更多具有相同关系类型的三元组,我们将每两个元素按照最接近的原则组合成一个三元组。例如,如果图2中的关系类型“Country-President”是“Country-President”,则在给定句子中将有四个具有相同关系类型的实体。 “United States”最接近实体“Trump”,而“Apple Inc”最接近“Jobs”,因此结果将是{United States, Company-Founder, Trump}和{Apple Inc, Company-Founder, Steven Paul Jobs}。
在本文中,我们只考虑一个实体属于一个三元组的情况,并且在将来的工作中考虑重叠关系的识别。
3.3、The End-to-end Model(端到端模型)
近年来,基于神经网络的端到端模型在序列标注任务中得到了广泛的应用。在本文中,我们采用了一个端到端的模型来生成标注序列,如图3所示。它包含双向长短期记忆(Bi-LSTM)层来对输入句子和具有偏置损失的基于LSTM的解码层进行编码。偏置损失可以增强实体标签的相关性。
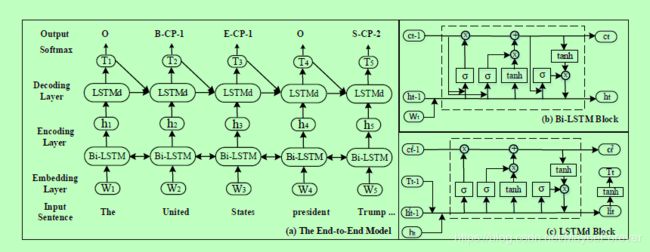
图三:我们的模型图。 (a)端到端模型的体系结构,(b)Bi-LSTM编码层中的LSTM记忆块,(c)LSTMd解码层中的LSTM记忆块。
(1)Bi-LSTM编码层
在序列标注问题中,Bi-LSTM编码层已被证明有效捕获每个单词的语义信息。它包含前向Lstm层,后向Lstm层和连接层。词嵌入层将one-hot表示的单词转换为嵌入向量。因此,一个单词序列可以表示为W = {w1,… wt,wt+1 … wn},其中wt∈Rd是对应于句中第t个单词的d维词向量,n是给定句子的长度。在词嵌入层之后,有两个平行的LSTM层:前向LSTM层和后向LSTM层。 LSTM体系结构由一组递归连接的子网(称为记忆块)组成。每个时间步是一个LSTM记忆块。 Bi-LSTM编码层中的LSTM记忆块用于根据前一个隐藏向量ht-1、前一个单元向量ct-1和当前输入词表示wt计算当前隐藏向量ht。其结构图如图3(b)所示,具体操作定义如下:
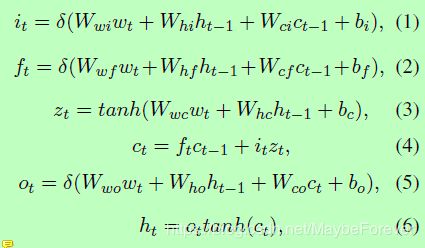
其中i,f和o分别是输入门、忘记门和输出门,b是偏置项,c是记忆元,W(.)是参数。对于每个词wt,前向LSTM层将通过考虑从词w1到wt的上下文信息(其被标记为ht(→))来编码wt。类似地,后向LSTM层将基于从wn到wt的上下文信息来编码wt,其被标记为ht(←)。最后,我们连接和来表示字t的编码信息,表示为ht=[ht(→),ht(←)]。
(2)LSTM解码器层
我们也采用LSTM结构来生成标注序列。当检测到单词wt的标注时,解码层的输入为:从Bi-LSTM编码层获得的ht,以前的预测标签表示Tt-1,以前的单元值:ct-1,以及解码层中的前一个隐藏向量ht-1。图3(c)显示了LSTMd记忆块的结构图,具体操作定义如下:
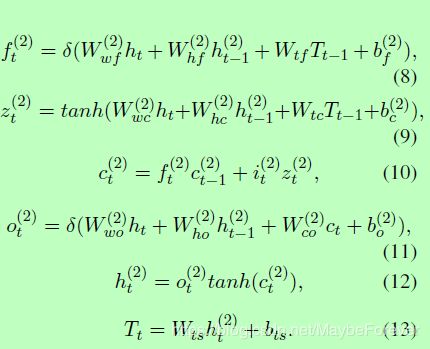
最终的softmax层根据标签预测向量Tt计算归一化实体标签概率:
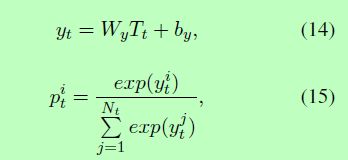
Wy是softmax矩阵,Nt是标签总数。由于T与标签嵌入类似,并且LSTM能够学习长期相关性,所以解码方式可以对标签交互进行建模。
(3)偏置目标函数
我们训练我们的模型来最大化数据的对数似然性,我们使用的优化方法是Hinton在(Tieleman和Hinton,2012)提出的RMSprop。目标函数可以定义为:
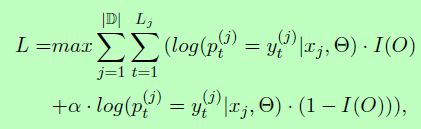
|D|是训练集的大小,Lj是句子xj的长度,yi(j)是单词xj中词t的标注,pt(j)是在公式15中定义的归一化标注概率。此外,I(O)是一个开关函数,以区分标注‘O’与可指示结果的相关标注间的损失。他被定义如下:
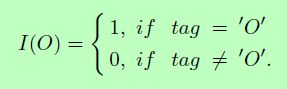
α是偏置权重,α越大,对模型中相关标注的影响越大。
四、Experiments
4.1、Experimental setting
数据集为了评估我们方法的性能,我们使用由远程监督方法(Ren et al., 2017)生成的公共数据集NYT。大量的训练数据可以通过远程监控的方式获得,无需人工标注。测试集是手工标记以确保其质量。训练数据总共包含353k三元组,测试集包含3,880三元组。此外,关系集的大小是24。
评估我们采用标准Precision(Prec)、Recall(Rec)和F1分数来评估结果。与经典方法不同,我们的方法可以在不知道实体类型信息的情况下提取三元组。换句话说,我们没有使用实体类型的标签来训练模型,因此我们不需要在评估中考虑实体类型。当三元组的关系类型和两个对应的实体的头部偏移都是正确的时,这个三元组被认为是正确的。此外,还给出了正确标注关系提及,并排除了“None”标签(Ren等,2017; Li和Ji,2014; Miwa和Bansal,2016)。我们通过从测试集中随机抽取10%的数据来创建验证集,并使用剩余的数据作为基于(Ren等,2017)的建议的评估。我们对每个实验运行10次,然后报告平均结果和它们的标准偏差,如表1所示。
超参数我们的模型由一个BiLSTM编码层和一个具有偏置目标函数的LSTM解码层组成。在编码部分中使用的单词向量是通过在NYT训练语料库上运行word2vec(Mikolov等,2013)来开始的。词表示向量的维数为d = 300,我们使用嵌入层上的损失来对我们的调整网络,丢失率为0.5。编码层的lstm单元数为300,解码层数为600。对应于表1结果的偏置参数α为10。
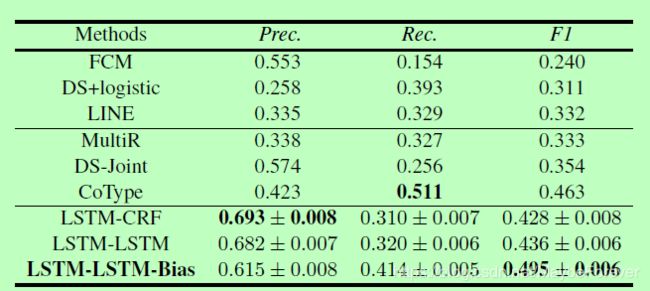
表一:提取两个实体及其关系的不同方法的预测结果。第一部分(从第一行到第三行)是流水线方法,第二部分(第四行到第六行)是联合提取方法。我们的标注方法在第三部分(第7到第9行)中显示。在这一部分,我们不仅报告准确率、召回率和F1的结果,我们还计算了它们的标准差。
基线我们将我们的方法与几种经典的三元组提取方法进行比较,这些方法可以分为以下几类:流水线方法、联合提取方法和基于标记方案的端到端方法。
对于流水线方法,我们遵循(Ren et al., 2017)的设置:NER结果由CoType(Ren等,2017)获得,然后应用几种经典的关系分类方法来检测关系。这些方法是:(1)DS-logistic(Mintz等,2009)是一种远程监督和基于特征的方法,它结合了监督IE和无监督IE特征的优点; (2)LINE(Tang等,2015)是一种网络嵌入方法,适用于任意类型的信息网络; (3)FCM(Gormley等,2015)是一个组合模型,它将词汇化的语言语境和词嵌入表示结合起来进行关系抽取。
本文所采用的联合提取方法如下:(4)DS-Joint(Li和Ji,2014)是一种监督方法,它使用结构化感知器在人注释的数据集上共同提取实体和关系。 (5)MultiR(Hoffmann等人,2011)是一种基于多实例学习算法的典型远程监督方法,用于对付有噪声的训练数据; (6)CoType(Ren et al., 2017)是一个领域无关的框架,将实体提及、关系提及、文本特征和类型标签联合嵌入到有意义的表示中。
此外,我们还将我们的方法与两种典型的端到端标注模型进行了比较:LSTMCRF(Lample等,2016)和LSTM-LSTM(Vaswani等,2016)。通过使用双向LSTM编码输入句子和条件随机场来预测实体标注序列,提出LSTM-CRF用于实体识别。与LSTM-CRF不同,LSTM-LSTM使用LSTM层来解码标注序列而不是CRF。它们被首次用于根据我们的标记方案共同提取实体和关系。
4.2、Experimental Results
我们展示了不同方法的结果,如表1所示。可以看出,我们的方法LSTM-LSTM-Bias在F1得分方面优于所有其他方法,与最佳方法CoType(Ren et al., 2017)相比,F1提高了3%。它显示了我们提出的方法的有效性。从表1还可以看出,联合提取方法优于流水线方法,标注方法优于大多数联合提取方法。这也验证了我们的标注方案对共同提取实体和关系的任务的有效性。
与传统方法相比,端到端模型的准确率显著提高。但是只有LSTM-LSTM-Bias可以更好地平衡准确率和召回率。原因可能是这些端到端模型都使用Bi-LSTM编码输入句子和不同的神经网络来解码结果。基于神经网络的方法可以很好地拟合数据。因此,他们可以很好地学习训练集的共同特征,并可能导致较低的可扩展性。我们还发现,基于我们的标注方案,LSTM-LSTM模型优于LSTM-CRF模型。因为,LSTM能够学习长期的依赖关系,CRF(Lafferty等,2001)擅长捕捉整个标注序列的联合概率。相关的标签可能相距很远。因此,LSTM解码方式比CRF好一些。 LSTM-LSTM-Bias增加了一个偏置权重,以增强实体标注的效果,减弱无效标注的影响。因此,在这个标注方案中,我们的方法可以比普通的LSTM解码方法更好。

表二:基于我们的标注方案的三元组元素的预测结果。
五、Analysis and Discussion
5.1、Error Analysis(错误分析)
在本文中,我们着重于提取由两个实体和一个关系组成的三元组。表1显示了任务的预测结果。只有当两个相应实体的关系类型和头部偏移量都是正确的时候,它才能处理三元组。为了找出影响端到端模型结果的因素,我们分析了预测三元组中每个元素的性能,如表2所示。E1和E2分别表示预测每个实体的性能。如果第一个实体的头部偏移是正确的,那么E1的实例是正确的,与E2相同。不管关系类型,如果两个对应实体的头部偏移都是正确的,则(E1,E2)的实例是正确的。
如表2所示,与E1和E2相比,(E1,E2)具有更高的准确率。但其召回率低于E1和E2。这意味着一些预测的实体不会形成一对。他们只获得E1而没有找到相应的E2,或者获得E2并且没有找到相应的E1。因此,它导致更多的单E和更少(E1,E2)对的预测。因此,实体对(E1,E2)比单个E具有更高的准确率和更低的召回率。另外,表1中的预测结果与表1中的预测结果相比,表2中的(E1,E2)这意味着3%的测试数据被预测为错误的,因为关系类型被预测为错误的。
5.2、Analysis of Biased Loss(偏置损失分析)
与LSTM-CRF和LSTM-LSTM不同的是,我们的方法偏向于关系标签来增强实体之间的联系。为了进一步分析偏置目标函数的影响,我们将每个端到端方法预测单个实体的比例可视化,如图4所示。单个实体是指那些找不到相应实体的实体。图4显示了是E1还是E2,我们的方法在单个实体上的比例相对较低。这意味着我们的方法可以有效地将两个实体关联起来,比较LSTM-CRF和LSTM-LSTM对关系标签关注不多。
此外,我们也将偏差参数α从1改变到20,预测结果如图5所示。如果α太大,会影响预测的准确率,如果α太小,召回率会下降。当α= 10时,LSTM-LSTMBias可以平衡准确率和召回率,并且可以达到最好的F1分数。
5.3、Case Study(案例分析)
在本节中,我们观察端到端方法的预测结果,然后选择几个有代表性的例子来说明这些方法的优缺点,如表3所示。每个例子包含三行,第一行是黄金标准,第二行和第三行分别是模型LSTM-LSTM和LSTM-LSTM-Bias的提取结果。
S1表示两个相关实体之间的距离彼此很远的情况,这使得更难以发现他们的关系。与LSTMLSTM相比,LSTM-LSTM-Bias使用偏置目标函数来增强实体之间的相关性。因此,在这个例子中,LSTM-LSTMBias可以提取两个相关的实体,而LSTMLSTM只能提取一个“Florida”实体,不能检测实体“Panama City Beach”。
S2是一个负面的例子,表明这些方法可能错误地预测了一个实体。Nuremberg和Germany实体之间没有任何指示性词语。另外,Germany和MiddleAges之间的“a *”形式可能容易误导它们之间存在“包含”关系的模式。通过将这种表达模式的一些样本添加到训练数据中可以解决问题。
S3是模型可以预测实体头部偏移量的情况,但是关系角色是错误的。 LSTM-LSTM将“Stephen A.Schwarzman”和“Blackstone Group”都视为实体E 1,并且找不到相应的E 2。虽然LSTM-LSMT-Bias可以找到实体对(E1,E2)它扭转了“Stephen A. Schwarzman”和“Blackstone Group”的角色。这说明LSTM-LSTM-Bias能够更好地预测实体对,但是在区分两个实体之间的关系方面还有待改进。
六、Conclusion
在本文中,我们提出了一种新的标注方案,并研究端到端模型来共同提取实体和关系。实验结果表明了我们提出的方法的有效性。但是在重叠关系的识别上还存在着一些缺陷。在未来的工作中,我们将用多个分类器来替换输出层中的softmax函数,这样一个词可以有多个标签。这样,一个单词可以出现在多个三元组结果中,可以解决重叠关系的问题。尽管我们的模型可以增强实体标注的效果,但是两个相应的实体之间的关联仍然需要在接下来的工作中进行细化。