mysql语法-DQL(select高级查询)
sql常用分类
- 1.DDL(数据定义语言)
- 2.DML(数据操作语言)
- 3.DQL(数据查询语言)
- 高级查询
- 1. 连接查询
- 2. 子查询
- in和exists的区别
- 小结:连接查询和子查询
- 3. 联合查询
1.DDL(数据定义语言)
DDL部分可以回顾上一篇文章:mysql语法-DDL(create、drop、alter)
2.DML(数据操作语言)
DML部分可以回顾上一篇文章:mysql语法-DML(insert、update、delete)
3.DQL(数据查询语言)
DQL基础查询可以回顾上一篇文章:mysql语法-DQL(select基础查询)
接下来记录一下查询的高级用法。
高级查询
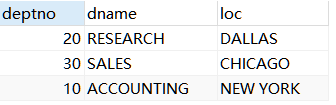
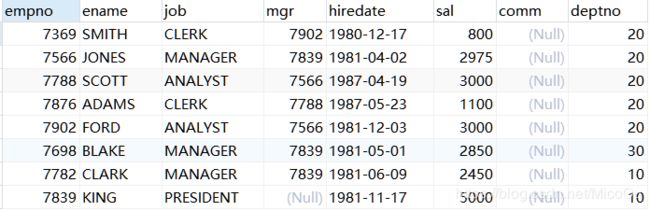
我们基于emp表和dept表进行查询。
emp表:
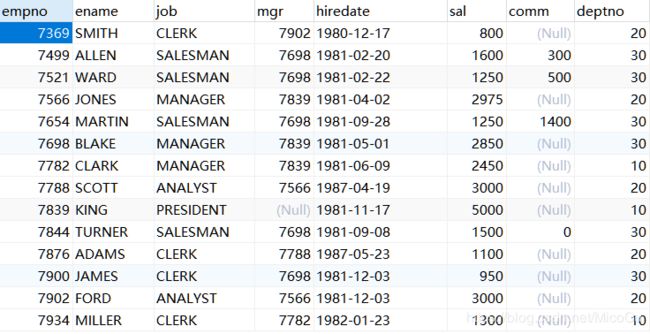
dept表:

1. 连接查询
1.1 笛卡尔积
直接查询两张表,最后的结果是笛卡尔积(两个集合所能组成的有序对)
emp表有14条记录,dept表有4条记录,一共查询出14*4=56条记录
select * from emp,dept;

1.2 内连接
内连接:多张表都匹配的记录(通用列)组成
特点:
无主从表之分,内连接与连接顺序无关(记录)
记录必须在多张表都匹配才能出现在结果集,不匹配就不会出现,比如dept的40号部门记录就没有出现
# 查询所有雇员及其部门信息
# 简单语法
select * from emp,dept where emp.deptno = dept.deptno;
#标准语法:inner join ... on 条件
select * from emp inner join dept on emp.deptno = dept.deptno;
## inner join ...using(通用列),
# 但是1.通用列的名称在多张表中必须一致才能使用
# 2.必须是等值=连接,不能大于小于
# 3.会掉重复列,比如deptno列只显示一列
select * from emp inner join dept using(deptno);
会出现重复列。

不会出现重复列。

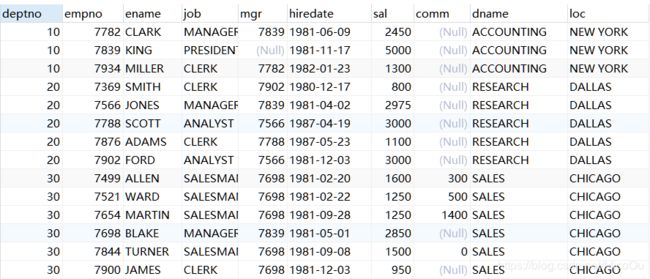
1.3 自然连接
自然连接:必须是等值连接,连接的字段必须一样
表中字段名称相等的字段进行连接,会自动去掉重复列
select * from emp natural join dept;
1.4 外连接
特点
外连接与连接顺序有关(区分主从表(驱动表/附属表))
以主表为驱动,依次在从表中寻找匹配的记录,如果匹配则连接并展示,否则以null填充
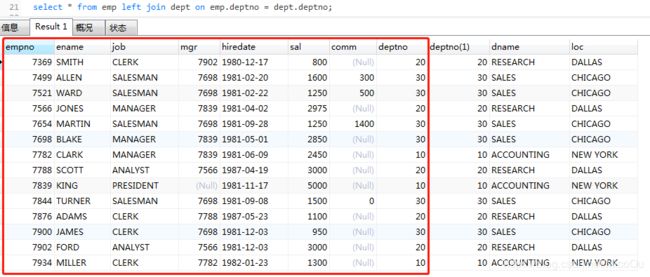
语法:left/right [outer] join ... on...
# 保留emp中所有记录,从dept表中寻找deptno匹配连接
select * from emp left join dept on emp.deptno = dept.deptno;
以emp表的记录顺序依次从dept表中找到匹配的值。
以dept表的记录顺序来依次从emp表中找到匹配的值。

# 保留dept表所有数据,依次从emp表中匹配连接,无匹配返回null
select * from dept left join emp on dept.deptno = emp.deptno;

1.5 自连接
以本身为镜像进行连接(自身连接自身)
# 查询员工及其领导的名称(员工和领导都在一张表上)
# 从e1表中的经理编号找到e2表中对应的员工编号,该员工编号对应的就是经理
select e1.ename,e2.ename as mgr from emp e1,emp e2 where e1.mgr = e2.empno;

2. 子查询
也叫嵌套查询,把查询出来的结果当作另外一个查询的条件
案例:查询员工编号为7788的员工所在部门的名称
内连接查询:
select dept.dname from dept inner join emp on dept.deptno = emp.deptno and emp.empno = 7788;
但是如果表的数据比较多,使用连接查询会非常慢,所以可以使用子查询
括号是子查询,优先执行
select dname from dept where deptno = (select deptno from emp where empno = 7788);
思路:
1.先筛选出emp表员工编号为7788的员工所在的部门编号;
2.然后dept表的部门编号=emp表的部门编号,查出dept表的部门名称。

案例:查询工资>2000的员工所在的部门信息。
单行子查询:子查询返回的结果是一条记录 可用= > <
多行子查询:子查询返回的结果是多条记录,可用:
=any : in >any:大于最小值 <any:小于最大值
<>all:不在 >all:大于最大值 <all:小于最小值
select * from dept where deptno in (select distinct deptno from emp where sal > 2000);
select * from dept where deptno = any (select distinct deptno from emp where sal > 2000);

嵌套层次越深,效率越低
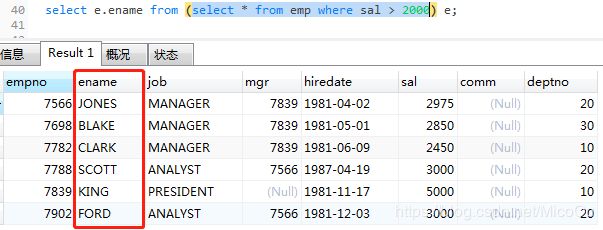
e是给括号内的查询结果命名,因为 from 关键字后要+表
select e.ename from(
select * from emp where sal > 2000) e;
in和exists的区别
where后面in的执行原理:主查询中的每一行在与in后面子查询语句的结果匹配时,子查询语句就重新执行遍历一遍。
所以在数据量极大的情况下,子查询在与主查询每匹配一次就重新遍历一次,总的时间就会变长。所以有时候性能甚至不如直接进行连接查询。
where后面exists的执行原理:主查询中每一行代入子查询进行匹配,匹配成功返回True,取得主表那一行数据;匹配失败返回False,不取该行数据。子查询不出结果,所以select的字段没有意义,一般用*。
exists的好处在于当子表数据量比较大的情况下,可以避免子表每匹配一次就进行全表扫描一次。
一般使用子查询的时候,对于性能一般可以这样区分:
1、当主表数据量大,子表数据量小,使用in。
2、当主表数据量小,子表数据量大,使用exists。
in
1.先执行子查询,再执行主查询
2.需要字段一一匹配,比如where后面要接字段
3.子查询必须返回结果集
select * from dept where deptno in (select deptno from emp where sal > 2000);
先执行子查询,获取工资>2000的部门编号,再执行主查询。

exists
1.先执行主查询,主查询遍历每条记录,在子查询中进行匹配,看是否出现匹配
2.不需要字段匹配,where后面不接字段
3.子查询不返回具体结果,返回True或False
#检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
#括号内查询出来很多条记录,注意不是单个字段
select * from dept where exists(select * from emp where sal > 2000 and emp.deptno = dept.deptno);

小结:连接查询和子查询
连接查询:如果最终结果分布在多张表,肯定用连接查询
子查询:如果最终结果只在一张表,可能只要用子查询就ok
实际工作中:连接和子查询一起用。
1.连接查询:容易思考,如果每张表的数据量较大,不适合直接连接,影响性能。(可先过滤筛选之后再连接)
2.子查询:有可能因为嵌套层次太多,影响性能。
查询员工编号为7788的员工的名称和所在部门的名称(分布在两张表)
两种思路:
1.先连接两张表--筛选7788
2.先筛选7788--再跟dept表连接(推荐)

3. 联合查询
union: 并集,所有的内容都查询,重复的显示一次
union all: 并集,所有的内容都显示,包括重复的
案例:查询20号部门或者员工工资>2000的员工的信息
# 去重后,有8条数据
select * from emp where deptno = 20
union
select * from emp where sal > 2000;
# 没有去重,有3条数据重复,重复的记录是条件为部门编号=20,同时工资也超过2000,因为只要查到一个条件就返回一次。
select * from emp where deptno = 20
union all
select * from emp where sal > 2000;
