【kaggle】泰坦尼克之灾(二)模型探索
第一篇:https://blog.csdn.net/Nicht_sehen/article/details/89741145
这一篇着重记录模型选择问题,不会过多做特征工程
数据处理
- 异:
增加Familysize 看家庭人数,增加Isalone看是否独自一人
drop 掉了’PassengerId’, ‘Cabin’, ‘Ticket’ - 同
Age,Embarked,Fare,Agecut, Farecut,Identify 处理相同
df_train=pd.read_csv("../input/train.csv")
df_test=pd.read_csv("../input/test.csv")
data_cleaner=[df_train,df_test]
for dataset in data_cleaner:
dataset['Age'].fillna(dataset['Age'].median(), inplace=True)
dataset['Embarked'].fillna(dataset['Embarked'].mode()[0], inplace=True)
dataset['Fare'].fillna(dataset['Fare'].median(), inplace=True)
dataset['Title'] = dataset['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0]
dataset['FareBin'] = pd.qcut(dataset['Fare'], 4)
dataset['AgeBin'] = pd.cut(dataset['Age'].astype(int), 5)
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
dataset['IsAlone'] = 1
dataset['IsAlone'].loc[dataset['FamilySize'] > 1] = 0
drop_column = ['PassengerId', 'Cabin', 'Ticket']
data1=df_train.copy()
data1.drop(drop_column, axis=1, inplace=True)
print(dataset.info())
print(data1.info())
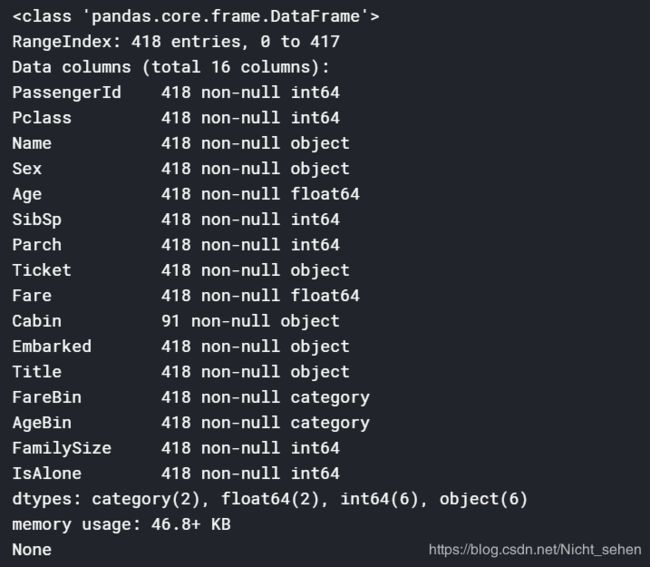
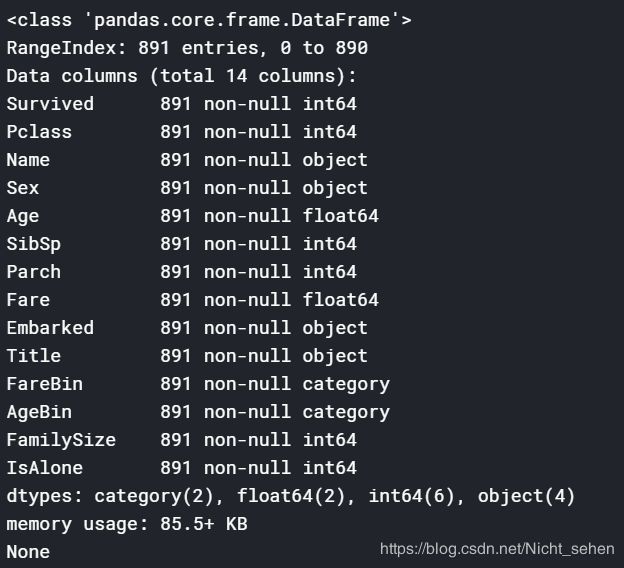
使用LabelEncoder对特征值进行编码
label = LabelEncoder()
for dataset in data_cleaner:
dataset['Sex_Code'] = label.fit_transform(dataset['Sex'])
dataset['Embarked_Code'] = label.fit_transform(dataset['Embarked'])
dataset['Title_Code'] = label.fit_transform(dataset['Title'])
dataset['AgeBin_Code'] = label.fit_transform(dataset['AgeBin'])
dataset['FareBin_Code'] = label.fit_transform(dataset['FareBin'])
data1['Sex_Code'] = label.fit_transform(data1['Sex'])
data1['Embarked_Code'] = label.fit_transform(data1['Embarked'])
data1['Title_Code'] = label.fit_transform(data1['Title'])
data1['AgeBin_Code'] = label.fit_transform(data1['AgeBin'])
data1['FareBin_Code'] = label.fit_transform(data1['FareBin'])
挑选特征并进行one-hot编码
Target = ['Survived']
data1_x = ['Sex','Pclass', 'Embarked', 'Title','SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone']
data1_x_calc = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code','SibSp', 'Parch', 'Age', 'Fare']
data1_xy = Target + data1_x
data1_x_bin = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code']
data1_xy_bin = Target + data1_x_bin
data1_dummy = pd.get_dummies(data1[data1_x])
data1_x_dummy = data1_dummy.columns.tolist()
data1_xy_dummy = Target + data1_x_dummy
data1.info()
dataset.info()
分配测试集训练集:
data_raw.describe(include = 'all')
train1_x, test1_x, train1_y, test1_y = model_selection.train_test_split(data1[data1_x_calc], data1[Target], random_state = 0)
train1_x_bin, test1_x_bin, train1_y_bin, test1_y_bin = model_selection.train_test_split(data1[data1_x_bin], data1[Target] , random_state = 0)
train1_x_dummy, test1_x_dummy, train1_y_dummy, test1_y_dummy = model_selection.train_test_split(data1_dummy[data1_x_dummy], data1[Target], random_state = 0)
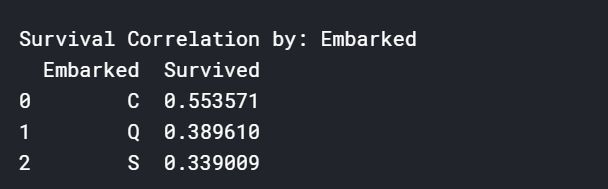
看一下各个特征和存活率之间的关系:
for x in data1_x:
if data1[x].dtype != 'float64':
print('Survival Correlation by:', x)
print(data1[[x, Target[0]]].groupby(x, as_index=False).mean())
print('-' * 10, '\n')
Sex和Pclass得出的结果和第一篇差不多

显然当Embarked为C时存活率更高
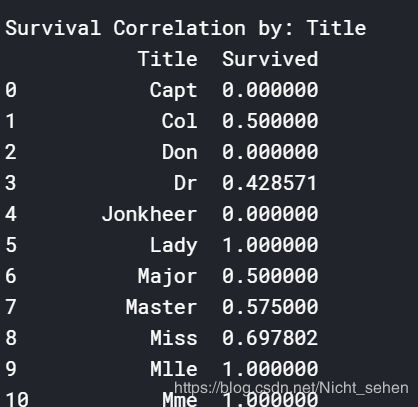
出乎意料的是Title有好几项都是1
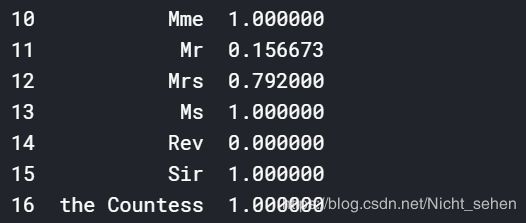

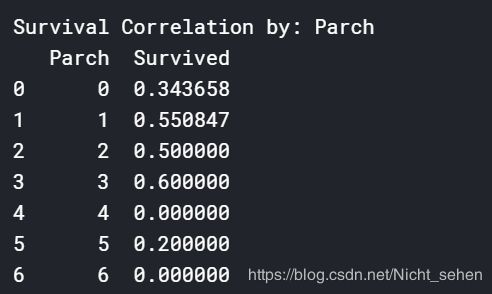


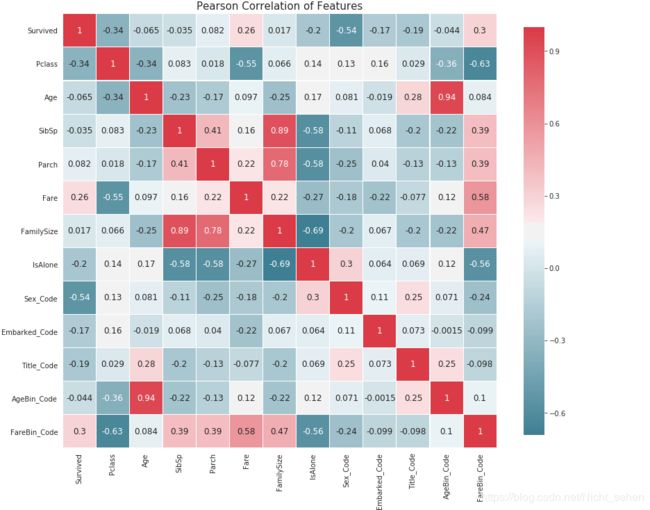
画一个热度图看看,因为后面还要用,所以封装起来了
def correlation_heatmap(df):
_, ax = plt.subplots(figsize=(14, 12))
colormap = sns.diverging_palette(220, 10, as_cmap=True)
_ = sns.heatmap(
df.corr(),
cmap=colormap,
square=True,
cbar_kws={'shrink': .9},
ax=ax,
annot=True,
linewidths=0.1, vmax=1.0, linecolor='white',
annot_kws={'fontsize': 12}
)
plt.title('Pearson Correlation of Features', y=1.05, size=15)
correlation_heatmap(data1)
模型选择
在这里,我选择将机器学习的算法做一个大合集看模型的效果
MLA = [
# Ensemble Methods
ensemble.AdaBoostClassifier(),
ensemble.BaggingClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(),
# Gaussian Processes
gaussian_process.GaussianProcessClassifier(),
# GLM
linear_model.LogisticRegressionCV(),
linear_model.PassiveAggressiveClassifier(),
linear_model.RidgeClassifierCV(),
linear_model.SGDClassifier(),
linear_model.Perceptron(),
# Navies Bayes
naive_bayes.BernoulliNB(),
naive_bayes.GaussianNB(),
# Nearest Neighbor
neighbors.KNeighborsClassifier(),
# SVM
svm.SVC(probability=True),
svm.NuSVC(probability=True),
svm.LinearSVC(),
# Trees
tree.DecisionTreeClassifier(),
tree.ExtraTreeClassifier(),
# Discriminant Analysis
discriminant_analysis.LinearDiscriminantAnalysis(),
discriminant_analysis.QuadraticDiscriminantAnalysis(),
# xgboost
XGBClassifier()
]
比较各个算法的得分
cv_split = model_selection.ShuffleSplit(n_splits=10, test_size=.3, train_size=.6,random_state=0)
MLA_columns = ['MLA Name', 'MLA Parameters', 'MLA Train Accuracy Mean', 'MLA Test Accuracy Mean',
'MLA Test Accuracy 3*STD', 'MLA Time']
MLA_compare = pd.DataFrame(columns=MLA_columns)
MLA_predict = data1[Target]
row_index = 0
for alg in MLA:
MLA_name = alg.__class__.__name__
MLA_compare.loc[row_index, 'MLA Name'] = MLA_name
MLA_compare.loc[row_index, 'MLA Parameters'] = str(alg.get_params())
cv_results = model_selection.cross_validate(alg, data1[data1_x_bin], data1[Target], cv=cv_split)
MLA_compare.loc[row_index, 'MLA Time'] = cv_results['fit_time'].mean()
MLA_compare.loc[row_index, 'MLA Train Accuracy Mean'] = cv_results['train_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy Mean'] = cv_results['test_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy 3*STD'] = cv_results['test_score'].std() * 3
alg.fit(data1[data1_x_bin], data1[Target])
MLA_predict[MLA_name] = alg.predict(data1[data1_x_bin])
row_index += 1
MLA_compare.sort_values(by=['MLA Test Accuracy Mean'], ascending=False, inplace=True)
MLA_compare


看不出出来差距的多少,而且太密集了,可视化一下看看:

前面的函数又用到了 :)
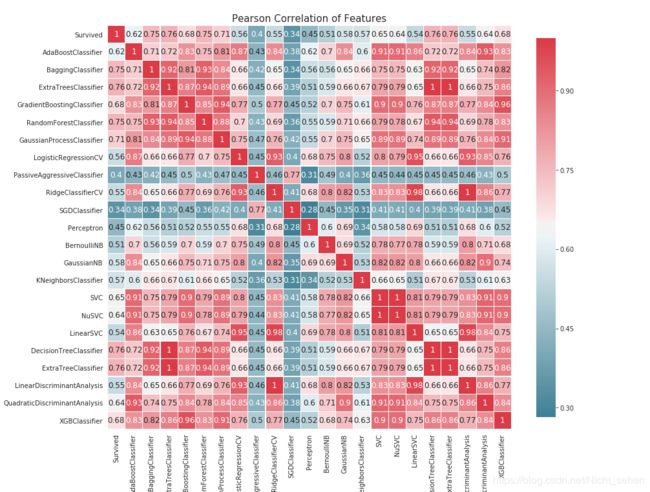
可以采用投票的方式:
vote_est = [
# Ensemble Methods
('ada', ensemble.AdaBoostClassifier()),
('bc', ensemble.BaggingClassifier()),
('etc', ensemble.ExtraTreesClassifier()),
('gbc', ensemble.GradientBoostingClassifier()),
('rfc', ensemble.RandomForestClassifier()),
# Gaussian Processes
('gpc', gaussian_process.GaussianProcessClassifier()),
# GLM
('lr', linear_model.LogisticRegressionCV()),
# Navies Bayes
('bnb', naive_bayes.BernoulliNB()),
('gnb', naive_bayes.GaussianNB()),
# Nearest Neighbor
('knn', neighbors.KNeighborsClassifier()),
# SVM
('svc', svm.SVC(probability=True)),
# xgboost:
('xgb', XGBClassifier())
]
vote_hard = ensemble.VotingClassifier(estimators=vote_est, voting='hard')
vote_hard_cv = model_selection.cross_validate(vote_hard, data1[data1_x_bin], data1[Target], cv=cv_split)
vote_hard.fit(data1[data1_x_bin], data1[Target])
print("Hard Voting Training w/bin score mean: {:.2f}".format(vote_hard_cv['train_score'].mean() * 100))
print("Hard Voting Test w/bin score mean: {:.2f}".format(vote_hard_cv['test_score'].mean() * 100))
print("Hard Voting Test w/bin score 3*std: +/- {:.2f}".format(vote_hard_cv['test_score'].std() * 100 * 3))
vote_soft = ensemble.VotingClassifier(estimators=vote_est, voting='soft')
vote_soft_cv = model_selection.cross_validate(vote_soft, data1[data1_x_bin], data1[Target], cv=cv_split)
vote_soft.fit(data1[data1_x_bin], data1[Target])
print("Soft Voting Training w/bin score mean: {:.2f}".format(vote_soft_cv['train_score'].mean() * 100))
print("Soft Voting Test w/bin score mean: {:.2f}".format(vote_soft_cv['test_score'].mean() * 100))
print("Soft Voting Test w/bin score 3*std: +/- {:.2f}".format(vote_soft_cv['test_score'].std() * 100 * 3))


开始对所有模型调参优化:
grid_n_estimator = [10, 50, 100, 300]
grid_ratio = [.1, .25, .5, .75, 1.0]
grid_learn = [.01, .03, .05, .1, .25]
grid_max_depth = [2, 4, 6, 8, 10, None]
grid_min_samples = [5, 10, .03, .05, .10]
grid_criterion = ['gini', 'entropy']
grid_bool = [True, False]
grid_seed = [0]
grid_param = [
[{
# AdaBoostClassifier
'n_estimators': grid_n_estimator, # default=50
'learning_rate': grid_learn, # default=1
'random_state': grid_seed
}],
[{
# BaggingClassifier
'n_estimators': grid_n_estimator, # default=10
'max_samples': grid_ratio, # default=1.0
'random_state': grid_seed
}],
[{
# ExtraTreesClassifier
'n_estimators': grid_n_estimator, # default=10
'criterion': grid_criterion, # default=”gini”
'max_depth': grid_max_depth, # default=None
'random_state': grid_seed
}],
[{
# GradientBoostingClassifier
'learning_rate': [.05],
'n_estimators': [300],
'max_depth': grid_max_depth, # default=3
'random_state': grid_seed
}],
[{
# RandomForestClassifier
'n_estimators': grid_n_estimator, # default=10
'criterion': grid_criterion, # default=”gini”
'max_depth': grid_max_depth, # default=None
'oob_score': [True],
'random_state': grid_seed
}],
[{
# GaussianProcessClassifier
'max_iter_predict': grid_n_estimator, # default: 100
'random_state': grid_seed
}],
[{
# LogisticRegressionCV
'fit_intercept': grid_bool, # default: True
'solver': ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'], # default: lbfgs
'random_state': grid_seed
}],
[{
# GaussianNB
'max_iter_predict': grid_n_estimator, #default: 100
'random_state': grid_seed
}],
[{
# KNeighborsClassifier
'n_neighbors': [1, 2, 3, 4, 5, 6, 7], # default: 5
'weights': ['uniform', 'distance'], # default = ‘uniform’
'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute']
}],
[{
# SVC
'C': [1, 2, 3, 4, 5], # default=1.0
'gamma': grid_ratio, # edfault: auto
'decision_function_shape': ['ovo', 'ovr'], # default:ovr
'probability': [True],
'random_state': grid_seed
}],
[{
# XGBClassifier
'learning_rate': grid_learn, # default: .3
'max_depth': [1, 2, 4, 6, 8, 10], # default 2
'n_estimators': grid_n_estimator,
'seed': grid_seed
}]
]
for clf, param in zip(vote_est, grid_param):
best_search = model_selection.GridSearchCV(estimator=clf[1], param_grid=param, cv=cv_split, scoring='roc_auc')
best_search.fit(data1[data1_x_bin], data1[Target])
best_param = best_search.best_params_
print('The best parameter for {} is {} with a runtime of {:.2f} seconds.'.format(clf[1].__class__.__name__,
best_param, run))
clf[1].set_params(**best_param)
grid_hard = ensemble.VotingClassifier(estimators = vote_est , voting = 'hard')
grid_hard_cv = model_selection.cross_validate(grid_hard, data1[data1_x_bin], data1[Target], cv = cv_split)
grid_hard.fit(data1[data1_x_bin], data1[Target])
print("Hard Voting w/Tuned Hyperparameters Training w/bin score mean: {:.2f}". format(grid_hard_cv['train_score'].mean()*100))
print("Hard Voting w/Tuned Hyperparameters Test w/bin score mean: {:.2f}". format(grid_hard_cv['test_score'].mean()*100))
print("Hard Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- {:.2f}". format(grid_hard_cv['test_score'].std()*100*3))
#Soft Vote or weighted probabilities w/Tuned Hyperparameters
grid_soft = ensemble.VotingClassifier(estimators = vote_est , voting = 'soft')
grid_soft_cv = model_selection.cross_validate(grid_soft, data1[data1_x_bin], data1[Target], cv = cv_split)
grid_soft.fit(data1[data1_x_bin], data1[Target])
print("Soft Voting w/Tuned Hyperparameters Training w/bin score mean: {:.2f}". format(grid_soft_cv['train_score'].mean()*100))
print("Soft Voting w/Tuned Hyperparameters Test w/bin score mean: {:.2f}". format(grid_soft_cv['test_score'].mean()*100))
print("Soft Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- {:.2f}". format(grid_soft_cv['test_score'].std()*100*3))