自动分类打标签!飞桨TSM模型帮你做视频理解
导读:目前互联网视频数据日益增多,用户观看短视频、小视频的时长也迅速增长,如何对海量的视频资源快速准确地分析、处理、归类是一个亟待解决的问题。视频理解技术可以多维度解析视频内容,理解视频语义,自动分类打标签,极大节省人工审核效率,节约成本;同时实现精准用户推荐,提升体验效果。
1. 视频理解之TSM
谈到视频理解,不得不给大家介绍一下新鲜出炉的视频理解技术之一:TSM(Temporal Shift Module)。TSM是由MIT和IBM Watson AI Lab的Ji Lin,Chuang Gan和SongHan等人提出的通过时间位移模拟3D建模达到效果和性能的平衡,提高视频理解能力的模块。
跟TSM最相关的视频理解模型当属Limin Wang等人在ECCV2016上发表的Temporal Segment Network (TSN)了。TSN模型从视频中采样N帧图像并通过最简单直接地对N帧图像分类结果进行平均的方式进行时序信息融合,取得了当时State-of-the-art的性能,并得到大规模的应用。考虑到TSN模型对时序信息的建模不够充分,以I3D,S3D, P3D等为代表的一系列工作通过3D卷积进行端到端联合时空建模,这一系列工作尽管能捕获时空特征,但是相比TSN,由2D卷积到3D卷积不可避免地引入了额外计算量。TSM巧妙的通过时间维度特征map移位的想法,理论上用零额外计算开销达到了不同帧之间特征融合联合建模的目的。
论文: Temporal Shift Module for Efficient VideoUnderstanding:https://arxiv.org/pdf/1811.08383v2.pdf
先看一下文中给出的测试视频示例:如果图片分别从左往右播放和从右往左播放,测试者会给出不同但是正确的理解结果,说明对视频的理解强依赖于视频的时序关系。

看起来很有意思,我们继续深入研究一下。
2. TSM关键技术介绍
在传统的图片分析的基础上,视频分析需要研究者补充关于时间信息(temporal information)的建模结构。目前,2D CNN和3D CNN是视频理解中最常用的两个方法:使用2D CNN 模型运算量少但会丧失部分时间信息;而使用3D CNN虽然效果好但运算量极大。面对这样的情况,MIT和IBM Watson AI Lab的Ji Lin,Chuang Gan和Song Han等人提出了Temporal Shift Module (TSM)模块。他们将时间位移模块嵌入2D CNN,从而可以在不添加任何额外的计算量和参数的情况下,轻松地达到与3D CNN效果相当的视频理解能力。

上图中矩阵的行和列分别表示特征图中的temporal和channel维度。在TSM模块中,将一部分的channel在temporal维度上向前位移一步,一部分的channel在temporal维度上向后位移一步,位移后的空缺补零。通过这种方式在特征图中引入temporal维度上的上下文交互,提高了在时间维度上的建模能力。
在此基础上,MIT和IBM Watson AI Lab的研发人员将模块进一步细分为适合在线视频使用的TSM模块和适合离线视频使用的TSM模块。
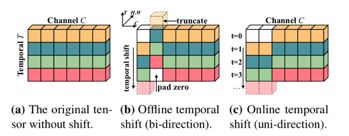
双向(bi-direction)的TSM模块可获取过去和未来的时空信息,适合高吞吐量的离线视频使用;而单向(uni-direction)的TSM模块仅可比对现在和过去的时空信息,适用于低延迟在线视频的识别。
好了,基本原理搞清楚了,可以找一个项目直接上手分析了。
3. 飞桨TSM快速上手
飞桨(PaddlePaddle)目前实现的版本是以ResNet-50作为主干网络的TSM模型。
3.1.数据准备
TSM的训练数据采用由DeepMind公布的Kinetics-400动作识别数据集。数据下载及准备请参考:
https://github.com/PaddlePaddle/models/blob/v1.5.1/PaddleCV/PaddleVideo/dataset/README.md
3.2.模型训练
数据准备完毕后,可以通过如下两种方式启动训练:
export FLAGS_fast_eager_deletion_mode=1
export FLAGS_eager_delete_tensor_gb=0.0
export FLAGS_fraction_of_gpu_memory_to_use=0.98
python train.py --model_name=TSM
--config=./configs/tsm.txt
--save_dir=checkpoints
--log_interval=10
--valid_interval=1
--pretrain=${path_to_pretrain_model}
bash scripts/train/train_tsm.sh
[1] 从头开始训练,需要加载在ImageNet上训练的ResNet50权重作为初始化参数,请下载此模型参数(https://paddlemodels.bj.bcebos.com/video_classification/ResNet50_pretrained.tar.gz)并解压,将上面启动脚本中的path_to_pretrain_model设置为解压之后的模型参数存放路径。如果没有手动下载并设置path_to_pretrain_model,则程序会自动下载并将参数保存在~/.paddle/weights/ResNet50_pretrained目录下面。
[2] 可下载已发布模型model(https://paddlemodels.bj.bcebos.com/video_classification/tsm_kinetics.tar.gz)通过--resume指定权重存放路径进行finetune等开发。
数据读取器说明:
模型读取Kinetics-400数据集中的mp4数据,每条数据抽取seg_num段,每段抽取1帧图像,对每帧图像做随机增强后,缩放至target_size。
训练策略:
采用Momentum优化算法训练,momentum=0.9
权重衰减系数为1e-4
模型评估
可通过如下两种方式进行模型评估:
python test.py --model_name=TSM
--config=configs/tsm.txt
--log_interval=1
--weights=$PATH_TO_WEIGHTS
bash scripts/test/test_tsm.sh
[1] 使用scripts/test/test_tsm.sh进行评估时,需要修改脚本中的--weights参数指定需要评估的权重。
[2] 若未指定--weights参数,脚本会下载已发布模型进行评估。
当取如下参数时,在Kinetics400的validation数据集的评估精度如下:
seg_num |
target_size |
Top-1 |
8 |
224 |
0.70 |
3.3.模型推断
可通过如下命令进行模型推断:
模型推断结果存储于TSM_infer_result中,通过pickle格式存储。
若未指定--weights参数,脚本会下载已发布模型进行推断。
python infer.py --model_name=TSM
--config=configs/tsm.txt
--log_interval=1
--weights=$PATH_TO_WEIGHTS
--filelist=$FILELIS3.4.效果实测
TOP5预测结果
分类 |
概率 |
Yoga(瑜伽) |
0.973069250584 |
stretching_leg(腿部拉伸) |
0.0223769713193 |
bending_back(向后弯腰) |
0.00322460732423 |
stretching_arm(上臂拉伸) |
0.00108245189767 |
Lunge(猛冲) |
0.00108245189767 |
可以看到,TSM模型准确的判断出了视频中是瑜伽(yoga)动作,而且预测概率0.97也是足够高,完全可以在商业中应用起来。
赶紧来试试吧!
想与更多的深度学习开发者交流,请加入飞桨官方QQ群:432676488。
如果您想详细了解更多飞桨PaddlePaddle的相关内容,请参阅以下文档或点击阅读原文。
官网地址:https://www.paddlepaddle.org.cn
项目地址:
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/PaddleVideo
最后给大家推荐一个GPU福利 - Tesla V100免费算力!配合PaddleHub能让模型原地起飞~ 扫描下方二维码申请~

