Linux杂录
Linux大概也是过了一遍了,现在来做一个总结,路线:内核控制路径->中断->进程调度与进程描述符->内存描述符与虚拟内存->文件系统与块设备->内存分配。(很多东西借助了其他博客)进程的进程调度算法、文件的IO调度算法、内存的伙伴和slab算法等。
内核控制路径分为异常(包括系统调用)、中断、内核线程。抽象来说内核线程就是内核自己的一些日常工作;有时候上面的用户态进程需要麻烦内核做一些只有内核态才能做的事比如分配页表内存(请页机制)、比如进行进程调度等,此时内核进入异常模式;有时候下面的硬件中断源遇到了比如网卡缓冲区来了数据、比如定时器到达了定时时间等事件、比如除法寄存器遇到了除数为0的浮点错误等,需要交由内核进行进一步处理,此时内核进入中断模式。因此整理下来这三条内核控制路径加起来大概就是内核每天需要做的事情。进入异常模式中的系统调用时我们称内核处于进程上下文,进入中断模式时我们称内核处于中断上下文。这两个上下文都需要内核收拾好前一个任务的相关寄存器值即上下文,然后进入下一个任务的上下文,这种情况下中断(中断优先级非常高)来了就进入中断上下文,中断完成后接着进入进程上下文或者内核线程。
内核控制路径可能出现的情况是共享了相同的临界区,从而导致进程抢占时前一个临界区的值没保存而被后一个临界区修改了。 比如中断和异常共享了一个等待队列,异常本来正在该临界区读写,后来被抢占了前者上下文收拾好,但临界区里的数据并没有保存,就被后一个给重新修改了,之后前者再回去看临界区里的值已经没有了。针对这种情况需要我们在内核控制路径间共享临界区的地方禁止本地中断并加上自旋锁(一般都是中断进行抢占,禁用了本地中断这个中断可能去到另外一个核执行,同样也会访问这个临界区,所以还要加上自旋锁,避免这个中断再用该临界区)。然而如果是用户进程间都会访问的临界区(中断不会访问),这时我们就不用禁止本地中断了,直接信号量就可(用户进程执行时间一般由用户程序控制,时间会较长,有时还需要睡眠等待资源)。如果只是内核线程间的抢占则直接自旋锁就可以了。
这里提一下信号量、自旋锁和信号,信号量类似于互斥锁,但可以用于读写情况,不用每次只有一个进程访问,它与自旋锁不同的地方在于自旋锁适用于进程短暂访问临界区的情况,比如就修改一个flag,因此不会陷入睡眠而是浪费CPU开始自旋,而信号量常用在访问临界区很长的情况下,此时等待信号量的进程会进入等待队列睡眠,睡眠的进程只是在这个临界区上睡眠,依旧可以去干其他事情。信号类似于用户态进程自己实现了中断,中断有thread_info->preempt_count的bitmap记录当前是否处在中断情况,信号也有一个sigqueue结构体记录当前是否有信号来,我们通过sigaction注册一个信号,然后sigqueue()发送信号,直接发送至对方进程task_struct结构体中的sigqueue中然后唤醒该进程,每次进程被唤醒时都会检查sigqueue是否有未决信号,有就根据注册的函数去做就可以了,信号还有一点是mask,有sigprocmask进行处理,mask可以屏蔽某些信号,避免打断当前的信号任务。中断还有一个irq_desc[]记录中断号,其中0x80是系统调用的中断号。
#题外话:提到spinlock再提一下rcu,rcu是一种用于高效读写的锁,spinlock则是用在互斥临界区,rcu里面用到了spinlock用于管理rcu里面的几个队列,rcu有订阅发布机制和副本宽限期写入机制
写:
spin_lock(&foo_mutex);
old_fp=gbl_foo;
*new_fp=*old_fp;
new_fp->a=new_a; #把new_a写入gbl_foo新指针
rcu_assign_pointer(gbl_foo,new_fp); #判断可写
spin_unlock(&foo_mutex);
synchronize_rcu(); #用于等待读者全部退出写着开始写
读:
rcu_read_lock();
rcu_deference(gbl_foo)->a; #判断可读
rcu_read_unlock(); #和read_lock两者用于保持一个读者的RCU临界区,该临界区内不能
发生抢占,因为里面用到了preempt_disable和preempt_enable。#当有写者就将写者rcu_head加入cpu[n]的每cpu变量的rcu_data的nxtlist,cpu会每时钟检测一次,当有写者就唤醒rcu软中断进行synchronize_rcu(),里面会判断rcu.completion变量。rcu初始化在内核的CPU上,start_kernel()->rcu_init(),为每个CPU初始化RCU相关结构。rcu_data里有curlist记录当前等待宽限期完成的回调函数、nxtlist、donelist记录宽限期结束后将curlist的值移至该链表上,当上一个等待回调函数处理完后又有新注册的回调函数就将taillist中间链表上的数据移至curlist上并开启新的宽限期等待。三个链表以及quiescbatch记录当前是否等待切换完成、passed_quiesc记录是否经历了一次宽限期、batch记录每一次宽限期的批次(判断这个写者需要在哪里进入),rcu_ctrlblk的completed变量赋值给quiescbatch。(瞎想瞎说)三个链表的思想跟TCP/IP协议栈接收缓存区的三个队列(receive队列、out_of_order队列、prequeue队列)有点像,batch的思想跟oracle等数据库里的多进程读写里的时间戳版本也有点相像,数据库这个打算开一个新博客介绍,地址等写完了再附上来。RCU经常用在路由表的查询(读远大于写)等情况,不过路由表查询好像也从哈希改为flow了,之后再把这一块知识整理一遍。
中断由于是抢占且高优先级,要求需要被快速响应,如果中断运行时间过长那么用户进程能感到明显卡顿。因此后来将一些耗时的中断放入软中断(也被称为可延迟函数),当硬中断得到响应退出后会触发soft_irq运行,如果软中断又运行了过长时间则转为ksoftirqd内核函数自行进行调度。软中断运行的同时硬中断又可以接着接收中断信号,避免信号丢失,但运行软中断时会屏蔽下一个软中断,避免嵌套抢占,但软中断结束后下一个软中断还可以接着运行,并没有丢弃。这些都记录在preempt_count中。
至于tasklet和workqueue:softirqd经常用于对性能敏感的子系统,因为其结束后还会去检查软中断有没有被触发,常用于如网络层、SCSI层和内核定时器等,而tasklet封装了softirqd,不可重用,更加易用,速度也相对快,而workqueue则是一种创建内核线程的机制,这样当有了下半部时我们交由workqueue建立内核线程去延迟执行,随遇而安而不讲究及时,并且工作队列由于全权交由内核线程,不同于softirqd和tasklet的前面部分(softirqd转为ksoftirqd是可以睡眠的),可以睡眠调度。
很久很久以前,不存在内核抢占,那么进程的任务都会一直做直到做完,或者进入一些等待条件代码让其放弃CPU,这样的特点就是很多进程的时间会分配不均导致响应慢。随着用户进程数量慢慢的增加,启用了内核抢占,此时进行进程调度就会由内核分配的时间片来决定,而内核的时间片又取决于task_struct中的进程优先级等值。内核抢占的出现导致了内核控制路径不再是一个进程一条路走到黑,而是会被其他进程抢占掉。
a.当进程时间片用完时内核会自动调度下一个排队在就绪队列中的进程,而之前那个被抢占的进程会进入就绪队列等待内核的下一次唤醒。
b.当进程需要等待某种资源而自行放弃CPU时,内核会调度该进程去到相应资源的等待队列,等待磁盘I/O的放入磁盘I/O的等待队列,等待epoll的放入epoll的等待队列...当资源拿到手后再进入就绪队列。
关于等待队列的:
sleep_on()置为TASK_UNINTERRUPTIBLE
sleep_on_timeout()设置是否超时
interruptible_sleep_on()设置为TASK_INTERRUPTIBLE
interruptible_sleep_on_timeout()
sched_yield()如果有优先级更高的进程在等待,则将当前进程放入就绪队列末端,没有则该进程接着运行,常用于多线程。
关于interruptible和uninterruptible,两者都会被放入等待队列,前者可以被信号唤醒,
而后者只能等待资源获取成功才能被显示唤醒,如果资源一直拿不到那么就会一直阻塞,
kill -9也杀不了。每次从中断上下文。后来转为了wait_event()函数,相应的用wake_up()函数唤醒。
wait_queue_head_t
init_waitqueue_head()
wait_event()中由于prepare_to_wait()
#注此处设置TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE(常用于磁盘等I/O,不好去打扰)
#调用前需要禁用本地中断+自旋锁,之后调用add_wait_queue()和set_current_state(),
可能怕中断程序也使用了该等待队列作为临界区并且设置状态。最后调用schedule()、finish_wait(),
管理等待队列上的数据。调度类抽象出了一个sched_class,里面有一系列入队出队任务函数,还有switch_to()、yield_task()等等,由CFS调度器和RT调度器自己实现。一个调度体对应一个task_struct或者是一个task_group。task_struct中有sched_entity *se和sched_rt_entity *rt两种,前者对应cfs_rq调度器(红黑树),属于公平调度器类策略;后者对应rt_rq调度器(优先级bitmap+双向链表),属于实时调度器类策略,他们最终都反映在rq类(内核中调度框架只识别rq),其中有nr_running记录当期那就绪队列中的进程数量。调度策略有CFS调度策略->SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE、实时调度策略->SCHED_RR、SCHED_FIFO。实时进程rt相比于普通进程cfs的调度优先级要更高,需要优先处理,RR和FIFO都是高优先级实时进程可抢占。CFS把CPU总时间按运行队列的所有se权重分配给每个se,每个se使用cpu的顺序有他们已使用的CPU虚拟时间(vruntime)决定,故已使用的虚拟时间越少,那么在运行队列中的位置越靠左,再次被调度执行的概率也越高。并保证在某个时间周期运行队列的所有se都能至少内调度一次。每一个cpu的时钟周期都触发一次schedule_tick函数调用,它会及时更新运行队列的时钟和load,然后调用当前进程的周期调度函数task_tick_fair,封装了entity_tick函数。每个时钟都会对当前进程执行时间进行检查,如果过长则置为TIF_NEED_RESCHED供主调度器在适当时机进行切换(check_preempt_tick/resched_task)。
cgroup是进程组控制机制,docker就使用了它+namespace隔离各种资源,cgroup由task_group进行管理,task_group呈树状结构,可以利用cgroup限制单个进程或多个进程使用资源的机制,对cpu和内存等资源实现精细化控制。如一个服务器上有两个服务,那么可以限制其中一组服务只使用部分几个核。cgroups与进程节点关联并且通过VFS把cgroups功能暴露给用户态,隐藏具体文件系统的实现细节,给用户态进程提供一套统一的API接口,cgroups实现了VFS提供的接口就可以注册到VFS中使内核可以读写这个系统。进程加入各个子系统的attach钩子函数,从而让进程跑在cgroup就绪队列中。
进程调度说完了,开始正式讲进程了。进程描述符task_struct是一个很庞大的结构体,目前已经讲过了其中的进程调度yu相关、信号量相关、进程状态相关的部分。接下来会讲内存描述符mm_struct部分,由该部分引申出mmap的文件系统、块系统读写、malloc内存管理相关部分。
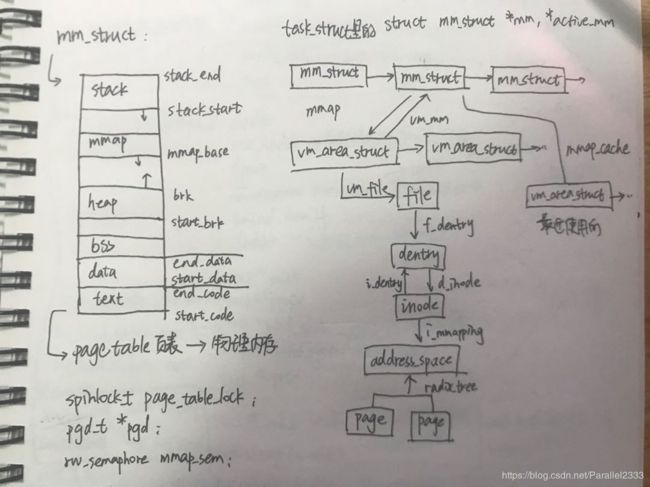
左图mm_struct结构体,右图堆结构与多线程。
先从左边的图开始讲起,每个task_struct结构里有一个mm_struct,记录该进程的内存空间,mm_struct中有左图中的堆、栈、data段、text段、bss段以及mmap区域。其中操作系统在编译时负责代码段、数据段、BSS段的加载,并在内存中为这些段分配空间,而栈则由操作系统动态分配和管理,堆由程序员自己管理。堆内存只有在系统调用malloc时会向上增长,在多线程的情况下可以看到堆内存的分配被称作brk,当使用malloc第一次向系统申请小于128KB的内存时,会通过sys_brk一次性申请132KB的堆内存放入进程内部,malloc的本质是brk或mmap(主进程使用sbrk(),线程使用mmap()),这132KB被称为arena,之后再需要malloc直接从arena中取,超出arena再向系统申请系统堆的大小。arena中存在很多个chunk,以链表的方式进行组织,当使用malloc后进行释放的时候,arena空间并不会及时释放回系统堆内存,而是继续留在进程中,释放的是chunk,会被添加至bins链表中(存储free的chunk的双链表)。之后再有malloc就优先直接从bins中获取。这里着重涉及将内存分配多线程的相关知识,主进程的arena成为main arena,由sbrk进行创建。当主进程中通过pthread_create创建了线程之后,就会通过mmap创建各自独立的thread arena,但线程arena数量不可能无限大,其他线程之间会公用arena,当堆不够用时一个thread arena会包含多个heap信息,毕竟是寄居在别的线程arena里的,所以占用别人的free chunk。但由于堆内存涉及系统调用以及上下文切换,会导致效率不如栈。而关于stack则由编译器自动分配释放,当你存在一个变量(静态变量直接由编译器完成,动态变量如Foo *由alloca分配)、一个参数等等,操作系统就会让你拥有一个栈,每个线程只要有自己的局部变量就肯定有自己的独立的栈,栈总额超过设定值就会溢出。
这里面的每一个连续区域都由一个虚拟内存区域vm_area_struct来表示,为什么会有那么多vm_area_struct主要原因是每块内存都有自己的映射方法或调用方法,有的可能来自于共享库、有的来自于可执行映像、有的来自于动态分配的内存区,因此每
个虚拟区间可能会有自己的处理方式,如文件映射就可能会有不同块设备映射,因此每个vm_area_struct对应一种vm_ops开关虚拟内存和请页机制,才能很好地控制特定的内存区。mm_struct通过链表的形式将这些vm_area_struct联系起来,当虚拟内存区域数量很多时会有一个红黑树结构便于我们快速查找虚拟内存区域,还会有一个cache保存当前经常经常用到的虚拟内存区域。虚拟内存区域有一个vm_ops,其中有open/close记录虚拟内存区域的打开和关闭,nopage记录是否缺页,缺页时就会通过nopage指向的do_page_fault()来处理缺页异常,malloc只是使用了brk来扩大了堆栈中的空间,但此时并没有关联到真正的物理地址。
如果是malloc引起的缺页异常,就会为缺页的地址关联一个pte(pgd->pmd->pte),pte会去映射一个空闲的物理页框(物理页框是由slab或伙伴算法分配的,根据需要的内存大小进行分配,但在堆栈空间中只扩大所需的字节大小),之后再将空闲页框与该进程的page_table进行关联。之后再重新去查找页表就可以找到malloc的地址了;如果是文件的缺页(文件缺页是通过查询address_space地址+偏移量查询mm_struct中pgd指向的page_table发现的,通过inode->imapping指向的address_space中的页进行查找,不在则去磁盘上找到相应的页预读进address_space,同时还会异步预读该页相关页面)。可以看到address_space主要是用在文件与进程内存的映射中。而程序中的malloc内存申请直接通过vm_area_struct与进程页表获得一个空闲物理页即可。malloc请页请的是一个空闲页框,这个页框是由内存分配机制得到的。
总结:malloc直接用get_free_page分配页,直接走伙伴算法;而内核中常用到的小结构或者用户态用到的小结构体我们使用kmalloc(通用缓存)、kmem_cache_create(专用缓存)来分配即可,走的是slab,而slab底层也是伙伴算法,只是在CPU层面从伙伴算法中取出页面并通过slab划分小内存。kmalloc是物理内存连续的,而vmalloc可以是不连续的,所以vmalloc需要更新页表来记录内存的分配。
slab分配算法采用kmem_cache中的obj存储内核或用户态小对象,伙伴算法分配的就是物理页,但很多时候比如一个300B的一个inode,分配一个4K的页就很浪费,现在的slab就有一系列的大小,分配最接近的slab即可。
从页框到内存机制到伙伴算法到slab/slub的逻辑我们来屡一下,在page结构中有一个union结构体,里面由address_space和s_mem,address_space关联的是用户态映射(malloc是直接基于伙伴算法的,可以这么理解,堆都是一次性132KB分的,而一个页4KB就是分配多个页),s_mem关联的是slab(kmalloc通过slab再到伙伴算法,slab大多针对各类小内存),而伙伴算法直接关联内存DDR硬件设备,直接将硬件内存划分为物理页。说明一个页可以整个页映射,也可以分成小部分(专用缓存和通用缓存)的slab内存,供inode、task_struct、nf_conn等内核小结构体分配内存,避免直接分配一个页造成内存的浪费。
对于slab来说会在kmem_cache_init中创建出cache_chain链表,连接着各种大小的slab的kmem_cache,比如32B kmem_cache、64B的kmem_cache等等,每个kmem_cache关联的是同一种大小的obj,如32B的kmem_cache关联的就是所有32B内存大小的obj(obj就是分配给小对象的内存)。调用kmem_cache_create函数其实就是从kmem_cache中取出一种大小的obj们。每个slab内部是由kmem_bufctl记录下一个空闲的obj的。
slab的作用在于每node记录了三个slab链表(空闲slab链表、部分空闲slab链表、满slab链表),每cpu(本地缓存和本地共享缓存)需要用到小内存就从每node上的空闲链表中获取到slab,放入(每CPU的)entry的obj结构体中。
对于slab来说三个链表很容易导致空闲slab的使用不及时,slub的优化就是每node只管理部分空闲slab链表和满slab链表,每CPU直接将node里的slab放入,slab中有obj结构体,obj由每CPU结构体中的free_list来管理。
每个vm_area_struct会对应一个vm_file,其下能够找到特定的inode。inode是内核中的文件,而file是用户进程空间的文件,每个进程会以不同的方式访问同一个inode。inode->imapping指向的就是一个大名鼎鼎的address_space(文件系统在mount的时候通过super_block(记录该文件系统的所有inode/block/使用量剩余量等信息),通过super_block我们可以找到inode(一个inode代表内核的一个文件,一个inode对应一个address_space))。address_space页高速缓存的好处在于实现了每进程4GB得到伟大宏图,但同时多进程写回页面都要经过页高速缓存机制,再统一写回磁盘,因此会存在脏页、写回不及时等问题,这是会影响高性能系统的。
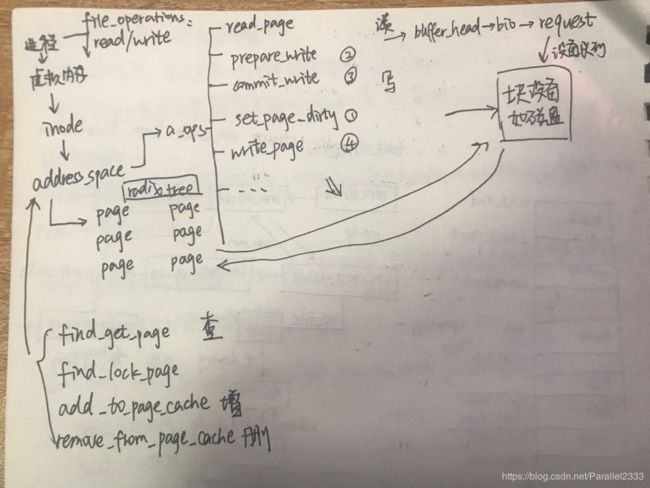
文件与用户层的关联是file_operations,与块设备的关联主要是address_space_operations,其中定义了针对每个设备块的读写方法 。文件从VFS读接口sys_read接着往下讲就是从address_space(find_get_page())所在的基数树上查找页面,address_space是一棵树,树上挂的是该进程访问这个inode常用的页面,如果页面找到了,则直接拷贝至缓冲区,如果没有找到则需要进行预读取(如果预读成功还会异步预读,读该页面关联的其他页面),将数据从磁盘读到页高速缓存(address_space)上,之后再去基数树上找页面读取即可。page的mapping指向的address_space结构上有一个mapping->a_ops->is_partially_uptodate用于记录脏页是否需要同步磁盘更新;mapping->a_ops->readpage(file,page)用于磁盘读入后加入页缓存机制返回给用户所调用的方法;对于写而言当要写的页不在页缓存中,则会在缓存中分配一个空闲项,同时用prepare_write创建一个写请求,等到数据从用户空间拷贝到内核缓冲相应的页上,就可以通过commit_write()写入磁盘。用户只需调用mapping->a_ops->SetPageDirty(page),之后内核会异步通过mapping->a_ops->writepage(file,page)把页写回;写回的时候会开启一个pdflush内核线程来完成。在readpage中,会构造一个buffer_head(其回调为end_buffer_async_read),然后调用submit_bh根据buffer_head构造bio(bio的回调为end_bio_bh_io_sync)发起读请求(bio会由进程记录在task->plug队列中,队列中将bio调度为request,当队列足够大或者schedule()前,会着手处理队列里的request),submit_bh中使用submit_bio将bio请求发送给指定块设备。submit_bio调用generic_make_request循环转发bio,调用__make_request最后送到块设备的dispatch queue队列上,在送的过程中会有IO Schedule(IO电梯,会进行再一次的合并),之前的plug中bio merge至同一个请求,不能合并则放至一个新的request中(回调为request_fn),IO电梯中又会进一步合并。再之后就是块设备如磁盘对request进行处理,大功告成。这里的IO调度在磁盘块设备上很多时候是多个进程共同读写的,因此需要调度出一个好的方法加快读写速度。