《中文文本信息抽取模型与方法研究》3:事件抽取模式的自动获取
传统的信息抽取系统大多是基于模式匹配的,因此,如何自动获取抽取模式就成为信息抽取中的一个核心问题。本章提出了一种从未标注的中文文本中基于自扩展策略自动获取时间抽取模式的算法,该算法从少数几个种子抽取模式开始,通过一个增量迭代的过程发现新模式,每一轮迭代从三个层次对抽取模式进行扩展,然后采用类似于TF/IDF的评估方法对产生的候选模式进行评估,选择得分最高的几个模式并入到当前模式集。
相关研究分五类:手工创建抽取模式的信息抽取系统、基于人工语料标注的抽取模式学习系统、基于人工语料分类的抽取模式学些系统、基于WordNet/HowNet和语料标注的抽取模式学习系统和基于种子模式的自扩展抽取模式获取系统。
3.3 面向中文文本的抽取模式获取难点
自动获取抽取模式又包含如下四个子问题:
- 中文文本信息抽取中抽取模式的表示
- 抽取模式库的组织
- 如何从未标注的中文文本中自动产生候选抽取模式
- 候选模式的评估,即怎样的抽取模式是“好”的模式
3.4 基于自扩展策略的中文文本抽取模式自动获取
一般来说,自扩展获取抽取模式无需用户提供大量的手工标注语料,只在初始阶段要求用户提供部分已知信息,利用这些信息以滚雪球的方式展开自扩展学习过程,具有启动速度快的优点,曾在词的歧义消解、通用概念发现、词典构建中得到较早的应用。后来又用于抽取模式的自动学习过程。自扩展方法的关键是寻找未知信息与已知信息之间的链接点,利用同一个信息由不同模式表达、同一模式又可以表达不同信息的特点,使得模式与信息成为相互的链接点;
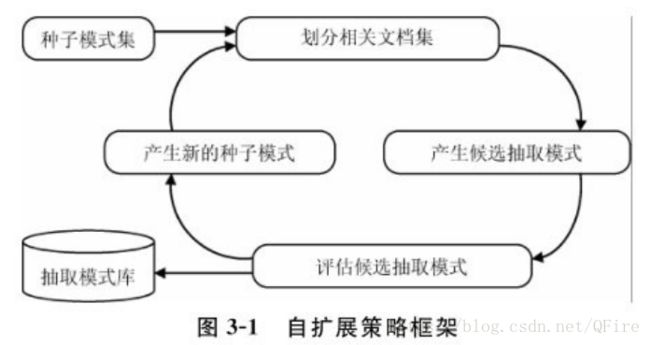
(1)初始化:首先采用手工的方式选择几个事件抽取模式作为种子模式。例如,对于“职务变动”场景,手工选择的种子模式包括“组织任命某人为某职位”和“某人出任某职位”等一些模式。
(2)迭代过程:
- 划分相关文档集:系统根据当前的种子模式集将文档集划分为两部分,即和场景相关的文档集和不相关文档集。
- 生成新的抽取模式:该过程通过不同的策略从已有的抽取模式以及和场景相关文档集中扩展生成候选抽取模式。
- 对候选抽取模式评估:依据一定的策略对候选抽取模式打分,依据分值再对候选抽取模式进行排序
- 产生新的种子模式集:将分值高的候选抽取模式加入种子模式集。
- 返回步骤1.
(3)构建抽取模式库:每一轮迭代将分值高的候选抽取模式并入当前种子模式集构成抽取模式库,经过一定次数的迭代或者系统收敛后,抽取模式库中就包含了用于该场景的最好抽取模式。
本章将一个事件抽取模式用一个四元组表示:{
四个阶段:
(1)文档预处理:句子切分(分成单句)、分词和词性标注(ICTCLAS),中文命名实体识别(自定义时间表达式等),浅层句法分析(识别名词短语和动词短语等)。
(2)文档划分:将输入的原始文档集依据现有的抽取模式集进行划分,根据和场景的相关性大小划分为场景相关文档集和不相关文档集。
(3)产生候选模式:基于抽取模式中动词同义的模式扩展(同义词词林或Word2Vec),主动语态和被动语态之间的相互扩展,基于相同语义项从相关文档集中扩展抽取模式。
(4)候选模式评估:类似TF/IDF
3.5 基于抽取模式的中文文本事件抽取
模式匹配是较成熟的技术,如KMP、编译器等。但是这些算法用于中文文本的事件模式匹配不太合适。一方面,事件抽取模式是文本中句法到语义的映射,是一种能够传递某种特定类型事件信息的语言表达形式。这种模式反映了自然语言中某种语义约束或句式约束,比传统的文本模式要复杂得多。另一方面,由于汉语的复杂性,中文文本中同一语义类存在大量同义词替代现象,这也增加了事件模式匹配的难度。本章的中文文本事件信息抽取中的模式匹配分为两步:概念语义类搜索和事件模式匹配。
概念语义类搜索主要从经过文本预处理的新文档中搜索当前所匹配的模式中存在的概念语义类。首先搜索模式中的动词概念语义类,在搜索时基于语义的词语相似度进行匹配《基于语义的词语相似度计算》。当在一个语句中搜索到该模式的动词概念语义类后,再在该语句中搜索模式中的名词性概念语义类,这些语义类一般对应到一个相应的命名实体或名词性词组。对这些概念语义类都要进行相应的标识,这些含有相应的概念语义类的句子就作为候选的语句继续进行下面的事件模式匹配。
在对候选语句进行事件模式匹配前,已经对这些语句进行了分词、词性标注以及场景相关类型的命名实体识别。具体的事件模式匹配过程如下:
(1)对候选语句过滤掉修饰性词语和中文停用词。
(2)生成候选语句对应的特征向量。即将动词性概念语义类以及其前后的相关类型命名实体或名词性短语对应的命名实体类型或语义类,生成该语句的特征向量:Ts = {
(3)比较当前模式和候选语句特征向量中动词性概念语义类前后的实体类型或语义类是否一致,如果有两个命名实体类别或语义类匹配,则进行下一步。
(4)将当前模式对应的向量Tp和该候选语句生成的向量Ts用传统的余弦公式计算两者的相似度,当相似度大于一定阈值时,就认为该候选语句和当前模式匹配,是一个特定类型事件的表述语句。
事件模板的填充:基于模式匹配从新文本文档中找到一个特定类型的事件表述语句之后,依据当前的事件抽取模式和事件模板的对应关系,对该语句进行事件信息的抽取,并将相应的信息填充到事件模板中。这一步需要对事件表述语句中是否出现否定词、时态对事件性质的影响等问题进行处理,然后依据事件模式中的语义类和事件模板中的槽之间的对应关系将该事件表述语句表述的事件信息填充到相应的事件模板中。