TSN视频识别详解
原作者给出的torch版本的代码,看起来有点不习惯,但比caffe版本好多了。paper在此
但光流提取及视频列表生成还是到原来的TSN repo.
总体:
稀疏时间采样策略及视频级监督。
Two-stream及卷积模型在拟合大尺度时间上有些力不从心,这主要因为它们的接近时间上下文背景有限,比如仅仅在单帧或几段clips上操作。复杂的运动时间跨度大,简单的网络结构可能失败,而TSN是视频级别的,能够拟合整个视频的动态。TSN综合了以上两种模型,由空间stream卷积和时间stream卷积组成,在每个视频小段进行预测行为的类别,然后就得到了视频级的预测。
对于整个视频V,分成K段(segments),得到如下公式:
![]()
每个小段对应的卷积函数为F(Tk;W),W表示卷积参数,是共享的,g将所有的多个小段的信息组合得到一致性类别假设,在此之后H预测整个视频的class,当然H的激活函数是softmax,损失函数是交叉熵。
思路如下:
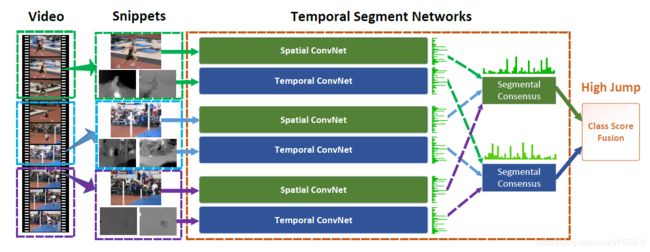
将视频小段选取一帧做空间卷积,小段中每帧提取光流做时间卷积,然后得到时间和空间维度的segments信息,再经过类别分数融合得到最终的结果。
网络结构:
BN-inception结构应用于Two-stream,TSN也是基于Two-stream来做的。
1)单张RGB图通常是在某个时间点,缺少上下帧的连续信息。堆叠了RGB difference作为另外一个输入。
2)通过估计单应矩阵(homography matrix)和补偿相机运动(考虑到拍视频时的相机移动)提取扭曲光流(warped)。扭曲光流压制背景移动(相机移动造成的)使得移动集中在运动的东西上。
1)空间网络的输入是RGB,考虑到数据量问题,很容易想到在ImageNet上的预训练模型作为初始化;
2)通过线性变换将光流离散化到(0,255),将RGB通道卷积层的权重由时间网络通道数进行平均,并复制过来。
上面的两个操作减少过拟合。
通过BN层将激活值转变到高斯分布,能加速收敛,但在此过程中仍有可能导致过拟合,因为激活分布是有偏估计,为何?因为训练的样本是有限的。故而在经预训练模型进行初始化后,除了第一层,固定BN层的均值和方差。为何除去第一层?这是因为光流分布与RGB图像是不同的,第一层卷积后的激活有不同的分布需要重新估计均值和方差。这种固定BN层参数的方法叫做partial BN。
在BN-inception结构后增加额外的dropout层,减少过拟合。dropout ratio 对空间和时间卷积网络分布设置为0.8/0.7.
数据扩增防止过拟合:
1)corner crop:从图像角落或者中心crop,防止注意力集中在图像中心;
2)尺度和比例改变:固定输入为256*340,并经过上面的crop,其中HW的大小从{256,224,192,168}中选择,最后resize成224*224用于训练。
作者经过试验,发现三个模态的输入(光流+扭曲光流+RGB)TSN得到UCF101最佳94.2%
下面看代码:
1-(扭曲)光流提取
def run_optical_flow(vid_item, dev_id=0):
vid_path = vid_item[0]
vid_id = vid_item[1]
vid_name = vid_path.split('/')[-1].split('.')[0]
out_full_path = os.path.join(out_path, vid_name)
try:
os.mkdir(out_full_path)
except OSError:
pass
current = current_process()
dev_id = (int(current._identity[0]) - 1) % NUM_GPU
image_path = '{}/img'.format(out_full_path)
flow_x_path = '{}/flow_x'.format(out_full_path)
flow_y_path = '{}/flow_y'.format(out_full_path)
cmd = os.path.join(df_path + 'build/extract_gpu')+' -f {} -x {} -y {} -i {} -b 20 -t 1 -d {} -s 1 -o {} -w {} -h {}'.format(
quote(vid_path), quote(flow_x_path), quote(flow_y_path), quote(image_path), dev_id, out_format, new_size[0], new_size[1])
os.system(cmd)
print('{} {} done'.format(vid_id, vid_name))
sys.stdout.flush()
return True
def run_warp_optical_flow(vid_item, dev_id=0):
vid_path = vid_item[0]
vid_id = vid_item[1]
vid_name = vid_path.split('/')[-1].split('.')[0]
out_full_path = os.path.join(out_path, vid_name)
try:
os.mkdir(out_full_path)
except OSError:
pass
current = current_process()
dev_id = (int(current._identity[0]) - 1) % NUM_GPU
flow_x_path = '{}/flow_x'.format(out_full_path)
flow_y_path = '{}/flow_y'.format(out_full_path)
cmd = os.path.join(df_path + 'build/extract_warp_gpu')+' -f {} -x {} -y {} -b 20 -t 1 -d {} -s 1 -o {}'.format(
vid_path, flow_x_path, flow_y_path, dev_id, out_format)
os.system(cmd)
print('warp on {} {} done'.format(vid_id, vid_name))
sys.stdout.flush()
return True只看这个还是看不懂光流是怎么提取的,说实话这个写得复杂了,因为还要调用工具提取,该工具是cpp写的,需要编译
2-BN-inception
这是一个inception的版本,就是inceptionV2,是谷歌2015年提出的,增加BN层的原因是为了解决内部协变量偏移问题。
预训练模型可以是resnet101、bninception、inceptionV3,这就是模型的arch或者称为backbone,输入的模态可以是RGB,RGBdiff,FLOW/wrap flow。
时间留给我的不多了。
下面TSM吧。
另外有相关问题可以加入QQ群讨论,不设微信群
QQ群:868373192
语音图像视频深度-学习群