Python+opencv 人脸识别----阔别8年后重学编程的点点滴滴
因为疫情已经在家里困了一个月零5天了,在家辅导幼儿园小朋友作业,其余时间没什么事,想着阔别了8年之久的编程工作,看着最近的科技产品越来越发达,还是想自己编点东西玩玩,网上搜了搜python的学习,这就开始吧。 —2020年2月29日
先立个Flag放到这,希望经过系统的学习和实验,能够完成这样一个效果:
1、摄像头立在公司门口,经过的员工进行人脸识别,记录来单位的时间。
2、再结合一个红外摄像头还是什么的,对该员工进行温度测量,并记录。
3、加个喇叭,体温正常了问个好,让员工开心上班;温度不正常了发出警告。
4、再有什么功能了再想。
然后一起学习,一起尝试着做出来吧。
鉴于目前什么都不会,先来第一步,让电脑认识我。
1、openCV人脸识别器cv2.face
1、环境搭建
之前的环境搭建业费了些事,不过网上有很多文章,大家可以看看。
至于cv2.face,我昨晚又下载了2个小时才弄好。
简单的说就是之前 pip install opencv-python 时安装的cv2不包含人脸识别部分,需要重新pip
首先把老的删掉,pip uninstall opencv-python,把之前安装的cv2删除,然后pip install opencv-contrib-python,安装新的包。
安装时很费劲,速度只有几k,还经常中断,不知道其他人怎么样,我是一遍一遍的重试,总会成功的,欢迎知道解决方案的朋友留言,谢谢大家。
2、人脸照片准备
做人脸识别,首先得让及其认识人,openCV中认人的方法就是通过足够的照片,来认识到一个人脸部的特征,然后看到新照片时才能认识。
SO,第一步准备照片。我准备了三个人的照片,妻子,儿子和我自己的。
准备的照片按照规则命名,并放在对应的文件夹里。 按照规则命名,里面的照片名也是1、2、3…这样的,好让程序循环读入。
按照规则命名,里面的照片名也是1、2、3…这样的,好让程序循环读入。
3、代码实现
主要是学习了beyond_LH 的文章,谢谢beyond_LH 的无私分享。
文章地址如下:
beyong_LH写的识别黄家驹,黄家强兄弟的程序
大部分程序实现借鉴了上面文章的写法,针对自己的想法改了一些具体应用,思路是一样的。
首先导入包
import cv2
import os
import numpy as np
然后是检测人脸的函数
其中‘haarcascade_frontalface_default.xml’我是在python的目录里搜索到复制出来的,网上说自己没有的话需要下载,大家可以自己找。
另外目前做到的水平是一张图片只识别一张脸,能成功后再尝试多人同时出镜。
#检测人脸
def detect_face(img):
#将检测图片转化为灰度图,因为openCV人脸识别用的是灰度图像
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#加载OpenCV人脸检测分类器Haar
face_cascade = cv2.CascadeClassifier('D:/PycharmProjects/Tset2/haarcascade_frontalface_default.xml')
#检测多尺度图像,返回值是一张脸部区域信息的列表(x,y,width,height)
faces = face_cascade.detectMultiScale(gray,scaleFactor=1.2,minNeighbors=5)
#如果没有检测到人脸,返回原始图像
if (len(faces) == 0):
return None,None
#目前假设只有一张脸,x,y为左上角坐标,w,h为矩形的宽高
(x,y,w,h) = faces[0]
#返回图像的正面部分
return gray[y:y+w,x:x+h],faces[0]
做一个读取图片的函数,返回人脸信息和对应的标签信息
这里就和之前建立文件夹和文件的命名规则对应了。
#该函数用于读取所有的训练图像,从每个图像检测人脸并将返回两个相同大小的列表,分别为脸部信息和标签
def prepare_training_data(data_folder_path):
# 获取数据文件夹中的目录(每个主题一个目录)
dirs = os.listdir(data_folder_path)
#建立两个列表,分别保存所有的脸部信息和标签
faces = []
labels = []
#浏览每个目录并访问其中的图像
for dir_name in dirs:
#dir_name(str类型)既标签
label = int(dir_name)
#建立包含当前主题主题图像的目录路径
subject_dir_path = data_folder_path + '/' + dir_name
#获取主题目录下图像名称
subject_images_names = os.listdir(subject_dir_path)
#浏览每张图片并检测脸部,然后将脸部信息添加到脸部列表
for image_name in subject_images_names:
#建立图像路径
image_path = subject_dir_path + '/' + image_name
#读取图像
image = cv2.imread(image_path)
#显示图像0.1s
cv2.imshow('Training on Image...',image)
cv2.waitKey(50)
#脸部检测
face,rect = detect_face(image)
#忽略未检测到得脸部,其他的加入列表
if face is not None:
faces.append(face)
labels.append(label)
print(str(image_path)+' '+str(label))
cv2.waitKey(1)
cv2.destroyAllWindows()
#返回人脸和标签列表
return faces,labels
调用训练函数,得到脸部图片列表和对应的标签列表
参数是data_folder_path 存放训练图片的文件夹路径
#调用训练函数
faces,labels = prepare_training_data('f:/FaceRegTest')
人脸特征识别!!!
最牛逼的步骤,但是都是大神们实现好的,我们只需要调用就行了
首次使用或者更新训练图片时要让识别器进行训练
#创建LBPH识别器并开始训练,也可以使用Eigen或者Fisher识别器
face_recognizer = cv2.face.LBPHFaceRecognizer_create()
face_recognizer.train(faces,np.array(labels))
每次训练都要耗费一定的时间,不想每次训练的话就提前把训练好的结果保存,下次使用时直接加载
#创建LBPH识别器并开始训练,也可以使用Eigen或者Fisher识别器
face_recognizer = cv2.face.LBPHFaceRecognizer_create()
#不想每次都训练,就把训练好的结果保存到xml文件,下次运行时直接加载该文件即可
#所生成的xml文件不小,50多长图片,8M多,这50多张图一共6M多,想训练得更准确文件会有多大?
# face_recognizer.train(faces,np.array(labels))
# face_recognizer.save('F:/face_recongnizer.xml')
#读取训练模型,有版本用的方法是.load()
face_recognizer.read('F:/face_recongnizer.xml')
在图像上画框
#根据给定的x,y坐标和宽高在图上绘制矩形
def draw_rect(img,rect):
(x,y,w,h) = rect
cv2.rectangle(img,(x,y),(x+w,y+h),(128,128,0),2)
在框上方写人名
#根据给定的(x,y)坐标标示出人名
def draw_text(img,text,x,y):
cv2.putText(img,text,(x,y),cv2.FONT_HERSHEY_COMPLEX,1,(128,128,0),2)
建立一个名字列表,顺序同自己建立的文件夹对应。
有的写法上直接把图片和名字用一个类似于电话号码本文件的东西做对应,就不用在程序中这么标明了,想扩展应用场景,图片和人名的对应方式需要改进
#建立标签与人名的映射列表(标签只能为整数)
subjects = ['Song JY','LJ','Song YT']
识别函数,此函数识别传递进来的图像中的人物并在检测到的脸部周围绘制一个矩形及其名称,并把绘制过矩形框及名字的图片返回
#识别函数,此函数识别传递进来的图像中的人物并在检测到的脸部周围绘制一个矩形及其名称
def predict(test_img):
#生成图像的副本,以保护原始图像
img = test_img
#检测人脸
face,rect = detect_face(img)
# print(face)
#预测人脸
if face is not None:
label = face_recognizer.predict(face)
print(label)
#获取由人脸识别器返回的相应标签的名称
label_text = subjects[label[0]]
#在检测到的人脸周围画一个矩形;标出识别出的名字
draw_rect(img,rect)
draw_text(img,label_text,rect[0],rect[1] - 5)
#返回预测的图像
return img
return None
笔记本自带摄像头的识别
#摄像头实时识别
def detect_Cap():
#打开摄像头
cap = cv2.VideoCapture(0)
#从摄像头循环获取图片,0.5s一张
while(1):
#获取图像
ret,frame = cap.read()
#print((frame.shape))
#执行预测
predicted_img1 = predict(frame)
#frame非空,但是不包含人脸信息
if predicted_img1 is not None:
size = predicted_img1.shape
img_h = size[0]
img_w = size[1]
window_h = 600
window_w = img_w * (600 / img_h)
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Image', int(window_w), int(window_h))
cv2.imshow('Image', predicted_img1)
#刚开摄像头时frame非空,但是frame还没有把我照进去,所以检测不到人脸
#代码重复了,不好看,回头改写
elif predicted_img1 is None:
size = frame.shape
img_h = size[0]
img_w = size[1]
window_h = 600
window_w = img_w * (600 / img_h)
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Image', int(window_w), int(window_h))
cv2.imshow('Image', frame)
#按Q退出,延时0.5s(自己定的时间,电脑老了,怕反应不过来)
if cv2.waitKey(500) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
识别一个指定图片中人脸的方法
# #加载测试图像 'f:/4.jpg'
def detect_Img(fileName):
test_img1 = cv2.imread(fileName)
#执行预测
predicted_img1 = predict(test_img1)
size = predicted_img1.shape
img_h = size[0]
img_w = size[1]
window_h = 600
window_w = img_w * (600/img_h)
# print('window_h '+ str(window_h)+' window_w '+str(int(window_w)))
cv2.namedWindow('Image',cv2.WINDOW_NORMAL)
cv2.resizeWindow('Image',int(window_w),int(window_h)
cv2.imshow('Image',predicted_img1)
cv2.waitKey(0)
cv2.destroyAllWindows()
一个小细节,Python在print时不会自动转化类型,要注意转换,否则会报错,如:
print('window_h'+window_h)这个是错误的,两者类型不一样需要写成print('window_h'+str(window_h))
最后,函数调用,执行识别
# detect_Img('f:/13.jpg')#识别单张图片
detect_Cap()#使用摄像头识别
4、下面放出整个程序的完整代码
import cv2
import os
import numpy as np
#检测人脸
def detect_face(img):
#将检测图片转化为灰度图,因为openCV人脸识别用的是灰度图像
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#加载OpenCV人脸检测分类器Haar
face_cascade = cv2.CascadeClassifier('D:/PycharmProjects/Tset2/haarcascade_frontalface_default.xml')
#检测多尺度图像,返回值是一张脸部区域信息的列表(x,y,width,height)
faces = face_cascade.detectMultiScale(gray,scaleFactor=1.2,minNeighbors=5)
#如果没有检测到人脸,返回原始图像
if (len(faces) == 0):
return None,None
#目前假设只有一张脸,x,y为左上角坐标,w,h为矩形的宽高
(x,y,w,h) = faces[0]
#返回图像的正面部分
return gray[y:y+w,x:x+h],faces[0]
#该函数用于读取所有的训练图像,从每个图像检测人脸并将返回两个相同大小的列表,分别为脸部信息和标签
def prepare_training_data(data_folder_path):
# 获取数据文件夹中的目录(每个主题一个目录)
dirs = os.listdir(data_folder_path)
#建立两个列表,分别保存所有的脸部信息和标签
faces = []
labels = []
#浏览每个目录并访问其中的图像
for dir_name in dirs:
#dir_name(str类型)既标签
label = int(dir_name)
#建立包含当前主题主题图像的目录路径
subject_dir_path = data_folder_path + '/' + dir_name
#获取主题目录下图像名称
subject_images_names = os.listdir(subject_dir_path)
#浏览每张图片并检测脸部,然后将脸部信息添加到脸部列表
for image_name in subject_images_names:
#建立图像路径
image_path = subject_dir_path + '/' + image_name
#读取图像
image = cv2.imread(image_path)
#显示图像0.1s
cv2.imshow('Training on Image...',image)
cv2.waitKey(50)
#脸部检测
face,rect = detect_face(image)
#忽略未检测到得脸部,其他的加入列表
if face is not None:
faces.append(face)
labels.append(label)
print(str(image_path)+' '+str(label))
cv2.waitKey(1)
cv2.destroyAllWindows()
#返回人脸和标签列表
return faces,labels
#调用训练函数
# faces,labels = prepare_training_data('f:/FaceRegTest')
#创建LBPH识别器并开始训练,也可以使用Eigen或者Fisher识别器
face_recognizer = cv2.face.LBPHFaceRecognizer_create()
#不想每次都训练,就把训练好的结果保存到xml文件,下次运行时直接加载该文件即可
#所生成的xml文件不小,50多长图片,8M多,这50多张图一共6M多,想训练得更准确文件会有多大?
# face_recognizer.train(faces,np.array(labels))
# face_recognizer.save('F:/face_recongnizer.xml')
face_recognizer.read('F:/face_recongnizer.xml')#读取训练模型,有版本用的方法是.load()
#根据给定的x,y坐标和宽高在图上绘制矩形
def draw_rect(img,rect):
(x,y,w,h) = rect
cv2.rectangle(img,(x,y),(x+w,y+h),(128,128,0),2)
#根据给定的(x,y)坐标标示出人名
def draw_text(img,text,x,y):
cv2.putText(img,text,(x,y),cv2.FONT_HERSHEY_COMPLEX,1,(128,128,0),2)
#建立标签与人名的映射列表(标签只能为整数)
subjects = ['SongJY','LJ ','Song YaTeng']
#识别函数,此函数识别传递进来的图像中的人物并在检测到的脸部周围绘制一个矩形及其名称
def predict(test_img):
#生成图像的副本,以保护原始图像
img = test_img
#检测人脸
face,rect = detect_face(img)
# print(face)
#预测人脸
if face is not None:
label = face_recognizer.predict(face)
print(label)
#获取由人脸识别器返回的相应标签的名称
label_text = subjects[label[0]]
#在检测到的人脸周围画一个矩形;标出识别出的名字
draw_rect(img,rect)
draw_text(img,label_text,rect[0],rect[1] - 5)
#返回预测的图像
return img
return None
#### 摄像头实时识别 ####
def detect_Cap():
#打开摄像头
cap = cv2.VideoCapture(0)
#从摄像头循环获取图片,0.5s一张
while(1):
#获取图像
ret,frame = cap.read()
print((frame.shape))
#执行预测
predicted_img1 = predict(frame)
if predicted_img1 is not None:
size = predicted_img1.shape
img_h = size[0]
img_w = size[1]
window_h = 600
window_w = img_w * (600 / img_h)
# print('window_h '+ str(window_h)+' window_w '+str(int(window_w)))
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Image', int(window_w), int(window_h)) # resizeWindow会把img放大或缩小
cv2.imshow('Image', predicted_img1)
elif predicted_img1 is None:
size = frame.shape
img_h = size[0]
img_w = size[1]
window_h = 600
window_w = img_w * (600 / img_h)
# print('window_h '+ str(window_h)+' window_w '+str(int(window_w)))
cv2.namedWindow('Image', cv2.WINDOW_NORMAL)
cv2.resizeWindow('Image', int(window_w), int(window_h)) # resizeWindow会把img放大或缩小
cv2.imshow('Image', frame)
#按Q退出,延时0.5s
if cv2.waitKey(500) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# #加载测试图像 'f:/4.jpg'
def detect_Img(fileName):
test_img1 = cv2.imread(fileName)
#执行预测
predicted_img1 = predict(test_img1)
size = predicted_img1.shape
img_h = size[0]
img_w = size[1]
window_h = 600
window_w = img_w * (600/img_h)
# print('window_h '+ str(window_h)+' window_w '+str(int(window_w)))
cv2.namedWindow('Image',cv2.WINDOW_NORMAL)
cv2.resizeWindow('Image',int(window_w),int(window_h))# resizeWindow会把img放大或缩小
cv2.imshow('Image',predicted_img1)
cv2.waitKey(0)
cv2.destroyAllWindows()
# detect_Img('f:/13.jpg')
detect_Cap()
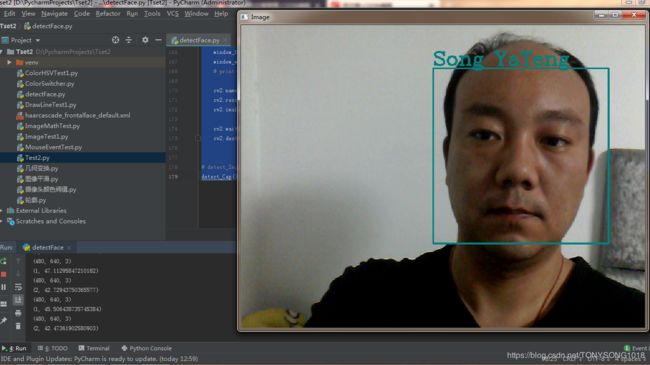
5、运行结果
摄像头识别效果如下:
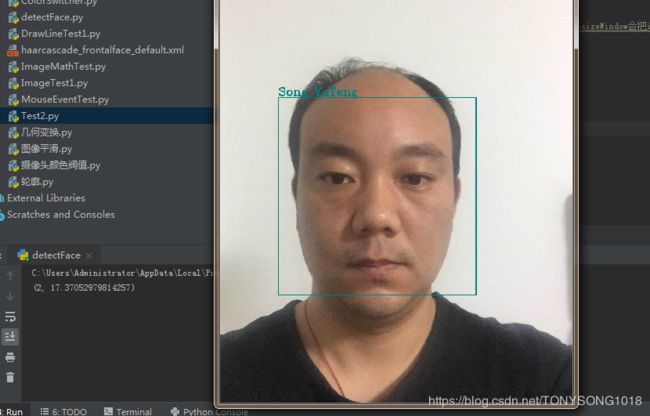
 单个照片执行结果如下:
单个照片执行结果如下:
6、其他问题
我自己同一天,照了十几张大头照用来训练程序,媳妇的照片照了手机中不多的十几张生活照用来训练,结果识别结果不理想,少数情况下把我认成我,而媳妇自己识别很成功,孩子的正确率也可以,关键我们家我们孩子像,媳妇跟我脸型绝对不一样,目前不知是什么原因,识别不理想,会继续尝试,希望有了解的朋友能够指教。
大家可以注意看一下咱们打的log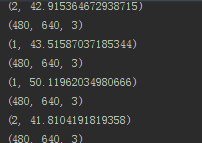 这个log是用摄像头识别时打的,按我自己观察来说,我和媳妇长得不像,但在目前的学习量上来说,程序经常把我识别成媳妇,不知是不是因为她的照片大部分是生活照,不是大头照,所以更不准确,稍后会再试试。
这个log是用摄像头识别时打的,按我自己观察来说,我和媳妇长得不像,但在目前的学习量上来说,程序经常把我识别成媳妇,不知是不是因为她的照片大部分是生活照,不是大头照,所以更不准确,稍后会再试试。
需要注意我们log中的(2,41.123123…)这个返回
def predict(test_img):
#生成图像的副本,以保护原始图像
img = test_img
#检测人脸
face,rect = detect_face(img)
# print(face)
#预测人脸
if face is not None:
label = face_recognizer.predict(face)
print(label)
返回结果是face_recognizer.predict(face)返回的,他返回一个对应的标签和相似度,当相似度是0.0时就是完全一样,大于40时我认为基本就不靠谱了,从log中看到同样是我,当相似度是43.123123123…时程序还把我是别成了我媳妇,我拿训练集里的原图测试时这个返回时0.0。
另外除了LBPH识别器,还有Eigen或者Fisher识别器,下一片尝试一下这两个识别器的区别是什么,然后开始下一步尝试,把这个程序移植到手机上,让手机用训练好的识别器认识自家人。