RPNhead类代码解释
class RPNHead(nn.Module):
"""Network head of RPN.
/ - rpn_cls (1x1 conv)
input - rpn_conv (3x3 conv) -
\ - rpn_reg (1x1 conv)
Args:
in_channels (int): Number of channels in the input feature map.
feat_channels (int): Number of channels for the RPN feature map.
anchor_scales (Iterable): Anchor scales.
anchor_ratios (Iterable): Anchor aspect ratios.
anchor_strides (Iterable): Anchor strides.
anchor_base_sizes (Iterable): Anchor base sizes.
target_means (Iterable): Mean values of regression targets.
target_stds (Iterable): Std values of regression targets.
use_sigmoid_cls (bool): Whether to use sigmoid loss for classification.
(softmax by default)
""" # noqa: W605
def __init__(self,
in_channels,
feat_channels=256,
anchor_scales=[8, 16, 32],
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[4, 8, 16, 32, 64],
anchor_base_sizes=None,
target_means=(.0, .0, .0, .0),
target_stds=(1.0, 1.0, 1.0, 1.0),
use_sigmoid_cls=False):
super(RPNHead, self).__init__()
self.in_channels = in_channels
self.feat_channels = feat_channels
self.anchor_scales = anchor_scales
self.anchor_ratios = anchor_ratios
self.anchor_strides = anchor_strides
self.anchor_base_sizes = list(
anchor_strides) if anchor_base_sizes is None else anchor_base_sizes
self.target_means = target_means
self.target_stds = target_stds
self.use_sigmoid_cls = use_sigmoid_cls
self.anchor_generators = []
for anchor_base in self.anchor_base_sizes:
self.anchor_generators.append(
AnchorGenerator(anchor_base, anchor_scales, anchor_ratios))
self.rpn_conv = nn.Conv2d(in_channels, feat_channels, 3, padding=1)
self.relu = nn.ReLU(inplace=True)
self.num_anchors = len(self.anchor_ratios) * len(self.anchor_scales)
out_channels = (self.num_anchors
if self.use_sigmoid_cls else self.num_anchors * 2)
self.rpn_cls = nn.Conv2d(feat_channels, out_channels, 1)
self.rpn_reg = nn.Conv2d(feat_channels, self.num_anchors * 4, 1)
self.debug_imgs = None
def init_weights(self):
normal_init(self.rpn_conv, std=0.01)
normal_init(self.rpn_cls, std=0.01)
normal_init(self.rpn_reg, std=0.01)
def forward_single(self, x):
rpn_feat = self.relu(self.rpn_conv(x))
rpn_cls_score = self.rpn_cls(rpn_feat)
rpn_bbox_pred = self.rpn_reg(rpn_feat)
return rpn_cls_score, rpn_bbox_pred
def forward(self, feats):
return multi_apply(self.forward_single, feats)
def get_anchors(self, featmap_sizes, img_metas):
"""Get anchors according to feature map sizes.
Args:
featmap_sizes (list[tuple]): Multi-level feature map sizes.
img_metas (list[dict]): Image meta info.
Returns:
tuple: anchors of each image, valid flags of each image
"""
num_imgs = len(img_metas)
num_levels = len(featmap_sizes)
# since feature map sizes of all images are the same, we only compute
# anchors for one time
multi_level_anchors = []
for i in range(num_levels):
anchors = self.anchor_generators[i].grid_anchors(
featmap_sizes[i], self.anchor_strides[i])
multi_level_anchors.append(anchors)
anchor_list = [multi_level_anchors for _ in range(num_imgs)]
# for each image, we compute valid flags of multi level anchors
valid_flag_list = []
for img_id, img_meta in enumerate(img_metas):
multi_level_flags = []
for i in range(num_levels):
anchor_stride = self.anchor_strides[i]
feat_h, feat_w = featmap_sizes[i]
h, w, _ = img_meta['pad_shape']
valid_feat_h = min(int(np.ceil(h / anchor_stride)), feat_h)
valid_feat_w = min(int(np.ceil(w / anchor_stride)), feat_w)
flags = self.anchor_generators[i].valid_flags(
(feat_h, feat_w), (valid_feat_h, valid_feat_w))
multi_level_flags.append(flags)
valid_flag_list.append(multi_level_flags)
return anchor_list, valid_flag_list
def loss_single(self, rpn_cls_score, rpn_bbox_pred, labels, label_weights,
bbox_targets, bbox_weights, num_total_samples, cfg):
# classification loss
labels = labels.contiguous().view(-1)
label_weights = label_weights.contiguous().view(-1)
if self.use_sigmoid_cls:
rpn_cls_score = rpn_cls_score.permute(0, 2, 3,
1).contiguous().view(-1)
criterion = weighted_binary_cross_entropy
else:
rpn_cls_score = rpn_cls_score.permute(0, 2, 3,
1).contiguous().view(-1, 2)
criterion = weighted_cross_entropy
loss_cls = criterion(
rpn_cls_score, labels, label_weights, avg_factor=num_total_samples)
# regression loss
bbox_targets = bbox_targets.contiguous().view(-1, 4)
bbox_weights = bbox_weights.contiguous().view(-1, 4)
rpn_bbox_pred = rpn_bbox_pred.permute(0, 2, 3, 1).contiguous().view(
-1, 4)
loss_reg = weighted_smoothl1(
rpn_bbox_pred,
bbox_targets,
bbox_weights,
beta=cfg.smoothl1_beta,
avg_factor=num_total_samples)
return loss_cls, loss_reg
def loss(self, rpn_cls_scores, rpn_bbox_preds, gt_bboxes, img_shapes, cfg):
featmap_sizes = [featmap.size()[-2:] for featmap in rpn_cls_scores]
assert len(featmap_sizes) == len(self.anchor_generators)
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_shapes)
cls_reg_targets = anchor_target(
anchor_list, valid_flag_list, gt_bboxes, img_shapes,
self.target_means, self.target_stds, cfg)
if cls_reg_targets is None:
return None
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
losses_cls, losses_reg = multi_apply(
self.loss_single,
rpn_cls_scores,
rpn_bbox_preds,
labels_list,
label_weights_list,
bbox_targets_list,
bbox_weights_list,
num_total_samples=num_total_pos + num_total_neg,
cfg=cfg)
return dict(loss_rpn_cls=losses_cls, loss_rpn_reg=losses_reg)
def get_proposals(self, rpn_cls_scores, rpn_bbox_preds, img_meta, cfg):
num_imgs = len(img_meta)
featmap_sizes = [featmap.size()[-2:] for featmap in rpn_cls_scores]
mlvl_anchors = [
self.anchor_generators[idx].grid_anchors(featmap_sizes[idx],
self.anchor_strides[idx])
for idx in range(len(featmap_sizes))
]
proposal_list = []
for img_id in range(num_imgs):
rpn_cls_score_list = [
rpn_cls_scores[idx][img_id].detach()
for idx in range(len(rpn_cls_scores))
]
rpn_bbox_pred_list = [
rpn_bbox_preds[idx][img_id].detach()
for idx in range(len(rpn_bbox_preds))
]
assert len(rpn_cls_score_list) == len(rpn_bbox_pred_list)
proposals = self._get_proposals_single(
rpn_cls_score_list, rpn_bbox_pred_list, mlvl_anchors,
img_meta[img_id]['img_shape'], cfg)
proposal_list.append(proposals)
return proposal_list
def _get_proposals_single(self, rpn_cls_scores, rpn_bbox_preds,
mlvl_anchors, img_shape, cfg):
mlvl_proposals = []
for idx in range(len(rpn_cls_scores)):
rpn_cls_score = rpn_cls_scores[idx]
rpn_bbox_pred = rpn_bbox_preds[idx]
assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
anchors = mlvl_anchors[idx]
if self.use_sigmoid_cls:
rpn_cls_score = rpn_cls_score.permute(1, 2,
0).contiguous().view(-1)
rpn_cls_prob = rpn_cls_score.sigmoid()
scores = rpn_cls_prob
else:
rpn_cls_score = rpn_cls_score.permute(1, 2,
0).contiguous().view(
-1, 2)
rpn_cls_prob = F.softmax(rpn_cls_score, dim=1)
scores = rpn_cls_prob[:, 1]
rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).contiguous().view(
-1, 4)
_, order = scores.sort(0, descending=True)
if cfg.nms_pre > 0:
order = order[:cfg.nms_pre]
rpn_bbox_pred = rpn_bbox_pred[order, :]
anchors = anchors[order, :]
scores = scores[order]
proposals = delta2bbox(anchors, rpn_bbox_pred, self.target_means,
self.target_stds, img_shape)
w = proposals[:, 2] - proposals[:, 0] + 1
h = proposals[:, 3] - proposals[:, 1] + 1
valid_inds = torch.nonzero((w >= cfg.min_bbox_size) &
(h >= cfg.min_bbox_size)).squeeze()
proposals = proposals[valid_inds, :]
scores = scores[valid_inds]
proposals = torch.cat([proposals, scores.unsqueeze(-1)], dim=-1)
proposals, _ = nms(proposals, cfg.nms_thr)
proposals = proposals[:cfg.nms_post, :]
mlvl_proposals.append(proposals)
proposals = torch.cat(mlvl_proposals, 0)
if cfg.nms_across_levels:
proposals, _ = nms(proposals, cfg.nms_thr)
proposals = proposals[:cfg.max_num, :]
else:
scores = proposals[:, 4]
_, order = scores.sort(0, descending=True)
num = min(cfg.max_num, proposals.shape[0])
order = order[:num]
proposals = proposals[order, :]
return proposals
RPNhead处于哪一部分呢?,借用某个博客的图
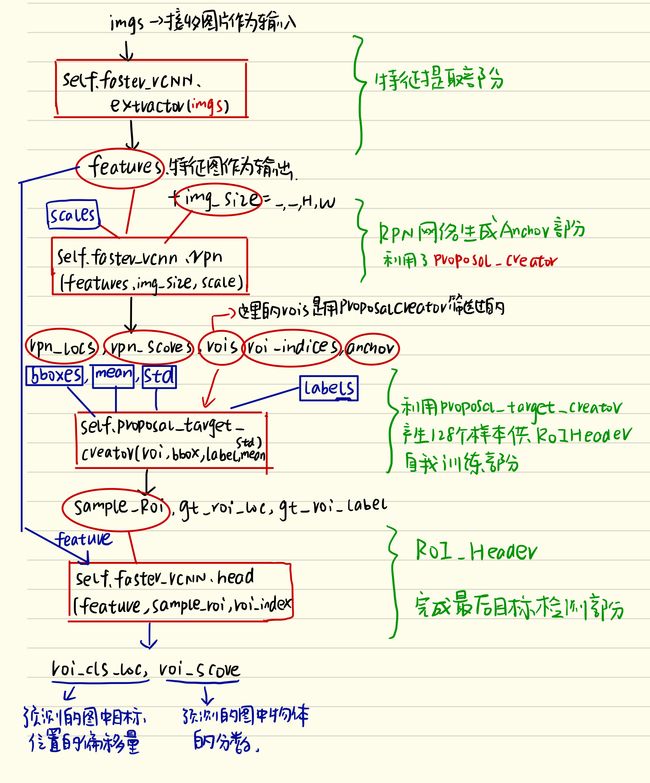
RPNhead就是以上绿色分区的倒数第二块。
简单来说就是,RPN网络计算了anchor之后,进入RPNhead,计算得到 分类的预测 和 回归的预测。
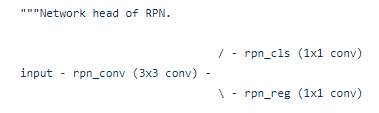
这个类分成init init_weights forward_single forward get_anchors loss_single loss get_proposals _get_proposals_single
也就是 初始化、forward训练部分、获取anchors 和计算loss、得到proposals 几个部分。
前几个比较简单,主要看一下得到proposal的部分。
在训练时,

只计算处预测分类和预测回归,用来计算loss即可。
所以我们的 proposal 方法是用在inference时,得到RPN的结果——proposals ,大小是 (cfg.max_num, 5),前四列坐标,第五列 预测得分
看_get_proposals_single 方法,这个方法计算一张图片的proposals
def _get_proposals_single(self, rpn_cls_scores, rpn_bbox_preds,
mlvl_anchors, img_shape, cfg):
mlvl_proposals = []
for idx in range(len(rpn_cls_scores)):
rpn_cls_score = rpn_cls_scores[idx]
rpn_bbox_pred = rpn_bbox_preds[idx]
assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
anchors = mlvl_anchors[idx]
if self.use_sigmoid_cls:
rpn_cls_score = rpn_cls_score.permute(1, 2,
0).contiguous().view(-1)
rpn_cls_prob = rpn_cls_score.sigmoid()
scores = rpn_cls_prob
else:
rpn_cls_score = rpn_cls_score.permute(1, 2,
0).contiguous().view(
-1, 2)
rpn_cls_prob = F.softmax(rpn_cls_score, dim=1)
scores = rpn_cls_prob[:, 1]
rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).contiguous().view(
-1, 4)
_, order = scores.sort(0, descending=True)
if cfg.nms_pre > 0:
order = order[:cfg.nms_pre]
rpn_bbox_pred = rpn_bbox_pred[order, :]
anchors = anchors[order, :]
scores = scores[order]
proposals = delta2bbox(anchors, rpn_bbox_pred, self.target_means,
self.target_stds, img_shape)
w = proposals[:, 2] - proposals[:, 0] + 1
h = proposals[:, 3] - proposals[:, 1] + 1
valid_inds = torch.nonzero((w >= cfg.min_bbox_size) &
(h >= cfg.min_bbox_size)).squeeze()
proposals = proposals[valid_inds, :]
scores = scores[valid_inds]
proposals = torch.cat([proposals, scores.unsqueeze(-1)], dim=-1)
proposals, _ = nms(proposals, cfg.nms_thr)
proposals = proposals[:cfg.nms_post, :]
mlvl_proposals.append(proposals)
proposals = torch.cat(mlvl_proposals, 0)
if cfg.nms_across_levels:
proposals, _ = nms(proposals, cfg.nms_thr)
proposals = proposals[:cfg.max_num, :]
else:
scores = proposals[:, 4]
_, order = scores.sort(0, descending=True)
num = min(cfg.max_num, proposals.shape[0])
order = order[:num]
proposals = proposals[order, :]
return proposals
在get_proposals方法中我们计算得到所有的图片的proposals, 循环调用num images次的 _get_proposals_single。
首先_get_proposals_single 的输入 rpn_cls_scores, rpn_bbox_preds, mlvl_anchors都是multi level的,也就是形如 num_level , channel , h ,w . 所以, 主体部分在一个for循环中,分别计算每个level的proposal 然后合并到一起。
for循环中,
一开始得到该level下的anchor,用在之后计算绝对坐标。
接着决定对 预测分数做 sigmod还是softmax, 如果是sigmod的方法,在初始化init中已经看到,分数只有一列,不分两类,所以输出通道数是 out_channels = (self.num_anchors if self.use_sigmoid_cls else self.num_anchors * 2),而softmax是两倍。
同样对 预测回归 调整形状,
紧接着对分数进行排序,根据 cfg.nums_pre 去掉一波结果,接着做NMS算法,这里有阈值设定。之后根据cfg.nums_post 再筛选一波。比如得到2000个proposal。
这样我们得到了某个level下的2000个proposal。同理,计算多个level的proposal。
多尺度下的结果proposals = torch.cat(mlvl_proposals, 0) 。
接着,有两种手段做最后一次筛选,可以再做一次NMS算法,选择最后需要的cfg.max_num个proposal
或者,直接排序 预测分数, 选择 前cfg.max_num个proposal