Hadoop3.1.3 完全分布式集群搭建
文章目录
- 完全分布式
- 编写集群分发脚本xsync
- 完全分布式集群规划: (按照3个副本来说)
- 单节点启动
- 集群格式化问题
- SSH无密登录配置
- 群起集群
- 配置历史服务器
- 配置日志的聚集
- 集群时间同步
完全分布式
克隆三台虚拟机 完成环境准备
查看
https://blog.csdn.net/VanasWang/article/details/105395279
sudo mkdir /opt/module /opt/software
sudo chown -R vanas:vanas /opt/module /opt/software
-
scp(secure copy)安全拷贝
-
rsync 远程同步工具
选项 功能 -a 归档拷贝 -v 显示复制过程 rsync用的比较多
scp -r /opt/module/* vanas@hadoop134:/opt/moudle/
<!]--拉过去 -->
scp -r vanas@hadoop132:/opt/module/* /opt/module
scp -r vanas@hadoop132:/opt/module/* vanas@hadoop133:/opt/module/
rsync -av /opt/module/* vanas@hadoop133:/opt/module/
[vanas@hadoop133 opt]$ scp -r vanas@hadoop132:/opt/module vanas@hadoop133:/opt/module
[vanas@hadoop132 bin]$ rsync -av /opt/module/ vanas@hadoop130:/opt/module
编写集群分发脚本xsync
[vanas@hadoop130 hadoop]$ cd ~
[vanas@hadoop130 ~]$ mkdir bin
[vanas@hadoop130 ~]$ cd bin
[vanas@hadoop130 bin]$ touch xsync
[vanas@hadoop130 bin]$ vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop133 hadoop134
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
[vanas@hadoop130 bin]$ chmod 777 xsync
[vanas@hadoop130 bin]$ ll
总用量 4
-rwxrwxrwx. 1 vanas vanas 621 4月 10 16:03 xsync
测试xsync是否好用
[vanas@hadoop130 bin]$ cd /opt/module/hadoop-3.1.3/
[vanas@hadoop130 hadoop-3.1.3]$ touch aaa.txt
[vanas@hadoop130 hadoop-3.1.3]$ ll
[vanas@hadoop130 hadoop-3.1.3]$ xsync aaa.txt
==================== hadoop133 ====================
The authenticity of host 'hadoop133 (192.168.69.133)' can't be established.
ECDSA key fingerprint is SHA256:yLxOgG/cw1It+0IgoLqv08WlIRDlFBh3jNoPkR7XU48.
ECDSA key fingerprint is MD5:e1:5d:77:03:df:e1:e6:8d:4d:e4:61:8b:a3:c9:9d:3c.
Are you sure you want to continue connecting (yes/no)? yest^H
Warning: Permanently added 'hadoop133,192.168.69.133' (ECDSA) to the list of known hosts.
vanas@hadoop133's password:
vanas@hadoop133's password:
sending incremental file list
aaa.txt
sent 103 bytes received 35 bytes 55.20 bytes/sec
total size is 0 speedup is 0.00
==================== hadoop134 ====================
The authenticity of host 'hadoop134 (192.168.69.134)' can't be established.
ECDSA key fingerprint is SHA256:yLxOgG/cw1It+0IgoLqv08WlIRDlFBh3jNoPkR7XU48.
ECDSA key fingerprint is MD5:e1:5d:77:03:df:e1:e6:8d:4d:e4:61:8b:a3:c9:9d:3c.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop134,192.168.69.134' (ECDSA) to the list of known hosts.
vanas@hadoop134's password:
vanas@hadoop134's password:
sending incremental file list
aaa.txt
sent 103 bytes received 35 bytes 39.43 bytes/sec
total size is 0 speedup is 0.00
分别查看hadoop133、和hadoop134都已存在
完全分布式集群规划: (按照3个副本来说)
1个NameNode 3个DataNode 1个SecondaryNameNode 1个ResourceManager 3个NodeManager
理论情况: 需要有6个机器
实际情况: 3台机器
因为NameNode 、SecondaryNameNode 、 ResourceManager运行中需要的资源比较多,因此分布到不同的节点中.
| Hadoop130 | Hadoop133 | Hadoop134 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
(1)核心配置文件
配置core-site.xml
[vanas@hadoop130 hadoop-3.1.3]$ cd etc/hadoop/
[vanas@hadoop130 hadoop]$ vim core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop130:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.data.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 下面是兼容性配置,先跳过 -->
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.vanas.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superuser)允许代理的用户所属组 -->
<property>
<name>hadoop.proxyuser.vanas.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superuser)允许代理的用户-->
<property>
<name>hadoop.proxyuser.vanas.users</name>
<value>*</value>
</property>
</configuration>
(2)HDFS配置文件
配置hdfs-site.xml
[vanas@hadoop130 hadoop]$ vim hdfs-site.xml
<configuration>
<!-- 指定NameNode数据的存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<!-- 指定Datanode数据的存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<!-- 指定SecondaryNameNode数据的存储目录 -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/namesecondary</value>
</property>
<!-- 兼容配置,先跳过 -->
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30s</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop130:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop134:9868</value>
</property>
</configuration>
(3)YARN配置文件
配置yarn-site.xml
[vanas@hadoop130 hadoop]$ vim yarn-site.xml
<configuration>
<!--指定mapreduce走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop133</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
(4)MapReduce配置文件
配置mapred-site.xml
<configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
在集群上分发配置好的hadoop
[vanas@hadoop130 hadoop]$ cd ..
[vanas@hadoop130 etc]$ xsync hadoop
==================== hadoop133 ====================
vanas@hadoop133's password:
vanas@hadoop133's password:
sending incremental file list
hadoop/
hadoop/core-site.xml
hadoop/hdfs-site.xml
hadoop/yarn-site.xml
sent 4,305 bytes received 114 bytes 1,262.57 bytes/sec
total size is 108,704 speedup is 24.60
==================== hadoop134 ====================
vanas@hadoop134's password:
vanas@hadoop134's password:
sending incremental file list
hadoop/
hadoop/core-site.xml
hadoop/hdfs-site.xml
hadoop/yarn-site.xml
[vanas@hadoop130 etc]$ cd /etc/profile.d
[vanas@hadoop130 profile.d]$ sudo vim my_env.sh
#JAVA_HOME
JAVA_HOME=/opt/module/jdk1.8.0_212
#HADOOP_HOME
HADOOP_HOME=/opt/module/hadoop-3.1.3
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH JAVA_HOME HADOOP_HOME
[vanas@hadoop130 profile.d]$ sudo scp -r ./my_env.sh root@hadoop133:/etc/profile.d/
The authenticity of host 'hadoop133 (192.168.69.133)' can't be established.
ECDSA key fingerprint is SHA256:yLxOgG/cw1It+0IgoLqv08WlIRDlFBh3jNoPkR7XU48.
ECDSA key fingerprint is MD5:e1:5d:77:03:df:e1:e6:8d:4d:e4:61:8b:a3:c9:9d:3c.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop133,192.168.69.133' (ECDSA) to the list of known hosts.
root@hadoop133's password:
my_env.sh 100% 146 211.6KB/s 00:00
[vanas@hadoop130 profile.d]$ sudo scp -r ./my_env.sh root@hadoop134:/etc/profile.d/
The authenticity of host 'hadoop134 (192.168.69.134)' can't be established.
ECDSA key fingerprint is SHA256:yLxOgG/cw1It+0IgoLqv08WlIRDlFBh3jNoPkR7XU48.
ECDSA key fingerprint is MD5:e1:5d:77:03:df:e1:e6:8d:4d:e4:61:8b:a3:c9:9d:3c.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop134,192.168.69.134' (ECDSA) to the list of known hosts.
root@hadoop134's password:
my_env.sh 100% 146 386.8KB/s 00:00
[vanas@hadoop130 profile.d]$ source /etc/profile
[vanas@hadoop133 profile.d]$ source /etc/profile
[vanas@hadoop134 profile.d]$ source /etc/profile
单节点启动
启动HDFS
初始化前注意清空data和logs
[vanas@hadoop130 hadoop-3.1.3]$ rm -rf data/ logs/
[vanas@hadoop133 hadoop-3.1.3]$ rm -rf data/ logs/
[vanas@hadoop134 hadoop-3.1.3]$ rm -rf data/ logs/
[vanas@hadoop130 profile.d]$ hdfs namenode -format
[vanas@hadoop130 hadoop-3.1.3]$ hdfs --daemon start namenode
[vanas@hadoop130 hadoop-3.1.3]$ hdfs --daemon start datanode
[vanas@hadoop130 hadoop-3.1.3]$ jps
36872 NameNode
39448 DataNode
39630 Jps
[vanas@hadoop133 profile.d]$ hdfs --daemon start datanode
[vanas@hadoop134 hadoop-3.1.3]$ hdfs --daemon start datanode
[vanas@hadoop134 hadoop-3.1.3]$ hdfs --daemon start secondarynamenode

启动yarn
[vanas@hadoop133 hadoop-3.1.3]$ yarn --daemon start resourcemanager
[vanas@hadoop130 hadoop-3.1.3]$ yarn --daemon start nodemanager
[vanas@hadoop130 hadoop-3.1.3]$ jps
52467 Jps
52339 NodeManager
36872 NameNode
39448 DataNode
[vanas@hadoop133 hadoop-3.1.3]$ yarn --daemon start nodemanager
[vanas@hadoop133 hadoop-3.1.3]$ jps
56788 Jps
40039 DataNode
56044 NodeManager
49724 ResourceManager
[vanas@hadoop134 hadoop-3.1.3]$ yarn --daemon start nodemanager
[vanas@hadoop134 hadoop-3.1.3]$ jps
56384 NodeManager
43090 SecondaryNameNode
57557 Jps
41535 DataNode

集群格式化问题
集群id问题
-
集群是否需要每次都格式化?
不需要. 正常情况下, 一个新配置好的集群需要格式化,后续就不要再进行格式化操作。
除非整个集群的数据都不要了,集群遇到严重的问题,需要重新搭建,等搭建好后需要格式化. -
如果要重新格式化集群需要注意什么问题?
如果要重新格式化需要删除 data目录 和 logs目录 。
如果不删除 , 重新格式化会生成新的集群id, 而DN记录的还是之前的集群id
当DN启动以后找不到NN,然后DN直接下线.DN启动起来以后,会自动找NN进行注册.
SSH无密登录配置

无密钥配置
[vanas@hadoop130 hadoop-3.1.3]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/vanas/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/vanas/.ssh/id_rsa.
Your public key has been saved in /home/vanas/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:RnHv4HI/XnZlKv0gXt/IjsjSF5H5YU1dR9UTZ8xXJm8 vanas@hadoop130
The key's randomart image is:
+---[RSA 2048]----+
| . . .=^|
| o . *X|
| . . .o oE|
| . . o+ o..|
| S o .+ .o|
| . o ....o.|
| . =.B .|
| ...+.X *.|
| .o.+.+ +|
+----[SHA256]-----+
[vanas@hadoop130 ~]$ ll -a
总用量 40
drwx------. 4 vanas vanas 4096 4月 10 19:38 .
drwxr-xr-x. 3 root root 4096 4月 2 19:59 ..
-rw-------. 1 vanas vanas 1714 4月 10 20:32 .bash_history
-rw-r--r--. 1 vanas vanas 18 4月 11 2018 .bash_logout
-rw-r--r--. 1 vanas vanas 193 4月 11 2018 .bash_profile
-rw-r--r--. 1 vanas vanas 231 4月 11 2018 .bashrc
drwxrwxr-x. 2 vanas vanas 4096 4月 10 16:03 bin
drwx------. 2 vanas vanas 4096 4月 11 09:29 .ssh
-rw-------. 1 vanas vanas 5701 4月 10 19:38 .viminfo
[vanas@hadoop130 ~]$ cd .ssh/
[vanas@hadoop130 .ssh]$ ll
总用量 12
-rw-------. 1 vanas vanas 1675 4月 11 09:29 id_rsa //私钥
-rw-r--r--. 1 vanas vanas 397 4月 11 09:29 id_rsa.pub //公钥
-rw-r--r--. 1 vanas vanas 372 4月 10 18:07 known_hosts
[vanas@hadoop130 .ssh]$ ssh-copy-id hadoop133
[vanas@hadoop130 .ssh]$ ssh-copy-id hadoop134
[vanas@hadoop130 .ssh]$ ssh hadoop133
Last login: Sat Apr 11 09:19:19 2020 from hadoop130
[vanas@hadoop133 ~]$ exit;
登出
Connection to hadoop133 closed.
[vanas@hadoop130 .ssh]$ ssh-copy-id hadoop130
[vanas@hadoop130 .ssh]$ ll
总用量 16
-rw-------. 1 vanas vanas 397 4月 11 09:36 authorized_keys
-rw-------. 1 vanas vanas 1675 4月 11 09:29 id_rsa
-rw-r--r--. 1 vanas vanas 397 4月 11 09:29 id_rsa.pub
-rw-r--r--. 1 vanas vanas 558 4月 11 09:36 known_hosts
.ssh文件夹下(~/.ssh)的文件功能解释
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
133、134也如此操作,以134为例
[vanas@hadoop134 ~]$ ssh-keygen -t rsa
[vanas@hadoop134 ~]$ ssh-copy-id hadoop130
[vanas@hadoop134 ~]$ ssh-copy-id hadoop133
[vanas@hadoop134 ~]$ ssh-copy-id hadoop134
当前操作只对当前用户vanas管用
注意:
如果需用root
还需要在hadoop130上采用root账号,配置一下无密登录到hadoop130、hadoop133、hadoop134
还需要在hadoop133上采用vanas账号配置一下无密登录到hadoop130、hadoop133、hadoop134服务器上
群起集群
配置workers
[vanas@hadoop130 hadoop]$ vim workers
hadoop130
hadoop133
hadoop134
[vanas@hadoop130 hadoop]$ xsync workers
启动hdfs
namenode的服务器
[vanas@hadoop130 hadoop]$ start-dfs.sh
启动yarn
注意在rm在哪个服务器上
[vanas@hadoop133 .ssh]$ start-yarn.sh
关闭集群
stop-yarn.sh
stop-dfs.sh
注意关机前最好要先关闭集群
群起脚本
[vanas@hadoop130 ~]$ cd bin
[vanas@hadoop130 bin]$ vim mycluster
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input Error!!!!!"
exit
fi
case $1 in
"start")
echo "======================== start hdfs ========================== "
ssh hadoop130 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
echo "======================== start yarn ========================== "
ssh hadoop133 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
;;
"stop")
echo "======================== stop yarn ========================== "
ssh hadoop133 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
echo "======================== stop hdfs ========================== "
ssh hadoop130 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
;;
*)
echo "Input Args Error!!!!!"
;;
esac
[vanas@hadoop130 bin]$ vim myjps
#!/bin/bash
for i in hadoop130 hadoop133 hadoop134
do
echo "====================== $i JPS ======================="
ssh $i /opt/module/jdk1.8.0_212/bin/jps
done
[vanas@hadoop130 bin]$ chmod 777 myjps
[vanas@hadoop130 bin]$ chmod 777 mycluster
集群基本测试
[vanas@hadoop130 ~]$ hdfs dfs -put /opt/module/hadoop-3.1.3/input/my.txt /user/vanas/input
[vanas@hadoop130 ~]$ cd /opt/module/hadoop-3.1.3/
[vanas@hadoop130 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/vanas/input /user/vanas/output

配置历史服务器
查看程序的历史运行情况,需要配置一下历史服务器
配置mapred-site.xml
[vanas@hadoop130 etc]$ cd hadoop/
[vanas@hadoop130 hadoop]$ vi mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop130:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop130:19888</value>
</property>
[vanas@hadoop130 hadoop]$ xysnc mapred-site.xml
[vanas@hadoop130 bin]$ mapred --daemon start historyserver
[vanas@hadoop130 bin]$ jps
82579 DataNode
83714 Jps
82391 NameNode
83113 NodeManager
83563 JobHistoryServer
http://hadoop130:19888/jobhistory
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager
配置yarn-site.xml
[vanas@hadoop130 hadoop-3.1.3]$ cd etc/hadoop/
[vanas@hadoop130 hadoop]$ vim yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop130:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
[vanas@hadoop101 hadoop]$ xsync yarn-site.xml
[vanas@hadoop133 .ssh]$ stop-yarn.sh
[vanas@hadoop130 hadoop]$ mapred --daemon stop historyserver
[vanas@hadoop133 .ssh]$ start-yarn.sh
[vanas@hadoop130 hadoop]$ mapred --daemon start historyserver
[vanas@hadoop130 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/vanas/input /user/vanas/output1
//设置虚拟内存超出
[vanas@hadoop130 hadoop]$ vim yarn-site.xml
<property>
<description>Whether virtual memory limits will be enforced for
containers.</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>true</value>
</property>
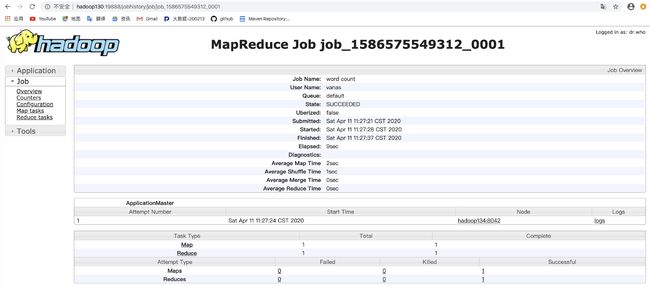
http://hadoop130:19888/jobhistory
here查看详情

集群时间同步
时间服务器配置(必须root用户)
在所有节点关闭ntp服务和自启动(130,133,134都关闭)
修改ntp配置文件
[vanas@hadoop130 hadoop]$ su root
密码:
[root@hadoop130 hadoop]# systemctl stop ntpd
[root@hadoop130 hadoop]# systemctl disable ntpd
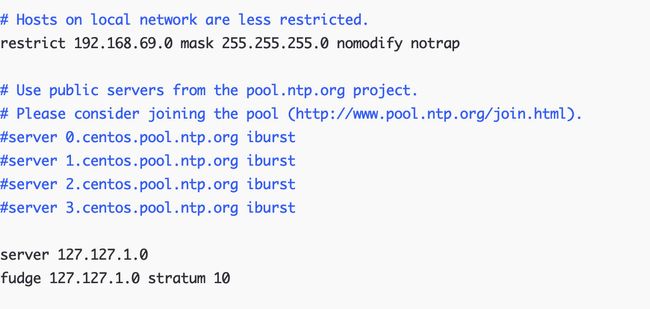
[root@hadoop130 hadoop]# vim /etc/ntp.conf
server 127.127.1.0
fudge 127.127.1.0 stratum 10
[root@hadoop130 hadoop]# vim /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes

[root@hadoop130 hadoop]# systemctl start ntpd
[root@hadoop130 hadoop]# systemctl enable ntpd
其他机器配置(必须root用户)
[root@hadoop133 ~]# crontab -e
[root@hadoop133 ~]# crontab -l
*/1 * * * * /usr/sbin/ntpdate hadoop130
[root@hadoop133 ~]# systemctl start ntpd
[root@hadoop133 ~]# systemctl enable ntpd
关闭
[root@hadoop133 ~]# crontab -e