Java多线程(六):J.U.C 之 AQS
Java 的内置锁一直都是备受争议的,在 JDK 1.6 之前,synchronized 这个重量级锁其性能一直都是较为低下,虽然在 1.6 后,进行大量的锁优化策略,但是与 Lock 相比 synchronized 还是存在一些缺陷的:虽然 synchronized 提供了便捷性的隐式获取锁释放锁机制(基于JVM机制),但是它却缺少了获取锁与释放锁的可操作性,可中断、超时获取锁,且它为独占式在高并发场景下性能大打折扣。
在介绍 Lock 之前,我们需要先熟悉一个非常重要的组件,掌握了该组件 J.U.C 包下面很多问题都不在是问题了。该组件就是 AQS 。
1. 简介
AQS ,AbstractQueuedSynchronizer ,即队列同步器。它是构建锁或者其他同步组件的基础框架(如 ReentrantLock、ReentrantReadWriteLock、Semaphore 等),J.U.C 并发包的作者(Doug Lea)期望它能够成为实现大部分同步需求的基础。
它是 J.U.C 并发包中的核心基础组件。
2. 优势
AQS 解决了在实现同步器时涉及当的大量细节问题,例如获取同步状态、FIFO 同步队列。基于 AQS 来构建同步器可以带来很多好处。它不仅能够极大地减少实现工作,而且也不必处理在多个位置上发生的竞争问题。
在基于 AQS 构建的同步器中,只能在一个时刻发生阻塞,从而降低上下文切换的开销,提高了吞吐量。同时在设计 AQS 时充分考虑了可伸缩性,因此 J.U.C 中,所有基于 AQS 构建的同步器均可以获得这个优势。
3. 同步状态
AQS 的主要使用方式是继承,子类通过继承同步器,并实现它的抽象方法来管理同步状态。
AQS 使用一个 int 类型的成员变量 state 来表示同步状态:
- 当
state > 0时,表示已经获取了锁。 - 当
state = 0时,表示释放了锁。
它提供了三个方法,来对同步状态 state 进行操作,并且 AQS 可以确保对 state 的操作是安全的:
#getState()#setState(int newState)#compareAndSetState(int expect, int update)
4. 同步队列
AQS 通过内置的 FIFO 同步队列来完成资源获取线程的排队工作:
- 如果当前线程获取同步状态失败(锁)时,AQS 则会将当前线程以及等待状态等信息构造成一个节点(Node)并将其加入同步队列,同时会阻塞当前线程
- 当同步状态释放时,则会把节点中的线程唤醒,使其再次尝试获取同步状态。
5. 主要内置方法
AQS 主要提供了如下方法:
#getState():返回同步状态的当前值。#setState(int newState):设置当前同步状态。#compareAndSetState(int expect, int update):使用 CAS 设置当前状态,该方法能够保证状态设置的原子性。- 【可重写】
#tryAcquire(int arg):独占式获取同步状态,获取同步状态成功后,其他线程需要等待该线程释放同步状态才能获取同步状态。 - 【可重写】
#tryRelease(int arg):独占式释放同步状态。 - 【可重写】
#tryAcquireShared(int arg):共享式获取同步状态,返回值大于等于 0 ,则表示获取成功;否则,获取失败。 - 【可重写】
#tryReleaseShared(int arg):共享式释放同步状态。 - 【可重写】
#isHeldExclusively():当前同步器是否在独占式模式下被线程占用,一般该方法表示是否被当前线程所独占。 acquire(int arg):独占式获取同步状态。如果当前线程获取同步状态成功,则由该方法返回;否则,将会进入同步队列等待。该方法将会调用可重写的#tryAcquire(int arg)方法;#acquireInterruptibly(int arg):与#acquire(int arg)相同,但是该方法响应中断。当前线程为获取到同步状态而进入到同步队列中,如果当前线程被中断,则该方法会抛出InterruptedException 异常并返回。#tryAcquireNanos(int arg, long nanos):超时获取同步状态。如果当前线程在 nanos 时间内没有获取到同步状态,那么将会返回 false ,已经获取则返回 true 。#acquireShared(int arg):共享式获取同步状态,如果当前线程未获取到同步状态,将会进入同步队列等待,与独占式的主要区别是在同一时刻可以有多个线程获取到同步状态;#acquireSharedInterruptibly(int arg):共享式获取同步状态,响应中断。#tryAcquireSharedNanos(int arg, long nanosTimeout):共享式获取同步状态,增加超时限制。#release(int arg):独占式释放同步状态,该方法会在释放同步状态之后,将同步队列中第一个节点包含的线程唤醒。#releaseShared(int arg):共享式释放同步状态。
从上面的方法看下来,基本上可以分成 3 类:
- 独占式获取与释放同步状态
- 共享式获取与释放同步状态
- 查询同步队列中的等待线程情况
AQS 内部维护着一个 FIFO 队列,该队列就是 CLH 同步队列。
1. 简介
CLH 同步队列是一个 FIFO 双向队列,AQS 依赖它来完成同步状态的管理:
- 当前线程如果获取同步状态失败时,AQS则会将当前线程已经等待状态等信息构造成一个节点(Node)并将其加入到CLH同步队列,同时会阻塞当前线程
- 当同步状态释放时,会把首节点唤醒(公平锁),使其再次尝试获取同步状态。
2. Node
在 CLH 同步队列中,一个节点(Node),表示一个线程,它保存着线程的引用(thread)、状态(waitStatus)、前驱节点(prev)、后继节点(next)。其定义如下:
Node 是 AbstractQueuedSynchronizer 的内部静态类。
|
-
waitStatus字段,等待状态,用来控制线程的阻塞和唤醒,并且可以避免不必要的调用LockSupport的#park(...)和#unpark(...)方法。。目前有 4 种:CANCELLEDSIGNALCONDITIONPROPAGATE。- 实际上,有第 5 种,
INITAL,值为 0 ,初始状态。 - 胖友请认真看下每个等待状态代表的含义,它不仅仅指的是 Node 自己的线程的等待状态,也可以是下一个节点的线程的等待状态。
- 实际上,有第 5 种,
-
CLH 同步队列,结构图如下:

prev和next字段,是 AbstractQueuedSynchronizer 的字段,分别指向同步队列的头和尾。head和tail字段,分别指向 Node 节点的前一个和后一个 Node 节点,从而实现链式双向队列。再配合上prev和next字段,快速定位到同步队列的头尾。
-
thread字段,Node 节点对应的线程 Thread 。 -
nextWaiter字段,Node 节点获取同步状态的模型( Mode )。#tryAcquire(int args)和#tryAcquireShared(int args)方法,分别是独占式和共享式获取同步状态。在获取失败时,它们都会调用#addWaiter(Node mode)方法入队。而nextWaiter就是用来表示是哪种模式:SHARED静态 + 不可变字段,枚举共享模式。EXCLUSIVE静态 + 不可变字段,枚举独占模式。#isShared()方法,判断是否为共享式获取同步状态。
-
#predecessor()方法,获得 Node 节点的前一个 Node 节点。在方法的内部,Node p = prev的本地拷贝,是为了避免并发情况下,prev判断完== null时,恰好被修改,从而保证线程安全。 -
构造方法有 3 个,分别是:
#Node()方法:用于SHARED的创建。#Node(Thread thread, Node mode)方法:用于#addWaiter(Node mode)方法。- 从
mode方法参数中,我们也可以看出它代表获取同步状态的模式。 - 在本文中,我们会看到这个构造方法的使用。
- 从
#Node(Thread thread, int waitStatus)方法,用于#addConditionWaiter()方法。- 在本文中,不会使用,所以解释暂时省略。
3. 入列
学了数据结构的我们,CLH 队列入列是再简单不过了:
tail指向新节点。- 新节点的
prev指向当前最后的节点。 - 当前最后一个节点的
next指向当前节点。
过程图如下:

但是,实际上,入队逻辑实现的 #addWaiter(Node) 方法,需要考虑并发的情况。它通过 CAS 的方式,来保证正确的添加 Node 。代码如下:
|
-
第 3 行:创建新节点
node。在创建的构造方法,mode方法参数,传递获取同步状态的模式。 -
第 5 行:记录原尾节点
tail。 -
在下面的代码,会分成 2 部分:
- 第 6 至 16 行:快速尝试,添加新节点为尾节点。
- 第 18 行:添加失败,多次尝试,直到成功添加。
-
========== 第 1 部分 ==========
-
第 7 行:当原尾节点非空,才执行快速尝试的逻辑。在下面的
#enq(Node node)方法中,我们会看到,首节点未初始化的时,head和tail都为空。 -
第 9 行:设置新节点的尾节点为原尾节点。
-
第 11 行:调用
#compareAndSetTail(Node expect, Node update)方法,使用 Unsafe 来 CAS 设置尾节点tail为新节点。代码如下:private static final Unsafe unsafe = Unsafe.getUnsafe(); private static final long tailOffset = unsafe.objectFieldOffset (AbstractQueuedSynchronizer.class.getDeclaredField("tail")); // 这块代码,实际在 static 代码块,此处为了方便理解,做了简化。 private final boolean compareAndSetTail(Node expect, Node update) { return unsafe.compareAndSwapObject(this, tailOffset, expect, update); }- 如果胖友对 Unsafe 不了解,请 Google 之。比较有趣的东东。
-
第 13 行:添加成功,最终,将原尾节点的下一个节点为新节点。
-
第 14 行:返回新节点。
-
如果添加失败,因为存在多线程并发的情况,此时需要执行【第 18 行】的代码。
-
========== 第 2 部分 ==========
-
调用
#enq(Node node)方法,多次尝试,直到成功添加。代码如下:1: private Node enq(final Node node) { 2: // 多次尝试,直到成功为止 3: for (;;) { 4: // 记录原尾节点 5: Node t = tail; 6: // 原尾节点不存在,创建首尾节点都为 new Node() 7: if (t == null) { 8: if (compareAndSetHead(new Node())) 9: tail = head; 10: // 原尾节点存在,添加新节点为尾节点 11: } else { 12: //设置为尾节点 13: node.prev = t; 14: // CAS 设置新的尾节点 15: if (compareAndSetTail(t, node)) { 16: // 成功,原尾节点的下一个节点为新节点 17: t.next = node; 18: return t; 19: } 20: } 21: } 22: }- 第 3 行:“死”循环,多次尝试,直到成功添加为止【第 18 行】。
- 第 5 行:记录原尾节点
t。 和#addWaiter(Node node)方法的【第 5 行】相同。 - 第 10 至 19 行:原尾节点存在,添加新节点为尾节点。 和
#addWaiter(Node node)方法的【第 7 至 16 行】相同。 - 第 6 至 9 行:原尾节点不存在,创建首尾节点都为 new Node() 。注意,此时修改的首尾节点是重新创建(
new Node())的,而不是新节点!-
这里,笔者的理解是,通过这样的方式,初始化好同步队列的首尾。另外,在 AbstractQueuedSynchronizer 的设计中,
head字段,是一个“占位节点”(暂时没想到特别好的比喻),代表最后一个获得到同步状态的节点(线程),实际它已经出列,所以它的Node.next才是真正的队首。当然,同步队列的初始时,new Node()也是满足这个条件,因为有新的 Node 进队列,目前就已经有线程获得到同步状态。 -
#compareAndSetHead(Node update)方法,使用 Unsafe 来 CAS 设置尾节点head为新节点。代码如下:private static final Unsafe unsafe = Unsafe.getUnsafe(); private static final long headOffset = unsafe.objectFieldOffset (AbstractQueuedSynchronizer.class.getDeclaredField("head")); // 这块代码,实际在 static 代码块,此处为了方便理解,做了简化。 private final boolean compareAndSetHead(Node update) { return unsafe.compareAndSwapObject(this, headOffset, null, update); }- 注意,第三个方法参数为
null,代表需要原head为空才可以设置。 和#compareAndSetTail(Node expect, Node update)方法,类似。
- 注意,第三个方法参数为
-
4. 出列
CLH 同步队列遵循 FIFO,首节点的线程释放同步状态后,将会唤醒它的下一个节点(Node.next)。而后继节点将会在获取同步状态成功时,将自己设置为首节点( head )。
这个过程非常简单,head 执行该节点并断开原首节点的 next 和当前节点的 prev 即可。注意,在这个过程是不需要使用 CAS 来保证的,因为只有一个线程,能够成功获取到同步状态。
过程图如下:

#setHead(Node node) 方法,实现上述的出列逻辑。代码如下:
|
AQS 的设计模式采用的模板方法模式,子类通过继承的方式,实现它的抽象方法来管理同步状态。对于子类而言,它并没有太多的活要做,AQS 已经提供了大量的模板方法来实现同步,主要是分为三类:
- 独占式获取和释放同步状态
- 共享式获取和释放同步状态
- 查询同步队列中的等待线程情况。
自定义子类使用 AQS 提供的模板方法,就可以实现自己的同步语义。
1. 独占式
独占式,同一时刻,仅有一个线程持有同步状态。
1.1 独占式同步状态获取
老艿艿:「1.1 独占式同步状态获取」 整个小节,是本文最难的部分。请一定保持耐心。
#acquire(int arg) 方法,为 AQS 提供的模板方法。该方法为独占式获取同步状态,但是该方法对中断不敏感。也就是说,由于线程获取同步状态失败而加入到 CLH 同步队列中,后续对该线程进行中断操作时,线程不会从 CLH 同步队列中移除。代码如下:
|
-
第 2 行:调用
#tryAcquire(int arg)方法,去尝试获取同步状态,获取成功则设置锁状态并返回 true ,否则获取失败,返回 false 。若获取成功,#acquire(int arg)方法,直接返回,不用线程阻塞,自旋直到获得同步状态成功。-
#tryAcquire(int arg)方法,需要自定义同步组件自己实现,该方法必须要保证线程安全的获取同步状态。代码如下:protected boolean tryAcquire(int arg) { throw new UnsupportedOperationException(); }- 直接抛出 UnsupportedOperationException 异常。
-
-
第 3 行:如果
#tryAcquire(int arg)方法返回 false ,即获取同步状态失败,则调用#addWaiter(Node mode)方法,将当前线程加入到 CLH 同步队列尾部。并且,mode方法参数为Node.EXCLUSIVE,表示独占模式。 -
第 3 行:调用
boolean #acquireQueued(Node node, int arg)方法,自旋直到获得同步状态成功。详细解析,见 「1.1.1 acquireQueued」 中。另外,该方法的返回值类型为boolean,当返回 true 时,表示在这个过程中,发生过线程中断。但是呢,这个方法又会清理线程中断的标识,所以在种情况下,需要调用【第 4 行】的#selfInterrupt()方法,恢复线程中断的标识,代码如下:static void selfInterrupt() { Thread.currentThread().interrupt(); }
1.1.1 acquireQueued
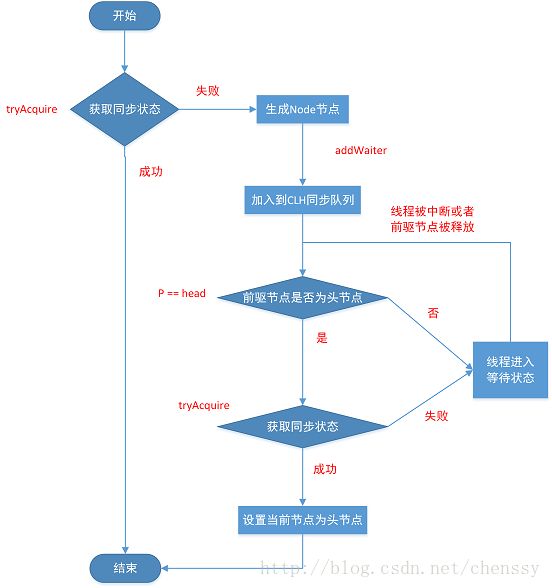
boolean #acquireQueued(Node node, int arg) 方法,为一个自旋的过程,也就是说,当前线程(Node)进入同步队列后,就会进入一个自旋的过程,每个节点都会自省地观察,当条件满足,获取到同步状态后,就可以从这个自旋过程中退出,否则会一直执行下去。
流程图如下:
代码如下:
|
- 第 3 行:
failed变量,记录是否获取同步状态成功。 - 第 6 行:
interrupted变量,记录获取过程中,是否发生线程中断。 - ========== 第 7 至 24 行:“死”循环,自旋直到获得同步状态成功。==========
- 第 12 行:调用
Node#predecessor()方法,获得当前线程的前一个节点p。 - 第 14 行:
p == head代码块,若满足,则表示当前线程的前一个节点为头节点,因为head是最后一个获得同步状态成功的节点,此时调用#tryAcquire(int arg)方法,尝试获得同步状态。 在#acquire(int arg)方法的【第 2 行】,也调用了这个方法。 - 第 15 至 18 行:当前节点( 线程 )获取同步状态成功:
- 第 15 行:设置当前节点( 线程 )为新的
head。 - 第 16 行:设置老的头节点
p不再指向下一个节点,让它自身更快的被 GC 。 - 第 17 行:标记
failed = false,表示获取同步状态成功。 - 第 18 行:返回记录获取过程中,是否发生线程中断。
- 第 15 行:设置当前节点( 线程 )为新的
- 第 20 至 24 行:获取失败,线程等待唤醒,从而进行下一次的同步状态获取的尝试。详细解析,见 《【死磕 Java 并发】—– J.U.C 之 AQS:阻塞和唤醒线程》 。详细解析,见 「1.1.2 shouldParkAfterFailedAcquire」 。
- 第 21 行:调用
#shouldParkAfterFailedAcquire(Node pre, Node node)方法,判断获取失败后,是否当前线程需要阻塞等待。
- 第 21 行:调用
- ========== 第 26 至 29 行:获取同步状态的过程中,发生异常,取消获取。==========
- 第 28 行:调用
#cancelAcquire(Node node)方法,取消获取同步状态。详细解析,见 「1.1.3 cancelAcquire」 。
1.1.2 shouldParkAfterFailedAcquire
|
pred和node方法参数,传入时,要求前者必须是后者的前一个节点。- 第 3 行:获得前一个节点(
pre)的等待状态。下面会根据这个状态有三种情况的处理。 - 第 4 至 9 行:等待状态为
Node.SIGNAL时,表示pred的下一个节点node的线程需要阻塞等待。在pred的线程释放同步状态时,会对node的线程进行唤醒通知。所以,【第 9 行】返回 true ,表明当前线程可以被 park,安全的阻塞等待。 - 第 19 至 26 行:等待状态为
0或者Node.PROPAGATE时,通过 CAS 设置,将状态修改为Node.SIGNAL,即下一次重新执行#shouldParkAfterFailedAcquire(Node pred, Node node)方法时,满足【第 4 至 9 行】的条件。- 但是,对于本次执行,【第 27 行】返回 false 。
- 另外,等待状态不会为
Node.CONDITION,因为它用在 ConditonObject 中。
- 第 10 至 18 行:等待状态为
NODE.CANCELLED时,则表明该线程的前一个节点已经等待超时或者被中断了,则需要从 CLH 队列中将该前一个节点删除掉,循环回溯,直到前一个节点状态<= 0。- 对于本次执行,【第 27 行】返回 false ,需要下一次再重新执行
#shouldParkAfterFailedAcquire(Node pred, Node node)方法,看看满足哪个条件。 - 整个过程如下图:
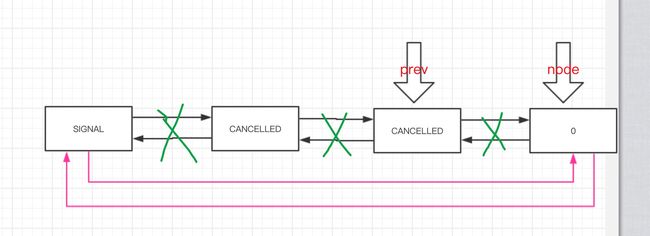
 转存失败重新上传取消
转存失败重新上传取消
- 对于本次执行,【第 27 行】返回 false ,需要下一次再重新执行
1.1.3 cancelAcquire
|
- 第 2 至 4 行:忽略,若传入参数
node为空。 - 第 6 行:将节点的等待线程置空。
- 第 9 行:获得
node节点的前一个节点pred。- 第 10 至 11 行: 逻辑同
#shouldParkAfterFailedAcquire(Node pred, Node node)的【第 15 至 17 行】。
- 第 10 至 11 行: 逻辑同
- 第 16 行:获得
pred的下一个节点predNext。在这个变量上,有很“复杂”的英文,我们来理解下:predNext从表面上看,和node是等价的。- 但是实际上,存在多线程并发的情况,所以在【第 25 行】或者【第 36 行】中,我们调用
#compareAndSetNext(...)方法,使用 CAS 的方式,设置pred的下一个节点。 - 如果设置失败,说明当前线程和其它线程竞争失败,不需要做其它逻辑,因为
pred的下一个节点已经被其它线程设置成功。
- 但是实际上,存在多线程并发的情况,所以在【第 25 行】或者【第 36 行】中,我们调用
- 第 21 行:设置
node节点的为取消的等待状态Node.CANCELLED。在这个变量上,有很“复杂”的英文,我们再来理解下:- 这里可以使用直接写,而不是 CAS 。
- 在这个操作之后,其它 Node 节点可以忽略
node。 Before, we are free of interference from other threads.TODO 9000 芋艿,如何理解。
- 下面开始开始修改
pred的新的下一个节点,一共分成三种情况。 - ========== 第一种 ==========
- 第 24 行:如果
node是尾节点,调用#compareAndSetTail(...)方法,CAS 设置pred为新的尾节点。- 第 25 行:若上述操作成功,调用
#compareAndSetNext(...)方法,CAS 设置pred的下一个节点为空(null)。
- 第 25 行:若上述操作成功,调用
- ========== 第二种 ==========
- 第 30 行:
pred非首节点。 - 第 31 至 32 行:
pred的等待状态为Node.SIGNAL,或者可被 CAS 为Node.SIGNAL。 - 第 33 行:
pred的线程非空。- TODO 9001 芋艿,如何理解。目前能想象到的,一开始 30 行为非头节点,在 33 的时候,结果成为头节点,线程已经为空了。
- 第 34 至 36 行:若
node的 下一个节点next的等待状态非Node.CANCELLED,则调用#compareAndSetNext(...)方法,CAS 设置pred的下一个节点为next。 - ========== 第三种 ==========
- 第 37 至 39 行:如果
pred为首节点( 在【第 31 至 33 行】也会有别的情况 ),调用#unparkSuccessor(Node node)方法,唤醒node的下一个节点的线程等待。详细解析,见 《【死磕 Java 并发】—– J.U.C 之 AQS:阻塞和唤醒线程》 。- 为什么此处需要唤醒呢?因为,
pred为首节点,node的下一个节点的阻塞等待,需要node释放同步状态时进行唤醒。但是,node取消获取同步状态,则不会再出现node释放同步状态时进行唤醒node的下一个节点。因此,需要此处进行唤醒。
- 为什么此处需要唤醒呢?因为,
- ========== 第 二 + 三种 ==========
- 第 41 行:TODO 芋艿 9002 为啥是 next 为 node 。目前收集到的资料如下:
-
http://donald-draper.iteye.com/blog/2360256
-
next的注释如下:/** * Link to the successor node that the current node/thread * unparks upon release. Assigned during enqueuing, adjusted * when bypassing cancelled predecessors, and nulled out (for * sake of GC) when dequeued. The enq operation does not * assign next field of a predecessor until after attachment, * so seeing a null next field does not necessarily mean that * node is at end of queue. However, if a next field appears * to be null, we can scan prev's from the tail to * double-check. The next field of cancelled nodes is set to * point to the node itself instead of null, to make life * easier for isOnSyncQueue. */- 最后一句话
-
1.2 独占式获取响应中断
AQS 提供了acquire(int arg) 方法,以供独占式获取同步状态,但是该方法对中断不响应,对线程进行中断操作后,该线程会依然位于CLH同步队列中,等待着获取同步状态。为了响应中断,AQS 提供了 #acquireInterruptibly(int arg) 方法。该方法在等待获取同步状态时,如果当前线程被中断了,会立刻响应中断,并抛出 InterruptedException 异常。
|
- 首先,校验该线程是否已经中断了,如果是,则抛出InterruptedException 异常。
- 然后,调用
#tryAcquire(int arg)方法,尝试获取同步状态,如果获取成功,则直接返回。 - 最后,调用
#doAcquireInterruptibly(int arg)方法,自旋直到获得同步状态成功,或线程中断抛出 InterruptedException 异常。 - 应该不仅仅 help gc
1.2.1 doAcquireInterruptibly
|
它与 #acquire(int arg) 方法仅有两个差别:
- 方法声明抛出 InterruptedException 异常。
- 在中断方法处不再是使用
interrupted标志,而是直接抛出 InterruptedException 异常,即<1>处。
1.3 独占式超时获取
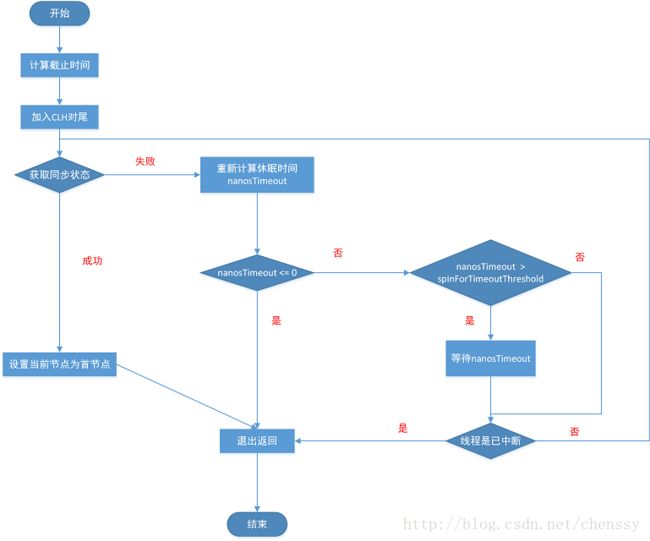
AQS 除了提供上面两个方法外,还提供了一个增强版的方法 #tryAcquireNanos(int arg, long nanos) 。该方法为 #acquireInterruptibly(int arg) 方法的进一步增强,它除了响应中断外,还有超时控制。即如果当前线程没有在指定时间内获取同步状态,则会返回 false ,否则返回 true 。
流程图如下:
代码如下:
|
- 首先,校验该线程是否已经中断了,如果是,则抛出InterruptedException 异常。
- 然后,调用
#tryAcquire(int arg)方法,尝试获取同步状态,如果获取成功,则直接返回。 - 最后,调用
#tryAcquireNanos(int arg)方法,自旋直到获得同步状态成功,或线程中断抛出 InterruptedException 异常,或超过指定时间返回获取同步状态失败。
1.3.1 tryAcquireNanos
|
- 因为是在
#doAcquireInterruptibly(int arg)方法的基础上,做了超时控制的增强,所以相同部分,我们直接跳过。 - 第 3 至 5 行:如果超时时间小于 0 ,直接返回 false ,已经超时。
- 第 7 行:计算最终超时时间
deadline。 - 第 9 行:【相同,跳过】
- 第 10 行:【相同,跳过】
- 第 13 行:【相同,跳过】
- 第 14 行:【相同,跳过】
- 第 15 至 21 行:【相同,跳过】
- 第 26 行:重新计算剩余可获取同步状态的时间
nanosTimeout。 - 第 27 至 29 行:如果剩余时间小于 0 ,直接返回 false ,已经超时。
- 第 33 行:【相同,跳过】
- 第 34 至 35 行:如果剩余时间大于
spinForTimeoutThreshold,则调用LockSupport#parkNanos(Object blocker, long nanos)方法,休眠nanosTimeout纳秒。否则,就不需要休眠了,直接进入快速自旋的过程。原因在于,spinForTimeoutThreshold已经非常小了,非常短的时间等待无法做到十分精确,如果这时再次进行超时等待,相反会让nanosTimeout的超时从整体上面表现得不是那么精确。所以,在超时非常短的场景中,AQS 会进行无条件的快速自旋。 - 第 36 至 39 行:若线程已经中断了,抛出 InterruptedException 异常。
- 第 40 至 43 行:【相同,跳过】
1.4 独占式同步状态释放
当线程获取同步状态后,执行完相应逻辑后,就需要释放同步状态。AQS 提供了#release(int arg)方法,释放同步状态。代码如下:
|
-
第 2 行:调用
#tryRelease(int arg)方法,去尝试释放同步状态,释放成功则设置锁状态并返回 true ,否则获取失败,返回 false 。同时,它们分别对应【第 3 至 6】和【第 8 行】的逻辑。-
#tryRelease(int arg)方法,需要自定义同步组件自己实现,该方法必须要保证线程安全的释放同步状态。代码如下:protected boolean tryRelease(int arg) { throw new UnsupportedOperationException(); }- 直接抛出 UnsupportedOperationException 异常。
-
-
第 3 行:获得当前的
head,避免并发问题。 -
第 4 行:头结点不为空,并且头结点状态不为 0 (
INITAL未初始化)。为什么会出现 0 的情况呢?老艿艿的想法是,以 ReentrantReadWriteLock ( 内部基于 AQS 实现 ) 举例子:-
线程 A 和线程 B ,都获取了读锁。
-
线程 A 和线程 B ,基本同时释放锁,那么此时【第 3 行】
h可能获取到的是相同的head节点。此时,A 线程恰好先执行了#unparkSuccessor(Node node)方法,会将waitStatus设置为 0 。因此,#unparkSuccessor(Node node)方法,对于 B 线程就不需要调用了。当然,更极端的情况下,可能 A 和 B 线程,都调用了#unparkSuccessor(Node node)方法。老艿艿:如上是我的猜想,并未实际验证。如果不正确,或者有其他情况,欢迎斧正。
-
-
第 5 行:调用
#unparkSuccessor(Node node)方法,唤醒下一个节点的线程等待。详细解析,见 《【死磕 Java 并发】—– J.U.C 之 AQS:阻塞和唤醒线程》 。
1.5 总结
这里稍微总结下:
在 AQS 中维护着一个 FIFO 的同步队列。
- 当线程获取同步状态失败后,则会加入到这个 CLH 同步队列的对尾,并一直保持着自旋。
- 在 CLH 同步队列中的线程在自旋时,会判断其前驱节点是否为首节点,如果为首节点则不断尝试获取同步状态,获取成功则退出CLH同步队列。
- 当线程执行完逻辑后,会释放同步状态,释放后会唤醒其后继节点。
2. 共享式
共享式与独占式的最主要区别在于,同一时刻:
- 独占式只能有一个线程获取同步状态。
- 共享式可以有多个线程获取同步状态。
例如,读操作可以有多个线程同时进行,而写操作同一时刻只能有一个线程进行写操作,其他操作都会被阻塞。参见 ReentrantReadWriteLock 。
2.1 共享式同步状态获取
AQS 提供 #acquireShared(int arg) 方法,共享式获取同步状态。代码如下:
#acquireShared(int arg)方法,对标#acquire(int arg)方法。
|
- 第 2 行:调用
#tryAcquireShared(int arg)方法,尝试获取同步状态,获取成功则设置锁状态并返回大于等于 0 ,否则获取失败,返回小于 0 。若获取成功,直接返回,不用线程阻塞,自旋直到获得同步状态成功。-
#tryAcquireShared(int arg)方法,需要自定义同步组件自己实现,该方法必须要保证线程安全的获取同步状态。代码如下:protected int tryAcquireShared(int arg) { throw new UnsupportedOperationException(); }- 直接抛出 UnsupportedOperationException 异常。
-
2.1.1 doAcquireShared
|
- 因为和
#acquireQueued(int arg)方法的基础上,所以相同部分,我们直接跳过。 - 第 3 行:调用
#addWaiter(Node mode)方法,将当前线程加入到 CLH 同步队列尾部。并且,mode方法参数为Node.SHARED,表示共享模式。 - 第 6 行:【相同,跳过】
- 第 9 至 22 行:【大体相同,部分跳过】
- 第 13 行:调用
#tryAcquireShared(int arg)方法,尝试获得同步状态。 在#acquireShared(int arg)方法的【第 2 行】,也调用了这个方法。 - 第 15 行:调用
#setHeadAndPropagate(Node node, int propagate)方法,设置新的首节点,并根据条件,唤醒下一个节点。详细解析,见 「2.1.2 setHeadAndPropagate」 。- 这里和独占式同步状态获取很大的不同:通过这样的方式,不断唤醒下一个共享式同步状态, 从而实现同步状态被多个线程的共享获取。
- 第 17 至 18 行:和
#acquire(int arg)方法,对于线程中断的处理方式相同,只是代码放置的位置不同。
- 第 13 行:调用
- 第 23 至 25 行:【相同,跳过】
- 第 27 至 30 行:【相同,跳过】
2.1.2 setHeadAndPropagate
|
- 第 2 行:记录原来的首节点
h。 - 第 3 行:调用
#setHead(Node node)方法,设置node为新的首节点。 - 第 20 行:
propagate > 0代码块,说明同步状态还能被其他线程获取。 - 第 20 至 21 行:判断原来的或者新的首节点,等待状态为
Node.PROPAGATE或者Node.SIGNAL时,可以继续向下唤醒。 - 第 23 行:调用
Node#isShared()方法,判断下一个节点为共享式获取同步状态。 - 第 24 行:调用
#doReleaseShared()方法,唤醒后续的共享式获取同步状态的节点。详细解析,见 「2.1.2 setHeadAndPropagate」 。
2.2 共享式获取响应中断
#acquireSharedInterruptibly(int arg) 方法,代码如下:
|
- 与 「1.2 独占式获取响应中断」 类似,就不重复解析了。
2.3 共享式超时获取
#tryAcquireSharedNanos(int arg, long nanosTimeout) 方法,代码如下:
|
- 与 「1.3 独占式超时获取」 类似,就不重复解析了。
2.4 共享式同步状态释放
当线程获取同步状态后,执行完相应逻辑后,就需要释放同步状态。AQS 提供了#releaseShared(int arg)方法,释放同步状态。代码如下:
|
-
第 2 行:调用
#tryReleaseShared(int arg)方法,去尝试释放同步状态,释放成功则设置锁状态并返回 true ,否则获取失败,返回 false 。同时,它们分别对应【第 3 至 5】和【第 6 行】的逻辑。-
#tryReleaseShared(int arg)方法,需要自定义同步组件自己实现,该方法必须要保证线程安全的释放同步状态。代码如下:protected boolean tryReleaseShared(int arg) { throw new UnsupportedOperationException(); }- 直接抛出 UnsupportedOperationException 异常。
-
-
第 3 行:调用
#doReleaseShared()方法,唤醒后续的共享式获取同步状态的节点。
2.4.1 doReleaseShared
|
1. parkAndCheckInterrupt
在线程获取同步状态时,如果获取失败,则加入 CLH 同步队列,通过通过自旋的方式不断获取同步状态,但是在自旋的过程中,则需要判断当前线程是否需要阻塞,其主要方法在acquireQueued(int arg) ,代码如下:
|
通过这段代码我们可以看到,在获取同步状态失败后,线程并不是立马进行阻塞,需要检查该线程的状态,检查状态的方法为 #shouldParkAfterFailedAcquire(Node pred, Node node)方法,该方法主要靠前驱节点判断当前线程是否应该被阻塞。详细解析,在 《【死磕 Java 并发】—– J.U.C 之 AQS:同步状态的获取与释放》 的 「1.1.2 shouldParkAfterFailedAcquire」 已经解析。
如果 #shouldParkAfterFailedAcquire(Node pred, Node node) 方法返回 true ,则调用parkAndCheckInterrupt() 方法,阻塞当前线程。代码如下:
|
- 开始,调用
LockSupport#park(Object blocker)方法,将当前线程挂起,此时就进入阻塞等待唤醒的状态。详细的实现,在 「3. LockSupport」 中。 - 然后,在线程被唤醒时,调用
Thread#interrupted()方法,返回当前线程是否被打断,并清理打断状态。所以,实际上,线程被唤醒有两种情况:- 第一种,当前节点(线程)的前序节点释放同步状态时,唤醒了该线程。详细解析,见 「2 unparkSuccessor」 。
- 第二种,当前线程被打断导致唤醒。
2. unparkSuccessor
当线程释放同步状态后,则需要唤醒该线程的后继节点。代码如下:
|
调用 unparkSuccessor(Node node) 方法,唤醒后继节点:
|
-
可能会存在当前线程的后继节点为
null,例如:超时、被中断的情况。如果遇到这种情况了,则需要跳过该节点。- 但是,为何是从
tail尾节点开始,而不是从node.next开始呢?原因在于,取消的node.next.next指向的是node.next自己。如果顺序遍历下去,会导致死循环。所以此时,只能采用tail回溯的办法,找到第一个( 不是最新找到的,而是最前序的 )可用的线程。 - 再但是,为什么取消的
node.next.next指向的是node.next自己呢?在#cancelAcquire(Node node)的末尾,node.next = node;代码块,取消的node节点,将其next指向了自己。
- 但是,为何是从
-
最后,调用
LockSupport的unpark(Thread thread)方法,唤醒该线程。详细的实现,在 「3. LockSupport」 中。
3. LockSupport
从上面我可以看到,当需要阻塞或者唤醒一个线程的时候,AQS 都是使用 LockSupport 这个工具类来完成的。
LockSupport 是用来创建锁和其他同步类的基本线程阻塞原语。
每个使用 LockSupport 的线程都会与一个许可与之关联:
如果该许可可用,并且可在进程中使用,则调用 #park(...) 将会立即返回,否则可能阻塞。 如果许可尚不可用,则可以调用 #unpark(...) 使其可用。 但是,注意许可不可重入,也就是说只能调用一次 park(...) 方法,否则会一直阻塞。
LockSupport 定义了一系列以 park 开头的方法来阻塞当前线程,unpark(Thread thread) 方法来唤醒一个被阻塞的线程。如下图所示:

park(Object blocker) 方法的blocker参数,主要是用来标识当前线程在等待的对象,该对象主要用于问题排查和系统监控。 park 方法和 unpark(Thread thread) 方法,都是成对出现的。同时 unpark(Thread thread) 方法,必须要在 park 方法执行之后执行。当然,并不是说没有调用 unpark(Thread thread) 方法的线程就会一直阻塞,park 有一个方法,它是带了时间戳的 #parkNanos(long nanos) 方法:为了线程调度禁用当前线程,最多等待指定的等待时间,除非许可可用。
3.1 park
|
3.2 unpark
|
3.3 实现原理
从上面可以看出,其内部的实现都是通过 sun.misc.Unsafe 来实现的,其定义如下:
|
两个都是 native 本地方法。Unsafe 是一个比较危险的类,主要是用于执行低级别、不安全的方法集合。尽管这个类和所有的方法都是公开的(使用 public 进行修饰),但是这个类的使用仍然受限,你无法在自己的 Java 程序中直接使用该类,因为只有授信的代码才能获得该类的实例。