使用Python对冒泡排序的再次优化(python-the re-optimization of bubble sort )
冒泡排序性能再次优化
之前的优化是在原有普通的冒泡排序的基础上,加入排序标记,如果检查相邻元素之后发现并没有发生元素顺序的调换,那么则可以看做已经排好序了,直接退出,进行下次循环
1. 问题描述
虽然效果已经比之前普通的冒泡排序要好很多,但是性能还是可以再做优化,尤其是在处理一些前半部分是无序,但是后半部分是有序的情况下,冒泡排序还会再去比较一次,这样其实是比较浪费的。
举个例子,比如[10,2,-4,7,3,11,9,13,14,15,16,17,18]
这个列表的前半部分是无序的,但是后半部分实际上已经是有序了的,
第一轮遍历
第一次:10跟2进行比较,10>2,进行交换
[2,10,-4,7,3,11,9,13,14,15,16,17,18]
第二次:10跟-4进行比较,10>-4 ,进行交换
[2,-4,10,7,3,11,9,13,14,15,16,17,18]
第三次:10跟7进行比较,10>7,进行交换
[2,-4,7,10,3,11,9,13,14,15,16,17,18]
第四次:10跟3进行比较,10>3,进行交换
[2,-4,7,3,10,11,9,13,14,15,16,17,18]
第五次:10跟11,进行比较,10<11,不动
[2,-4,7,3,10,11,9,13,14,15,16,17,18]
第六次:11跟9比较,11>9,进行交换
[2,-4,7,3,10,9,11,13,14,15,16,17,18]
虽然后面的元素已经是有序的了,但是冒泡排序还是会两个两个比较下去,直到元素比较完毕
这就是问题所在,这样的序列是有一定概率会出现的,那怎么应对?
2.解决办法
可以确定一个变量,用来存储最后一次发生交换时的元素下标,那么在这个界限下,变量后面的元素已经都是有序了的,那我们只需要在剩下的无序元素当中去完成就可以了
原理说完之后,上代码
# 进行优化
def optimization_bubble_sort(res):
'''
每一轮排序,记录好最后一次交换的列表元素下标,作为无序列表的界限
:param res: 制作的特殊列表
:return:优化之后得到的已排序的列表
'''
lastExchangeIndex = 0 # 设置最后一次发生交换的元素下标
sortIndex = len(res) - 1 # 设置无序列表的下标范围
for i in range(len(res) - 1):
# 确定是否排好序的标志
isSorted = True
for j in range(sortIndex):
if res[j] > res[j + 1]:
res[j], res[j + 1] = res[j + 1], res[j]
isSorted = False
lastExchangeIndex = j # 更新最后一次发生交换的元素下标
sortIndex = lastExchangeIndex # 更新无序列表的下标范围
if isSorted: break
return res
这样,经过有序的处理之后,每次已经排好的列表就不需要再次遍历了
3、创建一个特殊的列表做测试
def create_random_numList():
'''
创建随机数组
:return: 前半部分是无序,后半部分有序
'''
num = int(input('请输入想要得到的数组规模:'))
start_n = int(input('请输入开始的数字:'))
end_n = int(input('请输入结束的数字:'))
for i in range(num):
n = random.randint(start_n, end_n)
num_list.append(n)
num_index = len(num_list) // 2
# 前半部分获取原来的产生的元素
left_list = num_list[:num_index]
# 后半部分获取提前排好序的列表
right_list = optimization_bubble_sort(num_list[num_index:])
res_list = left_list + right_list
return res_list
在生成随机列表的时候就可以加上刚才排序的方法了
可以按照自己的喜好,设置列表规模和产生随机数的具体范围
import random
num_list = []
res_list = []
# 创建随机列表
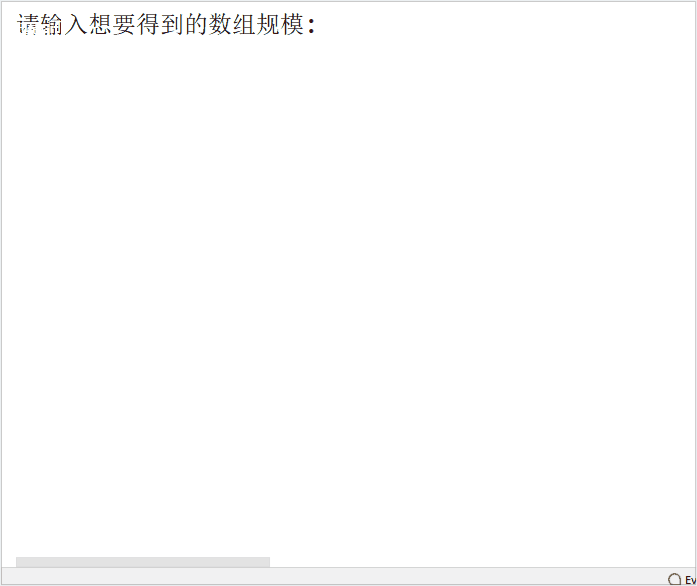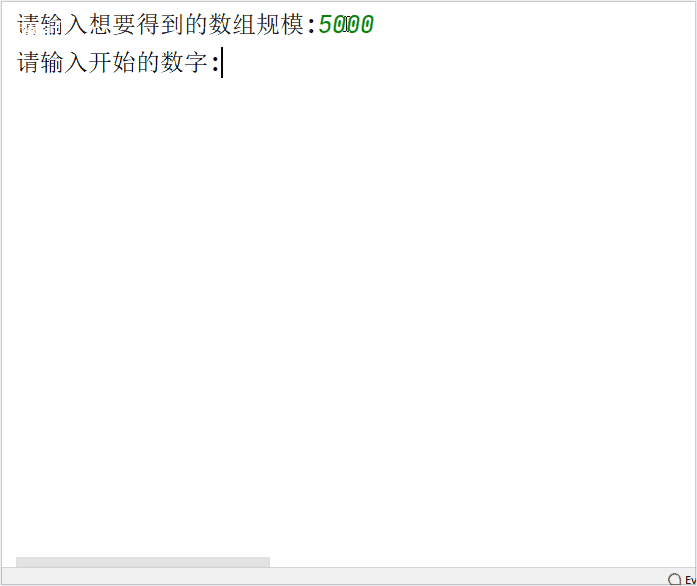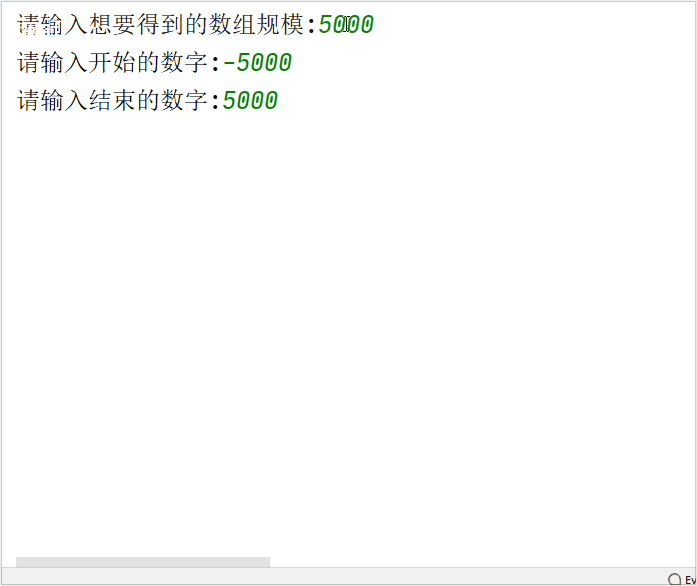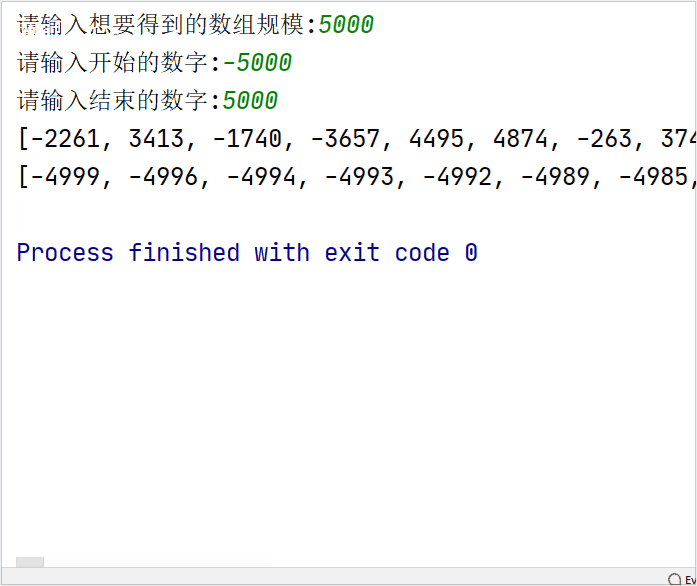
res = create_random_numList()
print(res)
# 优化冒泡排序得到的结果
optimization = optimization_bubble_sort(res)
print(optimization)
经过优化后的冒泡排序,运行的效率又是一个提升