数据压缩试验三:LZW 编码原理与C语言实现
LZW 编解码原理
背景
LZW 编码作为词典编码的一种,由 J. Ziv 和 A. Lempel 在 1978 年首次提出并由 Terry A. Welch 在 1984 年改进,最终以三人名字缩写命名。
基本原理
企图从输入的数据中创建一个“短语词典”(Dictionary Of the Phrases),这种短语可以是任意字符的组合。编码数据过程中当遇到已经在词典中出现的“短语”时,编码器就会输出这个词典中的短语的“索引号”而不是短语本身,进而达到压缩的目的。
编码
编码思路
将当前读取到的单字符记为 C(Current),将之前读取的但还未编码的字符或字符串记为 P(Previous),则编码思路可以通过以下流程图呈现
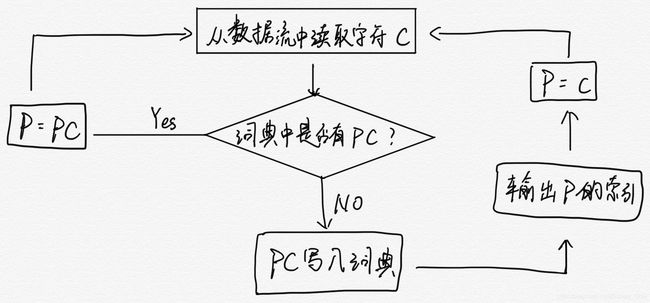
在最终的代码实现中,通过树的思想对词典进行构建,将每一个词条作为树中的一个节点,将每个节点(词条)定义为结构体,具有以下结构
- 尾缀字符(suffix)
- 母节点(parent)
- 第一个子节点(firstChild)
- 下一个兄弟节点(nextSibling)
此时每一个节点就可以用旧节点词条+新字符表示新的节点词条,进而简化查询步骤。
编码举例
现在以字符流“abbababac”举例,分别进行编码步骤演示与树的建立,初始化词典是用 ASCII 进行索引(a = 97,b = 98,c = 99)
| 步骤数 | P | C | PC 是否在词典中 | 是否输出 P的索引 | 新增词条 | 说明 |
|---|---|---|---|---|---|---|
| 1 | NULL | a | - | - | - | 初始化词典 |
| 2 | a | b | 否 | 是,输出97 | 256(ab) | ab 不在词典中,扩充词典,然后 P 变为 b |
| 3 | b | b | 否 | 是,输出98 | 257(bb) | bb 不在词典中,扩充词典,然后 P 变为 b |
| 4 | b | a | 否 | 是,输出98 | 258(ba) | ba 不在词典中,扩充词典,然后 P 变为 a |
| 5 | a | b | 是 | 否 | - | ab 在词典中,故不需要新建词条,P 变为 ab |
| 6 | ab | a | 否 | 是,输出256 | 259(aba) | aba 不在词典中,扩充词典,然后 P 变为 a |
| 7 | a | b | 是 | 否 | - | ab 在词典中,故不需要新建词条,P 变为 ab |
| 8 | ab | a | 是 | 否 | - | aba 在词典中,故不需要新建词条,P 变为 aba |
| 9 | aba | c | 否 | 是,输出259 | 260(abac) | abac 不在词典中,扩充词典,然后 P 变为 c |
| 10 | c | NULL | - | 是,输出99 | - | 无新的字符,结束编码,输出未编码字符 |
相应的树为下图所示

以词条 “bb”为例,他的 suffix 为 b,parent 为 b,firstChild 为 NULL,nextSibling 为 ba
解码
解码思路
将当前码字记为 cW,上一个码码字记为 pW,解码思路可以通过以下框图体现
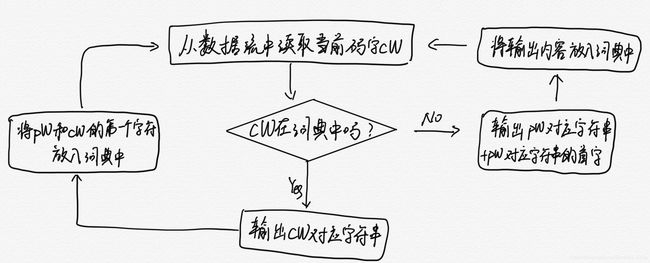
因为在实时编解码时,解码要比编码晚一个码字,因而存在码字词条刚被创造就被使用但在解码端还没有相应词条的情况(比如上述编码示例中的 “ababa” 字段),所以在查词典时判断若 cW 不在词典时便手动定义当前码字代表内容为“上一码字代表内容+上一码字代表内容的首字符”,以解决此类问题。
解码举例
词典在最开始已被初始化为 ASCII 码表内容,此处以“97 98 98 256 259 99”作为带解码流
| 步骤数 | pW | cW | cW 是否在词典中 | 输出内容 | 新增词条 | 说明 |
|---|---|---|---|---|---|---|
| 1 | NULL | 97 | 是 | a | - | 97 已经在词典中,因而输出 cW,新增 pW + cW 首字符 |
| 2 | 97 | 98 | 是 | b | ab: 256 | 98 已经在词典中,因而输出 cW,新增 pW + cW 首字符 |
| 3 | 98 | 98 | 是 | b | b b: 257 | 98 已经在词典中,因而输出 cW,新增 pW + cW 首字符 |
| 4 | 98 | 256 | 是 | ab | ba: 258 | 256 已经在词典中,因而输出 cW,新增 pW + cW 首字符 |
| 5 | 256 | 259 | 否 | aba | aba: 259 | 259 不在词典中,因而输出pW + pW 首字符,并将其添加到词典中 |
| 6 | 259 | 99 | 是 | c | abac: abac | 99 已经在词典中,因而输出 cW,新增 pW + cW 首字符 |
代码实现
bitIO.h
#ifndef __BITIO__
#define __BITIO__
#include bitIO.c
#include LZW.c
#include 主要定义了每个字符串存储时的结构,并声明了用到的函数
void PrintDictionary( void)
{
int n;
int count;
for( n=256; n<next_code; n++)
{
count = DecodeString( 0, n);
printf( "%4d->", n);
while( 0<count--)
printf("%c", (char)(d_stack[count]));
printf( "\n");
}
}
通过 for 循环实现了查找词典与输出字符串
int DecodeString( int start, int code){
int count;
count = start;
while( 0<=code)
{
d_stack[count] = dictionary[code].suffix;
code = dictionary[code].parent;
count ++;
}
return count;
}
通过对树的查找将对应码字写入栈
void InitDictionary(void)
{
int i;
for( i=0; i<256; i++)
{
dictionary[i].suffix = i;
dictionary[i].parent = -1;
dictionary[i].firstchild = -1;
dictionary[i].nextsibling = i+1;
}
dictionary[255].nextsibling = -1;
next_code = 256;
}
对词典进行初始化
/*
* Input: string represented by string_code in dictionary,
* Output: the index of character+string in the dictionary
* index = -1: if not found
*/
int InDictionary( int character, int string_code)
{
int sibling;
if(0>string_code)
return character;
sibling = dictionary[string_code].firstchild;
while(-1<sibling)
{
if(character == dictionary[sibling].suffix)
return sibling;
sibling = dictionary[sibling].nextsibling;
}
return -1;
}
通过 while 循环寻找与character相同的节点。
若有,则返回节点值;若没有,则返回 -1
void AddToDictionary(int character, int string_code)
{
int firstsibling, nextsibling;
if( 0>string_code)
return;
dictionary[next_code].suffix = character;
dictionary[next_code].parent = string_code;
dictionary[next_code].nextsibling = -1;
dictionary[next_code].firstchild = -1;
firstsibling = dictionary[string_code].firstchild;
if( -1<firstsibling)
{ // the parent has child
nextsibling = firstsibling;
while( -1<dictionary[nextsibling].nextsibling )
nextsibling = dictionary[nextsibling].nextsibling;
dictionary[nextsibling].nextsibling = next_code;
}
else
{// no child before, modify it to be the first
dictionary[string_code].firstchild = next_code;
}
next_code ++;
}
将新的字符串编码加入词典:
若节点有子节点,则通过 while 循环找到最后一个子节点并将新编码作为它的下一个兄弟节点
若节点没有子节点,则将新的编码设为其子节点
void LZWEncode( FILE *fp, BITFILE *bf)
{
int character;
int string_code;
int index;
unsigned long file_length;
fseek( fp, 0, SEEK_END);
file_length = ftell( fp);
fseek( fp, 0, SEEK_SET);
BitsOutput( bf, file_length, 4*8);
InitDictionary();
string_code = -1;
while( EOF!=(character=fgetc( fp)))
{
index = InDictionary( character, string_code);
if( 0<=index)
{ // string+character in dictionary
string_code = index;
}
else
{ // string+character not in dictionary
output( bf, string_code);
if( MAX_CODE > next_code)
{ // free space in dictionary
// add string+character to dictionary
AddToDictionary( character, string_code);
}
string_code = character;
}
}
output( bf, string_code);
}
进行 LZW 编码
void LZWDecode( BITFILE *bf, FILE *fp)
{
int character;
int new_code, last_code;
int phrase_length;
unsigned long file_length;
file_length = BitsInput( bf, 4*8);
if( -1 == file_length) file_length = 0;
InitDictionary();
last_code = -1;
while( 0<file_length)
{
new_code = input( bf);
if( new_code >= next_code)
{ // this is the case CSCSC( not in dict)
d_stack[0] = character;
phrase_length = DecodeString( 1, last_code);
}else
{
phrase_length = DecodeString( 0, new_code);
}
character = d_stack[phrase_length-1];
while( 0<phrase_length)
{
phrase_length --;
fputc( d_stack[ phrase_length], fp);
file_length--;
}
if( MAX_CODE>next_code)
{ // add the new phrase to dictionary
AddToDictionary( character, last_code);
}
last_code = new_code;
}
}
进行 LZW 解码
int main( int argc, char **argv)
{
FILE *fp;
BITFILE *bf;
if( 4>argc)
{
fprintf( stdout, "usage: \n%s \n" , argv[0]);
fprintf( stdout, "\t: E or D reffers encode or decode\n" );
fprintf( stdout, "\t: input file name\n" );
fprintf( stdout, "\t: output file name\n" );
return -1;
}
if( 'E' == argv[1][0])
{ // do encoding
fp = fopen( argv[2], "rb");
bf = OpenBitFileOutput( argv[3]);
if( NULL!=fp && NULL!=bf)
{
LZWEncode( fp, bf);
fclose( fp);
CloseBitFileOutput( bf);
fprintf( stdout, "encoding done\n");
}
}else if( 'D' == argv[1][0])
{ // do decoding
bf = OpenBitFileInput( argv[2]);
fp = fopen( argv[3], "wb");
if( NULL!=fp && NULL!=bf)
{
LZWDecode( bf, fp);
fclose( fp);
CloseBitFileInput( bf);
fprintf( stdout, "decoding done\n");
}
}else
{ // otherwise
fprintf( stderr, "not supported operation\n");
}
return 0;
}