第一范式,第二范式,第三范式
第一范式
存在非主属性对码的部分依赖关系 R(A,B,C) AB是码 C是非主属性 B-->C B决定C C部分依赖于B
第一范式
定义:如果关系R 中所有属性的值域都是单纯域,那么关系模式R是第一范式的
那么符合第一模式的特点就有
1)有主关键字
2)主键不能为空,
3)主键不能重复,
4)字段不可以再分
例如:
StudyNo | Name | Sex | Contact
20040901 john Male Email:[email protected],phone:222456
20040901 mary famale email:[email protected] phone:123455
以上的表就不符合,第一范式:主键重复(实际中数据库不允许重复的),而且Contact字段可以再分
所以变更为正确的是
StudyNo | Name | Sex | Email | Phone
20040901 john Male [email protected] 222456
20040902 mary famale [email protected] 123455
第二范式
存在非主属性对码的传递性依赖 R(A,B,C) A是码 A -->B ,B-->C
定义:如果关系模式R是第一范式的,而且关系中每一个非主属性不部分依赖于主键,称R是第二范式的。
所以第二范式的主要任务就是
满足第一范式的前提下,消除部分函数依赖。
StudyNo | Name | Sex | Email | Phone | ClassNo | ClassAddress
01 john Male [email protected] 222456 200401 A楼2
01 mary famale [email protected] 123455 200402 A楼3
这个表完全满足于第一范式,
主键由StudyNo和ClassNo组成,这样才能定位到指定行
但是,ClassAddress部分依赖于关键字(ClassNo-〉ClassAddress),
所以要变为两个表
表一
StudyNo | Name | Sex | Email | Phone | ClassNo
01 john Male [email protected] 222456 200401
01 mary famale [email protected] 123455 200402
表二
ClassNo | ClassAddress
200401 A楼2
200402 A楼3
第三范式
不存在非主属性对码的传递性依赖以及部分性依赖 ,
StudyNo | Name | Sex | Email | bounsLevel | bouns
20040901 john Male [email protected] 优秀 $1000
20040902 mary famale [email protected] 良 $600
这个完全满足了第二范式,但是bounsLevel和bouns存在传递依赖
更改为:
StudyNo | Name | Sex | Email | bouunsNo
20040901 john Male [email protected] 1
20040902 mary famale [email protected] 2
bounsNo | bounsLevel | bouns
1 优秀 $1000
2 良 $600
这里我比较喜欢用bounsNo作为主键,
基于两个原因
1)不要用字符作为主键。可能有人说:如果我的等级一开始就用数值就代替呢?
2)但是如果等级名称更改了,不叫 1,2 ,3或优、良,这样就可以方便更改,所以我一般优先使用与业务无关的字段作为关键字。
一般满足前三个范式就可以避免数据冗余。
第一范式 1NF
属性不可再分割,符合原子性。
没什么好解释的,地球人都明白
第二范式 2NF
在1NF的基础上:
不允许出现有field部分依赖于主键(或者说依赖于主键的一部分)
官方说法:数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于整组候选关键字。
Allen解释一下:比如一张表是(A, B, C, D),其中(A, B)是主键,如果存在B->C就违反了2NF,因为C只需要主键的一部分就可以被决定了
第三范式 3NF
在2NF的基础上:
不允许出现可传递的依赖关系(transitive dependencies)
官方说法:在第二范式的基础上,数据表中如果不存在非关键字段对关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A
很容易理解,Kiza同学说这是人类的常识。
Boyce-Codd范式 BCNF
在3NF的基础上:
不允许出现有主键的一部分被主键另一部分或者其他部分决定
另一种说法:Left side of every non-trivial FD must contains a key
每个非平凡FD的左边必须有一个主键
BCNF,表中的每个决定因子是候选键。如果只有一个候选键,则3NF和BCNF相同
网友们通常喜欢用的一个例子:
假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
也就是说,(仓库ID, 存储物品ID)这个主键中的仓库ID可以被管理员ID决定,同样(管理员ID, 存储物品ID)中管理员ID也可以被仓库ID决定,所以此表应该拆分。
3NF->BCNF的步骤:
1. 一个表,从所给的FD中,找出一个FD左边没有key的
2. 给这个FD的右边补全属性(field)。
3. 此时得到两个表,一个是第2步中得到的FD中的表,另一个是第2步中FD的所有左边 及 其他所有没有在这个FD中出现的属性组成的表
4. 投影总的FD分别到两个表
如果仍然有表violation,继续分解
例如:
表(Name, Location, Application, Provider, FavAppl)
FD: Name->Location, Name->FavAppl, Application->Provider
Key: Name, Application
1. Name->Location的左边没有key。
2. 将其补充。Name->Location, Name->FavAppl,因此得到表(Name, Location, FavAppl)
3. 一个表是(Name, Location, FavAppl)。另一个表,”第2步中FD的所有左边“是指Name,“其他所有没有在这个FD中出现的属性”是指Application和
Provider。因此第二个表是(Name, Application, Provider)
4. 第二个表中,Application->Provider的左边没有key,继续分解第二个表
最终结果,原表分为了(Name, Location, Provider),(Application, Provider),(Application, Name)
总结:
1NF
| 消除非主属性对码的部分依赖
2NF
| 消除非主属性对码的传递依赖
3NF
| 消除主属性对码的部分和传递依赖
BCNF
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
在实际开发中最为常见的设计范式有三个:
1.第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
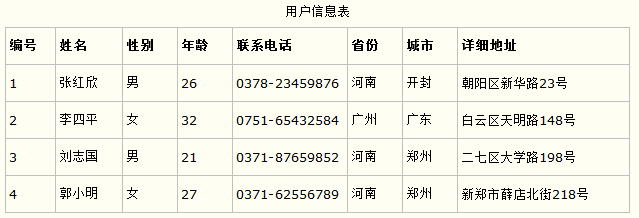
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表

这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
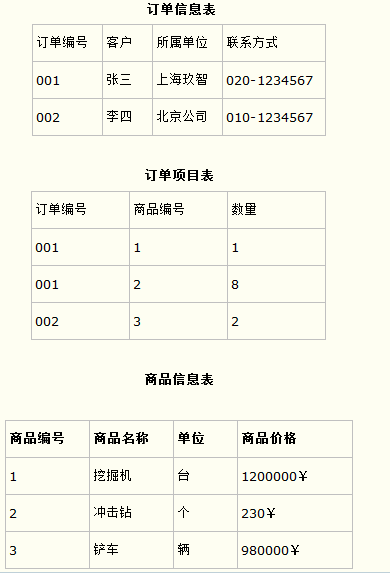
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。

这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
引用地址:http://www.cnblogs.com/linjiqin/archive/2012/04/01/2428695.html;http://blog.csdn.net/allenlsy/article/details/5356899;http://www.cnblogs.com/GISerYang/archive/2012/05/09/2491996.html