自编码器python实现
自编码器
自编码器是一种非常通用的神经网络工具。主要思想是通过一个编码器,将原始信息编码为一组向量,然后通过一个解码器,将向量解码为原始数据。通过衡量输入与输出的差别,来对网络参数进行训练。主要可以用来进行信息压缩、降噪、添加噪声等工作。
最进在了解GAN方向的应用,发现很多GANs类似与自编码器的思想,在条件GAN中,生成器类似于自编码器中的解码器。都是通过给定一组输入,来得到相应的图片。我比较好奇自编码器产生的编码信息,想知道在手动修改编码信息后,解码出来的图像会是什么样子。
于是以利用卷积神经网络构建了一个简单的自编码器。
import tensorflow as tf
import keras
import numpy as np
from keras.datasets import mnist
from keras.preprocessing import sequence
from keras.models import Sequential, Model
from keras.layers import Dense, Embedding, Reshape
from keras.layers import GRU, Input, Lambda
from keras.layers import Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, UpSampling2D
from keras.callbacks import TensorBoard, CSVLogger, EarlyStopping
from keras import backend as K
from PIL import Image
batch_size = 128
num_classes = 10
epochs = 12
img_rows, img_cols = 28, 28
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
input_img = Input(shape=(28, 28, 1))
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(inputs=input_img, outputs=decoded)
autoencoder.compile(optimizer='adagrad', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256,
shuffle=True, validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='autoencoder')])
decoded_imgs = autoencoder.predict(x_test)
在50个epoch后,网络的loss在0.11左右,已经能很好的编码mnist图像了。
Epoch 50/50
60000/60000 [==============================] - 5s 76us/step - loss: 0.1123 - val_loss: 0.1112
可以看出原始图像和编码-解码后的图像差别不大,只是编码-解码的图像会稍微有点糊:
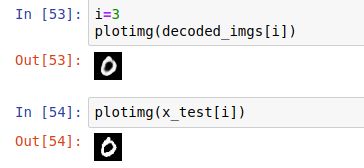
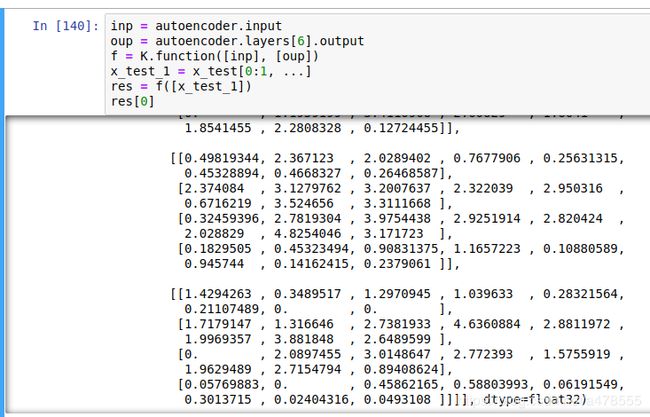
通过手动获取内部的输入输出,我们能得到编码后的向量:
通过修改编码向量的值,再经过解码器解码,可以得到不同的图片结果。
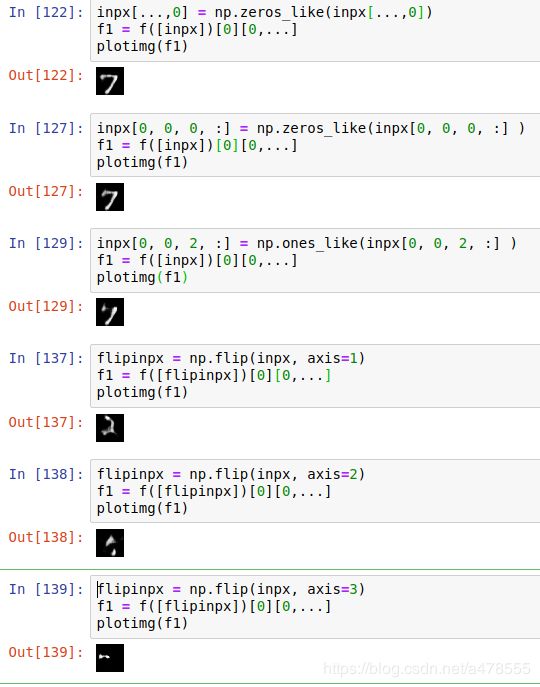
有时候会让图片更清晰(锐化),但一般修改后的编码向量都会时图像变的无意义。