muduo网络库——Buffer类的设计与使用
muduo Buffer设计要点:
1.一块连续的内存(char *p, int len)。
2.size()可以自动增长,以适应不同大小的消息。
3.内部以std::vector
Buffer像一个queue,从末尾写入数据,从头部读出数据。
TcpConnection会有两个Buffer成员:input buffer, output buffer
1.input buffer, TcpConnection会从socket读取数据,然后写入input buffer (用Buffer::readFd()完成);客户代码从input buffer读取数据。
2.output buffer, 客户代码会把数据写入output buffer( 用TcpConnection::send()完成);TcpConnection从output buffer读取数据并写入socket。
Buffer的数据结构
Buffer的内部是一个std::vector

两个index把vector的内容分为三块:prependable, readable, writable。
各块大小:
prependable = readIndex
readable = writeIndex - readIndex
writable = size() - writeIndex
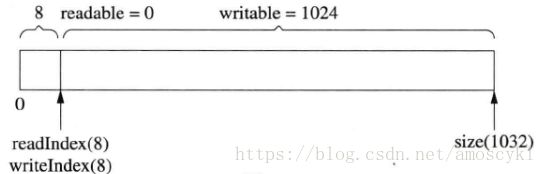
muduo Buffer 里有两个常数kCheapPrepend 和 kInitialSize,定义了prependable的初始大小和writable的初始大小,readable初始大小为0。初始化之后Buffer数据结构如图:

Buffer的操作
基本的read-write cycle
1.初始化之后向Buffer写入了200字节,那么布局如图:
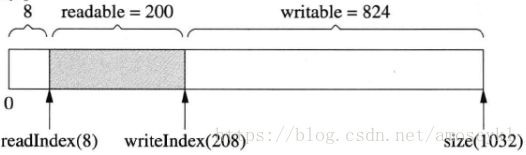
2.如果Buffer read() & retrieve() (读入) 了 50字节,结果如图:
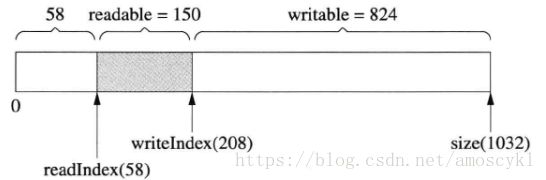
3.然后写入200字节,writeIndex向后移动200字节,如图:

4.接下来,一次性读入350字节,由于数据全部读完了,readIndex和writeIndex返回原位以备新一轮使用:
以上过程看作发送方发送了两条消息,长度分别为50和350字节,接收方分两次收到数据,每次200字节,然后进行分包。
自动增长
muduo Buffer不是固定长度的,可以自动增长。
此时写入1000字节,buffer自动增长以容纳全部数据。

由于vector重新分配了内存,原来指向其元素的指针会失效。readIndex返回到了前面。
size()与capacity()
使用vector的另一个好处是它的capacity()机制减少了内存分配的次数。
vector的capacity()以指数方式增长。
比如经过第一次增长,size()刚好满足写入的需求,如图:

但此时vector的capacity()已经大于size(),在接下来写入capacity()-size()字节的数据时,都不会重新分配内存。
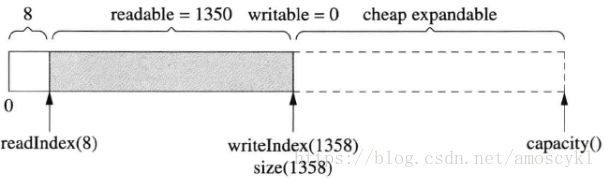
内部腾挪
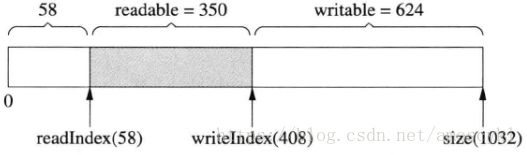
若经过多次读写,readIndex移到了比较靠后的位置,留下了巨大的prependable空间,如图:
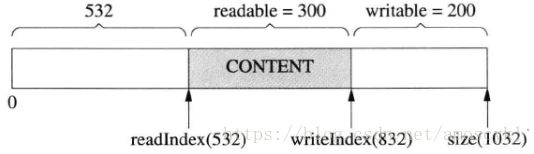
这时候想写入300字节,但writable只有200字节。muduo Buffer在这种情况下不会重新分配内存,而是把先有的数据移到前面去,腾出writable空间:
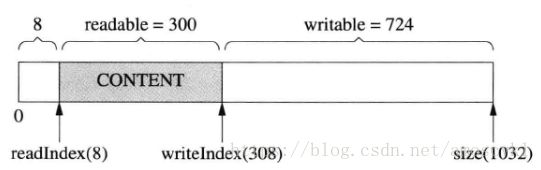
这样就就可以写入300字节了。
前方添加
提供prependable空间,让程序能以很低的代价在数据前面添加几个字节。
比如程序以固定的4个字节表示消息的长度,要序列化一个消息,但是不知道有多长,那么可以一直append()直到序列化完成(如图写入了200字节)。
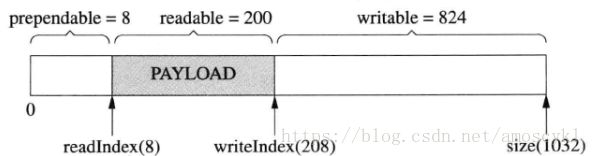
然后再在序列化数据的前面添加消息的长度(把200这个数prepend到首部):
