如何用区块链技术解决信任问题?Fabric 架构深度解读

阿里妹导读:区块链技术,随着比特币的兴起而为大家所知。但是具体到技术本身,大家相对熟悉的几个词可能是“数据不可篡改”、“公开链”、“分布式数据”、“共识机制”等。
这篇文章将抛砖引玉,通过深度解读Hyperledger Project旗下的Fabric,介绍区块链适合的应用场景,如何从技术上去解决实际业务中的问题,希望能和大家一起探讨、学习。
前言
Hyperledger Project 由Linux基金会创办于2015年10月,是一个开源的区块链研发孵化项目,致力于提供可协同开发以区块链为底层的分布式账本。旗下的Fabric项目目标为打造一个提供分布式账本解决方案的平台。
业务上所期望解决的问题——信用问题
首先从比特币说起,大家对比特币算力证明(POW)的名词应该不陌生,先不说其耗费大量的资源,从共识机制上来看,拥有超过50%的算力即可掌控整个比特币,无论从技术还是业务的角度都是一个风险极高的机制,但神奇的金融圈没有人会去触碰这样的底线,一旦有人拥有超过50%的算力,比特币可能就玩不下去了:)
那么实际的业务场景中的需求应该是怎样的呢?比如说,银行结算清算系统,传统的银行交易系统中,如果出现跨行交易,那么交易数据便需要一个清算系统进行定时对账确保双方的交易数据是同步无误的,那么就可能导致跨行转账需要T+1的时长,而主要的原因是因为双方的系统及数据相互独立,数据互不“信任”,所以需要一个清算系统去验证交易数据,而区块链可以说是为了解决这种“信任”问题而产生的技术,在双方进行交易的同时对数据进行了认证,那么便无需交易后再进行清算而达到实时转账等功能。下面来说为了解决“信用”问题,技术上需要哪些手段去满足。
技术上需要哪些特性去达到“数据可信任”
以上面提出的清算系统为例,可能有人提出,双方使用同一个分布式数据库不就可以达到实时的数据同步了嘛。确实,区块链其中一个特性便是分布式,但是和传统的分布式数据库区别在哪呢?在回归到业务中,如果双方银行进行交易的时候,使用这样一个分布式数据库,难道不担心对方偷偷地把数据改了吗?如果你说有日志可以追述得到修改记录,首先日志也是容易被修改的,且日志也无法挽回动不动可能就上百万千万甚至过亿的金额损失,所以说传统的分布式数据库对于企业之间来说是”不可信的“,那么便要求区块链需要达到数据不可篡改、用户有身份认证、交易可追述、交易有权重等一系列的特性。
剖析技术原理
上面说到区块链的各种特性,从功能上来说这些特性有些是相辅相成。那么应当如何去实现这些功能呢,接下来结合Fabric的一些具体实现来一一阐述。
存储数据结构
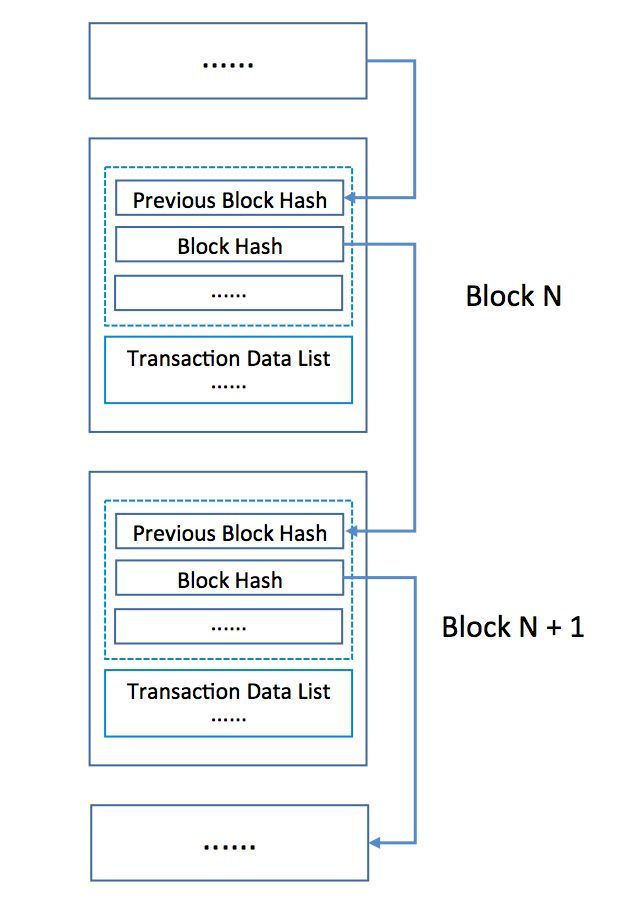
要达到数据不可篡改首先从数据结构上来看,也是区块链之所以称之为区块链的原因。如下图所示,每个存储单元包含上一存储单元的hash值(图中hash值的对应关系不完全精确,仅示意用)以及自身存储的交易数据块,可以从表象来看就像把所有数据块连接在一起,称之为“区块链”,形成链状可追述的交易记录。这种链状结构的数据称之为账本数据,保存着所有交易的记录,此外还有一个“世界状态”,其实质为Key-Value数据库,维护着交易数据的最终状态,便于查询等操作运算,并且每个数据都有其对应的版本号。
Fabric主要模块
总体来说,市面上各种区块链的实现方案都是基于这种数据结构,而仅靠数据结构并不能保证数据不可篡改,还有一个非常重要的因素,便是共识机制,一个好的共识机制才是保障整个业务运转的根本,相当于双方签订的合同或者协议,只有双方都遵守条约才能合作将业务展开进行。例如常见的POW,POS,PBFT等都属于共识机制,而其原理或者弊端这里不做赘述,主要来详细讲解Fabric应用的设计方案及其原理,此前先解释下一些特定名词的概念。
首先说”智能合约“的概念。在传统中心化的系统中,例如支付宝用户A给B转账100元,那么假设起始A有100元B有0元,那么在支付宝系统内调用转账的函数可能是这样的一个流程,调用transfer(A,B,100),而函数内可能会去读取用户A和B的账户余额,那么我们可以表达成input(A,B,100),read(A:100,B:0),write(A:0,B:100),那么这个仅是在支付宝的系统内执行了便完成了,那如何形成一个合约呢?
就如A、B在签订一份合同,双方都要对合同进行签名认可,在程序中就等于,用户A在其本地执行transfer(A,B,100)得出input(A,B,100),read(A:100,B:0),write(A:0,B:100)并对其签名认证,用户B在其本地执行transfer(A,B,100)得出input(A,B,100),read(A:100,B:0),write(A:0,B:100)并对其签名认证,然后双方将结果发给对方,然后判断对方结果是否一致并对其签名进行校验无误后便认为合约达成将结果写入本地。通俗来说就是将一段核心代码抽出来,所有参与方都去执行该代码并对其结果进行签名认证比对,便称之为执行智能合约,而其中共有的代码便是“合约"。
再说”背书策略“的概念。那么根据上面所言的共有代码在交易中是不是所有用户都要执行呢?比如说A、B用户转账,那么C、D用户显然就不需要规定其参与执行职能合约了,那么背书策略便是规定智能合约的结果需要哪些成员的签名背书才算交易成功。
在Fabric的交易流程中,主要有几个关键节点参与,包括Peer节点、Orderer节点、CA节点及client端。
Peer节点
该节点是参与交易的主体,可以说是代表每个参与到链上的成员,他负责储存完整的账本数据即区块链数据,负责共识环节中的执行智能合约,其中所有的Peer节点都维护完整的账本数据称之为Committer,而根据具体的业务划分背书策略时决定哪些Peer。
Orderer节点
该节点负责收集交易请求进行排序并打包生产新的区块,主体功能便是对交易排序从而保证各Peer节点上的数据一致性,也包含了ACL进行访问控制。
CA节点
该节点负责对加入链内的所有节点进行授权认证,包括上层的client端,每一个节点都有其颁发的证书用于交易流程中的身份识别。
client
Fabric对于client端提供了SDK让开发人员可以更容易地对接到区块链内的交易环节,交易的发起便是通过SDK进行。
供应链金融中的应用
以上简单的阐述了各模块的功能,当然实际当中包含更多服务支持的功能,那么这里在套进供应链金融来举例,更好地理解各节点的意义。
一个简单的供应链模型,一个核心企业向其供应商进行采购1000w物资,按照赊销合同在收到物资后半年进行结账,那么半年的账期供应商资金无法周转开便拿着核心企业开具的银行承兑汇票进行抵押融资,那么银行审核通过后将票据95%的金额马上转给了供应商,半年账期到后,核心企业便直接将货款转给银行,这样就形成了一次供应链的融资交易了。
在实际的业务当中大部分都是在线下进行操作的,耗费众多的人力及时间,那如何将这样的业务转成线上电子化呢?有人或许说银行提供这样的平台服务不就好了嘛,那假设这个平台不仅仅是这一家银行参与呢,若所有的银行或者企业都可以在同一个平台进行,那么交由某一个银行提供服务就显得不合适了。好,那么我们用Fabric来实现这样一个系统我们看看在部署上是怎样分布的呢。

上面是理想下的模型,当然在实际当中这样的部署方案也可能不成立,比如供应商并不一定有能力在其内部接入服务器等。我们仍然以此为例说明节点的意义,图中每个参与方都在本地部署Peer节点以及接入业务系统client端,那么每个Peer节点都保持了所有交易的数据,那么在查数据的时候仅在本地便可完成,当然也可以去查他人的Peer节点比对数据,而中心的CA节点负责给每一个节点包括client端颁发证书让其在交易流程中可以互相认证从而防止外部恶意接入查看数据或者参与交易,而Orderer节点与所有的Peer节点相连接获取交易结果进行排序控制,那么这里涉及到了整体的交易流程,引用官方的示例图来解释。
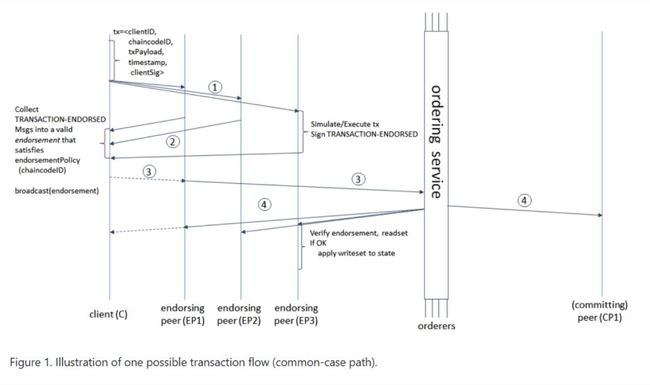
来描述一下上图的交易流程,首先由client发起一个交易请求,而上图中的背书策略要求Peer1、Peer2及Peer3参与交易,所以client将请求分别发给Peer1、Peer2和Peer3,然后三个Peer接收到交易请求后执行对应的智能合约并对结果进行签名然后分别将输出结果返回给client,client收到所有执行结果后打包一并发送到Orderer,Orderer将接收到的该次交易在交易池里进行排序并组合打包生成一个新的区块,Orderer将新的区块发送给所有的Peer节点,每个Peer节点接收到新区块后,对其中的每一笔交易结果的签名进行验证是否符合背书策略,以及比对读写集合(Read-Write Set,在下面的章节中解释)与本地的版本是否相同,如满足所有条件则将新的区块写入本地账本内完成交易。
以上是相对粗略的描述了交易流程,而实际当中还有很多细节的处理。除此外可能有人会问,共识节点去哪了?为什么有Orderer这样的中心节点?如果再细细思考一下,你会发现共识机制已经融合在整个交易流程中了,这也是这个设计优越的所在,我们来分析一下,假设Orderer节点是恶意节点,是否能控制交易生成”假账“呢?那么再来看一下Orderer的功能,接收交易数据进行排序并打包成块,假设Orderer要造假数据,那么他需要绕过的是每个Peer节点将数据写入前进行的背书策略的校验,那么数据里就必须包含背书策略里要求的节点签名,而Orderer是没有办法获取到各Peer节点的私钥也就没办法生成对应的签名,由此Orderer是没办法控制交易链造假的,可以说Orderer是一个工具服务并不参与到任何业务流程内,其关心的只是服务的稳定性,如果需要数据对Orderer节点保密,目前需要自行实现数据加密。正因为其背书策略的设定,可以精确地满足的具体的业务场景需求不会受到任何形式的恶意节点入侵,这也是区别于POW或者拜占庭容错等,他们在一定条件后是可能被恶意节点所操控的。
核心基础服务
对Fabric的主体模块及流程有一定认识后,我们在继续深究里面的细节功能,为了让整个框架能运作起来当然需要用到更多的技术手段,这里主要讲几个相对核心的功能点。
Gossip Protocol
回顾上述的交易流程图中,Orderer将交易数据排序打包后分发给各个Peer节点,若假设有成百上千甚至更多的Peer节点都由Orderer节点进行分发那么首先单点的压力是否能承受,其次如果出现失败的情况又该如何同步等问题。在Fabric的实现当中,采用的是让Peer节点之间相互同步而非Orderer节点来分发消息,每个Peer节点都会维护其他Peer节点的信息,随机的与部分其他Peer节点进行通信互换区块信息,传输时利用Peer-to-Peer的技术去加快数据的传输,而Orderer节点仅是将打包好的区块发送至特定的Leader Peer(可手动指定也可由Orderer自行选取),然后Peer节点之间在通过Gossip协议相互交换数据达到最终一致性。
Eventhub
那么根据上面描述的Gossip协议,可见每个Peer节点写入区块的时间可能是不一致的,那么client端进行业务逻辑判断(如事务逻辑)如何获知特定交易数据是否已经写入Peer节点内呢?实际上每个Peer都会和client端保持一个Eventhub的连接,在Peer节点完成交易后,如将区块写入账本后便会发送消息通知各个client,但是也要注意,回调总是不可信的,存在消息丢失的可能性,Fabric也并没有保证消息的最终到达。
Read-Write Set
在Peer节点将一个区块写入账本前,如上所述会进行背书策略的校验,以防止恶意节点的入侵,达到有权重划分,可实名制交易的联盟链。除去验证各节点签名验证,当然还要比对个节点输出的结果是否一致,那如何去衡量结果是否一致呢?这里提出了读写集合的概念,一段程序我们化做为IO,如果使用相同Input得出一致的Output,那么我们便可以认同在这一特定情况下函数性质是相同的。在这里我们并不关心Input,只要写入/修改的数据一致便可认为达成了共识,所以Write Set是用于保存最终需要写入/修改的数据集,这个是用来比对各节点的结果集是否一致,而Read Set中存着各节点执行合约中读取了哪些数据,并会把这个数据的当前版本记录在Read Set中,在Peer节点写入区块前也会校验Read Set中读取的数据版本是否和当前数据环境中的版本一致,以防止交易并发带来的错乱。
认证体系
刚接触区块链的同学可能会有一个概念,区块链应该保证公平公正公开,所以形成了“公有链”的一个概念,例如比特币,全员可参与,对所有人透明。但是区块链并不仅局限于“公有链”,对于大多数业务场景来说,应该属于“联盟链”,即由特定成员参与、有权重分配的业务,例如银行间的对账环节,A、B、C银行互相的交易中,A、B银行间的交易当然不愿意透露给C银行,而A、B、C银行的所有交易或许都要上报给央行,可见此处“公有链”是不可取的。那如何去保证公平公正公开呢?首先代码必须对成员开源,所有服务可由自身搭建,利益相关成员共同审核“智能合约”,全员共识的背书策略,相互授权或由可信第三方认证中心授权。那么最基础的一道认证体系便显得尤为重要了,我们在来看看Fabric是如何去实现他的认证体系的。
首先有几个概念需要明确,Fabric的CA认证中心是基于PKI体系打造的,相关资料可参考如下。
PKI(Public Key Infrastructure)
X.509 证书
Membership Service Providers(MSP)
在划分成员结构的时候Fabric用MSP来定义一个成员,在最佳实例推荐中,一个企业或者机构可以是一个单独的MSP,例如上述说到的供应链的案例,由例图来说明,核心企业便是一个MSP,银行和供应商各代表一个MSP,那么在一个MSP下可以有多个Peer节点,而不同的授权便有不同的功能,MSP具体应用场景主要如下。
在部署智能合约或者初始化时需要拥有对应CA赋权的证书才可执行(默认为PeerAdmin用户)。
为新节点或用户注册证书时,需要CA对该操作证书赋予权限(一般为Admin用户)。
在背书策略中可通过MSP来代表背书成员,可设定单个Peer节点代表其MSP达成协议(也可以要求全部Peer节点通过才达成协议)。
在跨MSP间的Peer节点通信,先通过各MSP内指定的Anchor Peer收集MSP内的Peer列表,然后通过各MSP下的Anchor Peer交互其Peer列表,将其他MSP下的Peer列表同步到内部Peer后,便通过Gossip协议Peer节点间随机通信。
每个MSP都有自己独立的CA节点,为其提供所有的证书需求,各MSP共享其CA节点的ROOT证书达到互相认证。
匿名交易。在一笔交易中,包含着每一个参与背书的用户证书,这可以认为是公开实名制的交易,所有链内成员都可以看见每一笔交易是由谁参与的,但是如果我们希望匿名交易该如何实现呢?在Fabric 0.6版本内有Ecert和Tcert的概念,Ecert即为用户的证书,而Tcert则是用于匿名交易,用户可以通过向CA申请一批Tcert用于交易,而该Tcert不包含用户的信息,当需要验证查验信息时可通过CA来认证该用户的身份。(此功能在1.0版本尚未实现)
Revoke,废除证书。在PKI体系中,其最大的优势便是Off line的,即在证书颁发后,不需要CA节点的存在也可以在本地进行认证,而遇到很大的问题是类似于废除证书时如果希望能即是将废除证书的消息通知到各个节点,目前的做法是需要CA节点保持在线并与各节点保持通信。(获取Tcert也需要CA节点在线)
在每个区块链中其相关的配置信息也包含了MSP的划分,阐述相对复杂这里便不描述,有兴趣可以参考官方文档 :)
难点及待解决的问题
上述篇幅主要是给读者对Fabric的整体框架有基本的认识,仍有许多细微的问题无法一一讨论。当然,在区块链尚未大规模能应用于市场下其技术也是不完善的,在Fabric中也有许多需要解决的难点问题。
在官方推荐的实践当中,划分数据的隔离是通过账本的粒度进行隔离,不关联的交易便在不同的账本中了,但是实际业务当中,总有需要在单账本内进行数据隔离的场景,早前已经看到有相关的设计文档出稿了,不过距离正式发布该功能就不确定合适能完成了,目前只能自行在业务逻辑中对数据进行加密隔离。
当两个数据通过账本隔离后需要交互的场景目前来看是比较难实现的,及跨账本调用,首要解决的问题便是认证模型如何去进行融合。
目前想要接入区块链的成本仍然是很高的,即便Fabric项目大部分功能都无法通过可视化的配置,需要了解更多的底层细节才能正确搭建环境及配置。
引用
https://hyperledger-fabric.readthedocs.io/en/release/
https://github.com/hyperledger/fabric
https://www.ibm.com/blockchain/hyperledger.html

你可能还喜欢
点击下方图片即可阅读

如何快速成长为技术大牛?

当数据库遇见FPGA:
X-DB异构计算如何实现百万级TPS?

阿里新突破!
自主创新的下一代匹配&推荐技术

关注「阿里技术」
把握前沿技术脉搏