【0】环境需求
Windows server 2016 任意版本
Sql server 2012及以上,建议 sql server 2016及以上
【0.1】我的环境准备
OS:windows server 2016 datacenter 数据中心
Software: Sql Server 2016 原生版,SSMS18.5
机器名 IP地址 角色
DB2 192.168.175.132 节点
DB3 192.168.175.133 节点
DB4 192.168.175.134 共享文件夹仲裁/新增节点
alwayson 192.168.175.135 故障转移集群VIP
侦听器 192.168.175.136 可用性组侦听器
| OS16 |
ed2k://|file|cn_windows_server_2016_x64_dvd_9327743.iso|6020876288|58F585A340248EF7603A48F832F08B6D|/ |
| SQL16 |
ed2k://|file|cn_sql_server_2016_enterprise_x64_dvd_8699450.iso|2452795392|D8AFD8D6245F518F53F720C48E2819C0|/ |
如果使用虚拟机:建议操作步骤如下
-
构造好第一台机器,安装好SQL SERVER,修改好DNS,修改好RDO远程连接,修改好防火墙1433/5022端口
-
克隆,修改SID
-
修改主机名,重启
-
修改sql server实例名,同步成主机名
【0.2】前置要求
1,只有Windows Server 2016 操作系统才能配置不依赖域的群集 ,3台服务器的操作系统,安全补丁,SQL Server版本要完全一致。
2,两个节点的Windos Server 2016 都必须以Administrator账户登录,并且两台服务器的Administrator密码相同,无特殊意义,只是为了方便后续的操作。
3,两个节点的SQL Server 2016 服务启动账户都设置成Administrator 。3个节点的数据库都有Administrator的登录名,也就是使用Administrator登录服务器时,可用Windows身份验证登录SQL Server。
即:
节点1的SQL Server上有:DB2\administrator ;节点2上有:DB3\administrator ;节点3上有:DB4\administrator ;
这3个登录账号,在安装SQL Server的时候可创建。均有sysadmin权限。
【1】前置杂项配置
【1.1】修改主机名/DNS后缀
(1)控制面板=》查看该计算机名
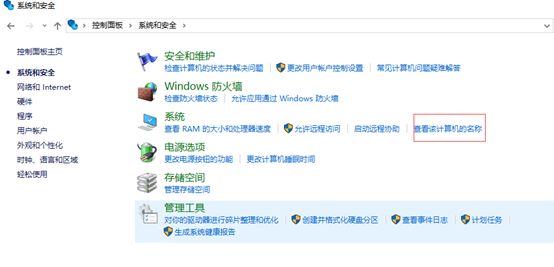
-
修改计算机名

(3)修改DNS后缀(两台机器都需要改成一样的)

【1.2】安装sql server2016
这个比较简单,掠过..
【2】安装故障转移群集(所有节点均使用administrator登录)
【2.1】安装故障转移群集功能(所有节点)
(1)服务器管理器=》添加角色和功能
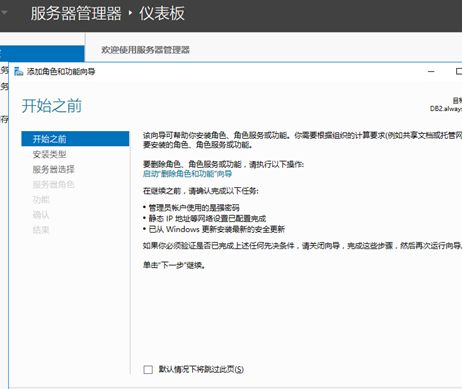
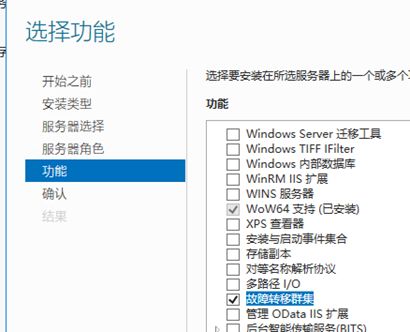
(2)添加故障转移群集功能
直接下一步下一步到功能界面,选择故障转移群集,建议把telnet客户端功能也安装上,后面方便做端口访问测试。
【2.2】配置hosts(所有节点)
文件路径: c:\windows\System32\drivers\etc
加上如下DNS内容
192.168.175.132 DB2.alwayson1.cn
192.168.175.133 DB3.alwayson1.cn
192.168.175.135 AlwaysOn_test
192.168.175.136 Listen_test
如下图:

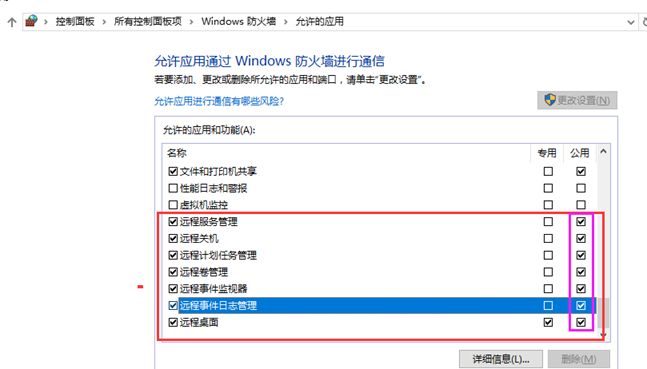
【2.3】防火墙设置(所有节点)
防火墙的话,我们把故障转移群集的 WMI程序允许通过防火墙
并且可以的话,把数据库端口及alwaysOn通信端口,1433,5022都打开
开启wmi
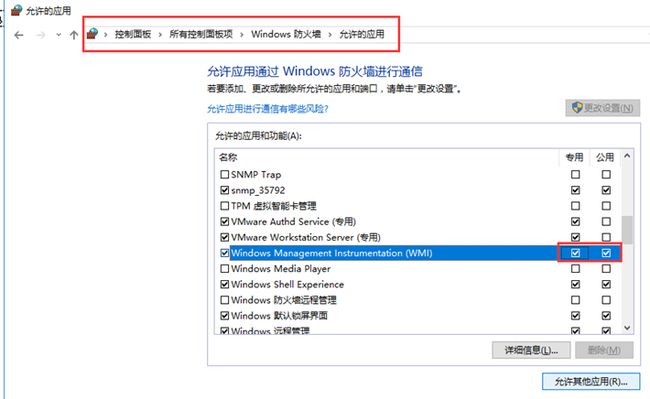
开启公用网络(也就是与其他机器通信)相关程序。
【2.4】使用powershell创建故障转移群集(DB2节点)
注意:如果登陆Windows Server 2016服务器的账户不是Administrator,需要先以管理员方式运行PowerShell,并执行下面的脚本:
new-itemproperty -path HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System -Name LocalAccountTokenFilterPolicy -Value 1
因为我们这里用的是管理员账户administrator 账户登录的。就直接运行下列代码了
右击=》运行=》powershell
--新建集群
New-Cluster -Name AlwaysOn_test –Node DB2,DB3 –StaticAddress 192.168.175.135 –administrativeAccessPoint DNS
--获取集群名
Get-Cluster
--群集详情
Get-ClusterResource
【2.5】使用故障集群管理器连接alwaysOn_test 集群
在服务器管理器界面中
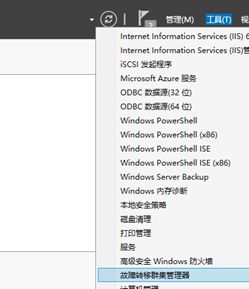
打开后,直接看是看不到的,需要手动连接
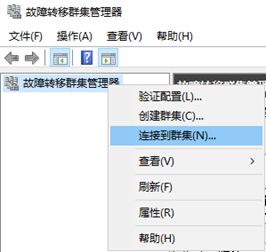

连接上后,可以查看节点信息是否有问题,我们可以看到脸上的群集上有一把叉,不用管那是因为有错误的群集事件发生。
如果可以,尽量解决群集事件中的错误信息;
【2.6】配置共享文件夹仲裁
【3】配置alwaysOn
【3.0】测试数据库创建
create database test
use test;
create table test1(
id int identity(1,1) primary key,
num1 int,
num2 int,
str1 varchar(100),
str2 varchar(200)
)
insert into test1(num1,num2,str1,str2) values(1,2,'a','b');
insert into test1(num1,num2,str1,str2) values(3,3,'aa','bb'),(4,4,'cc','dd');
--(2) select * into new_table from tablename
use test;
go
;with a as (
select 1 as id1 ,2 as id2
union all
select id1+1,id2+1 from a
where id1<=100
)
select * into test2 from a option(maxrecursion 0)
--(3) insert into exists_table select from tableName
select * into test3 from test1 where 1=2
insert into test3 select num1,num2,str1,str2 from test1;
【3.1】开启AlwaysOn功能(所有节点)
右击实例引擎服务=》属性=》找到alwaysOn高可用性选项卡=》勾上即可=》重启服务/启动服务
最好也把代理服务启动起来。

核验是否开启成功,HADR开启成功就意味着我们开启了alwaysOn功能选项了。
HADR是什么?就是High Availability Disaster Recovery 高可用性与灾难恢复

【3.2】创建共享文件夹(DB2节点)
用来存放证书互信,初始化文件等等,有其他方式能复制过去也行,可以省掉这一步。
右击文件夹,共享即可,我们这里都是用administrator登录的,所以把它加上。


测试一下DB3,是否可以访问这个UNC路径;
OK,很明显可以。这里我们共享文件夹就创建完成了;

【3.3】构建秘钥、证书、端口
既然节点没有加入域,那么就不能用域认证,只能用证书认证。
因此需要在每个节点的数据库中创建其他节点的数据库证书。(请留意我连接数据库的账户,在创建端口的代码中有用到)
因此,在配置可用性组之前,先在各个节点上配置证书互信。
--共享文件夹UNC路径:\\DB2\share_file 或者 \\192.168.175.132\share_file
两个机器需要先做(1)--(4)步骤,然后再做第(5)步
| DB2 |
DB3/DB4,DB4对应修改一下成DB4即可 |
| Use master; Go --(1)创建主秘钥 Create master key encryption by password='alwaysOn_test2016'; Go
--(2)创建证书,用来给其他DB入站 Create certificate DB2_cert With subject='create DB2_cert for database alwaysOn', Start_date='2020-06-24',expiry_date='2099-12-31'; Go
--(3)创建端点 CREATE ENDPOINT [SQLAG_Endpoint] --AUTHORIZATION [DB2\administrator] ----此账户是连接数据库的账户 STATE=STARTED AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL) ---侦听端口,1024 和 32767 之间的任何数字都有效。侦听IP地址,默认值为 ALL,表示侦听器将接受任何有效 IP 地址上的连接 FOR DATA_MIRRORING (ROLE = ALL,AUTHENTICATION = CERTIFICATE DB2_CERT, ENCRYPTION = REQUIRED ALGORITHM AES) GO
--(4)备份证书 Backup certificate DB2_CERT to file='\\DB2\share_file\DB2_CERT.cer'
--等所有节点执行完(1)-(4)步骤之后再做(5) --(5)DB2上执行:创建其他节点的证书 USE master; GO CREATE CERTIFICATE DB3_CERT FROM FILE = '\\DB2\share_file\DB3_CERT.cer'; CREATE CERTIFICATE DB4_CERT FROM FILE = '\\DB2\share_file\DB4_CERT.cer'; GO
|
Use master; Go --(1)创建主秘钥 Create master key encryption by password='alwaysOn_test2016'; Go
--(2)创建证书,用来给其他DB入站 Create certificate DB3_cert With subject='create DB3_cert for database alwaysOn', Start_date='2020-06-24',expiry_date='2099-12-31'; Go
--(3)创建端点 CREATE ENDPOINT [SQLAG_Endpoint] --AUTHORIZATION [DB3\administrator] ----此账户是连接数据库的账户 STATE=STARTED AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL) ---侦听端口,1024 和 32767 之间的任何数字都有效。侦听IP地址,默认值为 ALL,表示侦听器将接受任何有效 IP 地址上的连接 FOR DATA_MIRRORING (ROLE = ALL,AUTHENTICATION = CERTIFICATE DB3_CERT, ENCRYPTION = REQUIRED ALGORITHM AES) GO
--(4)备份证书 Backup certificate DB3_CERT to file='\\DB2\share_file\DB3_CERT.cer'
--等所有节点执行完(1)-(4)步骤之后再做(5) --(5)DB3上执行:创建其他节点的证书 USE master; GO CREATE CERTIFICATE DB2_CERT FROM FILE = '\\DB2\share_file\DB2_CERT.cer'; CREATE CERTIFICATE DB2_CERT FROM FILE = '\\DB2\share_file\DB4_CERT.cer';
GO |
【3.4】配置可用性组(DB2节点)
其实任一节点都可以,这里我们用db2节点吧。
(1)新建可用性组

(2)设置可用性组名称
这里我们可以勾上数据库级别运行状况监测,DTC(分布式事务)支持

(3)选择加入可用性组的数据库
我这里已经有了,我就选test了。
如果没有测试库的,需要
-
创建数据库,设置成完整恢复模式,或者把现有的数据库设置成完整恢复模式
-
全备1次,如果全备1次还不行,那么再至少备份一次事务日志
然后再来这个界面

(4)选择数据同步
《1》副本
默认是只有我们本机实例的,我们点击添加副本把DB3添加上来
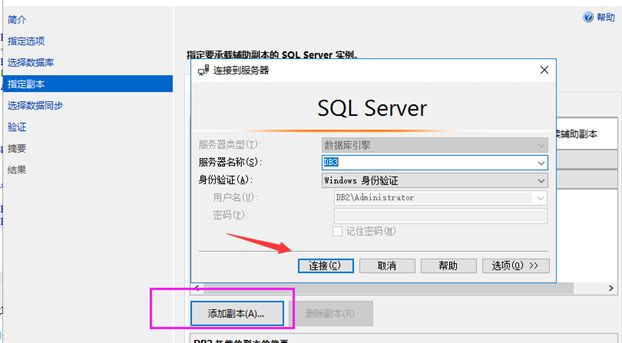
并且啊,勾上自动故障转移,可读辅助副本要勾上,不然不能读。
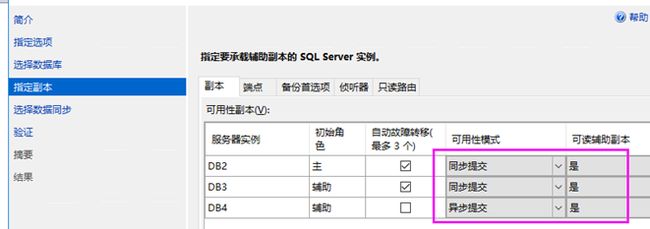
《2》端点
端点配置:端点填写刚才创建的端点名,如下图。填写后, "端口号"+"端点名称"+"对数据进行加密" 则变为不可更改

《3》备份首选项

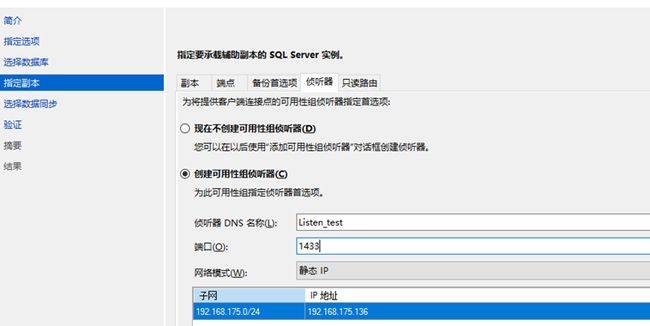
《4》创建侦听器
我们直接在这里建了算了吧,没必要到外面还要手动搞一次。
这个名称和IP一定要配置成【2.2】中我们host中事先规划好的名称和IP。
这个端口就是sql server远程连接的端口,这里我没有修改就用默认的1433端口吧。
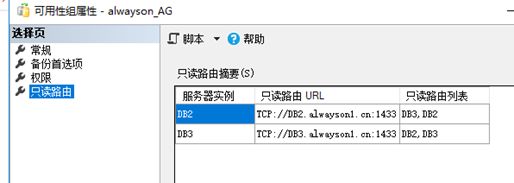
《5》只读路由配置
什么是只读路由啊?就是如果连接串开启ApplicationIntent=ReadOnly 过来访问URL的时候(一般这个是访问侦听器,侦听器转发访问URL)。
以轮询的方式访问只读路由列表,比如第1次 select 访问DB2,第2次select 访问DB3;
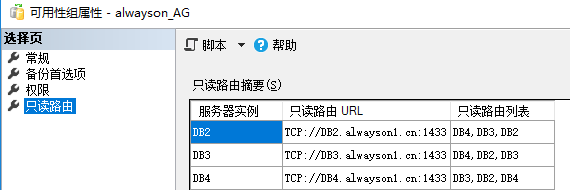
为了读写分离吧,这里我们就只读路由就只设置对方吧,这样DB2为主的时候会先DB4=>DB3=>DB2轮询
反之DB3为主的时候,会DB4=>DB2=>DB3轮询 以此类推
TCP://DB4.alwayson1.cn:1433 记住这个端口1433是我们sql server的TCP访问端口
【3.5】数据库初始化
在DB2主库上
Backup database test to disk='\\db2\share_file\test.bak' with init,format
Backup log test to disk='\\db2\share_file\test.trn' with init,format
在DB3/DB4从库上
restore database test from disk='\\db2\share_file\test.bak' with norecovery
restore database test from disk='\\db2\share_file\test.trn' with norecovery
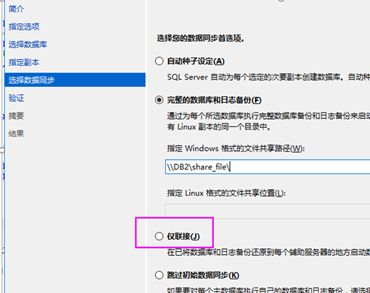
【3.6】选择数据库同步方式
这里我们选择仅连接
【3.7】生成脚本
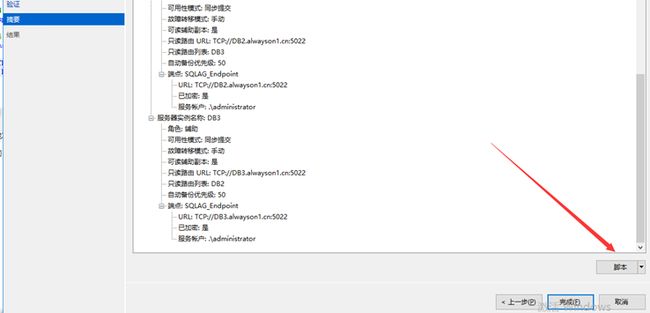
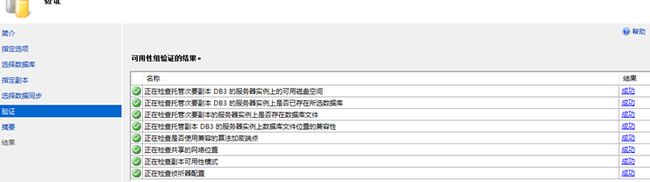
【3.8】完成,基本核验
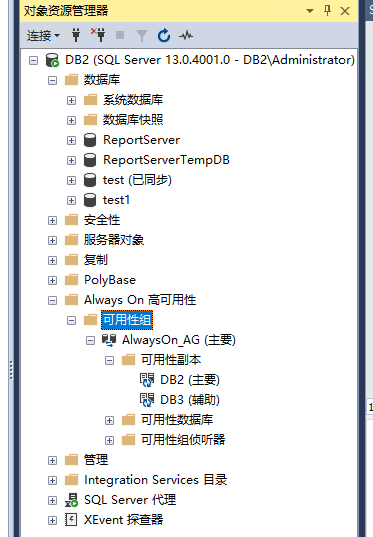
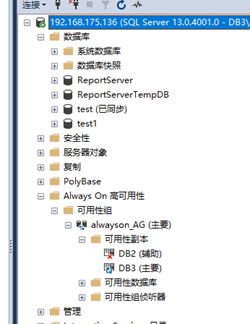
(1)SSMS数据库状态、可用性组状态查看
看左图:在DB2上查看可用性组与数据库状态,发现都有了,但看图标就知道正在同步。
看右图:连接侦听器,发现也OK了。

(2)面板查看

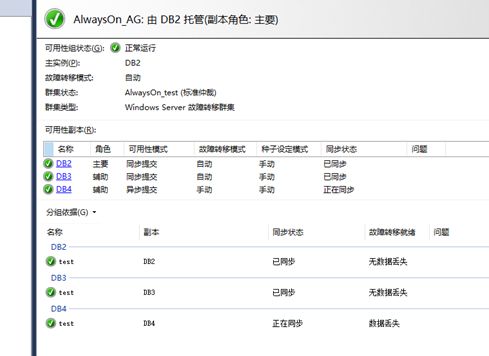
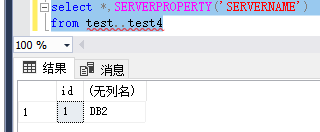
(3)数据插入测试
在主库上运行 select 1 as id into test..test4
结果如下:同步成功


【3.9】把主库账户同步到其他辅助副本(避免孤立用户)
1.创建SID相同的登录名
2.切换后更新用户的login
3.包含用户(将用户存储在DB里,而不是master里)
对已有系统,1的选择居多
使用办法(1)比较多,在构建好always on系统后,就务必要进行这一步操作。
使用下列脚本获取主库的登录名信息及sid,再从库运行即可。
![]()
--导出登录脚本 注:可用于 alwayson 辅助副本同步密码或者服务器迁移。
SELECT 'CREATE LOGIN [' + p.name + '] '
+ CASE WHEN p.type IN ( 'U', 'G' ) THEN 'FROM windows '
ELSE ''
END + 'WITH ' + CASE WHEN p.type = 'S'
THEN 'password = '
+ master.sys.fn_varbintohexstr(l.password_hash)
+ ' hashed, ' + 'sid = '
+ master.sys.fn_varbintohexstr(l.sid)
+ ', check_expiration = '
+ CASE WHEN l.is_expiration_checked > 0
THEN 'ON, '
ELSE 'OFF, '
END + 'check_policy = '
+ CASE WHEN l.is_policy_checked > 0
THEN 'ON, '
ELSE 'OFF, '
END
+ CASE WHEN l.credential_id > 0
THEN 'credential = ' + c.name
+ ', '
ELSE ''
END
ELSE ''
END + 'default_database = '
+ p.default_database_name
+ CASE WHEN LEN(p.default_language_name) > 0
THEN ', default_language = ' + p.default_language_name
ELSE ''
END
FROM sys.server_principals p
LEFT JOIN sys.sql_logins l
ON p.principal_id = l.principal_id
LEFT JOIN sys.credentials c
ON l.credential_id = c.credential_id
WHERE p.type IN ( 'S', 'U', 'G' )
AND p.name NOT IN ( 'sa')
AND p.name NOT LIKE '%##%'
AND p.name NOT LIKE '%NT SERVICE%'
AND p.name NOT LIKE '%NT AUTHORITY%'
【3.10】修改故障转移集群频率
在测试期间由于故障转移时间间隔次数限制,可能会导致故障节点上线之后无法自动恢复。所以我们需要修改频率(应用自【故障13】)
右击故障转移群集式立体,属性,然后再常规选项卡中点击管理核心群集资源组。找到故障转移选项卡,兵设置为运行故障回复。

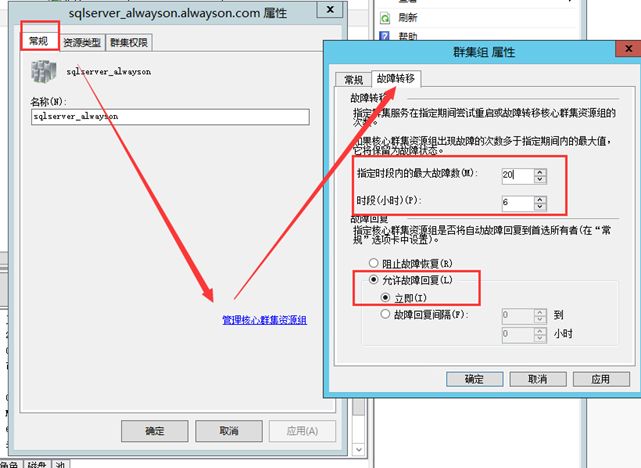
还有,侦听器也要这样设计
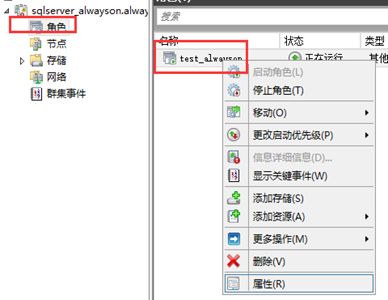

【4】相关测试
【4.1】故障转移测试
强行停止主库引擎,服务模拟宕机,停掉了引擎服务
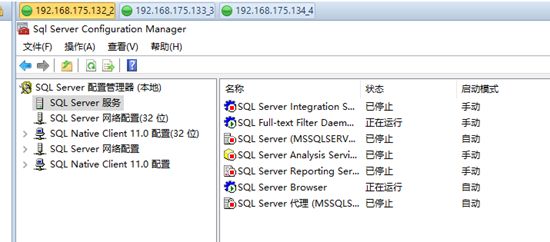
如下图,连过来已经是DB3了,完成了自动故障转移
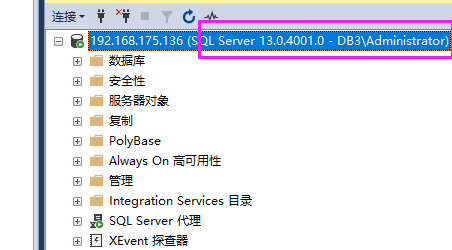
但是我们可以看到,DB4变成了未同步

select * from sys.certificates –证书
select * from sys.tcp_endpoints –tcp端口
select * from sys.database_mirroring_endpoints
通过排查,是在DB3上少了DB4的证书,所以DB4无法连接访问到DB3。
但DB2是完整的,所以当DB2为主副本的时候集群看起来没有任何问题
原DB2,重新启动服务后,自动加入可用性组变成了已同步状态。
手动故障转移的话,右击可用性组就可以了。
或者登录上预备做新主库的机器。
ALTER AVAILABILITY GROUP [alwayson_AG] FAILOVER;
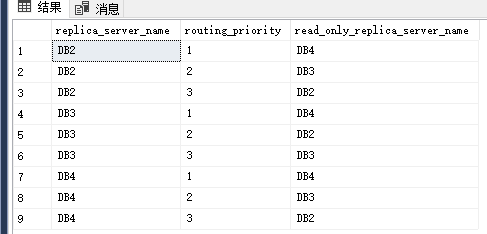
【4.2】只读路由测试
查看只读路由
SELECT ar.replica_server_name ,
rl.routing_priority ,
(
SELECT ar2.replica_server_name
FROM sys.availability_read_only_routing_lists rl2
JOIN sys.availability_replicas AS ar2 ON rl2.read_only_replica_id = ar2.replica_id
WHERE rl.replica_id = rl2.replica_id
AND rl.routing_priority = rl2.routing_priority
AND rl.read_only_replica_id = rl2.read_only_replica_id
) AS 'read_only_replica_server_name'
FROM sys.availability_read_only_routing_lists rl
JOIN sys.availability_replicas AS ar ON rl.replica_id = ar.replica_id
(1)使用sqlcmd测试吧。
Sqlcmd –U sa –P a123456! –S 192.168.175.136 –K readonly –d test –Q"select @@servername;"
(2)使用ssms测试
1》一定要选择连接到数据库设置指定的我们的可用组中的数据库

配置连接参数 applicationIntent=readonly

连接成功,我们看看,主机名果然是DB4了
我们设置的规则是 DB2为主副本时,只读连接的访问顺序为 DB4=>DB3=>DB2,最先访问DB4,只有当DB4挂掉之后才会到DB3

只有当DB4挂掉之后才会到DB3,我们测试一下把DB4引擎服务关掉。
如下图,不需要重新登录,直接默认的查询就分发到DB3去了,因为DB4挂了。

我们再把DB4启动,看看会不会切换回来,如下图,居然过了一会儿之后真的切换回来了。(但是现有查询窗口不会切回来,新窗口会)
【4.3】读负载均衡配置
参考:https://www.cnblogs.com/gered/p/12773587.html
Sql server2016开始支持读负载均衡,但是图形界面好像配置不了,默认配置是只读路由,下面我们配置只读路由+读负载均衡
--更新只读路由URL(这里没有改变)
USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB2.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB3.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB4.alwayson1.cn:1433'))
GO
--其实就下面修改一下,只读路由里把多个只读路由列表合成了一个整体。
--比如 ((N'DB4',N'DB3'),N'DB2'))) ,就是把 DB4和DB3合成了一个路由整体,然后在这个整体里做
USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = ((N'DB3',N'DB2'),N'DB4')))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = ((N'DB4',N'DB2'),N'DB3')))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = ((N'DB4',N'DB3'),N'DB2')))
GO
然后再查看这个只读路由信息,就可以看到变化了。可

测试:用SSMS readonly+默认test数据库连接
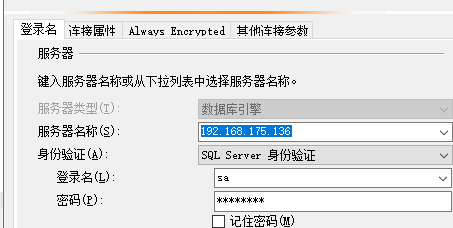


SSMS连接效果:
左边是第一次连接,断开之后,右边是第二次连接,果然新连接已经到DB4了;


测试:使用sqlcmd测试
Sqlcmd –U sa –P a123456! –S 192.168.175.136 –K readonly –d test –Q"select @@servername;"
如下图:可以看到不同的连接会轮询依次访问DB3/DB4
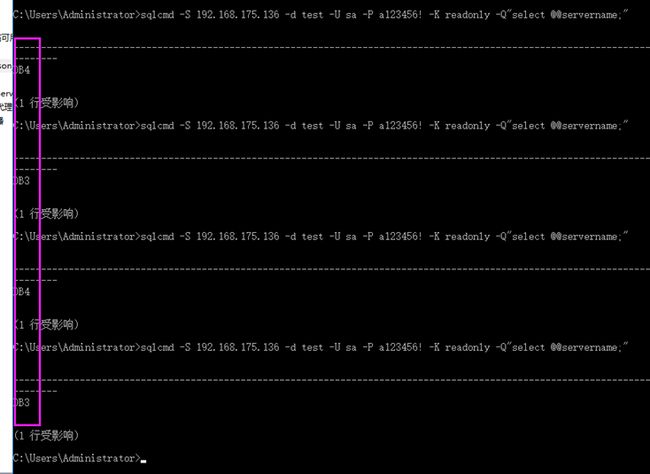
把DB4停了会怎么样?
如下图,我们发现它只会访问DB3了;不会导致整个(DB3/DB4)整体脱机;

测试:T-SQL测试
使用ssm 连接192.168.175.136 默认test库,applicationIntent=readonly
开了4个窗口,运行如下查询(DB2为主库,DB3/DB4为DB2的读负载均衡库)
declare @i int=1
while @i<=10
begin
select count(*),@@servername from test1;
set @i=@i+1;
waitfor delay '00:00:03'
end
结果:(我也只是成功了1-2次会把查询分发到DB4构成读负载均衡,但却失败了3-5次查询只运行在DB3上)
最终思考,算法应该不是轮询,应该是类似于根据负载大小分发查询的算法。因为每次重新切换到新库也是需要代价的
窗口1: 窗口2:
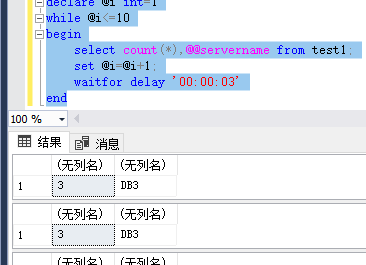
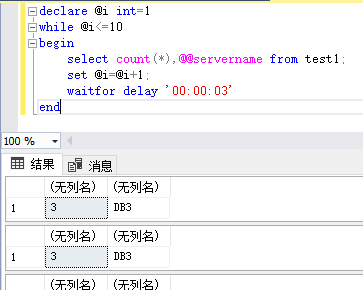
窗口3: 窗口4:

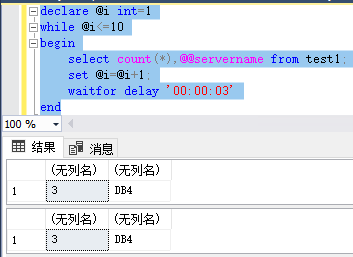
如上图,我们可以看出,在大批量查询的时候,即使没有切换当前连接,在DB3负载高一点的时候也会读负载均衡,把相关请求分发到DB4去。
但对于这个已经连接到DB3的readonly连接,绝大部分甚至是全部操作都是在DB3上(连接所在机器)的。
总结:
(1)读写分离:
使用applicationIntent=readwrite ,applicationIntent=readwrite,算是达到了半读写分离,因为还是2个不同的连接串
达到了我们读写分离,读负载均衡
【4.4】客户端连接alwaysOn
.net连接主副本:Server=tcp: AGListener,1433;Database=MyDB;Integrated Security=SSPI
.net连接辅助副本:Server=tcp:AGListener;Database=AdventureWorks;Integrated Security=SSPI;ApplicationIntent=ReadOnly
【5】使用T-SQL监控
参考:https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/monitor-availability-groups-transact-sql?view=sql-server-2016
【5.1】ServerProperty
Select ServerProperty('HadrManagerStatus') as '可用性组管理器(0挂起,1启动,2失败)'
Select ServerProperty('IsHadrEnabled') as 'AlwaysOn可用性组功能(0 禁用,1启用,null无效或出错)'
【5.2】监视WSFC群集
sys.dm_hadr_cluster --查看故障转移群集的群集名称和仲裁信息
sys.dm_hadr_cluster_members -- 查看当前节点所在故障转移群集的所有成员
sys.dm_hadr_cluster_networks -- 查看当前节点所在故障转移群集的所有成员所在网段
sys.dm_hadr_instance_node_map -- 查看故障转移群集节点与sql server实例的映射(解决多实例对应问题)
sys.dm_hadr_name_id_map – 显示alwayson可用性组的映射
【5.3】监视可用性组
sys.availability_groups –-为 SQL Server 的本地实例承载其可用性副本的每个可用性组返回一行。 每一行都包含可用性组元数据的缓存的副本。
重要的包含:failure_condition_level 故障转移级别,health_check_timeout 监控检查超时默认30S。建议使用这个
sys.availability_groups_cluster -- 为 WSFC 群集中的每个可用性组返回一行。
每一行均包含 Windows Server 故障转移群集 (WSFC) 群集中的可用性组元数据。和上面那个区别不大
sys.dm_hadr_availability_group_states
为在 SQL Server的本地实例上拥有可用性副本的每个可用性组返回一行。 每行显示定义给定可用性组的运行状况的状态。
【5.4】监视可用性副本状态/复制状态/只读路由
sys.availability_replicas
为 SQL Server 的本地实例承载其可用性副本的每个可用性组中的每个可用性副本返回一行。
sys.availability_read_only_routing_lists
为 WSFC 故障转移群集中 AlwaysOn 可用性组的每个可用性副本的只读路由列表返回一行。
sys.dm_hadr_availability_replica_cluster_nodes
为 Windows Server 故障转移群集 (WSFC) 群集中 AlwaysOn 可用性组的每个可用性副本(不论联接状态如何)都返回一行。
sys.dm_hadr_availability_replica_cluster_states
为 Windows Server 故障转移群集 (WSFC) 群集中所有 AlwaysOn 可用性组(不论副本位于何处)的每个副本(不论联接状态如何)都返回一行。
sys.dm_hadr_availability_replica_states
返回一行以显示每个本地可用性副本的状态,并为同一可用性组中的每个远程可用性副本返回一行。
sys.fn_hadr_backup_is_preferred_replica
确定当前副本是否为首选备份副本
【5.5】监视可用性数据库
sys.dm_hadr_database_replica_cluster_states
显示实例所在故障转移群集中,可用性副本的实例上的每个可用性数据库
sys.dm_hadr_auto_page_repair
为针对任何可用性数据库(位于服务器实例为任何可用性组承载的可用性副本上)的每一个自动页修复尝试都返回一行。 该视图包含对应于给定主/辅助数据库上最新自动页修复尝试的行,每个数据库最多可对应 100 行。 只要一个数据库对应的行达到最大值,则它的下个自动页修复尝试对应的行将替换现有的一个项。
sys.dm_hadr_database_replica_states
为参与任何可用性组( SQL Server 的本地实例正承载其可用性副本)的每个数据库返回一行。
sys.availability_databases_cluster
返回一行信息,这些信息旨在让您洞察 WSFC 故障转移群集 (WSFC) 群集上每个可用性组中的可用性数据库的运行状况。 此动态管理视图适用于以下情况:计划或响应某一故障转移,或发现可用性组中的哪一个辅助副本正在阻止给定主数据库上的日志截断。
【5.6】监视侦听器
sys.availability_group_listener_ip_addresses
针对可用性组侦听器,为当前联机的每个符合标准的虚拟 IP 地址返回一行。
sys.availability_group_listeners
对于给定的可用性组,返回零行(指示没有与该可用性组关联的网络名称),或为 WSFC 群集中的每个可用性组侦听器配置返回一行。
sys.dm_tcp_listener_states
返回包含各个 TCP 侦听器的动态信息的行
【6】常用维护
(1)查看可用性组同步情况
use test;
go
SELECT availability_mode_desc ,
role_desc ,
replica_server_name ,
last_redone_time ,
GETDATE() now ,
DATEDIFF(ms, last_redone_time, GETDATE()) last_now_diffMS
FROM ( ( sys.availability_groups AS ag
JOIN sys.availability_replicas AS ar ON ag.group_id = ar.group_id
)
JOIN sys.dm_hadr_availability_replica_states AS ar_state ON ar.replica_id = ar_state.replica_id
)
JOIN sys.dm_hadr_database_replica_states dr_state ON ag.group_id = dr_state.group_id
AND dr_state.replica_id = ar_state.replica_id;

(2)查看节点监控情况
SELECT CND.*, RST.is_local, RST.role_desc, RST.operational_state_desc,
RST.connected_state_desc, RST.synchronization_health_desc
FROM sys.dm_hadr_availability_replica_cluster_nodes CND
JOIN sys.dm_hadr_availability_replica_cluster_states CST
ON CND.replica_server_name=CST.replica_server_name
JOIN sys.dm_hadr_availability_replica_states RST
ON CST.replica_id=RST.replica_id
【6.2】如何备份?
本章节引用自:https://www.cnblogs.com/chenmh/p/6971992.html
Always On 可用性组活动辅助功能包括支持在辅助副本上执行备份操作。 备份操作可能会给 I/O 和 CPU 带来很大的压力(使用备份压缩)。 将备份负荷转移到已同步或正在同步的辅助副本后,您可以使用承载第一层工作负荷的主副本的服务器实例上的资源,您可以创建主数据库的任何类型的备份。 也可以创建辅助数据库的日志备份和仅复制完整备份。
(0)概念
1.辅助副本上支持的备份类型
BACKUP DATABASE :在辅助副仅支持数据库、文件或文件组的仅复制完整备份。 请注意,仅复制备份不影响日志链,也不清除差异位图。
辅助副本不支持差异备份。
BACKUP LOG 仅支持常规日志备份(辅助副本上的日志备份不支持 COPY_ONLY 选项)。
若要备份辅助数据库,辅助副本必须能够与主副本进行通信,并且状态必须为 SYNCHRONIZED 或 SYNCHRONIZING。
2.配置运行备份作业的位置
在辅助副本上执行备份以减轻主生产服务器的备份工作负荷非常有好处。 但是,对辅助副本执行备份会显著增加用于确定应在何处运行备份作业的过程的复杂性。 要解决这个问题,请按如下所示配置备份作业运行的位置:
配置可用性组以便指定要对其执行备份的可用性副本。
为承载作为执行备份候选的可用性副本的每个服务器实例上的每个可用性数据库都创建编写了脚本的备份作业。
(1)备份首选项
优先辅助副本
指定备份应在辅助副本上发生,但在主副本是唯一联机的副本时除外。 在该情况下,备份应在主副本上发生。 这是默认选项。
仅辅助副本
指定备份应该永远不会在主副本上执行。 如果主副本是唯一的联机副本,则备份应不会发生。
主副本
指定备份应该始终在主副本上发生。 如果您需要在对辅助副本运行备份时存在不支持的备份功能,例如创建差异备份,此选项将很有用。
任意副本
指定您希望在选择要执行备份的副本时备份作业将忽略可用性副本的角色。请注意,备份作业可能评估其他因素,例如每个可用性副本的备份优先级及其操作状态和已连接状态。
注意:如果您计划使用日志传送为可用性组准备任何辅助数据库,请将自动备份首选项设置为Primary,直到准备好所有辅助数据库并将其加入可用性组。没有强制的自动备份首选项设置。 对此首选项的解释取决于您为给定可用性组中的数据库撰写备份作业脚本的逻辑(如果有)。 自动备份首选项设置对即席备份没有影响。
(2)判断语句
若要为某一给定可用性组考虑使用自动备份首选项,则对于承载备份优先级大于零 (>0) 的可用性副本的每个服务器实例,您需要为该可用性组中的数据库的备份作业编写脚本。若要确定当前副本是否为首选备份副本,请在备份脚本中使用 sys.fn_hadr_backup_is_preferred_replica 函数。如果当前实例上的数据库位于首选副本上,则返回 1否则返回 0。 通过对查询此函数的每个可用性副本运行判断脚本,可以确定哪个副本应运行给定的备份作业。
If sys.fn_hadr_backup_is_preferred_replica(@dbname)=1
BEGIN
BACKUP DATABASE @DBNAME TO DISK=
END
ELSE
PRINT('当前副本不是备份首选副本')
在所有可能执行的备份的副本上面创建相同的备份语句,在发生故障转移时,无需修改任何脚本或作业
(3)创建代理作业
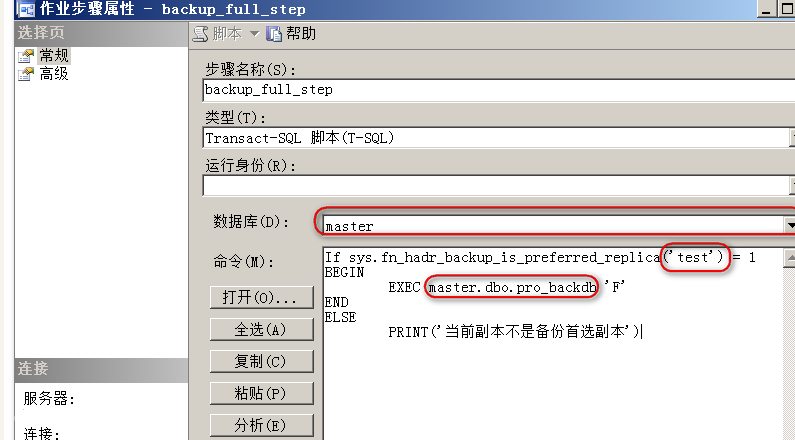
注意:
1.这里的数据库要选择"master",如果当前的alwayson配置了只读路由而你这里选择的是可用性数据库的话那么在辅助副本上面创建的作业会执行失败,因为只读路由连接辅助副本可用性数据库需要readonly连接属性。创建非备份的其它作业也是一样。
2.当前我的备份脚本放在master数据库中,如果是执行其它数据库下的脚本也是一样,这里需要将数据库名带上。
3. 如果if判断这里指定的是一个非可用性组的数据库返回的结果同样是1,因为对于实例来说非可用性的数据库也是备份的首先副本。
4.如果begin end中执行的是存储过程,不能在执行存储过程语句之前做可能涉及修改的其它相关操作比如:
1.选择数据库(use database);
2.定义变量(declare @id);
3.set赋值
4.其它的相关操作。
判断是否是主副本命令
If sys.fn_hadr_is_primary_replica (@dbname) =1
BEGIN
PRINT('1')
END
ELSE
PRINT('当前副本不是主副本')
备注:判断是否是主副本命令和判断是否是备份主副本命令不一样,如果指定的数据库是非可用性组数据库判断是否是主副本返回的结果是NULL,而判断是否是备份主副本返回的是1。
总结
1.在可用性组的主数据库或辅助数据库上不允许 RESTORE 语句。
2.备份首选项只是给出一个备份的判断选项,无论你手动在哪个副本上备份都可以,唯一的限制就是辅助副本的完整备份只支持"复制"备份。由于辅助副本只支持仅复制备份,所以辅助副本无法进行差异备份。要进行差异备份那么首先备份副本应该选择主副本。
3.无论是在主副本上备份日志还是在辅助副本上备份日志最终都会截断所有副本上的日志链。
【7】节点操作
【7.1】删除辅助副本(DB4)
(1)连到主副本,找到要删除的辅助副本右击=》从可用性组中删除
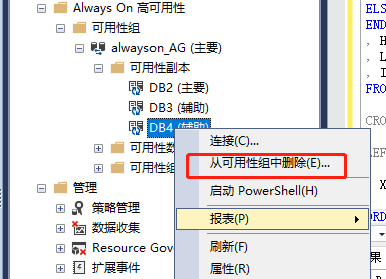
ALTER AVAILABILITY GROUP alwayson_AG REMOVE REPLICA ON N'DB4';
然后点击确定,没有报错的话就完事了。
然后,也可以把它从集群中逐出,以做他用。故障转移群集管理器=》节点=》右击DB4

【7.2】添加辅助副本
如果没有加入故障转移群集,需要先加入故障转移群集
(1)右击=》连接到群集=》输入alwayson_test
(2)右击节点=》添加节点
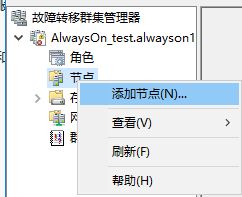
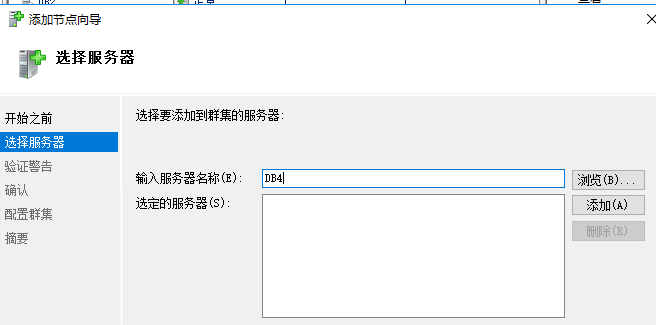
然后一直下一步下一部就好了;
添加可用性副本:
(1)先备份主库(怕破坏日志链也可以使用copyonly与notruncate的方式备份全备和事务备份)(或者利用现有备份)
Backup database test to disk='\\DB2\share_file\test.bak' with init;
Backup log test to disk='\\DB2\share_file\test.trn' with init;
(2)利用主库的全备+事务备以norecovery的方式还原到新节点
Restore database test from disk=' \\DB2\share_file\test.bak' with norecovery
Restore database test from disk=' \\DB2\share_file\test.trn' with norecovery
(3)连接到主副本(或者以非readonly方式连接到侦听器)

这里我们把这个新节点设置成异步的辅助副本;

选择仅连接即可。

下一步下一步完成即可。
这样子的话,我们的只读路由需要重新更新一下;现在的只读路由如下
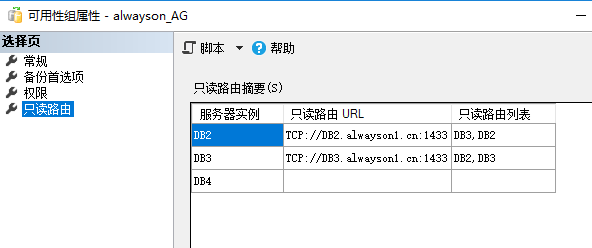
我们用4.3中读负载均衡的配置:(在主副本中运行)
--更新只读路由URL
USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB2.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB3.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB4.alwayson1.cn:1433'))
GO
--更新读负载均衡与只读路由配置
USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = ((N'DB3',N'DB2'),N'DB4')))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = ((N'DB4',N'DB2'),N'DB3')))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = ((N'DB4',N'DB3'),N'DB2')))
GO

OK,大功告成
【7.3】添加可用性数据库
(1)手动初始化
--主副本备份:
backup database test1 to disk='\\db2\share_file\test1.bak' with init
backup log test1 to disk='\\db2\share_file\test1.trn' with init
--辅助副本还原:
Use master;
restore database test1 from disk='\\db2\share_file\test1.bak' with norecovery,replace
restore log test1 from disk='\\db2\share_file\test1.trn' with norecovery
(2)登录主副本(或者非只读方式访问侦听器)现在主副本是DB3
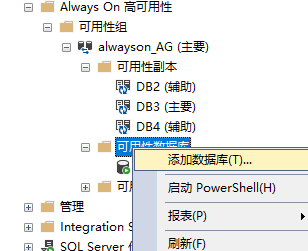

连接登录一下其他辅助节点:

下一步下一步完成即可,注意看验证是否有错误。
【7.4】删除、断开可用性数据库
我们从库可以单方面断开/连接与主库的可用性组数据库


对应语句:
从库上数据库连接到可用性组:ALTER DATABASE [test1] SET HADR AVAILABILITY GROUP = [alwayson_AG];
从库上数据库断开可用性组:ALTER DATABASE test1 SET HADR off;
【8】两个节点的无域控AlwaysOn测试

【8.1】故障转移测试(停服务、手动转移)--可用
总结:手动停服、手动故障转移这2个操作都不影响可用性组侦听器
(1)手动故障转移:成功
右击可用性组=》故障转移=》选择新DB
或者连上新的你想要操作的主库之后,运行下面语句
ALTER AVAILABILITY GROUP [alwayson_AG] FAILOVER;
(2)自动故障转移
停止服务:成功从DB3切换到DB2了
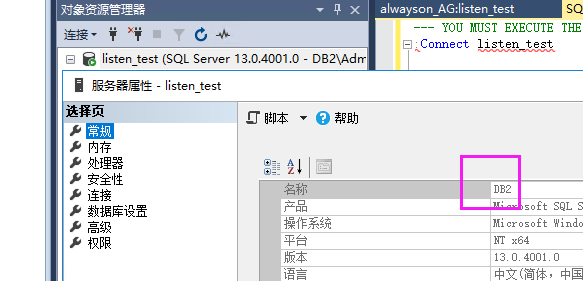
重启DB3后:又自动连接回集群了

【8.2】故障转移测试(机器宕机)--不可用
总结:主库宕机会导致可用性组奔溃,从库宕机没有关系,主库依旧可以提供服务
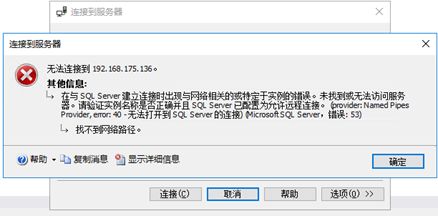
(1)模拟主副本所在机器宕机
现在DB3是主库,然后我挂起虚拟机模拟机器关闭

DB2并没有接管可用性组变成主库,反而成了一个无法操作的test库
侦听器也无法连接上去了。
故障转移群集:也挂掉了

重启好db3之后,一直发现DB2显示未同步

上故障转移集群管理器上看了一下,它被隔离了!
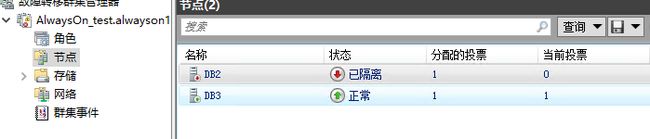
为什么被隔离,我们从群建事件中找到了关键信息,又查看了一下故障转移次数,是因为设置的允许次数很小。
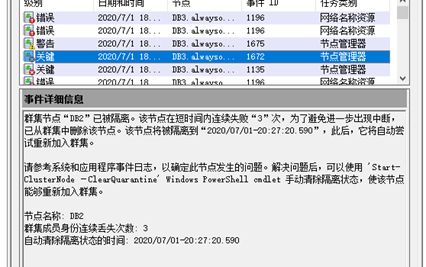
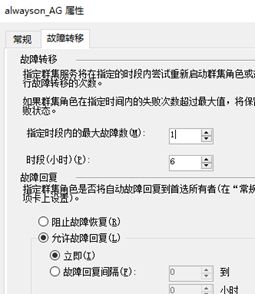
然后我们启动一下,恢复回来,然后数据库也正常了
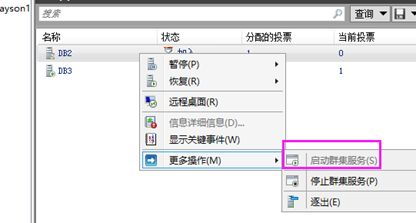
(2)从库辅助副本宕机
不影响。只是辅助副本断开了而已。然后DB2又被隔离了….

【故障处理】
参考官网故障策略:
https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/always-on-policies-for-operational-issues-always-on-availability?view=sql-server-2016
(1)创建故障转移集群失败
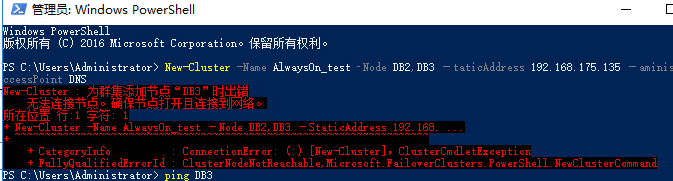
这个多半是DNS的问题
排查思路:
-
网络是否通顺
-
防火墙
-
Hosts文件中是否写的是 dns名称,我这里曾经就是因为hosts中写的是主机名而不是整个DNS名称,所以报错。
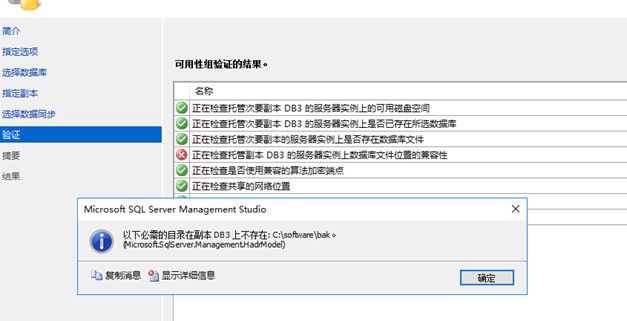
(2)创建可用性组时验证报错(文件位置)
很明显,要求两个机器要有相同的存储路径,否则会保存。
(3)不能使用共享文件夹见证仲裁

前提:防火墙关了,网络是通的,共享文件夹给了everyone权限,在其他机器上可以通过UNC路径访问;
最终还是不行
(4)如何重新加入新集群?
如果SQL配置过旧集群,加入过旧集群,删除集群后;
SQL Server要重新加入到新集群(在SQL配置管理器,先取消启用AlwaysON,重启SQL再启用)
(5)故障转移群集连不上?
大概率是DNS和权限的问题,查看一下hosts 以及登录账户是否是administrator
(6)可用性组中的可用性副本连接已断开(未同步)
可能的原因
辅助副本未连接到主副本。 连接状态为 DISCONNECTED。 此问题可能由以下原因导致:
连接端口可能与另一个应用程序冲突。
加密类型或算法不匹配。
连接端点已被删除或尚未启动。
传输已断开连接。
可能的解决方法
以下是此问题的可能解决方法:
检查主副本和辅助副本实例的数据库镜像端点配置,并更新不匹配的配置。
检查端口是否冲突,如果冲突,请更改端口号。
select * from sys.certificates –证书
select * from sys.tcp_endpoints –tcp端口
select * from sys.database_mirroring_endpoints
(7)辅助副本数据库状态一直显示正在还原...
<1>选择数据库同步方式:因为选择了使用完整的数据库和日志备份的方式,辅助副本一直处于正在还原的状态,如下图:
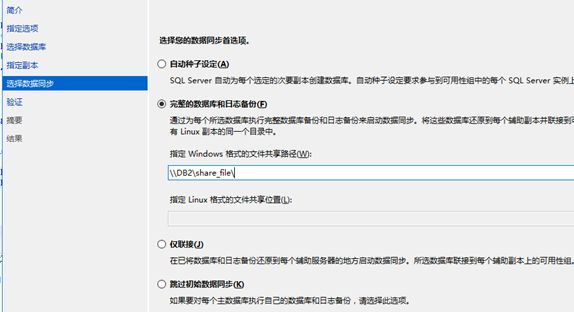
在无域控证书验证的操作过程中,使用共享文件夹来利用备份备份还原这一步似乎有问题。
解决办法:
0)在从库(辅助副本)上使用 restore database with norecovery试试,不行建议使用下面的办法
1)使用手动复制主库数据库+日志的备份文件到从库restore database with norecovery 的方式初始化,如【3.5】中的操作
2)参考(6)中解决办法
(8)已存在AG使用图形界面创建只读路由报错……
使用图形界面创建报错,需要先添加只读路由URL,才能构建只读路由列表,这个在新建AG的时候可以操作成功,但是在AG成功后操作,居然报错了。
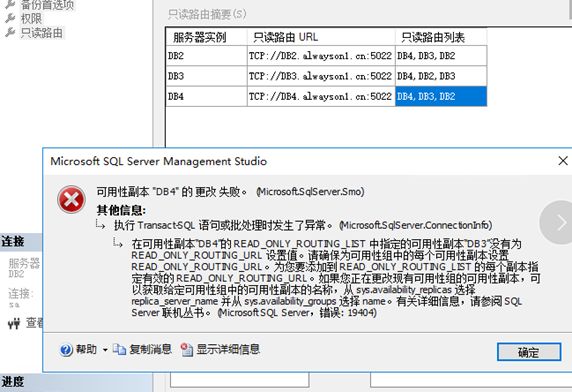
我们用这个,点击生成脚本。

USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB4.alwayson1.cn:1433))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'DB3',N'DB2',N'DB4')))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB3.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'DB4',N'DB2',N'DB3')))
GO
USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB2.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'DB4',N'DB3',N'DB2')))
GO
--脚本如上,我们直接执行会报错,所以需要先执行下面的构建只读URL
--更新只读路由URL
USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB2.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB3.alwayson1.cn:1433'))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (SECONDARY_ROLE(READ_ONLY_ROUTING_URL = N'TCP://DB4.alwayson1.cn:1433'))
GO
--更新只读路由列表
USE [master]
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB4' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'DB3',N'DB2',N'DB4')))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB3' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'DB4',N'DB2',N'DB3')))
GO
ALTER AVAILABILITY GROUP [alwayson_AG]
MODIFY REPLICA ON N'DB2' WITH (PRIMARY_ROLE(READ_ONLY_ROUTING_LIST = (N'DB4',N'DB3',N'DB2')))
GO
--查看是否建立成功
SELECT ar.replica_server_name ,
rl.routing_priority ,
(
SELECT ar2.replica_server_name
FROM sys.availability_read_only_routing_lists rl2
JOIN sys.availability_replicas AS ar2 ON rl2.read_only_replica_id = ar2.replica_id
WHERE rl.replica_id = rl2.replica_id
AND rl.routing_priority = rl2.routing_priority
AND rl.read_only_replica_id = rl2.read_only_replica_id
) AS 'read_only_replica_server_name'
FROM sys.availability_read_only_routing_lists rl
JOIN sys.availability_replicas AS ar ON rl.replica_id = ar.replica_id

OK。成功
参考文档
故障:https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/always-on-policies-for-operational-issues-always-on-availability?view=sql-server-2016
搭建:https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/monitoring-of-availability-groups-sql-server?view=sql-server-2016
监控:https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/monitoring-of-availability-groups-sql-server?view=sql-server-ver15
读负载均衡参考:https://www.cnblogs.com/gered/p/12773587.html
解决alwayson可用性组配置问题:https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/troubleshoot-always-on-availability-groups-configuration-sql-server?view=sql-server-2014
对alwaysOn各种情况的管理:https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/perform-a-planned-manual-failover-of-an-availability-group-sql-server?view=sql-server-2014
运营:https://docs.microsoft.com/zh-cn/sql/database-engine/availability-groups/windows/remove-a-secondary-database-from-an-availability-group-sql-server?view=sql-server-2016