MongoDB集群(三) 分片
何时选择分片是一个值得权衡的问题。通畅不必太早分片,因为分片不仅会增加部署的操作复杂度,还要求作出设计决策,而该决策之后很难再改。
另外最好也不要在系统运行太久之后再分片,因为在一个过载的系统上不停机进行分片是非常困难的。
分片的好处:
1. 增加可用RAM
2. 增加可用磁盘空间
3. 减轻单台服务器的负载
4. 处理单个mongod无法承受的吞吐量
举个例子,比如说现有的系统已经做了一个副本集(replSet)作为读写分离的集群,一个副本集只有一台主节点作为写节点,而其他的副本作为读节点,假设20毫秒内主节点可以处理1000次写请求,但是我们需要其能够在20毫秒内处理5000次请求,这个时候就需要考虑分片来提高吞吐量,并确保请求被均衡的分发到各集群成员上。
由于我比较懒,就从网上copy了以下对MongoDB分片的主要概念(from:lanceyan.com)
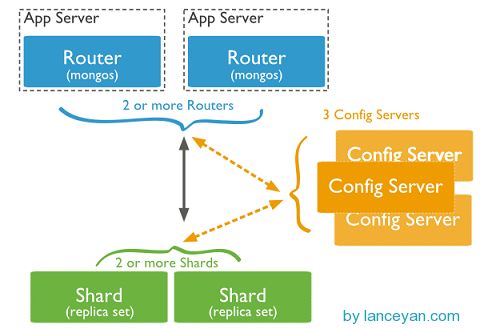
从图中可以看到有四个组件:mongos、config server、shard、replica set。
mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,这个可不能丢失!就算挂掉其中一台,只要还有存货, mongodb集群就不会挂掉。
shard,这就是传说中的分片了。上面提到一个机器就算能力再大也有天花板,就像军队打仗一样,一个人再厉害喝血瓶也拼不过对方的一个师。俗话说三个臭皮匠顶个诸葛亮,这个时候团队的力量就凸显出来了。在互联网也是这样,一台普通的机器做不了的多台机器来做,如下图:
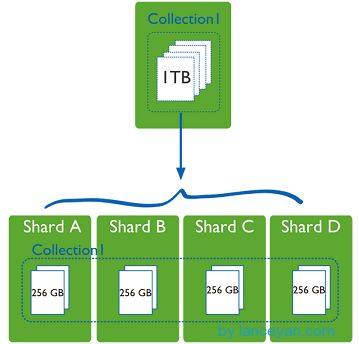
一台机器的一个数据表 Collection1 存储了 1T 数据,压力太大了!在分给4个机器后,每个机器都是256G,则分摊了集中在一台机器的压力。也许有人问一台机器硬盘加大一点不就可以了,为什么要分给四台机器呢?不要光想到存储空间,实际运行的数据库还有硬盘的读写、网络的IO、CPU和内存的瓶颈。在mongodb集群只要设置好了分片规则,通过mongos操作数据库就能自动把对应的数据操作请求转发到对应的分片机器上。在生产环境中分片的片键可要好好设置,这个影响到了怎么把数据均匀分到多个分片机器上,不要出现其中一台机器分了1T,其他机器没有分到的情况,这样还不如不分片!
说了这么多,下面我们来实际操作一下。
本次操作是在单台服务器上练习的,那么就用1个mongos + 1个config server + 2个shard
1、我们需要创建相应的文件夹来存放这些数据,按照功能的不同创建不同文件夹
添加config server文件夹
> md config1\db
添加mongos文件夹
> md mongos
> cd.>mongs\mongos.conf
添加shard1文件夹
> md shard1\db
> md shard1\log
添加shard2文件夹
> md shard2\db
> md shard2\log
2、启动config服务
> mongod --dbpath ../data/config/mongos.conf --port 10000
3、启动mongos服务
> mongos --configdb 127.0.0.1:10000 -f ../data/mongos/mongos.conf
4、启动shard1服务和shard2服务
5、配置mongos
首先切换到mongos服务对应的命令行
> mongo 127.0.0.1:27017
然后添加分片服务器
> sh.addShard("127.0.0.1:10001")
> sh.addShard("127.0.0.1:10002")
接着添加需要分片的数据库(我用来测试的数据库是“TestDB”)
> sh.enableSharding("TestDB")
最后添加分片集合和片键(这一步是非常关键的,片建的作用是告诉config server按照什么样的规则去分配数据的存储位置)
> sh.shardCollection("TestDB.Customer",{"CustomerID":"hashed"})
设置完成后Customer会自动生成CustomerID_hashed索引
{"CustomerID":"hashed"} 表示按照“CustomerID”这个属性的hash值来组合分配。
到这一步我们的配置工作已经全部完成了,可以用sh.status()命令去查看当前的配置状态。
6、做一个测试程序来测试一把。
插入100000条随机数据
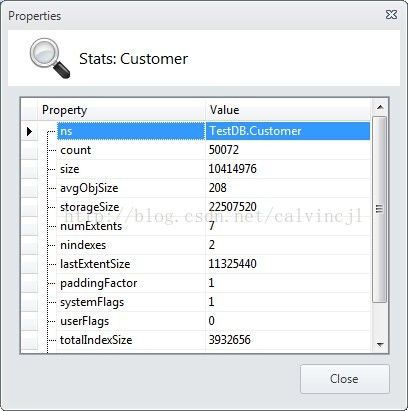
shard1里面的数据量为50072
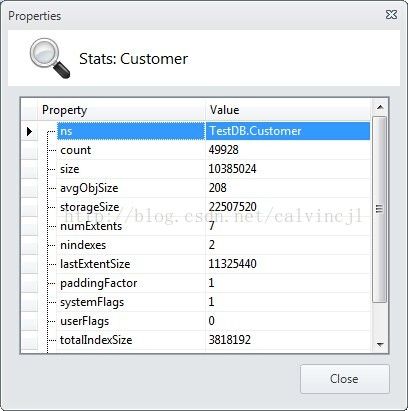
shard2里面的数据量为49928
大功告成!!
到目前为止简单版的mongo分片集群练习就做好了,就当是抛砖引玉,大家可以去读读相关的书籍和文章,mongo分区的知识还是比较深的,而且合理的运用mongo分片也不那么容易。