NLP-nltk篇
nltk
by deamon([email protected])
nltk的全称是natural language toolkit,是一套基于python的自然语言处理工具集,⾃带语料库,词性分类库,⾃带分类,分词,等等功能。
注意: 在运行命令nltk.download()安装 NLTK 的 nltk_data 模块的时候可能会出错。此时建议离线下载安装 NLTK 的 nltk_data 模块。
数据见:https://pan.baidu.com/s/1jIHTlyQ。 在下载完数据之后,将数据放在正确的nltk目录下,查看目录运行nltk.data.find("."),如下所示:
import nltk
nltk.data.find(".")
import nltk
#nltk.download()
NLTK功能如下表所示

NLTK⾃带语料库
from nltk.corpus import brown
brown.categories()
print(len(brown.sents()))
print(len(brown.words()))
⽂本处理流程
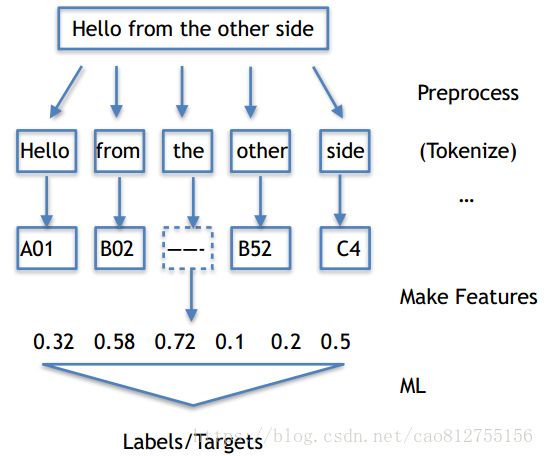
Tokenize
import nltk
sentence = "hello, world"
tokens = nltk.word_tokenize(sentence)
print(tokens)
中英⽂NLP区别
英文直接使用空格分词,中文需要专门的方法进行分词:

社交⽹络语⾔的tokenize
from nltk.tokenize import word_tokenize
tweet = 'RT @angelababy: love you baby! :D http://ah.love #168cm'
print(word_tokenize(tweet))
使用正则表达式对社交网络语言进行切词
如上面对'RT @angelababy: love you baby! :D http://ah.love #168cm'的切词客户已发现,切出来的数据不是很正确。那么对社交网络语言进行
tokenize的时候需要借助正则表达式,将表情符,网址,话题,@某人等作为一个整体.
正则表达式:http://www.regexlab.com/zh/regref.htm
import re
emoticons_str = r"""
(?:
[:=;] # 眼睛
[oO\-]? # ⿐⼦
[D\)\]\(\]/\\OpP] # 嘴
)"""
regex_str = [
emoticons_str,
r'<[^>]+>', # HTML tags
r'(?:@[\w_]+)', # @某⼈
r"(?:\#+[\w_]+[\w\'_\-]*[\w_]+)", # 话题标签
r'http[s]?://(?:[a-z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-f][0-9a-f]))+',
# URLs
r'(?:(?:\d+,?)+(?:\.?\d+)?)', # 数字
r"(?:[a-z][a-z'\-_]+[a-z])", # 含有 - 和 ‘ 的单词
r'(?:[\w_]+)', # 其他
r'(?:\S)' # 其他
]
tokens_re = re.compile(r'('+'|'.join(regex_str)+')', re.VERBOSE | re.IGNORECASE)
emoticon_re = re.compile(r'^'+emoticons_str+'$', re.VERBOSE | re.IGNORECASE)
def tokenize(s):
return tokens_re.findall(s)
def preprocess(s, lowercase=False):
tokens = tokenize(s)
if lowercase:
tokens = [token if emoticon_re.search(token) else token.lower() for token in tokens]
return tokens
tweet = 'RT @angelababy: love you baby! :D http://ah.love #168cm'
print(preprocess(tweet))
纷繁复杂的词形
Inflection变化: walk => walking => walked (不影响词性)
derivation 引申: nation (noun) => national (adjective) => nationalize (verb) (影响词性)
词形归⼀化
Stemming 词⼲提取:⼀般来说,就是把不影响词性的inflection的⼩尾巴砍掉
walking 砍ing = walk
walked 砍ed = walk
Lemmatization 词形归⼀:把各种类型的词的变形,都归为⼀个形式
went 归⼀ = go are 归⼀ = be
NLTK实现Stemming
词⼲提取:是把不影响词性的inflection的⼩尾巴砍掉
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem('maximum'))
print(porter_stemmer.stem('presumably'))
print(porter_stemmer.stem('multiply'))
print(porter_stemmer.stem('provision'))
from nltk.stem import SnowballStemmer
snowball_stemmer=SnowballStemmer('english')
print(snowball_stemmer.stem('maximum'))
print(snowball_stemmer.stem('presumably'))
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer=LancasterStemmer()
print(lancaster_stemmer.stem('maximum'))
print(lancaster_stemmer.stem('presumably'))
print(lancaster_stemmer.stem('presumably'))
from nltk.stem.porter import PorterStemmer
p = PorterStemmer()
print(p.stem('went'))
print(p.stem('wenting'))
LTK实现Lemma
词形归⼀:把各种类型的词的变形,都归为⼀个形式
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
print(wordnet_lemmatizer.lemmatize('dogs'))
print(wordnet_lemmatizer.lemmatize('churches'))
print(wordnet_lemmatizer.lemmatize('aardwolves'))
print(wordnet_lemmatizer.lemmatize('abaci'))
print(wordnet_lemmatizer.lemmatize('hardrock'))
Lemma Tips
一些词的雌性不一样的时候表达的意思是不一样的,比如:
Went v. go的过去式
Went n. 英⽂名:温特
NLTK更好地实现Lemma
# 没有POS Tag,默认是名词
print(wordnet_lemmatizer.lemmatize('are'))
print(wordnet_lemmatizer.lemmatize('is'))
# 加上POS Tag
print(wordnet_lemmatizer.lemmatize('is',pos='v'))
print(wordnet_lemmatizer.lemmatize('are',pos='v'))
部分语言

NLTK词性标注符号含义
标记 含义 例子
CC 连词 and, or,but, if, while,although
CD 数词 twenty-four, fourth, 1991,14:24
DT 限定词 the, a, some, most,every, no
EX 存在量词 there, there's
FW 外来词 dolce, ersatz, esprit, quo,maitre
IN 介词连词 on, of,at, with,by,into, under
JJ 形容词 new,good, high, special, big, local
JJR 比较级词语 bleaker braver breezier briefer brighter brisker
JJS 最高级词语 calmest cheapest choicest classiest cleanest clearest
LS 标记 A A. B B. C C. D E F First G H I J K
MD 情态动词 can cannot could couldn't
NN 名词 year,home, costs, time, education
NNS 名词复数 undergraduates scotches
NNP 专有名词 Alison,Africa,April,Washington
NNPS 专有名词复数 Americans Americas Amharas Amityvilles
PDT 前限定词 all both half many
POS 所有格标记 ' 's
PRP 人称代词 hers herself him himself hisself
PRP 所有his mine my our ours
RB 副词 occasionally unabatingly maddeningly
RBR 副词比较级 further gloomier grander
RBS 副词最高级 best biggest bluntest earliest
RP 虚词 aboard about across along apart
SYM 符号 % & ' '' ''. ) )
TO 词to to
UH 感叹词 Goodbye Goody Gosh Wow
VB 动词 ask assemble assess
VBD 动词过去式 dipped pleaded swiped
VBG 动词现在分词 telegraphing stirring focusing
VBN 动词过去分词 multihulled dilapidated aerosolized
VBP 动词现在式非第三人称时态 predominate wrap resort sue
VBZ 动词现在式第三人称时态 bases reconstructs marks
WDT Wh限定词 who,which,when,what,where,how
WP WH代词 that what whatever
WP WH代词所有格 whose
WRB WH副词
P.S.上面的含义可以直接使用“nltk.help.upenn_tagset()”查看官方英文说明。
NLTK标注POS Tag
import nltk
text=nltk.word_tokenize('what does the for say')
print('text : ',text)
print(nltk.pos_tag(text))
停用词
停用词(Stop Words) ,词典译为“电脑检索中的虚字、非检索用字”。在SEO中,为节省存储空间和提高搜索效率,搜索引擎在索引页面
或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词、静止词)。
停用词一定程度上相当于过滤词(Filter Words),不过过滤词的范围更大一些,包含黄色、政治等敏感信息的关键词都会被视做过滤词加以处理,
停用词本身则没有这个限制。通常意义上,停用词(Stop Words)大致可分为如下两类:
(1)使用十分广泛,甚至是过于频繁的一些单词。比如英文的“i”、“is”、“a”、“the”,中文的“我”、“的”之类词几乎在每个文档上
均会出现,查询这样的词搜索引擎就无法保证能够给出真正相关的搜索结果,难于缩小搜索范围提高搜索结果的准确性,同时还会降低搜索的效率。
因此,在真正的工作中,Google和百度等搜索引擎会忽略掉特定的常用词,在搜索的时候,如果我们使用了太多的停用词,也同样有可能无法得到
非常精确的结果,甚至是可能大量毫不相关的搜索结果。
(2)文本中出现频率很高,但实际意义又不大的词。这一类主要包括了语气助词、副词、介词、连词等,通常自身并无明确意义,只有将其放入
一个完整的句子中才有一定作用的词语。如常见的“的”、“在”、“和”、“接着”之类,比如“SEM分享是个关于SEM的博客”这句话中的
“是”、“的”就是两个停用词。
英文停用词:https://www.ranks.nl/stopwords
中文停用词:https://github.com/chdd/weibo/tree/master/stopwords
NLTK去除stopwords
from nltk.corpus import stopwords
# 先token,得到一个word_list
word_list = nltk.word_tokenize('what does the for say')
# 然后filter
filtered_words = [word for word in word_list if word not in stopwords.words('english')]
print(' filtered_words : ',filtered_words)
⼀条typical的⽂本预处理流⽔线

文本预处理流程

NLTK在NLP中的应用
- 情感分析
- ⽂本相似度
- ⽂本分类
应用一:情感分析
对词进行打分,并且构建词典,比如:
- like 1
- good 2
- bad -2
- terrible -3
import sys
sentiment_dictionary = {}
file = open('./nltk/data/AFINN-111.txt',encoding='utf-8')
line = file.readline()
while line:
word,score = line.split('\t')
sentiment_dictionary[word] = int(score)
line = file.readline()
words = sentiment_dictionary.keys()
total_score = sum(sentiment_dictionary.get(word,0) for word in words)
print(total_score)
基于ML的情感分析
from nltk.classify import NaiveBayesClassifier
s1='this is a good book'
s2='this is a awesome book'
s3='this is a bad book'
s4='this is a terrible book'
def preprocess(s):
# Func:句子处理,简单的用split(),把句子中每个单词分开
return {word:True for word in s.lower().split()}
# 把训练集做成标准形式
training_data=[[preprocess(s1),'pos'],
[preprocess(s2),'pos'],
[preprocess(s3),'neg'],
[preprocess(s4),'neg']]
#模型训练
model=NaiveBayesClassifier.train(training_data)
#输出结果
print(model.classify(preprocess('this is a good book')))
应用二:文本相似度
- ⽤元素频率表⽰⽂本特征,如下所示:

- 文本相似度求解原理,余弦定理
-

Frequency频率统计
import nltk
from nltk import FreqDist
#词库
corpus='this is my sentence this is my life this is the day '
tokens=nltk.word_tokenize(corpus)
print(' tokens : ',tokens)
# 用NLTK的FreqDist统计一下文字出现的频率
fdist = FreqDist(tokens)
# 查看某一个单词的频次
print('the word is frequence : ',fdist['is'])
# 最常用的50个单词
standard_freq_vector = fdist.most_common(50)
size = len(standard_freq_vector)
print('top 50 common words : ')
print(standard_freq_vector)
# 按照出现频率大小,记录每一个单词的位置
def position_lookup(v):
res = {}
counter=0
for word in v:
res[word[0]]=counter
counter+=1
return res
# 把标准的单词位置记录下来
standard_position_dict=position_lookup(standard_freq_vector)
print(standard_position_dict)
sentence='this is cool'
# 新建一个和标准vector同样大小的向量
freq_vector=[0]*size
tokens=nltk.word_tokenize(sentence)
# 对sentence中的词进行处理
for word in tokens:
try:
# 如果在词库中出现过,那么就在“标准位置”上+1
freq_vector[standard_position_dict[word]] += 1
except KeyError:
# 如果是新词,就pass掉
continue
print(freq_vector)
应用三:文本分类
TF-IDF
-
TF: Term Frequency, 衡量⼀个term在⽂档中出现得有多频繁。TF(t) = (t出现在⽂档中的次数) / (⽂档中的term总数).
-
IDF: Inverse Document Frequency, 衡量⼀个term有多重要。有些词出现的很多,但是明显不是很有卵⽤。⽐如’is', ’the‘, ’and‘之类的。为了平衡,我们把罕见的词的重要性(weight)搞⾼,把常见词的重要性搞低。IDF(t) = log_e(⽂档总数 / 含有t的⽂档总数).
-
TF-IDF = TF * IDF举个例子: ⼀个⽂档有100个单词,其中单词baby出现了3次。那么, TF(baby) = (3/100) = 0.03.有10M的⽂档, baby出现在其中的1000个⽂档中。那么, IDF(baby) = log(10,000,000 / 1,000) = 4TF-IDF(baby) = TF(baby) * IDF(baby) = 0.03 * 4 = 0.12
NLTK实现TF-IDF
from nltk.text import TextCollection
text1 = 'I like the movie so much '
text2 = 'That is a good movie '
text3 = 'This is a great one '
text4 = 'That is a really bad movie '
text5 = 'This is a terrible movie'
# 构建TextCollection对象
tc=TextCollection([text1,text2,text3,text4,text5])
new_text = 'That one is a good movie. This is so good!'
word = 'That'
tf_idf_val=tc.tf_idf(word,new_text)
print('{}的TF-IDF值为:{}'.format(word,tf_idf_val))
正则表达式分块器
为了创建一个NP-块,我们需要定义NP-块的块语法。正则表达式分块器接受正则表达式规则定义的语法来对文本进行分块
import nltk
# 分词
text = "the little yellow dog barked at the cat"
sentence = nltk.word_tokenize(text)
# 词性标注
sentence_tag = nltk.pos_tag(sentence)
print(sentence_tag)
# 定义分块语法
# 这个规则是说一个NP块由一个可选的限定词后面跟着任何数目的形容词然后是一个名词组成
# NP(名词短语块) DT(限定词) JJ(形容词) NN(名词)
grammar = "NP: {?*}"
# 进行分块
cp = nltk.RegexpParser(grammar)
tree = cp.parse(sentence_tag)
tree.draw()
多条规则的正则表达式分块器
上面的例子只有一条语法规则,如果面对复杂的情况就不太适用,我们可以定义多条分块规则。面对多条规则,分块器会轮流应用分块规则,
依次更新块结构,所有的规则都被调用后才返回。
import nltk
# 分词
text = "Lucy let down her long golden hair"
sentence = nltk.word_tokenize(text)
# 词性标注
sentence_tag = nltk.pos_tag(sentence)
print(sentence_tag)
# 定义分块语法
# NNP(专有名词) PRP$(格代名词)
# 第一条规则匹配可选的词(限定词或格代名词),零个或多个形容词,然后跟一个名词
# 第二条规则匹配一个或多个专有名词
# $符号是正则表达式中的一个特殊字符,必须使用转义符号\来匹配PP$
grammar = r"""
NP: {?*}
{+}
"""
# 进行分块
cp = nltk.RegexpParser(grammar)
tree = cp.parse(sentence_tag)
tree.draw()
ConditionalFreqDist::tabulate(conditions, samples):根据指定的条件和样本,打印条件频率分布表格。
import nltk
from nltk.corpus import brown
pairs = [(genre, word) for genre in brown.categories() for word in brown.words(categories=genre)]
cfd = nltk.ConditionalFreqDist(pairs)
genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
cfd.tabulate(conditions=genres, samples=modals)
cfd.plot(conditions=genres, samples=modals)
