SAP技术总结
1. 基础
1.1. 基本数据类型
C、N、D、T、I、F、P、X、string、Xstring
P:默认为8字节,最大允许16字节。最大整数位:16*2 = 32 - 1 = 31 -14(允许最大小数位数) = 17位整数位
| 类型 |
最大长度(字符数) |
默认长度 |
说明 |
| C |
1~262143个字符 |
1 字符 |
|
| N |
1~262143个字符 |
1 字符 |
0到9之间字符组成的数字字符串 |
| D |
8 个字符 |
|
日期格式必须为 YYYYMMDD |
| T |
6 个字符 |
|
格式为 24-hour的 HHMMSS |
| I |
4 bytes |
|
-2.147.483.648 to +2.147.483.647 |
| F |
8 bytes |
|
小数位最大可以到17位,即可精确到小数点后17位 |
| P |
1 to 16 bytes |
8 bytes |
两个数字位压缩后才占一个字节,由于0-9的数字只需要4Bit位,所以一个字节实质上允许存储二位数字,这就是P数据类型为压缩数据类型的由来。并借用半个字节来存储小数点位置、正号、负号相关信息 |
| X |
1~524,287 bytes |
1 byte |
十六进制字符 0-9, A-F具体的范围为:00~FF 类型X是十六进制类型,可表示内存字节实际内容,使用两个十六制字符表示一个字节中所存储的内容。但直接打印输出时,输出的还是赋值时字面意义上的值,而不是Unicode解码后的字符 如果未在 DATA 语句中指定参数 注:如果值是字母,则一定要大写 |
1.1.1.P类型(压缩型)数据
是一种压缩的定点数,其数据对象占据内存字节数和数值范围取定义时指定的整个数据大小和小数点后位数,如果不指定小数位,则将视为I类型。其有效数字位大小可以是从1~31位数字(小数点与正负号占用一个位置,半个字节),小数点后最多允许14个数字。
P类型的数据,可用于精确运算(这里的精确指的是存储中所存储的数据与定义时字面上所看到的大小相同,而不存在精度丢失问题——看到的就是内存中实实在在的大小)。在使用P类型时,要先选择程序属性中的选项 Fixed point arithmetic(即定点算法,一般默认选中),否则系统将P类型看用整型。其效率低于I或F类型。
"16 * 2 = 32表示了整个字面意义上允许的最大字面个数,而14表示的是字面上小数点后面允许的最大小数位,而不是指14个字节,只有这里定义时的16才表示16个字节
DATA: p(16) TYPE p DECIMALS 14 VALUE '12345678901234567.89012345678901'.
"正负符号与小数点固定要占用半个字节,一个字面上位置,并包括在这16个字节里面。
"16 * 2 = 32位包括了小数点与在正负号在内
"在定义时字面上允许最长可以达到32位,除去小数点与符号需占半个字节以后
"有效数字位可允许31位,这31位中包括了整数位与小数位,再除去定义时小
"数位为14位外,整数位最多还可达到17位,所以下面最多只能是17个9
DATA: p1(16) TYPE p DECIMALS 14 VALUE '-99999999999999999'.
"P类型是以字符串来表示一个数的,与字符串不一样的是,P类型中的每个数字位只会占用4Bit位,所以两个数字位才会占用一个字节。另外,如果定义时没有指定小数位,表示是整型,但小数点固定要占用半个字节,所以不带小数位与符号的最大与最小整数如下(最多允许31个9,而不是32个)
DATA: p1(16) TYPE p VALUE '+9999999999999999999999999999999'.
DATA: p2(16) TYPE p VALUE '-9999999999999999999999999999999'.
其实P类型是以字符串形式来表示一个小数,这样才可以作到精确,就像Java中要表示一个精确的小数要使用BigDecimal一样,否则会丢失精度。
DATA: p(9) TYPE p DECIMALS 2 VALUE '-123456789012345.12'.
WRITE: / p."123456789012345.12-
DATA: f1 TYPE f VALUE '2.0',
f2 TYPE f VALUE '1.1',
f3 TYPE f.
f3 = f1 - f2."不能精确计算
"2.0000000000000000E+00 1.1000000000000001E+00 8.9999999999999991E-01
WRITE: / f1 , f2 , f3.
DATA: p1 TYPE p DECIMALS 1 VALUE '2.0',
p2 TYPE p DECIMALS 1 VALUE '1.1',
p3 TYPE p DECIMALS 1.
p3 = p1 - p2."能精确计算
WRITE: / p1 , p2 , p3. "2.0 1.1 0.9
Java中精确计算:
publicstaticvoid main(String[] args) {
System.out.println(2.0 - 1.1);// 0.8999999999999999
System.out.println(sub(2.0, 0.1));// 1.9
}
publicstaticdouble sub(double v1, double v2) {
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.subtract(b2).doubleValue();
}
1.2.TYPE、LIKE
透明表(还有其它数据词典中的类型,如结构)即可看作是一种类型,也可看作是对象,所以即可使用TYPE,也可以使用LIKE:
TYPES type6 TYPE mara-matnr.
TYPES type7 LIKE mara-matnr.
DATA obj6 TYPE mara-matnr.
DATA obj7 LIKE mara-matnr.
"SFLIGHT为表类型
DATA plane LIKE sflight-planetype.
DATA plane2 TYPE sflight-planetype.
DATA plane3 LIKE sflight.
DATA plane4 TYPE sflight.
"syst为结构类型
DATA sy1 TYPE syst.
DATA sy2 LIKE syst.
DATA sy3 TYPE syst-index.
DATA sy4 LIKE syst-index.
注:定义的变量名千万别与词典中的类型相同,否则表面上即可使用TYPE也可使用LIKE,就会出现这两个关键字(Type、Like)都可用的奇怪现像,下面是定义一个变量时与词典中的结构同名的后果(导致)
DATA : BEGIN OF address2,
street(20) TYPE c,
city(20) TYPE c,
END OF address2.
DATA obj4 TYPE STANDARD TABLE OF address2."这里使用的实质上是词典中的类型address2
DATA obj5 LIKE STANDARD TABLE OF address2."这里使用是的上面定义的变量address2
上面程序编译通过,按理obj4定义是通过不过的(只能使用LIKE来引用另一定义变量的类型,TYPE是不可以的),但由于address2是数字词典中定义的结构类型,所以obj4使用的是数字词典中的结构类型,而obj5使用的是LIKE,所以使用的是address2变量的类型
1.3. DESCRIBE
DESCRIBE FIELD dobj
[TYPE typ [COMPONENTS com]]
[LENGTH ilen IN {BYTE|CHARACTER} MODE]
[DECIMALS dec]
[OUTPUT-LENGTH olen]
[HELP-ID hlp]
[EDIT MASK mask].
DESCRIBE TABLE itab [KIND knd] [LINES lin] [OCCURS n].
1.4.字符串表达式
可以使用&或&&将多个字符模板串链接起来,可以突破255个字符的限制,下面两个是等效的:
|...| & |...|
|...| && |...|
如果内容只有字面常量文本(没有变量表达式或控制字符\r \n \t),则不需要使用字符模板,可这样(如果包含了这些控制字符时,会原样输出,所以有这些控制字符时,请使用 |...|将字符包起来):
`...` && `...`
但是上面3个与下面3个是不一样的:
`...` & `...`
'...' & '...'
'...' && '...'
上面前两个还是会受255个字符长度限制,最后一个虽然不受255限制,但尾部空格会被忽略
字面常量文本(literal text)部分,使用 ||括起来,不能含有控制字符(如 \r \n \t这些控制字符),特殊字符 |{ } \需要使用 \进行转义:
txt = |Characters \|, \{, and \} have to be escaped by \\ in literal text.|.
字符串表达式:
str = |{ ( 1 + 1 ) * 2 }|."算术计算表达式
str = |{ |aa| && 'bb' }|."字符串表达式
str = |{ str }|."变量名
str = |{ strlen( str ) }|."内置函数
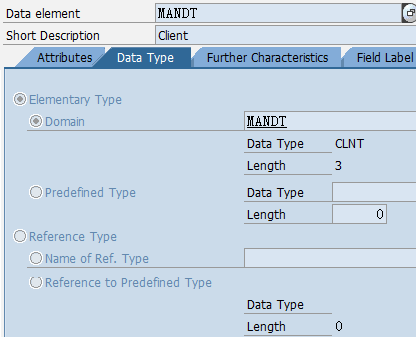
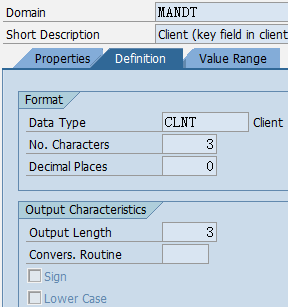
1.5. Data element、Domain
数据元素是构成结构、表的基本组件,域又定义了数据元素的技术属性。Data element主要附带Search Help、Parameter ID、以及标签描述,而类型是由Domain域来决定的。Domain主要从技术方面描述了Data element,如Data Type数据类型、Output Length输出长度、Convers. Routine转换规则、以及Value Range取值范围
将技术信息从Data element提取出来为Domain域的好处:技术信息形成的Domain可以共用,而每个表字段的业务含意不一样,会导致其描述标签、搜索帮助不一样,所以牵涉到业务部分的信息直接Data element中进行描述,而与业务无关的技术信息部分则分离出来形成Domain

1.6. 词典预定义类型与ABAP类型映射
当你在ABAP程序中引用了ABAPDictionary,则预置Dictionary类型则会转换为相应的ABAP类型,预置的Dictionary类型转换规则表如下:
| Dictionarytype |
Meaning |
Maximumlengthn |
ABAPtype |
| DEC |
Calculation/amountfield |
1-31, 1-17intables |
P((n+1)/2) |
| INT1 |
Single-byte integer |
3 |
Internalonly |
| INT2 |
Two-byteinteger |
5 |
Internalonly |
| INT4 |
Four-byteinteger |
10 |
I |
| CURR |
Currencyfield货币字段 |
1-17 |
P((n+1)/2) |
| CUKY |
Currencykey货币代码 |
5 |
C(5) |
| QUAN |
Amount金额 |
1-17 |
P((n+1)/2) |
| UNIT |
Unit单位 |
2-3 |
C(n) |
| PREC |
Accuracy |
2 |
X(2) |
| FLTP |
Floating pointnumber |
16 |
F(8) |
| NUMC |
Numeric text数字字符 |
1-255 |
N(n) |
| CHAR |
Character字符 |
1-255 |
C(n) |
| LCHR |
Long character |
256-max |
C(n) |
| STRING |
Stringofvariable length |
1-max |
STRING. |
| RAWSTRING |
Byte sequence of variable length |
1-max |
XSTRING |
| DATS |
Date |
8 |
D |
| ACCP |
Accounting period YYYYMM |
6 |
N(6) |
| TIMS |
Time HHMMSS |
6 |
T |
| RAW |
Byte sequence |
1-255 |
X(n) |
| LRAW |
Long byte sequence |
256-max |
X(n) |
| CLNT |
Client |
3 |
C(3) |
| LANG |
Language |
internal 1, external 2 |
C(1) |
这里的“允许最大长度m”表示的是字面上允许的字符位数,而不是指底层所占内存字节数,如
int1的取值为0~255,所以是3位(不包括符号位)
int2的取值为-32768~32767,所以是5位
lLCHR and LRAW类型允许的最大值为INT2 最大值
lRAWSTRING and STRING 具有可变长度,最大值可以指定,但没有上限
lSSTRING 长度是可变的,其最大值必须指定且上限为255。与CHAR类型相比其优势是它与ABAP type string进行映射。
这些预置的Dictionary类型在创建Data element、Domain时可以引用

在Unicode系统中,一个字符占两个字节


1.7.字符串处理
SPLIT dobj AT sep INTO { {result1 result2 ...} | {TABLE result_tab} }必须指定足够目标字段。否则,用字段dobj的剩余部分填充最后目标字段并包含分界符;或者使用内表动态接收
SHIFT dobj {[{BY num PLACES}|{UP TO sub_string}][[LEFT|RIGHT][CIRCULAR]]}
| { {LEFT DELETING LEADING}|{RIGHT DELETING TRAILING} } pattern
对于固定长度字符串类型,shift产生的空位会使用空格或十六进制的0(如果为X类型串时)来填充
向右移动时前面会补空格,固定长度类型字符串与String结果是不一样:String类型右移后不会被截断,只是字串前面补相应数量的空格,但如果是C类型时,则会截断;左移后后面是否被空格要看是否是固定长度类型的字符串还是变长的String类型串,左移后C类型会补空格,String类型串不会(会缩短)
CIRCULAR:将移出的字符串放在左边或者左边
pattern:只要前导或尾部字符在指定的pattern字符集里就会被去掉,直到第一个不在模式pattern的字符止
CONDENSE
CONCATENATE {dobj1 dobj2 ...}|{LINES OF itab}[kənˈkatɪneɪt]
INTO result
[SEPARATED BY sep]
[RESPECTING BLANKS].
CDNT类型的前导空格会保留,尾部空格都会被去掉,但对String类型所有空格都会保留;对于c, d, n, t类型的字符串有一个RESPECTING BLANKS选项可使用,表示尾部空格也会保留。注:使用 `` 对String类型进行赋值时才会保留尾部空格 字符串连接可以使用 && 来操作,具体请参考这里
strlen(arg)、Xstrlen(arg)String类型的尾部空格会计入字符个数中,但C类型的变量尾部空格不会计算入
substring( val = TEXT [off = off] [len = len] )
count( val = TEXT {sub = substring}|{regex = regex} )匹配指定字符串substring或正则式regex出现的子串次数,返回的类型为i整型类型
contains( val = TEXT REGEX = REGEX)是否包含。返回布尔值,注:只能用在if、While等条件表达式中
matches( val = TEXT REGEX = REGEX)regex表达式要与text完全匹配,这与contains是不一样的。返回布尔值,也只能用在if、While等条件表达式中
match( val = TEXT REGEX = REGEX occ = occ)返回的为匹配到的字符串。注:每次只匹配一个。occ:表示需匹配到第几次出现的子串。如果为正,则从头往后开始计算,如果为负,则从尾部向前计算
find( val = TEXT {sub = substring}|{regex = regex}[occ = occ] )查找substring或者匹配regex的子串的位置。如果未找到,则返回-1,返回的为offset,所以从0开始
FIND ALL OCCURRENCES OF REGEX regex IN dobj
[MATCH COUNT mcnt] 成功匹配的次数
{ {[MATCH OFFSET moff][MATCH LENGTH mlen]}最后一次整体匹配到的串(整体串,最外层分组,而不是指正则式最内最后一个分组)起始位置与长度
| [RESULTS result_tab|result_wa] } result_tab接收所有匹配结果,result_wa只能接收最后一次匹配结果
[SUBMATCHES s1 s2 ...].通常与前面的MATCH OFFSET/ LENGTH一起使用。只会接收使用括号进行分组的子组。如果变量s1 s2 ...比分组的数量多,则多余的变量被initial;如果变量s1 s2 ...比分组的数量少,则多余的分组将被忽略;且只存储第一次或最后一次匹配到的结果
replace( val = TEXT REGEX = REGEX WITH = NEW)使用new替换指定的子符串,返回String类型
REPLACE ALL OCCURRENCES OF REGEX regex IN dobj WITH new
1.7.1. count、match结合
DATA: text TYPE string VALUE `Cathy's cat with the hat sat on Matt's mat.`,
regx TYPE string VALUE `\<.at\>`."\< 单词开头,\> 单词结尾
DATA: counts TYPE i,
index TYPE i,
substr TYPE string.
WRITE / text.
NEW-LINE.
counts = count( val = text regex = regx )."返回匹配次数
DO counts TIMES.
index = find( val = text regex = regx occ = sy-index )."返回匹配到的的起始位置索引
substr = match( val = text regex = regx occ = sy-index )."返回匹配到的串
index = index + 1.
WRITE AT index substr.
ENDDO.
![]()
1.7.2.FIND …SUBMATCHES
DATA: moff TYPE i,
mlen TYPE i,
s1 TYPE string,
s2 TYPE string,
s3 TYPE string,
s4 TYPE string.
FIND ALL OCCURRENCES OF REGEX `((\w+)\W+\2\W+(\w+)\W+\3)`"\2 \3 表示反向引用前面匹配到的第二与第三个子串
IN `Hey hey, my my, Rock and roll can never die Hey hey, my my`"会匹配二次,但只会返回第二次匹配到的结果,第一次匹配到的子串不会存储到s1、s2、s3中去
IGNORING CASE
MATCH OFFSET moff
MATCH LENGTH mlen
SUBMATCHES s1 s2 s3 s4."根据从外到内,从左到右的括号顺序依次存储到s1 s2…中,注:只取出使用括号括起来的子串,如想取整体子串则也要括起来,这与Java不同
WRITE: / s1, / s2,/ s3 ,/ s4,/ moff ,/ mlen."s4会被忽略

1.7.3. FIND …RESULTS itab
DATA: result TYPE STANDARD TABLE OF string WITH HEADER LINE .
"与Java不同,只要是括号括起来的都称为子匹配(即使用整体也用括号括起来了),
"不管括号嵌套多少层,统称为子匹配,且匹配到的所有子串都会存储到,
"MATCH_RESULT-SUBMATCHES中,即使最外层的括号匹配到的子串也会存储到SUBMATCHES
"内表中。括号解析的顺序为:从外到内,从左到右的优先级顺序来解析匹配结构。
"Java中的group(0)存储的是整体匹配串,即使整体未(或使用)使用括号括起来
PERFORM get_match TABLES result
USING '2011092131221032' '(((\d{2})(\d{2}))(\d{2})(\d{2}))'.
LOOP AT result .
WRITE: / result.
ENDLOOP.
FORM get_match TABLES p_result"返回所有分组匹配(括号括起来的表达式)
USING p_str
p_reg.
DATA: result_tab TYPE match_result_tab WITH HEADER LINE.
DATA: subresult_tab TYPE submatch_result_tab WITH HEADER LINE.
"注意:带表头时 result_tab 后面一定要带上中括号,否则激活时出现奇怪的问题
FIND ALL OCCURRENCES OF REGEX p_reg IN p_str RESULTS result_tab[].
"result_tab中存储了匹配到的子串本身(与Regex整体匹配的串,存储在
"result_tab-offset、result_tab-length中)以及所子分组(括号部分,存储在
"result_tab-submatches中)
LOOP AT result_tab .
"如需取整体匹配到的子串(与Regex整体匹配的串),则使用括号将整体Regex括起来
"来即可,括起来后也会自动存储到result_tab-submatches,而不需要在这里像这样读取
* p_result = p_str+result_tab-offset(result_tab-length).
* APPEND p_result.
subresult_tab[] = result_tab-submatches.
LOOP AT subresult_tab.
p_result = p_str+subresult_tab-offset(subresult_tab-length).
APPEND p_result.
ENDLOOP.
ENDLOOP.
ENDFORM.


1.7.4.正则式类
regex = Regular expression [ˈreɡjulə]
cl_abap_regex:与Java中的 java.util.regex.Pattern的类对应
cl_abap_matcher:与Java中的 java.util.regex.Matcher的类对应
1.7.4.1.matches、match
是否完全匹配(正则式中不必使用 ^ 与 $);matches为静态方法,而match为实例方法,作用都是一样
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
"^$可以省略,因为matches方法本身就是完全匹配整个Regex
IF cl_abap_matcher=>matches( pattern = '^(db(ai).*)$' text = 'dbaiabd' ) = 'X'.
matcher = cl_abap_matcher=>get_object( )."获取最后一次匹配到的 Matcher 实例
match = matcher->get_match( ). "获取最近一次匹配的结果(注:是整体匹配的结果)
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
"^$可以省略,因为matche方法本身就是完全匹配整个Regex
matcher = cl_abap_matcher=>create( pattern = '^(db(ai).*)$' text = 'dbaiabd' ).
IF matcher->match( ) = 'X'.
match = matcher->get_match( ). "获取最近一次匹配的结果
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
1.7.4.2.contains
是否包含(也可在正则式中使用 ^ 与 $ 用于完全匹配检查,或者使用 ^ 检查是否匹配开头,或者使用 $ 匹配结尾)
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result,
match_line TYPE submatch_result.
IF cl_abap_matcher=>contains( pattern = '(db(ai).{2}b)' text = 'dbaiabddbaiabb' ) = 'X'.
matcher = cl_abap_matcher=>get_object( ). "获取最后一次匹配到的 Matcher 实例
match = matcher->get_match( ). "获取最近一次匹配的结果
WRITE / matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDIF.
![]()
1.7.4.3.find_all
一次性找出所有匹配的子串,包括子分组(括号括起的部分)
DATA: matcher TYPE REF TO cl_abap_matcher,
match_line TYPE submatch_result,
itab TYPE match_result_tab WITH HEADER LINE.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*(ml)>' text = 'hello' )."创建 matcher 实例
"注:子分组存储在itab-submatches字段里
itab[] = matcher->find_all( ).
LOOP AT itab .
WRITE: / matcher->text, itab-offset, itab-length,matcher->text+itab-offset(itab-length).
LOOP AT itab-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDLOOP.

1.7.4.4.find_next
逐个找出匹配的子串,包括子分组(括号括起的部分)
DATA: matcher TYPE REF TO cl_abap_matcher,
match TYPE match_result, match_line TYPE submatch_result,
itab TYPE match_result_tab WITH HEADER LINE.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*(ml)>' text = 'hello' ).
WHILE matcher->find_next( ) = 'X'.
match = matcher->get_match( )."获取最近一次匹配的结果
WRITE: / matcher->text, match-offset, match-length,matcher->text+match-offset(match-length).
LOOP AT match-submatches INTO match_line. "提取子分组(括号括起来的部分)
WRITE: /20 match_line-offset, match_line-length,matcher->text+match_line-offset(match_line-length).
ENDLOOP.
ENDWHILE.

1.7.4.5.get_length、get_offset、get_submatch
DATA: matcher TYPE REF TO cl_abap_matcher,
length TYPE i,offset TYPE i,
submatch TYPE string.
matcher = cl_abap_matcher=>create( pattern = '(<[^<>]*(ml)>)' text = 'hello' ).
WHILE matcher->find_next( ) = 'X'. "循环2次
"为0时,表示取整个Regex匹配到的子串,这与Java一样,但如果整个Regex使用括号括起来后,
"则分组索引为1,这又与Java不一样(Java不管是否使用括号将整个Regex括起来,分组索引号都为0)
"上面Regex中共有两个子分组,再加上整个Regex为隐含分组,所以一共为3组
DO 3 TIMES.
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串长度
length = matcher->get_length( sy-index - 1 ).
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串起始位置
offset = matcher->get_offset( sy-index - 1 ).
"在当前匹配到的串(整个Regex相匹配的串)中返回指定子分组的匹配到的字符串
submatch = matcher->get_submatch( sy-index - 1 ).
WRITE:/ length , offset,matcher->text+offset(length),submatch.
ENDDO.
SKIP.
ENDWHILE.

1.7.4.6.replace_all
DATA: matcher TYPE REF TO cl_abap_matcher,
count TYPE i,
repstr TYPE string.
matcher = cl_abap_matcher=>create( pattern = '<[^<>]*>' text = 'hello' ).
count = matcher->replace_all( ``)."返回替换的次数
repstr = matcher->text. "获取被替换后的新串
WRITE: / count , repstr.

1.8.CLEAR、REFRESH、FREE
内表:如果使用有表头行的内表,CLEAR 仅清除表格工作区域。要重置整个内表而不清除表格工作区域,使用REFRESH语句或 CLEAR 语句CLEAR
以上都不会释放掉内表所占用的空间,如果想初始化内表的同时还要释放所占用的空间,请使用:FREE
1.9.ABAP程序中的局部与全局变量
报表程序中选择屏幕事件块(AT SELECTION-SCREEN)与逻辑数据库事件块、以及methods(类中的方法)、subroutines(FORM子过程)、function modules(Function函数)中声明的变量为局部的,即在这些块里声明的变量不能在其他块里使用,但这些局部变量可以覆盖同名的全局变量;除这些处理块外,其他块里声明的变量都属于全局的(如报表事件块、列表事件块、对话Module),效果与在程序最开头定义的变量效果是一样的,所以可以在其他处理块直接使用(但要注意的是,需遵守先定义后使用的原则,这种先后关系是从语句书写顺序来说的,与事件块的本身运行顺序没有关系);另外,局部变量声明时,不管在处理块的任何地方,其效果都是相当于处理块里的全局变量,而不像其他语言如Java那样:局部变量的作用域可以存在于任何花括号{}之间(这就意味着局部变量在处理过程范围内是全局的),如下面的i,在ABAP语言中还是会累加输出,而不会永远是1(在Java语言中会是1):
FORM aa.
DO 10 TIMES.
DATA: i TYPE i VALUE 0.
i = i + 1.
WRITE: / i.
ENDDO.
ENDFORM.
1.10.Form、Function
Form、Function中的TABLES参数,TYPE与LIKE后面只能接标准内表类型或标准内表对象,如果要使用排序内表或者哈希内表,则只能使用USING(Form)与CHANGING方式来代替。当把一个带表头的实参通过TABLES参数传递时,表头也会传递过去,如果实参不带表头或者只传递了表体(使用了[]时),系统会自动为内表参数变量创建一个局部空的表头
不管是以TABLES还是以USING(Form)非值、CHANGE非值方式传递时,都是以引用方式(即别名,不是指地址,注意与Java中的传引用区别:Java实为传值,但传递的值为地址的值,而ABAP中传递的是否为地址,则要看实参是否是通过Type ref to定义的)传递;但如果USING值传递,则对形参数的修改不会改变实参,因为此时不是引用传递;但如果CHANGE值传递,对形参数的修改还是会改变实参,只是修改的时机在Form执行或Function执行完后,才去修改
Form中通过引用传递时,USING与CHANGING完全一样;但CHANGING为值传递方式时,需要在Form执行完后,才去真正修改实参变量的内容,所以CHANGING传值与传引用其结果都是一样:结果都修改了实参内容,只是修改的时机不太一样而已
1.10.1.FORM
FORM subr [TABLES t1 [{TYPE itab_type}|{LIKE itab}|{STRUCTURE struc}]
t2 […]]
[USING { VALUE(p1)|p1 } [ { TYPE generic_type }
| { LIKE
| { TYPE {[LINE OF] complete_type}|{REF TO type} }
| { LIKE {[LINE OF] dobj} | {REF TO dobj} }
| STRUCTURE struc]
{ VALUE(p2)|p2 } […]]
[CHANGING{ VALUE(p1)|p1 } [ { TYPE generic_type }
| { LIKE
| { TYPE {[LINE OF] complete_type} | {REF TO type} }
| { LIKE {[LINE OF] dobj} | {REF TO dobj} }
| STRUCTURE struc]
{ VALUE(p2)|p2 } […]]
[RAISING {exc1|RESUMABLE(exc1)} {exc2|RESUMABLE(exc2)} ...].
generic_type:为通用类型
complete_type:为完全限制类型
generic_para:为另一个形式参数类型,如下面的 b 形式参数
DATA: d(10) VALUE'11'.
FIELD-SYMBOLS:
ASSIGN d TO
PERFORM aa USING
FORM aa USING fs like
WRITE:fs,/ a , / b.
ENDFORM.
如果没有给形式参数指定类,则为ANY类型
如果TABLES与USING、CHANGING一起使用时,则一定要按照TABLES、USING、CHANGING顺序声明
值传递中的VALUE关键字只是在FORM定义时出现,在调用时PERFORM语句中无需出现,也就是说,调用时值传递和引用传递不存在语法格式差别
DATA : i TYPE i VALUE 100.
WRITE: / 'frm_ref===='.
PERFORM frm_ref USING i .
WRITE: / i."200
WRITE: / 'frm_val===='.
i = 100.
PERFORM frm_val USING i .
WRITE: / i."100
WRITE: / 'frm_ref2===='.
"不能将下面的变量定义到frm_ref2过程中,如果这样,下面的dref指针在调用frm_ref2 后,指向的是Form中局部变量内存,为不安全发布,运行会抛异常,因为From结束后,它所拥有的所有变量内存空间会释放掉
DATA: i_frm_ref2 TYPE i VALUE 400.
i = 100.
DATA: dref TYPE REF TO i .
get REFERENCE OF i INTO dref.
PERFORM frm_ref2 USING dref ."传递的内容为地址,属于别名引用传递
WRITE: / i."4000
field-SYMBOLS :
ASSIGN dref->* to
WRITE: /
WRITE: / 'frm_val2===='.
i = 100.
DATA: dref2 TYPE REF TO i .
get REFERENCE OF i INTO dref2.
PERFORM frm_val2 USING dref2 .
WRITE: / i."4000
ASSIGN dref2->* to
WRITE: /
FORM frm_ref USING p_i TYPE i ."C++中的引用参数传递:p_i为实参i的别名
WRITE: / p_i."100
p_i = 200."p_i为参数i的别名,所以可以直接修改实参
ENDFORM.
FORM frm_val USING value(p_i)."传值:p_i为实参i的拷贝
WRITE: / p_i."100
p_i = 300."由于是传值,所以不会修改主调程序中的实参的值
ENDFORM.
FORM frm_ref2 USING p_i TYPE REF TO i ."p_i为实参dref的别名,类似C++中的引用参数传递(传递的内容为地址,并且属于别名引用传递)
field-SYMBOLS :
"现在
ASSIGN p_i->* to
WRITE: /
DATA: dref TYPE REF TO i .
get REFERENCE OF i_frm_ref2 INTO dref.
"由于USING为C++的引用参数,所以这里修改的直接是实参所存储的地址内容,这里的p_i为传进来的dref的别名,是同一个变量,所以实参的指向也发生了改变(这与Java中传递引用是不一样的,Java中传递引用时为地址的拷贝,即Java中永远也只有传值,但C/C++/ABAP中可以传递真正引用——别名)
p_i = dref."此处会修改实参的指向
ENDFORM.
FORM frm_val2 USING VALUE(p_i) TYPE REF TO i ."p_i为实参dref2的拷贝,类似Java中的引用传递(虽然传递的内容为地址,但传递的方式属于地址拷贝——值传递)
field-SYMBOLS :
"现在
ASSIGN p_i->* to
WRITE: /
DATA: dref TYPE REF TO i .
get REFERENCE OF i_frm_ref2 INTO dref.
"这里与过程 frm_ref2 不一样,该过程 frm_val2 参数的传递方式与java中的引用传递是原理是一样的:传递的是地址拷贝,所以下面不会修改主调程序中实参dref2的指向,它所改变的只是拷贝过来的Form中局部形式参数的指向
p_i = dref.
ENDFORM.
1.10.2.FUNCTION

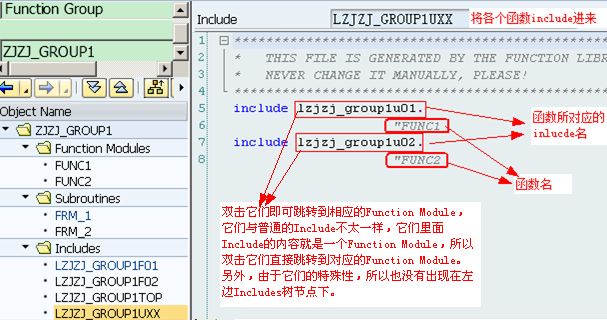
1.10.2.1. Function Group结构
当使用Function Builder创建函数组时,系统会自动创建main program与相应的include程序:

l
lSAPL
lL
lL
lL
lL
当你调用一个function module时,系统加将整个function group(包括Function Module、Include文件等)加载到主调程序所在的internal session中,然后该Function Module得到执行,该Function Group一直保留在内存中,直到internal session结束。Function Group中的所定义的Include文件中的变量是全局,被所有Function Module共享,所以Function Group好比Java中的类,而Function Module则好比类中的方法,所以Function Group中的Include文件中定义的东西是全局型的,能被所有Function Module所共享使用



1.10.2.2.Function参数传值、传址
function fuc_ref .
*"-------------------------------------------------------------------
*"*"Local Interface:
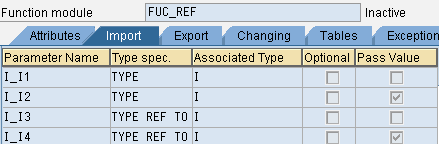
*" IMPORTING
*" REFERENCE(I_I1) TYPE IREFERENCE(别名)为参数的默认传递类型
*" VALUE(I_I2) TYPE I 定义时勾选了Pass Value选项才会是 VALUE类型
*" REFERENCE(I_I3) TYPE REF TO I
*" VALUE(I_I4) TYPE REF TO I
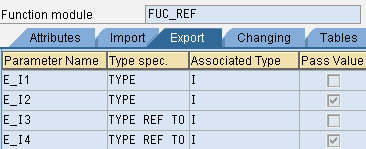
*" EXPORTING
*" REFERENCE(E_I1) TYPE I
*" VALUE(E_I2) TYPE I
*" REFERENCE(E_I3) TYPE REF TO I
*" VALUE(E_I4) TYPE REF TO I
*" TABLES
*" T_1 TYPE ZJZJ_ITAB
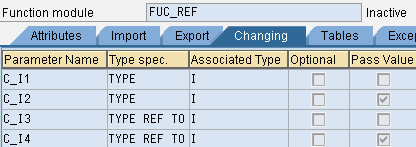
*" CHANGING
*" REFERENCE(C_I1) TYPE I
*" VALUE(C_I2) TYPE I
*" REFERENCE(C_I3) TYPE REF TO I
*" VALUE(C_I4) TYPE REF TO I
*"-------------------------------------------------------------------
write: / i_i1."1
"由于i_i1为输入类型参数,且又是引用类型,实参不能被修改。这里i_i1是以C++中的引用(别名)参数方式传递参数,所以如果修改了i_i1就会修改实际参数,所以函数中不能修改REFERENCE 的 IMPORTING类型的参数,如果去掉下面注释则编译出错
"i_i1 = 10.
write: / i_i2."2
"虽然i_i2是输入类型的参数,但不是引用类型,所以可以修改,编译能通过但不会修改外面实参的值,只是修改了该函数局部变量的值
i_i2 = 20.
field-symbols:
assign i_i3->* to
"由于i_i3存储的是地址,所以先要解引用再能使用
write: /
"同上面,REFERENCE的IMPORTING类型的参数不能被修改:这里即不能修改实参的指向"GET REFERENCE OF 30 INTO i_i3."虽然不可以修改实参的指向,但可以修改实参所指向的实际内容
assign i_i4->* to
"i_i4存储也的是地址,所以先要解引用再能使用
write: /
"虽然i_i4是输入类型的参数,但不是引用类型,所以可以修改,只会修改函数中的局部参数i_i4的指向,但并不会修改实参的指向
get reference of 40 into i_i4.
"虽然不能修改实参的指向,但可以直接修改实参的所指向的实际内容
WRITE: / c_i1."111
"c_i1为实参的别名,修改形参就等于修改实参内容
c_i1 = 1110.
WRITE: / c_i2."222
"c_i2为实参的副本,所以不会影响实参的内容,但是,由于是CHANGING类型的参数,且为值传递,在函数正常执行完后,还是会将该副本再次拷贝给实参,所以最终实参还是会被修改
c_i2 = 2220.
ENDFUNCTION.
调用程序:
DATA: i_i1 TYPE i VALUE 1,
i_i2 TYPE i VALUE 2,
i_i3 TYPE REF TO i ,
i_i4 TYPE REF TO i ,
c_i1 TYPE i VALUE 111,
c_i2 TYPE i VALUE 222,
c_i3 TYPE REF TO i ,
c_i4 TYPE REF TO i ,
t_1 TYPE zjzj_itab WITH HEADER LINE.
DATA: i_i3_ TYPE i VALUE 3.
GET REFERENCE OF i_i3_ INTO i_i3.
DATA: i_i4_ TYPE i VALUE 4.
GET REFERENCE OF i_i4_ INTO i_i4.
DATA: c_i3_ TYPE i VALUE 333.
GET REFERENCE OF c_i3_ INTO c_i3.
DATA: c_i4_ TYPE i VALUE 444.
GET REFERENCE OF c_i4_ INTO c_i4.
CALL FUNCTION 'FUC_REF'
EXPORTING
i_i1 = i_i1
i_i2 = i_i2
i_i3 = i_i3
i_i4 = i_i4
TABLES
t_1 = t_1
CHANGING
c_i1 = c_i1
c_i2 = c_i2
c_i3 = c_i3
c_i4 = c_i4.
WRITE: / i_i2."2
WRITE: / i_i3_."30
WRITE: / i_i4_."400
WRITE: / c_i1."1110
WRITE: / c_i2."2220
1.11. 字段符号FIELD-SYMBOLS
字段符号可以看作仅是已经被解引用的指针(类似于C语言中带有解引用操作符 * 的指针),但更像是C++中的引用类型(int i ;&ii= i;),即某个变量的别名,它与真正的指针还是有很大的区别的,在ABAP中引用变量(通过TYPE REF TO定义的变量)才好比C语言中的指针
ASSIGN ... TO
1.11.1.ASSIGN隐式强转
TYPES: BEGIN OF t_date,
year(4) TYPE n,
month(2) TYPE n,
day(2) TYPE n,
END OF t_date.
FIELD-SYMBOLS
ASSIGN sy-datum TO
1.11.2.ASSIGN显示强转
DATA txt(8) TYPE c VALUE '19980606'.
FIELD-SYMBOLS
ASSIGN txt TO
1.11.3.ASSIGN 动态分配
请参考动态语句à ASSIGN 动态分配
1.11.4.UNASSIGN、CLEAR
UNASSIGN:该语句是初始化
CLEAR:与UNASSIGN不同的是,只有一个作用就是初始化它所指向的内存区域,而不是解除分配
1.12.数据引用、对象引用
TYPE REF TO data 数据引用data references
TYPE REF TO object 对象引用object references
除了object,所有的通用类型都能直接用TYPE后面(如TYPE data,但没有TYPE object,object不能直接跟在TYPE后面,只能跟在TYPE REF TO后面)
TYPE REF TO 后面可接的通用类型只能是data(数据引用)或者是object(对象引用)通用类型,其他通用类型不行
1.12.1.数据引用Data References
DATA: dref TYPE REF TO i ."dref即为数据引用,即数据指针,指向某个变量或常量,存储变量地址
CREATE DATA dref.
dref->* = 2147483647."可直接解引用使用,不需要先通过分配给字段符号后再使用
DATA: BEGIN OF strct,
c,
END OF strct.
DATA: dref LIKE REF TO strct .
CREATE DATA dref .
dref->*-c = 'A'.
TYPES: tpy TYPE c.
DATA: c1 TYPE REF TO tpy.
DATA: c2 LIKE REF TO c1."二级指针
GET REFERENCE OF 'a' INTO c1.
GET REFERENCE OF c1 INTO c2.
WRITE: c2->*->*."a
1.12.2.对象引用Object references
CLASS cl DEFINITION.
PUBLIC SECTION.
DATA: i VALUE 1.
ENDCLASS.
CLASS cl IMPLEMENTATION.
ENDCLASS.
DATA: obj TYPE REF TO cl.
CREATE OBJECT obj. "创建对象
DATA: oref LIKE REF TO obj. "oref即为对象引用,即对象指针,指向某个对象,存储对象地址
GET REFERENCE OF obj INTO oref. "获取对象地址
WRITE: oref->*->i."1
1.12.3.GET REFERENCE OF获取变量/对象/常量地址
DATA: e_i3 TYPE REF TO i .
GET REFERENCE OF 33 INTO e_i3.
WRITE: e_i3->*."33
"但不能修改常量的值
"e_i3->* = 44.
DATA: i TYPE i VALUE 33,
dref LIKE REF TO i."存储普通变量的地址
GET REFERENCE OF i INTO dref.
dref->* = 44.
WRITE: i. "44
1.13.动态语句
1.13.1.内表动态访问
SORT itab BY (comp1)...(compn)
READ TABLE itab WITH KEY(k1)=v1...(kn)=vn
READ TABLE itab...INTOwaCOMPARING(comp1)...(compn) TRANSPORTING(comp1)...
MODIFY [TABLE] itab TRANSPORTING(comp1)...(compn)
DELETE TABLEitabWITH TABLE KEY(comp1)...(compn)
DELETE ADJACENT DUPLICATES FROM itab COMPARING(comp1)...(compn)
AT NEW/END OF (comp)
1.13.2.动态类型
CREATE DATA ... TYPE (type)...
DATA: a TYPE REF TO i.
CREATE DATA a TYPE ('I').
a->* = 1.
CREATE OBJECT ... TYPE (type)...请参考类对象反射章节
1.13.3.动态SQL
Select请参照后面的动态SQL
MODIFY/UPDATE(dbtab)...
1.13.4.动态调用类的方法
CALL METHOD (meth_name)
| cref->(meth_name)
| iref->(meth_name)
| (class_name)=>(meth_name)
| class=>(meth_name)
| (class_name)=>meth
实例请参考类对象反射章节
1.13.5.ASSIGN 动态分配
FIELD-SYMBOLS:
DATA:str(20) TYPE c VALUE 'Output String',
name(20) TYPE c VALUE 'STR'.
"静态分配:编译时就知道要分配的对象名
ASSIGN name TO
"通过变量名动态访问变量
ASSIGN (name) TO
DATA: BEGIN OF line,
col1 TYPE i VALUE '11',
col2 TYPE i VALUE '22',
col3 TYPE i VALUE '33',
END OF line.
DATA comp(5) VALUE 'COL3'.
FIELD-SYMBOLS:
ASSIGN line TO
ASSIGN comp TO
"还可以直接使用以下的语法访问其他程序中的变量
ASSIGN ('(ZJDEMO)SBOOK-FLDATE') TO
"通过索引动态的访问结构成员
ASSIGN COMPONENT sy-index OF STRUCTURE
"通过字段名动态的访问结构成员
ASSIGN COMPONENT
"如果定义的内表没有组件名时,可以使用索引为0的组件来访问这个无名字段(注:不是1)
ASSIGN COMPONENT 0 OF STRUCTURE itab TO
1.13.5.1.动态访问类的属性成员
ASSIGN oref->('attr') TO
ASSIGN oref->('static_attr') TO
ASSIGN ('C1')=>('static_attr') TO
ASSIGN c1=>('static_attr') TO
ASSIGN ('C1')=>static_attr TO
实例请参考类对象反射章节
1.14.反射
CL_ABAP_TYPEDESCR
|--CL_ABAP_DATADESCR
| |--CL_ABAP_ELEMDESCR
| |--CL_ABAP_REFDESCR
| |--CL_ABAP_COMPLEXDESCR
| |--CL_ABAP_STRUCTDESCR
| |--CL_ABAP_TABLEDESCR
|--CL_ABAP_OBJECTDESCR
|--CL_ABAP_CLASSDESCR
|--CL_ABAP_INTFDESCR
DATA: structtype TYPE REF TO cl_abap_structdescr.
structtype ?= cl_abap_typedescr=>describe_by_name( 'spfli' ).
*COMPDESC-TYPE ?= CL_ABAP_DATADESCR=>DESCRIBE_BY_NAME( 'EKPO-MATNR' ).
DATA: datatype TYPE REF TO cl_abap_datadescr,
field(5) TYPE c.
datatype ?= cl_abap_typedescr=>describe_by_data( field ).
DATA: elemtype TYPE REF TO cl_abap_elemdescr.
elemtype = cl_abap_elemdescr=>get_i( ).
elemtype = cl_abap_elemdescr=>get_c( 20 ).
DATA: oref1 TYPE REF TO object.
DATA: descr_ref1 TYPE REF TO cl_abap_typedescr.
CREATE OBJECT oref1 TYPE ('C1'). "C1为类名
descr_ref1 = cl_abap_typedescr=>describe_by_object_ref( oref1 ).
还有一种:describe_by_data_ref
1.14.1.TYPE HANDLE
handle只能是CL_ABAP_DATADESCR或其子类的引用变量,注:只能用于Data类型,不能用于Object类型,即不能用于CL_ABAP_ OBJECTDESCR,所以没有:
CREATE OBJECT dref TYPE HANDLE objectDescr.
DATA: dref TYPE REF TO data,
c10type TYPE REF TO cl_abap_elemdescr.
c10type = cl_abap_elemdescr=>get_c( 10 ).
CREATE DATA dref TYPE HANDLE c10type.
DATA: x20type TYPE REF TO cl_abap_elemdescr.
x20type = cl_abap_elemdescr=>get_x( 20 ).
FIELD-SYMBOLS:
ASSIGN dref->* TO
1.14.2.动态创建数据Data或对象Object
TYPES: ty_i TYPE i.
DATA: dref TYPE REF TO ty_i .
CREATE DATA dref TYPE ('I')."根据基本类型名动态创建数据
dref->* = 1.
WRITE: / dref->*." 1
CREATE OBJECT oref TYPE ('C1')."根据类名动态创建实例对象
1.14.3.动态创建基本类型变量、结构、内表
DATA: dref_str TYPE REF TO data,
dref_tab TYPE REF TO data,
dref_i TYPE REF TO data,
itab_type TYPE REF TO cl_abap_tabledescr,
struct_type TYPE REF TO cl_abap_structdescr,
elem_type TYPE REF TO cl_abap_elemdescr,
table_type TYPE REF TO cl_abap_tabledescr,
comp_tab TYPE cl_abap_structdescr=>component_table WITH HEADER LINE.
FIELD-SYMBOLS :
**=========动态创建基本类型
elem_type ?= cl_abap_elemdescr=>get_i( ).
CREATE DATA dref_i TYPE HANDLE elem_type ."动态的创建基本类型数据对象
**=========动态创建结构类型
struct_type ?= cl_abap_typedescr=>describe_by_name( 'SFLIGHT' )."结构类型
comp_tab[] = struct_type->get_components( )."组成结构体的各个字段组件
* 向结构中动态的新增一个成员
comp_tab-name = 'L_COUNT'."为结构新增一个成员
comp_tab-type = elem_type."新增成员的类型对象
INSERT comp_tab INTO comp_tab INDEX 1.
* 动态创建结构类型对象
struct_type = cl_abap_structdescr=>create( comp_tab[] ).
CREATE DATA dref_str TYPE HANDLE struct_type."使用结构类型对象来创建结构对象
**=========动态创建内表
* 基于结构类型对象创建内表类型对象
itab_type = cl_abap_tabledescr=>create( struct_type ).
CREATE DATA dref_tab TYPE HANDLE itab_type."使用内表类型对象来创建内表类型
ASSIGN dref_tab->* TO
"**========给现有的内表动态的加一列
table_type ?= cl_abap_tabledescr=>describe_by_data( itab ).
struct_type ?= table_type->get_table_line_type( ).
comp_tab[] = struct_type->get_components( ).
comp_tab-name = 'FIDESC'.
comp_tab-type = cl_abap_elemdescr=>get_c( 120 ).
INSERT comp_tab INTO comp_tab INDEX 2.
struct_type = cl_abap_structdescr=>create( comp_tab[] ).
itab_type = cl_abap_tabledescr=>create( struct_type ).
CREATE DATA dref_tab TYPE HANDLE itab_type.
1.14.4.类对象反射
CLASS c1 DEFINITION.
PUBLIC SECTION.
DATA: c VALUE 'C'.
METHODS: test.
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD:test.
WRITE:/ 'test'.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
TYPES: ty_c.
DATA: oref TYPE REF TO object .
DATA: oref_classdescr TYPE REF TO cl_abap_classdescr .
CREATE OBJECT oref TYPE ('C1')."根据类名动态创建实例对象
"相当于Java中的Class类对象
oref_classdescr ?= cl_abap_classdescr=>describe_by_object_ref( oref ).
DATA: t_attrdescr_tab TYPE abap_attrdescr_tab WITH HEADER LINE,"类中的属性列表
t_methdescr_tab TYPE abap_methdescr_tab WITH HEADER LINE."类中的方法列表
FIELD-SYMBOLS
t_attrdescr_tab[] = oref_classdescr->attributes.
t_methdescr_tab[] = oref_classdescr->methods.
LOOP AT t_attrdescr_tab."动态访问类中的属性
ASSIGN oref->(t_attrdescr_tab-name) TO
WRITE: /
ENDLOOP.
LOOP AT t_methdescr_tab."动态访问类中的方法
CALL METHOD oref->(t_methdescr_tab-name).
ENDLOOP.
![]()
2.面向对象
2.1. 类与接口定义
CLASS class DEFINITION [ABSTRACT][FINAL].
[PUBLIC SECTION.
[components]]
[PROTECTED SECTION.
[components]]
[PRIVATE SECTION.
[components]]
ENDCLASS.
INTERFACE intf.
[components]
ENDINTERFACE.
2.1.1. components
²TYPES, DATA, CLASS-DATA, CONSTANTS for data types and data objects
²METHODS, CLASS-METHODS, EVENTS, CLASS-EVENTS for methods and events
² INTERFACES(如果在类中,表示需要实现哪个接口;如果是在接口中,表示继承哪个接口) for implementing interfaces
² ALIASESfor alias names for interface components给接口组件取别名
2.2.类定义、实现
CLASS math DEFINITION.
PUBLIC SECTION.
METHODS divide_1_by
IMPORTING operand TYPE i
EXPORTING result TYPE f
RAISING cx_sy_arithmetic_error.
ENDCLASS.
CLASS math IMPLEMENTATION.
METHOD divide_1_by.
result = 1 / operand.
ENDMETHOD.
ENDCLASS.
2.3.接口定义、实现
INTERFACEint1.
ENDINTERFACE.
CLASSclass DEFINITION. [ˌdefiˈniʃən]
PUBLICSECTION.
INTERFACES: int1,int2."可实现多个接口
ENDCLASS.
CLASS class IMPLEMENTATION. [ˌɪmplɪmənˈteɪ-ʃən]
METHOD intf1~imeth1.
ENDMETHOD.
ENDCLASS.
2.4.类、接口继承
CLASS
INTERFACE i0.
METHODS m0.
ENDINTERFACE.
INTERFACE i1.
INTERFACES i0.
"可以有相同的成员名,因为继承过来后,成员还是具有各自的命名空间,在实现时
"被继承过来的叫 i0~m0,在这里的名为i1~m0,所以是不同的两个方法
METHODS m0.
METHODS m1.
ENDINTERFACE.
2.5. 向下强转型 ?=
CLASS person DEFINITION.
ENDCLASS.
CLASS stud DEFINITION INHERITING FROMperson.
ENDCLASS.
START-OF-SELECTION.
DATA p TYPE REF TO person.
DATA s TYPE REF TO stud.
CREATE OBJECT s.
p = s. "向上自动转型
"拿开注释运行时抛异常,因为P此时指向的对象不是Student,而是Person所以能强转的前提是P指向的是Student
"CREATE OBJECT p.
s ?= p."向下强转型
2.6. 方法
METHODS/CLASS-METHODS meth [ABSTRACT|FINAL]
[IMPORTING parameters [PREFERRED PARAMETER p]]
[EXPORTING parameters]
[CHANGING parameters]
[{RAISING|EXCEPTIONS} exc1 exc2 ...].
应该还有一个Returning选项,且RETURNING不能与EXPORTING、CHANGING同时使用:
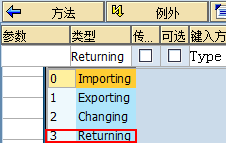
2.6.1.parameters
... { VALUE(p1) | REFERENCE(p1) | p1 }
{ TYPE generic_type }
|{TYPE{[LINE OF] complete_type}|{REF TO {data|object|complete_type |class|intf}}}
|{LIKE{[LINE OF] dobj}|{REF TO dobj} }
[OPTIONAL|{DEFAULT def1}]
{ VALUE(p2) | REFERENCE(p2) | p2 }...
²data、object:表示是通用数据类型data、object
²complete_type:为完全限定类型
²OPTIONAL与DEFAULT两个选项不能同时使用,且对于EXPORTING类型的输入参数不能使用
²如果参数名p1前没有使用VALUE、REFERENCE,则默认为还是REFERENCE,即引用传递
²方法中的输入输出参数是否能修改,请参考Form、Function参数的传值传址
2.6.2. PREFERRED PARAMETER首选参数
设置多个IMPORTING类型参数中的某一个参数为首选参数。
首选参数的意义在于:当所有IMPORTING类型都为可选optional时,我们可以通过PREFERRED PARAMETER选项来指定某一个可选输入参数为首选参数,则在以下简单方式调用时:[CALL METHOD] meth( a ). 实参a的值就会传递给设置的首选参数,而其他不是首参数的可选输入参数则留空或使用DEFAULT设置的默认值
注:此选项只能用于IMPORTING类型的参数;如果有必选的IMPORTING输入参数,则没有意义了
2.6.3. 普通调用
[CALL METHOD] meth|me->meth|oref->meth|super->meth|class=>meth[(]
[EXPORTING p1 = a1 p2 = a2 ...]
{ {[IMPORTING p1=a1 p2=a2 ...][CHANGING p1 = a1 p2 = a2 ...]}
|[RECEIVING r = a ] } RECEIVING不能与EXPORTING、CHANGING同时使用
[EXCEPTIONS [exc1 = n1 exc2 = n2 ...]
[OTHERS = n_others] ] [)].
如果省略CALL METHOD,则一定要加上括号形式;如果通过CALL METHOD来调用,则括号可加可不加
RECEIVING:用来接收METHODS /CLASS-METHODS 中RETURNING选项返回的值
如果EXPORTING、IMPORTING、CHANGING、RECEIVING、EXCEPTIONS、OTHERS同时出现时,应该按此顺序来编写
注:使用此种方式调用(使用 EXPORTING、IMPORTING等这些选项)时,如果原方法声明时带了返回值RETURNING,只能使用RECEIVING来接受,而不能使用等号来接收返回值,下面用法是错误的:
num2 = o1->m1( EXPORTING p1 = num1 ).
2.6.4. 简单调用
此方式下输入的参数都只能是IMPORTING类型的参数,如果要传CHANGING、EXPORTING、RAISING、EXCEPTIONS类型的参数时,只能使用上面通用调用方式。
²meth( )
此种方式仅适用于没有输入参数(IMPORTING)、输入\输出参数(CHANGING)、或者有但都是可选的、或者不是可选时但有默认值也可
²meth( a )
此种方式仅适用于只有一个必选输入参数(IMPORTING)(如果还有其他输入参数,则其他都为可选,或者不是可选时但有默认值也可),或者是有多个可选输入参数(IMPORTING)(此时没有必选输入参数情况下)的情况下但方法声明时通过使用PREFERRED PARAMETER选项指定了其中某个可选参数为首选参数(首选参数即在使用meth( a )方式传递一个参数进行调用时,通过实参a传递给设置为首选的参数)
²meth( p1 = a1 p2 = a2 ... )
此种方式适用于有多个必选的输入参数(IMPORTING)方法的调用(其它如CHANGING、EXPORTING没有,或者有但可选),如果输入参数(IMPORTING)为可选,则也可以不必传
2.6.5.函数方法
Return唯一返回值
METHODS meth
[IMPORTING parameters [PREFERRED PARAMETER p]]
RETURNINGVALUE(r) typing
[{RAISING|EXCEPTIONS} exc1 exc2 ...].
RETURNING :用来替换EXPORTING、CHANGING,不能同时使用。定义了一个形式参数 r 来接收返回值,并且只能是值传递
具有唯一返回值的函数方法可以直接用在以下语句中:逻辑表达式(IF、ELSEIF、WHILE、CHECK、WAIT)、CASE、LOOP、算术表达式、赋值语句
函数方法可以采用上面简单调用方式来调用:meth( )、meth( a )、meth( p1 = a1 P2 = a2 ... )
ref->m( RECEIVING r = i ).
CALL METHOD ref->m( RECEIVING r = i ).
CALL METHOD ref->m RECEIVING r = i.
2.7.me、super
等效于Java中的 this、super
2.8. 事件
2.8.1. 事件定义
EVENTS|CLASS-EVENTS evt [EXPORTING VALUE(p1)
{ TYPE generic_type }
|{TYPE {[LINE OF] complete_type} |
{ REF TO {data|object|complete_type|class|intf}} }
| {LIKE{[LINE OF] dobj} | {REF TO dobj} }
[OPTIONAL|{DEFAULT def1}]
VALUE(p2) ...].
²data、object:表示是通用数据类型data、object
²complete_type:为完全限定类型
² OPTIONAL与DEFAULT两个选项不能同时使用
²EXPORTING:定义了事件的输出参数,并且事件定义时只能有输出参数,且只能是传值
非静态事件声明中除了明确使用EXPORTING定义的输出外,每个实例事件其实还有一个隐含的输出参数sender,它指向了事件源对象,当使用RAISE EVENT语句触发一个事件时,事件源的对象就会分配给这个sender引用,但是静态事件没有隐含参数sender
事件evt的定义也是在类或接口的定义部分进行定义的
非静态事件只能在非静态方法中触发,而不能在静态方法中触发;而静态事件即可在静态也可在非静态方法中进行触发,或者反过来说:实例方法既可触发静态事件,也可触发非静态事件,但静态方法就只能触发静态事件
2.8.2. 事件触发
RAISE EVENT evt [EXPORTING p1 = a1 p2 = a2 ...].
该语句只能在定义evt事件的同一类或子类,或接口实现方法中进行调用
当实例事件触发时,如果在event handler事件处理器声明语句中指定了形式参数sender,则会自动接收事件源,但不能在RAISE EVENT …EXPORTING语句中明确指定,它会自动传递(如果是静态事件,则不会传递sender参数)
CLASS c1 DEFINITION.
PUBLIC SECTION.
EVENTS e1 EXPORTING value(p1) TYPE string value(p2) TYPE i OPTIONAL. "定义
METHODS m1.
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD m1.
RAISE EVENT e1 EXPORTING p1 = '...'."触发
ENDMETHOD.
ENDCLASS.
2.8.3.事件处理器Event Handler
静态或非静态事件处理方法都可以处理静态或非静态事件,与事件的静态与否没有直接的关系
INTERFACE window. "窗口事件接口
EVENTS: minimize EXPORTINGVALUE(status) TYPE i."最小化事件
ENDINTERFACE.
CLASS dialog_window DEFINITION. "窗口事件实现
PUBLIC SECTION.
INTERFACES window.
ENDCLASS.
INTERFACE window_handler. "窗口事件处理器接口
METHODS: minimize_window FOR EVENT window~minimize OF dialog_window
IMPORTING status sender. "事件处理器方法参数要与事件接口定义中的一致
ENDINTERFACE.
2.8.4. 注册事件处理器
实例事件处理器(方法)注册(注:被注册的方法只能是用来处理非静态事件的方法):
SET HANDLER handler1 handler2 ... FOR oref|{ALL INSTANCES}[ACTIVATION act].
静态事件处理器(方法)注册(注:被注册的方法只能是用来处理静态事件的方法):
SET HANDLER handler1 handler2 ... [ACTIVATION act].
oref:只将事件处理方法handler1 handler2注册到 oref 这一个事件源对象
ALL INSTANCES:将事件处理方法注册到所有的事件源实例中
ACTIVATION act:表示是注册还是注销
2.8.5. 示例
CLASS c1 DEFINITION."事件源
PUBLIC SECTION.
EVENTS: e1 EXPORTING value(p1) TYPE c,e2.
CLASS-EVENTS ce1 EXPORTING value(p2) TYPE i.
METHODS:trigger."事件触发方法
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD trigger.
RAISE EVENT: e1 EXPORTING p1 = 'A',e2,ce1 EXPORTING p2 = 1.
ENDMETHOD.
ENDCLASS.
静态(如下面的h1方法)或非静(如下面的h2方法)态事件处理方法都可以处理静态或非静态事件,事件的处理方法是否只能处理静态的还是非静态事件与事件的静态与否没有关系,但事件的触发方法与事件的静态与否有关系(实例方法既可触发静态事件,也可触发非静态事件,但静态方法就只能触发静态事件);但是,事件处理方法虽然能处理的事件与事件的静态与否没有关系,但如果处理的是静态事件,那此处理方法就成为了静态处理器,只能采用静态注册方式对此处理方法进行注册。如果处理的是非静态事件,那此处理方法就是非静态处理器,只能采用非静态注册方式对此处理方法进行注册
处理器的静态与否与处理方法本身是否静态没有关系,只与处理的事件是否静态有关
CLASS c2 DEFINITION."监听器:即事件处理器
PUBLIC SECTION.
"静态方法也可以处理非静态事件,此方法属于非静态处理器,只能采用非静态注册方式
CLASS-METHODS h1 FOR EVENT e1 OF c1 IMPORTING p1 sender.
"非静态方法处理非静态事件,此方法属于非静态处理器,只能采用非静态注册方式
METHODS: h2 FOR EVENT e2 OF c1 IMPORTING sender,
"非静态方法当然更可以处理静态事件,此方法属于静态处理器,只能采用静态注册方式
h3 FOR EVENT ce1 OF c1 IMPORTING p2.
ENDCLASS.
CLASS c2 IMPLEMENTATION.
METHOD h1 .
WRITE: 'c2=>h1'.
ENDMETHOD.
METHOD: h2.
WRITE: 'c2->h2'.
ENDMETHOD.
METHOD: h3.
WRITE: 'c2->h3'.
ENDMETHOD.
ENDCLASS.
DATA: trigger TYPE REF TO c1,
trigger2 TYPE REF TO c1,
handler TYPE REF TO c2.
START-OF-SELECTION.
CREATE OBJECT trigger.
CREATE OBJECT trigger2.
CREATE OBJECT handler.
"由于h1、h2两个处理方法分别是用来处理非静态事件e1、e2的,所以只能采用实例注册方式
SET HANDLER: c2=>h1 handler->h2 FOR trigger,
"h3处理方法是用来处理静态事件ce1的,属于静态处理器,所以只能采用静态注册方式
handler->h3.
trigger->trigger( ).
"虽然trigger( )方法会触发 e1,e2,ce1 三种事件,但h1、h2未向实例trigger2注册,而h3属于静态处理器,与实例无关,即好比向所有实例注册过了一样
trigger2->trigger( ).

3. 内表
3.1.LOOP AT循环内表
LOOP AT itab {INTO wa}|{ASSIGNING
[[USING KEY key_name|(name)] [FROM idx1] [TO idx2] [WHERE log_exp|(cond_syntax)]].
ENDLOOP.
FROM … TO: 只适用于标准表与排序表 WHERE … : 适用于所有类型的内表
如果没有通过USING KEY选项的key_name,则循环读取的顺序与表的类型相关:
l标准表与排序表:会按照primary table index索引的顺序一条条的循环,且在循环里SY-TABIX为当前正在处理行的索引号
l 哈希表:由于表没有排序,所以按照插入的顺序来循环处理,注,此时SY-TABIX 总是0
可以在循环内表时增加与删除当前行:If you insert or delete lines in the statement block of a LOOP , this will have the following effects:
- If you insert lines behind(后面) the current line, these new lines will be processed in the subsequent loop(新行会在下一次循环时被处理) passes. An endless loop(可能会引起死循环)can result
- If you delete lines behind the current line, the deleted lines will no longer be processed in the subsequent loop passes
- If you insert lines in front(前面) of the current line, the internal loop counter is increased by one with each inserted line. This affects sy-tabix in the subsequent loop pass(这会影响在随后的循环过程SY-TABIX)
- If you delete lines in front of the current line, the internal loop counter is decreased by one with each deleted line. This affects sy-tabix in the subsequent loop pass
3.1.1.循环中删除行
DATA : BEGIN OF gt_table OCCURS 0,
c,
END OF gt_table.
APPEND 'a' TO gt_table.
APPEND 'b' TO gt_table.
APPEND 'c' TO gt_table.
APPEND 'd' TO gt_table.
APPEND 'e' TO gt_table.
APPEND 'f' TO gt_table.
APPEND 'g' TO gt_table.
APPEND 'h' TO gt_table.
LOOP AT gt_table .
IF gt_table-c = 'b' OR gt_table-c = 'c' OR gt_table-c = 'e'.
WRITE : / sy-tabix COLOR = 6 INTENSIFIED ON INVERSE OFF ,
gt_table COLOR = 6 INTENSIFIED ON INVERSE OFF .
ELSE.
WRITE : / sy-tabix, gt_table.
ENDIF.
ENDLOOP.
SKIP 2.
DATA count TYPE i .
LOOP AT gt_table .
count = count + 1.
"当循环到第三次时删除,即循环到 C 时进行删除
IF count = 3.
DELETE gt_table WHERE c = 'b' OR c = 'c' OR c = 'e'.
ENDIF.
"删除之后sy-tabix会重新开始对内表现有的行进行编号
WRITE :/ sy-tabix, gt_table.
ENDLOOP.
SKIP 2.
LOOP AT gt_table .
WRITE : / sy-tabix, gt_table.
ENDLOOP.

3.1.2.SUM
如果在 AT - ENDAT 块中使用 SUM,则系统计算当前行组中所有行的数字字段之和并将其写入工作区域中相应的字段中
3.1.3. AT...ENDAT
| |
含义 |
| FIRST |
内表的第一行时触发 |
| LAST |
内表的最后一行时触发 |
| NEW |
相邻数据行中相同 |
| END Of |
相邻数据行中相同 |
在使用AT...... ENDAT之前,一这要先按照这些语句中的组件名进行排序,且排序的顺序要与在AT...... ENDAT语句中使用顺序一致,排序与声明的顺序决定了先按哪个分组,接着再按哪个进行分组,最后再按哪个进行分组,这与SQL中的Group By 相似
用在AT...... ENDAT语句中的中的组件名不一定要是结构中的关键字段,但这些字段一定要按照出现在AT关键字后面的使用顺序在结构最前面进行声明,且这些组件字段的声明之间不能插入其他组件的声明。如现在需要按照
LOOP AT
AT FIRST. ... ENDAT.
AT NEW
AT NEW
.......
.......
AT END OF
AT END OF
AT LAST. .... ENDAT.
ENDLOOP.
一旦进入到 AT...
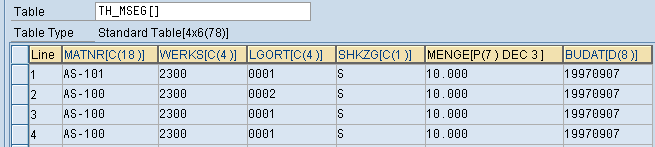
DATA: BEGIN OF th_mseg OCCURS 10,
matnr TYPE mard-matnr, werks TYPE mard-werks,
lgort TYPE mard-lgort, shkzg TYPE mseg-shkzg,
menge TYPE mseg-menge, budat TYPE mkpf-budat,
LOOP AT th_mseg.
AT END OF shkzg."会根据shkzg及前面所有字段来进行分组
sum.
WRITE: / th_mseg-matnr, th_mseg-werks,th_mseg-lgort,
th_mseg-shkzg,th_mseg-menge,th_mseg-budat.
ENDAT.
ENDLOOP.
AS-101 2300 0001 S 10.000 ****.**.**
AS-100 2300 0002 S 10.000 ****.**.**
AS-100 2300 0001 S 20.000 ****.**.**
上面由于没有根据matnr + werks + lgort + shkzg 进行排序,所以结果中的第三行其实应该与第一行合并。其实这个统计与SQL里的分组(Group By)统计原理是一样的,Group By 后面需要明确指定分组的字段,如上面程序使用SQL分组写法应该为 Group Bymatnr werks lgort shkzg,但在ABAP里你只需要按照 matnr werks lgort shkzg按照先后顺序在结构定义的最前面进行声明就可表达了Group By那种意义,而且不一定要将matnr werks lgort shkzg这四个字段全部用在AT语句块中AT NEW、AT END OF shkzg 才正确,其实像上面程序一样,只写AT END OF shkzg这一个语句,前面三个字段matnr werks lgort都可以不用在AT语句中出现,因为ABAP默认会按照结构中声明的顺序将shkzg前面的字段也全都用在了分组中了
DATA: BEGIN OF line,
"C2、C3组件名声明的顺序一定要与在AT...... ENDAT块中使用的次序一致,即这里不能将C3声明在C2之前,且不能在C2与C3之间插入其他字段的声明
c2(5) TYPE c,
c3(5) TYPE c,
c4(5) TYPE c,
i1 TYPE i,
i2 TYPE i,
c1(5) TYPE c,
END OF line.
"使用在AT...... ENDAT语句中的字段不一定要是关键字段
DATA: itab LIKE TABLE OF line WITH HEADER LINE WITH NON-UNIQUE KEY i1.
PERFORM append USING 2 'b' 'bb' 'bbb' '2222' 22.PERFORM append USING 3 'c' 'aa' 'aaa' '3333' 33.
PERFORM append USING 4 'd' 'aa' 'bbb' '4444' 44.PERFORM append USING 5 'e' 'bb' 'aaa' '5555' 55.
PERFORM append USING 6 'f' 'bb' 'bbb' '6666' 66.PERFORM append USING 7 'g' 'aa' 'aaa' '7777' 77.
PERFORM append USING 8 'h' 'aa' 'bbb' '8888' 88.
SORT itab ASCENDING BY c2 c3.
LOOP AT itab.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
ENDLOOP.
SKIP.
LOOP AT itab.
AT FIRST.
WRITE:/ '>>>> AT FIRST'.
ENDAT.
AT NEW c2.
WRITE: / ' >>>> Start of' , itab-c2.
ENDAT.
AT NEW c3.
WRITE: / ' >>>> Start of' , itab-c2, itab-c3.
ENDAT.
"只要一出 AT 块,则表头的数据又会恢复成当前被遍历行的内容
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
AT END OF c3.
SUM.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
WRITE: / ' <<<< End of' , itab-c2, itab-c3.
ENDAT.
AT END OF c2.
SUM.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
WRITE: / ' <<<< End of' , itab-c2.
ENDAT.
AT LAST.
SUM.
WRITE: / itab-c2,itab-c3,itab-c1,itab-c4,itab-i1,itab-i2.
WRITE:/ '<<<< AT LAST'.
ENDAT.
ENDLOOP.
TYPES: c5(5) TYPE c.
FORM append USING value(p_i1) TYPE Ivalue(p_c1) TYPE c5 value(p_c2) TYPE c5
value(p_c3) TYPE c5 value(p_c4) TYPE c5 value(p_i2) TYPE i.
itab-i1 = p_i1. itab-c1 = p_c1. itab-c2 = p_c2.
itab-c3 = p_c3. itab-c4 = p_c4. itab-i2 = p_i2.
APPEND itab.
ENDFORM.
aa aaa c 3333 3 33
aa aaa g 7777 7 77
aa bbb d 4444 4 44
aa bbb h 8888 8 88
bb aaa a 1111 1 11
bb aaa e 5555 5 55
bb bbb b 2222 2 22
bb bbb f 6666 6 66
>>>> AT FIRST
>>>> Start of aa
>>>> Start of aa aaa
aa aaa c 3333 3 33
aa aaa g 7777 7 77
aa aaa ***** ***** 10 110
<<<< End of aa aaa
>>>> Start of aa bbb
aa bbb d 4444 4 44
aa bbb h 8888 8 88
aa bbb ***** ***** 12 132
<<<< End of aa bbb
aa ***** ***** ***** 22 242
<<<< End of aa
>>>> Start of bb
>>>> Start of bb aaa
bb aaa a 1111 1 11
bb aaa e 5555 5 55
bb aaa ***** ***** 6 66
<<<< End of bb aaa
>>>> Start of bb bbb
bb bbb b 2222 2 22
bb bbb f 6666 6 66
bb bbb ***** ***** 8 88
<<<< End of bb bbb
bb ***** ***** ***** 14 154
<<<< End of bb
***** ***** ***** ***** 36 396
<<<< AT LAST
3.1.4.自已实现AT...ENDAT
如果循环的内表不是自己定义的,有时无法将分组的字段按顺序声明在一起,所以需要自己实现这些功能,下面是自己实现AT NEW与AT END OF(另一好处是在循环内表时可以使用Where条件语句)(注:使用这种只需要按照分组的顺序排序即可,如要分成bukrs与bukrs anlkl两组时,需要按照BY bukrs anlkl排序,而不能是BYanlkl bukrs):
DATA: lp_bukrs TYPE bukrs, "上一行bukrs字段的值
lp_anlkl TYPE anlkl. "上一行anlkl字段的值
"下面假设按bukrs,bukrs anlkl分成两组
SORT itab_data BY bukrs anlkl.
DATA: i_indx TYPE i .
DATA: lwa_data Like itab_data
LOOP AT itab_data where flg = 'X'.
i_indx = sy-tabix.
"**********AT NEW 对当前分组首行进行处理
IF itab_data-bukrs <> lp_bukrs. "Bukrs组
".........
ENDIF.
IF itab_data-bukrs <> lp_bukrs OR itab_data-anlkl <> lp_anlkl. "bukrs anlkl 分组
".........
ENDIF.
IF itab_data-bukrs <> lp_bukrs OR itab_data-anlkl <> lp_anlkl OR itab_data-.. <> lp_.. . "bukrs anlkl .. 分组
".........
ENDIF.
"**********普通循环处理
".........
"**********AT END OF 对当前分组末行进行处理
DATA : l_nolast1,l_nolast12 . "不是分组中最末行
"这里还是要清一下,以防该代码直接写在报表程序的事件里,而不是Form里(直接放在Report程序事件里时,l_nolast1,l_nolast12将会成为全局变量)
CLEAR: l_nolast1,l_nolast12,l_nolast...
DO.
i_indx = i_indx + 1.
READ TABLE itab_data INTO lwa_data INDEX i_indx."尝试读取下一行
IF sy-subrc <> 0."当前行已是内表中最后一行
EXIT.
"如果第一分组字段都发生了变化,则意味着当前行为所有分组中的最后行
"注:即使有N 个分组,这里也只需要判断第一分组字段是否发生变化,不
"需要对其他分组进行判断,即这里不需要添加其他 ELSEIF 分支
ELSEIF lwa_data-bukrs <> itab_data-bukrs.
EXIT.
ENDIF.
********断定满足条件的下一行不是分组最的一行
"如果Loop循环中没有Where条件,则可以将下面条件 lwa_data-flg = 'X' 删除即可
IF sy-subrc = 0 AND lwa_data-flg = 'X' .
IF lwa_data-bukrs = itab_data-bukrs ."判断当前行是否是 bukrs 分组最后行
l_nolast1 = '1'.
IF lwa_data-nanlkl = itab_data-nanlkl ."判断当前行是否是 bukrs nanlkl 分组最后行
l_nolast2 = '1'.
IF lwa_data-.. = itab_data-..."判断当前行是否是 bukrs nanlkl ..分组最后行
l_nolast.. = '1'.
ENDIF.
ENDIF.
EXIT."只要进到此句所在外层If,表示找到了一条满Where条件的下一行数据,因此,只要找到这样的数据就可以判断当前分组是否已完,即一旦找到这样的数据就不用再往后面找了,则退出以防继续往下找
ENDIF.
ENDIF.
ENDDO.
IF l_nolast..IS INITIAL"处理 bukrs nanlkl ..分组
......
ENDIF.
IF l_nolast2 IS INITIAL ."处理 bukrs nanlkl 分组
......
ENDIF.
IF l_nolast1 IS INITIAL ."处理 bukrs 分组
......
ENDIF.
lp_bukrs = itab_data-bukrs.
lp_anlkl = itab_data-anlkl.
lp_.. = itab_data-.. .
ENDLOOP.
3.2. 在LOOP AT中修改当前内表行
3.2.1.循环中修改索引表
TYPES: BEGIN OF line ,
key ,
val TYPE i ,
END OF line .
DATA: itab1 TYPE line OCCURS 0 WITH HEADER LINE .
DATA: itab2 TYPE line OCCURS 0 WITH HEADER LINE .
itab1-key = 1.
itab1-val = 1.
APPEND itab1.
itab2 = itab1.
APPEND itab2.
itab1-key = 2.
itab1-val = 2.
APPEND itab1.
itab2 = itab1.
APPEND itab2.
LOOP AT itab1.
WRITE: / 'itab1 index: ' , sy-tabix.
READ TABLE itab2 INDEX 1 TRANSPORTING NO FIELDS."试着读取其他内表
"READ TABLE itab1 INDEX 1 TRANSPORTING NO FIELDS."读取本身也不会影响后面的 MODIFY 语句
WRITE: / 'itab2 index: ', sy-tabix.
itab1-val = itab1-val + 1.
"在循环中可以使用下面简洁方法来修改内表,修改的内表行为当前正被循环的行,即使循环中使用了
"READ TABLE语句读取了其他内表(读取本身也没有关系)而导致了sy-tabix 发生了改变,因为以下
"语句不是根据sy-tabix来修改的(如果在前面读取内表导致sy-tabix 发生了改变发生改变后,再使用
"MODIFY itab1 INDEX sy-tabix语句进行修改时,反而不正确。而且该语句还适用于Hash内表,需在
"MODIFY后面加上TABLE关键字后再适用于Hash表——请参见后面章节示例)
MODIFY itab1.
ENDLOOP.
LOOP AT itab1.
WRITE: / itab1-key,itab1-val.
ENDLOOP.

3.2.2. 循环中修改HASH表
TYPES: BEGIN OF line ,
key ,
val TYPE i ,
END OF line .
DATA: itab1 TYPE HASHED TABLE OF line WITH HEADER LINE WITH UNIQUE KEY key.
DATA: itab2 TYPE line OCCURS 0 WITH HEADER LINE .
itab1-key = 1.
itab1-val = 1.
INSERT itab1 INTO TABLE itab1.
itab2 = itab1.
APPEND itab2.
itab1-key = 2.
itab1-val = 2.
INSERT itab1 INTO TABLE itab1.
itab2 = itab1.
APPEND itab2.
LOOP AT itab1.
WRITE: / 'itab1 index: ' , sy-tabix."循环哈希表时,sy-tabix永远是0
READ TABLE itab2 INDEX 1 TRANSPORTING NO FIELDS.
WRITE: / 'itab2 index: ', sy-tabix.
itab1-val = itab1-val + 1.
MODIFY TABLE itab1."注:该语句不一定在要放在循环里才能使用——循环外修改Hash也是一样的,这与上面的索引表循环修改是不一样的,并且修改的条件就是itab1表头工作区,itab1即是条件,也是待修改的值,修改时会根据内表设置的主键来修改,而不是索引号
ENDLOOP.
LOOP AT itab1.
WRITE: / itab1-key,itab1-val.
ENDLOOP.

3.3. 第二索引
三种类型第二索引:
²UNIQUE HASHED: 哈希算法第二索引
²UNIQUE SORTED: 唯一升序第二索引
²NON-UNIQUE SORTED:非唯一升序第二索引
TYPES sbook_tab TYPE STANDARD TABLEOF sbook
"主索引:如果要为主索引指定名称,则只能使用预置的 primary_key,但可以通过后面的 ALIAS 选项来修改(注:ALIAS选项只能用于排序与哈希表)
WITH NON-UNIQUE KEY primary_key "ALIAS my_primary_key
COMPONENTS carrid connid fldate bookid
"第一个第二索引:唯一哈希算法
WITH UNIQUE HASHED KEY hash_key
COMPONENTS carrid connid
"第二第二索引:唯一升序排序索引
WITH UNIQUE SORTED KEY sort_key1
COMPONENTS carrid bookid
"第三第二索引:非唯一升序排序索引
WITH NON-UNIQUE SORTED KEY sort_key2
COMPONENTS customid.
3.3.1. 使用第二索引
1、 可以在READ TABLE itab、MODIFY itab、DELETE itab、LOOP AT itab内表操作语句中通过WITH [TABLE] KEYkey_nameCOMPONENTSK1=V1 ...或者USING KEY key_name,语句中的key_name为第二索引名:
READ TABLE itab WITH TABLE KEY[key_nameCOMPONENTS] {K1|(K1)} = V1... INTO wa
READ TABLE itab WITH KEY key_nameCOMPONENTS {K1|(K1)} = V1... INTO wa
READ TABLE itab FROM wa [USING KEY key_name] INTO wa
READ TABLE itab INDEX idx [USING KEY key_name] INTO wa
MODIFY TABLE itab [USING KEY key_name] FROM wa
MODIFY itab [USINGKEY loop_key] FROM wa此语句只能用在LOOP AT内表循环语句中,并且此时 USING KEY loop_key 选项也可以省略(其实默认就是省略的),其中loop_key是预定义的,不能写成其他名称
MODIFY itab INDEX idx [USING KEY key_name] FROM wa
MODIFY itab FROM wa [USING KEY key_name] ...WHERE ...
DELETE TABLE itab FROM wa [USING KEY key_name]
DELETE TABLE itab WITH TABLE KEY [key_nameCOMPONENTS] {K1|(K1)} = V1...
DELETE itab INDEX idx [USING KEY key_name|(name)]
DELETE itab [USING KEY loop_key]
DELETE itab [USING KEY key_name ] ...WHERE ...
DELETE ADJACENT DUPLICATES FROM itab [USING KEY key_name] [COMPARING K1 K2...]
LOOP AT itab USING KEY key_name WHERE... .
ENDLOOP.
2、 可以在INSERTitab与APPEND语句中通过USING KEY选项来使用第二索引
INSERT wa [USING KEY key_name] INTO TABLE itab
APPEND wa [USING KEY key_name] TO itab
3.3.2.示例
DATA itab TYPE HASHED TABLE OF dbtab WITH UNIQUE KEY col1 col2 ...
"向内表itab中添加大量的数据 ...
READ TABLE itab "使用非主键进行搜索,搜索速度将会很慢
WITH KEY col3 = ... col4 = ...
ASSIGNING ...
上面定义了一个哈希内表,在读取时未使用主键,在大数据量的情况下速度会慢,所以在搜索字段上创建第二索引:
DATA itab TYPE HASHED TABLE OF dbtab
WITH UNIQUE KEY col1 col2 ...
"为非主键创建第二索引
WITH NON-UNIQUE SORTED KEY second_key
COMPONENTS col3 col4 ...
"向内表itab中添加大量的数据 ...
READ TABLE itab "根据第二索引进行搜索,会比上面程序快
WITH TABLE KEY second_key
COMPONENTS col3 = ... col4 = ...
ASSIGNING ...
"在循环内表的Where条件中,如果内表不是排序内表,则不会使用二分搜索,如果使用SORTED KEY,则循环时,会用到二分搜索?
LOOP AT itab USING KEY second_key where col3 = ... col4 = ... .
ENDLOOP.
3.4. 向Unique Key的Sort、Hash表中插入重得数据
TYPES: BEGIN OF typ_tab,
mandt TYPE t001-mandt,
bukrs TYPE t001-bukrs,
END OF typ_tab.
DATA: lt_hash TYPE HASHED TABLE OF typ_tab WITH UNIQUE KEY mandt WITH HEADER LINE.
DATA: lt_sort TYPE SORTED TABLE OF typ_tab WITH UNIQUE KEY mandt WITH HEADER LINE.
lt_hash-mandt = '200'.lt_hash-bukrs = '200'.
INSERT lt_hash INTO TABLE lt_hash.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_hash-mandt = '100'.lt_hash-bukrs = '300'.
INSERT lt_hash INTO TABLE lt_hash.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_hash-mandt = '200'.lt_hash-bukrs = '400'.
"重复的无法插入,也不会覆盖,也不会抛异常
INSERT lt_hash INTO TABLE lt_hash.
WRITE:/ 'sy-subrc:',sy-subrc.
SKIP.
LOOP AT lt_hash.
WRITE: / lt_hash-mandt,lt_hash-bukrs.
ENDLOOP.
WRITE:/ '-----------------------'.
lt_sort-mandt = '200'.lt_sort-bukrs = '200'.
INSERT lt_sort INTO TABLE lt_sort.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_sort-mandt = '100'.lt_sort-bukrs = '300'.
INSERT lt_sort INTO TABLE lt_sort.
WRITE:/ 'sy-subrc:',sy-subrc.
lt_sort-mandt = '200'.lt_sort-bukrs = '400'.
"与HASH一样,重复的无法插入,也不会覆盖,也不会抛异常
INSERT lt_sort INTO TABLE lt_sort.
WRITE:/ 'sy-subrc:',sy-subrc.
SKIP.
LOOP AT lt_sort.
WRITE: / lt_sort-mandt,lt_sort-bukrs.
ENDLOOP.
WRITE:/ '-----------------------'.
"不管是Sort,还是Hash 表,只要是 Unique Key,且从数据库查出来的数据存在重复,则会Dump掉
*SELECT mandt bukrs INTO TABLE lt_hash FROM t001 CLIENT SPECIFIED WHERE mandt BETWEEN '100' AND'999'.
*SELECT mandt bukrs INTO TABLE lt_sort FROM t001 CLIENT SPECIFIED WHERE mandt BETWEEN '100' AND'999'.
另:针对Unique的Sort、Hash内表,可以使用Collect语句进行汇总统计
另外:对于排序内表,不要使用APPEND 、APPEND LINES附加数据,要使用INSERT、INSERT LINES向排序内表中插入数据,因为如果附加的数据不按排序内表排序规则来的话,会Dump,但使用INSERT就不会了

3.5. 适合所有类型的内表操作
COLLECT [
INSERT
INSERT LINES OF
向UNIQUE 的排序表或哈希表插入重复的数据时,不会抛异常,但数据不会被插入进去,这与APPEND是不一样的
Hash内表的KEY设置只能是开头前部分定义的连续的组件字段,不能只将中间或先后几个字段设置为KEY,否则在查找时会出问题,数据无法查到
"只要根据关键字或索引在内表中读取到相应数据,不管该数据行是否与COMPARING 指定的字段相符,都会存储到工作区
READ TABLE
INTO
[TRANSPORTING
| ASSIGNING
READ TABLE
COMPARING:系统根据
如果系统找根据指定
MODIFY TABLE
MODIFY
DELETE TABLE
DELETE TABLE
DELETE itab WHERE ( col2 > 1 ) AND ( col1 < 4 )"删除多行
DELETE ADJACENT DUPLICATESFROM
注,在未使用COMPARING 选项时,要删除重复数据之前,一定要按照内表关键字声明的顺序来进行排序,才能删除重复数据,否则不会删除掉;如果指定了COMPARING 选项,则需要根据指定的比较字段顺序进行排序(如COMPARING
3.6.适合索引内表操作
APPEND
APPEND LINES OF
INSERT
INSERT LINES OF
APPEND/INSERT…INDEX 操作不能用于Hash表
APPEND/INSERT…INDEX用于排序表时条件:附加/插入时一定要按照Key的升序来附加;如果是Unique排序表,则不能附加/插入重附的数据,这与INSERT…INTO TABLE是不一样的
READ TABLE
INTO
[TRANSPORTING
| ASSIGNING
MODIFY
DELETE
DELETE
4. OPEN SQL
4.1. SELECT 、INSERT、UPDATE、DELETE、MODIFY
如果从数据库读出来的数据存在重复时,不能存储到Unique内表中去——如Unique的排序表与哈希表
SELECT SINGLE...INTO [CORRESPONDING FIELDS OF] wa WHERE...
SELECT SINGLE
SELECT ... FROM
SELECT...INTO|APPENDING CORRESPONDING FIELDS OF TABLE
单条插入:在插入时是按照数据库表结构来解析
INSERT INTO
INSERT
多条插入:itab内表的行结构也必须和数据库表的行结构一致;ACCEPTING DUPLICATE KEYS:如果现出关键字相同条目,系统将SY-SUBRC返回4,并跳过该条目,但其他数据会插入进去
INSERT
单条更新:会根据数据库表关键字来更新其他非关键字段。如果WA工作区是自己定义的且未参照数据库表,则WA的结构需要与数据库表相一致,且不能短于数据库表结构,但字段名可任意取
UPDATE dbtab FROM wa
多条更新:主键不会被更新,即使在SET后面指定后也不会被更改
UPDATEdbtab SETf1 = g1 … fi = gi WHERE
UPDATE dbtab FROMTABLE itab 与从WA工作区单条更新原理一样,根据数据表库关键字段来更新,且行结构要与数据库表结构一致,并且不能短于数据库表结构,一样内表行结构组件名可任意
单条删除:下面的WA与Itab原理与Update是一样的
DELETE dbtab FROM wa
多条删除:
DELETE dbtab FROMTABLE itab
DELETEFROM dbtab WHERE
插入或更新:下面的WA与Itab原理与Update是一样的
MODIFY dbtab FROM wa 单行
MODIFY dbtab FROMTABLE itab多行,有就修改,没有就插入
4.2.条件操作符
=、<>、<、<=、>、>=
[NOT] BETWEEN ...AND
[NOT] LIKE
[NOT] IN
IS [NOT] NULL
4.3.RANG条件内表
两种定义方式:
RANGES seltab FOR dobj [OCCURS n].其中dobj为自定义变量或者是参照某个表字段
SELECT-OPTIONSselcritFOR {dobj|(name)}
上面两个语句会生成如下结构的内表,该条件内表的每一行都代表一个逻辑条件:
DATA: BEGIN OF seltab OCCURS 0,
sign TYPE c LENGTH 1, 允许值为I和E,I表示包含 Include,E表示排除Exclude
option TYPE c LENGTH 2, OPTION表示选择运算符,
low LIKE dobj, 下界,相当于前面文本框中的值
high LIKE dobj, 上界,相当于后面文本框中的值
END OF rtab.
option: HIGH字段为空,则取值可以为:EQ(=)、NE(<>)、GT(>)、GE(>=)、LE(<=)、LT(<)、CP、NP,CP(集合之内的数据)和NP(集合之外数据)只有当在输入字段中使用了通配符(“*”或“+”)时它们才是有效的
SELECT ... WHERE ... field [NOT] IN seltab ...
如果RANG条件内表为空,则IN seltab逻辑表达试恒为真,XX NOT IN seltab恒为假
注:不会像FOR ALL ENTRIES那样,忽略其他的条件表达式,其他条件还是起作用
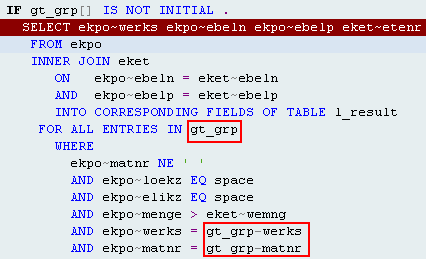
4.4. FOR ALL ENTRIES
1、使用该选项后,对于最后得出的结果集系统会自动删除重复行。因此如果你要保留重复行记录时,记得在SELECT语句中添加足够字段
2、FOR ALL ENTRIES IN后面使用的内部表itab如果为空,将查出当前CLIENT端所有数据(即忽略整个WHERE语句,其他条件都会被忽略)
3、内表中的条件字段不能使用BETWEEN、LIKE、IN比较操作符
4、使用该语句时,ORDER BY语句和HAVING语句将不能使用
5、使用该语句时,除COUNT( * )(并且如果有了COUNT函数,则不能再选择其他字段,只能使用在Select ... ENDSelect语句中了)以外的所有合计函数(MAX,MIN,AVG,SUM)都不能使用
即使Where后面还有其它条件,所有的条件都会忽略:
SELECT vbeln posnr pstyv werks matnr arktx lgort waerk kwmeng
FROM vbap INTO TABLE gt_so FOR ALL ENTRIES IN lt_matnr
WHERE matnr = lt_matnr-matnr AND vbeln IN s_vbeln AND posnr IN s_posnr.
如果上面的lt_matnr为空,则“AND vbeln IN s_vbeln AND posnr IN s_posnr”条件也会忽略掉,即整个Where都会被忽略掉。
SELECT matnr FROM mara INTO CORRESPONDING FIELDS OF TABLE strc
FOR ALL ENTRIES IN strc WHERE matnr = strc-matnr .
生成的SQL语句:SELECT "MATNR" FROM "MARA" WHERE "MANDT" = '210' AND "MATNR" IN ( '000000000000000101' , '000000000000000103' , '000000000000000104' )
注:这里看上去FOR ALL ENTRIES使用 IN 表达式来代替了,这是只有使用到内表中一个条件是这样的,如果使用多个条件时,不会使用In表达式,而是使用OR连接,像这样:
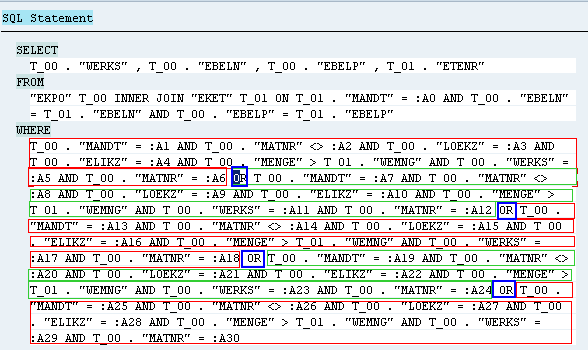
另外,在使用FOR ALL ENTRIES时,不管使用了条件内表中的一个还是多个条件字段,都会以5个值为单位进行SQL发送
4.5.INNER JOIN、LEFT OUTER JOIN使用限制
ON后面的条件与Where条件类似,但有以下不同:
² 必需有ON条件语句,且多个条件之间只能使用AND连接
²每个条件表达式中两个操作数之中必须有一个字段是来自于JOIN右表
²如果是LEFT OUTER JOIN,则至少有一个条件表达式的两个操作数一个是来自于左表,另一个来自右表
²不能使用NOT、LIKE、IN(但如果是 INNER JOIN,则>、<、BETWEEN …AND、<>都可用)
²如果是LEFT OUTER JOIN,则只能使用等号操作符:(=、EQ)
²如果是LEFT OUTER JOIN,同一右表不能多次出现在不同的LEFT OUTER JOIN的ON条件表达式中
²LEFT OUTER JOIN的右表所有字段不能出现在WHERE中
²如果是LEFT OUTER JOIN,则在同一个ON条件语句中只能与同一个左表进行关联
4.6. 动态SQL
SELECT (column_syntax) FROM...
column:可以是内表,也可以是字符串
TYPES: line_type TYPE c LENGTH 72.
DATA: column_syntax TYPE TABLE OF line_type .
APPEND 'CARRID' TO column_syntax.
APPEND 'CITYFROM CITYTO' TO column_syntax.
SELECT ... FROM (dbtab_syntax)...
PARAMETERS: p_cityfr TYPE spfli-cityfrom,
p_cityto TYPE spfli-cityto.
DATA: BEGIN OF wa,
fldate TYPE sflight-fldate,
carrname TYPE scarr-carrname,
connid TYPE spfli-connid,
END OF wa.
DATA itab LIKE SORTED TABLE OF wa
WITH UNIQUE KEY fldate carrname connid.
DATA: column_syntax TYPE string,
dbtab_syntax TYPE string.
column_syntax = `c~carrname p~connid f~fldate`.
dbtab_syntax = `( ( scarr AS c `
& ` INNER JOIN spfli AS p ON p~carrid = c~carrid`
& ` AND p~cityfrom = p_cityfr`
& ` AND p~cityto = p_cityto )`
& ` INNER JOIN sflight AS f ON f~carrid = p~carrid `
& ` AND f~connid = p~connid )`.
SELECT (column_syntax) FROM (dbtab_syntax)
INTO CORRESPONDING FIELDS OF TABLE itab.
SELECT ... WHERE (cond_syntax) ...
SELECT ... WHERE
DATA: cond(72) TYPE c,
itab LIKE TABLE OF cond.
APPEND 'cityfrom = ''NEW YORK''' TO itab.
APPEND 'or cityfrom = ''SAN FRANCISCO''' TO itab.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (itab).
DATA:cond1(72) TYPE c VALUE 'cityfrom = ''NEW YORK''',
cond2(72) TYPE c VALUE 'cityfrom = ''SAN FRANCISCO'''.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (cond1) OR (cond2).
DATA: cond(72) TYPE c,
cond1(72) TYPE c VALUE 'cityfrom = ''NEW YORK''',
itab LIKE TABLE OF cond.
APPEND 'cityfrom = ''SAN FRANCISCO''' TO itab.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (itab) OR (cond1).
DATA: cond(72) TYPE c,
itab LIKE TABLE OF cond.
APPEND 'cityfrom = ''SAN FRANCISCO''' TO itab.
SELECT * INTO TABLE itab_spfli FROM spfli WHERE (itab)OR cityfrom ='NEW YORK'
4.7.子查询
colum operator[ALL|ANY|SOME]、[NOT] EXISTS、[NOT] IN连接至WHERE从句与HAVING从句中
4.7.1.=、<>、<、<=、>、>=子查询
子查询的SELECT中只有一个表字段或者是一个统计列,并且只能返回一条数据
SELECT * FROM sflight INTO wa_sflight
WHERE seatsocc = ( SELECT MAX( seatsocc ) FROM sflight ).
ENDSELECT.
操作符可以是:=、<>、<、<=、>、>=
4.7.1.1.ALL、ANY、SOME
如果子查询返回的是多条,则使用ALL、ANY、SOME来修饰
SELECT customid COUNT( * ) FROM sbook INTO (id, cnt) GROUP BY customid
HAVING COUNT( * ) >= ALL ( SELECT COUNT( * ) FROM sbook GROUP BY customid ).
ENDSELECT.
² ALL:主查询数据大于所有子查询返回的行数据时,才为真
² ANY|SOME:主查询数据只要大于任何一条子查询返回的行数据时,才为真
² = ANY|SOME:等效IN子查询
4.7.2.[NOT] IN子查询
此类子查询SELECT中也只有单独的一列选择列,但查询出的结果可能有多条
SELECT SINGLE city latitude longitude INTO (city, lati, longi) FROM sgeocity
WHERE city IN ( SELECT cityfrom FROM spfli
WHERE carrid = carr_id AND connid = conn_id ).
4.7.3.[NOT] EXISTS子查询
这类子查询没有返回值,也不要求SELECT从句中只有一个选择列,选择列可以任意个数,WHERE 或者 HAVING从句根据该子查询的是否查询到数据来决定外层主查询语句来选择相应数据
SELECT carrname INTO TABLE name_tab FROM scarr
WHERE EXISTS ( SELECT * FROM spfli
WHERE carrid = scarr~carridAND cityfrom = 'NEW YORK' ).
4.7.4. 相关子查询
上面的示例子查询即为相关子查询
如果某个子查的WHERE条件中引用了外层查询语句的列,则称此子查询为相关子查询。相关子查询对外层查询结果集中的每条记录都会执行一次,所以尽量少用相关子查询
4.8.统计函数
MAX、MIN、AVG、SUM、COUNT,聚合函数都可以加上DISTINCT选项
4.9.分组过滤
如果将统计函数与GROUP BY子句一起使用,那么Select语句中未出现在统计函数的数据库字段都必须在GROUP BY子句中出现。如果使用INTO CORRESPONDING FIELDS项,则需要在Select语句中通过AS后面的别名将统计结果存放到与之相应同名的内表字段中:
SELECT MIN( price ) AS mINTO price FROM sflight GROUP BY carrid
HAVING MAX(price)>10. Having从句中比较统计结果时,需要将统计函数重写一遍,而不能使用Select中定义的别名
ENDSELECT.
4.10.游标
DATA: c TYPE cursor.[ˈkɜ:sə]
DATA: wa TYPE spfli.
"1、打开游标
OPEN CURSOR: c FOR SELECT carrid connid FROM spfli WHERE carrid = 'LH'.
DO.
"2、读取数据
FETCH NEXT CURSOR c INTO CORRESPONDING FIELDS OF wa.
IF sy-subrc <> 0.
"3、关闭游标
CLOSE CURSOR c.
EXIT.
ELSE.
WRITE: / wa-carrid, wa-connid.
ENDIF.
ENDDO.
4.11.三种缓存
l 单记录缓存:从数据库中仅读取一条数据并存储到table buffer 中。此缓存只对SELECT SINGLE…语句起作用
l 部分缓存:需要在指定generic key(即关键字段组合,根据哪些关键字段来缓存,可以是部分或全部关键字段)。如果主键是由一个字段构成,则不能选择此类型缓存。当你使用generic key进行数据访问时,则属于此条件范围的整片数据都会被加载到table buffer中
1、查询时如果使用BYPASSING BUFFER 选项,除了绕过缓存直接到数据库查询外,查出的数据不会放入缓存
2、只要查询条件中出现了用作缓存区域的所有关键字段,则查询出所有满足条件全部数据进行缓存
3、如果查询条件中generic key只出现某个或者某部分,则不会进行缓存操作
4、如果主键是只由一个字段组成,则不能设定为此种缓存
5、如果有MANDT字段,则为generic key的第一个字段

l 全部缓存:在第一次读取表数据时,会将整个表的数据都会缓存下来,不管WHERE条件
4.12.Native SQL
4.12.1.查询
DATA: BEGIN OF wa,
connid TYPE spfli-connid,
cityfrom TYPE spfli-cityfrom,
cityto TYPE spfli-cityto,
END OF wa.
DATA c1 TYPE spfli-carrid VALUE 'LH'.
"Native SQL语句不能以句点号结尾;
"不能在EXEC SQL…ENDEXEC间有注释,即不能有星号与双引号的出现;
"参数占位符使用冒号,而不是问号;
EXEC SQL PERFORMING loop_output.
SELECT connid, cityfrom, cityto
INTO :wa
"或使用:INTO :wa-connid ,:wa-cityfrom ,:wa-cityto
FROM spfli
WHERE carrid = :c1
ENDEXEC.
FORM loop_output.
WRITE: / wa-connid, wa-cityfrom, wa-cityto.
ENDFORM
4.12.2.存储过程
EXEC SQL.
EXECUTE PROCEDURE proc1 ( IN:x,OUT:y,INOUT:z )
ENDEXEC.
4.12.3.游标
DATA: arg1 TYPE string VALUE '800'.
TABLES: t001.
EXEC SQL.
OPEN c1 FOR SELECT MANDT, BUKRS FROM T001 "打开游标
WHERE MANDT = :arg1 AND BUKRS >= 'ZA01'
ENDEXEC.
DO.
EXEC SQL.
FETCH NEXT c1 INTO :t001-mandt, :t001-bukrs "读取游标
ENDEXEC.
IF sy-subrc <> 0.
EXIT.
ELSE.
WRITE: / t001-mandt, t001-bukrs.
ENDIF.
ENDDO.
EXEC SQL.
CLOSE c1 "关闭游标
ENDEXEC.
4.13.SAP锁
通用数据库表锁函数:ENQUEUE_E_TABLE、DEQUEUE_E_TABLE、DEQUEUE_ALL(解锁所有)[kju:]
特定数据库表锁函数:ENQUEUE_
自定义的锁对象都必须以EZ_ 或者EY_ 开头来命名
|
|
允许第二次加锁模式 |
||
| 第一次加锁模式 |
S |
E |
X |
| S 共享锁 |
是(是) |
否(是) |
否(否) |
| E 可重入的排他锁 |
否(是) |
否(是) |
否(否) |
| X 排他锁 |
否(否) |
否(否) |
否(否) |
括号内为同一程序(即同一事务内)内,括号外为非同一程序内
CALL FUNCTION 'ENQUEUE_EZ_ZSPFLI'"加锁
EXPORTING
mode_zspfli = 'E'
mandt = sy-mandt
carrid = 'AA'
connid = '0011'
* X_CARRID = ' '"设置字段初始值(Initial Value),若为X,则当遇到与CARRID的初始值Initial Value相同值时才会设置锁对象。CARRID的初始值只需在数据库表字段中选择Initial Value选项(SE11中设置)。当没有设置X时,则会用该锁函数所设置的Default Value指定初始值
* X_CONNID = ' '
* _SCOPE = '2'"该选项只有在UPDATE函数(CALL FUNCTION FM IN UPDATE TASK)中才起作用,用来控制锁的传递。一般当调用解锁函数DEQUEUE或程序结束时(LEAVE PROGRAM或者LEAVE TO TRANSACTION)锁就会被自动解除,另外,遇到A、X消息时或用户在命令框中输入/n 时锁也会被解除,但是,当事务码正在执行UPDATE函数时就不一样了,函数结束时是否自动解除锁则要看该选项 _SCOPE 了:
1-表示程序内有效 2-表示update module 内有效 3-全部
* _WAIT = ' '"表示如果对象已经被锁定,是否等待后再尝试加锁
* _COLLECT = ' '"参数表示是否收集后进行统一提交
程序锁定:ENQUEUE_ES_PROG和DEQUEUE_ES_PROG
5.SAP/DB LUW
5.1.DB LUW
DB LUW(Logic Unit Work)是确保数据库更新一致性的机制,是数据库级别的,和底层DBMS有关,和SAP系统无关。如下图,从一致性状态A到B,中间有一系列的数据库操作,一个BD luw以数据库提交commit结束,这些操作要么全都执行,要么全都不执行。当全部执行成功,则数据库进入一致性状态B,如果在此DB luw中发生错误,则将从DB luw开始的所有操作进行回滚,数据库还是在A状态。
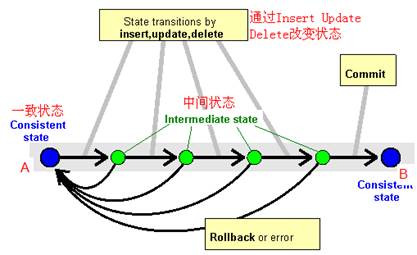
这是在数据库级别实现的,和SAP系统无关。
在SAP系统中,DB luw commit and rollback 可以被显式或隐式的触发。
不管是commit还是rollback,结束了一个DB luw,也即是开始了一个新的DB luw。
5.1.1.显式提交
·Native SQL提交语句
·Calling the function module DB_COMMIT.
·COMMIT WORK语句
5.1.2.隐式提交
·对话屏幕结束时(跳转另一屏幕)
·同步或异步方式远程调用RFC时:
CALL FUNCTION func DESTINATION dest
CALL FUNCTION func STARTING NEW TASK DESTINATION dest taskname
但RFC事务调用不会触发隐式提交:CALL FUNCTION func IN BACKGROUND TASK DESTINATION dest
·取RFC异步执行结果回调Form中RECEIVE 语句:CALL FUNCTION rfm_name STARTING NEW TASK DESTINATION dest tasknamePERFORMING return_form ON END OF TASK中的RECEIVE RESULTS FROM FUNCTION rfm_name语句会触发
·WAIT UNTIL log_exp [UP TO sec SECONDS]语句
·Sending error messages(E), information messages(I), and warnings(W).
5.1.3. 显示回滚
·使用Native-SQL进行回滚
·使用ROLLBACK WORK.进行回滚
5.1.4. 隐式回滚
·runtime error:在程序执行过程中未捕获的异常以及message type X的消息,因为runtime error会导致程序的termination
·因为发送的Message而导致程序的termination(除了A、X类型的消息会导致程序终止外,其他类型的消息在特定的情况下也会导致程序终止,具体请参见《User Dialogs.docx》中的消息显示及处理章节)
Runtime Error:系统不能继续运行,并且ABAP程序终止,以下情况会发生运行时错误:
²未处理的异常(当一个能够被处理的异常却未被处理时;抛出了一个不能够处理的异常)
²X类型消息
² ASSERT断言语句不成立时
5.2.SAP LUW
sap系统中一个业务操作会有多个对话屏幕,只到save操作成功,才算完成了一个业务。那么仅使用DB luw是不能保证SAP 系统数据一致性的。如下图,如果只是最后屏幕300保存时的DB luw发生错误,那么在数据库级一致性机制作用下只能回滚这一个db luw使数据库处于g状态,而前几个db luw在屏幕结束时已经提交,进行的数据库更新会全部生效,从业务层面上讲,这是不合理的,因为这个业务并没有保存成功,我们需要回滚到A或a状态。SAP luw就是sap在DB luw基础上保证数据库一致性的一种机制。

上图(未使用SAP LUW),绿色表示数据库更新操作。每个dialog steps都会形成一个单独的DB LUW。默认情况下(未通过SAP LUW的绑定方式来实现延迟执行数据库更新操作),每个DB LUW都会提交事务

上图(将多个DB LUW绑定成一个SAP LUW),将每个dialog steps(即DB LUW)中的数据库操作“移”到最后一个dialog steps(即DB LUW)中执行,这里的“移”实质上是一种延迟执行的方式,即先将前面每个dialog steps中的数据库更新操作记录下来,待最后统一由COMMIT来提交。
SAP LUW可以跨多个DB LUW,是一个业务逻辑上的概念,可人为的去定义开始与结束,而DB LUW是不能人为控制的
SAP LUW是DB LUW的一个增强,受体系结构限制,SAP程序每次屏幕切换时(控制权从后台DIALOG进程转移到前台GUI的Session),都会触发一个隐式的数据库提交,一个程序在运行是会产生多个DB 的LUW,这样无法做到全部提交或全部回滚,在某些业务场景下,这种事务的提交机制不足以保证数据的一致性,为此有了SAP LUW机制。
SAP LUW是一种延迟执行的技术,它将本来需要执行的程序块,记录下来(通过特定的方式来调用来实现SAP LUW的绑定:perform XXX on commit、update Funciton module),待系统在执行COMMIT WORK的时候会查询记录,真正执行需要运行的代码。COMMIT WORK一般在最后一个屏幕执行,这样就实现了将跨屏幕的数据更新逻辑绑定到一个DBLUW中(在后台会自动将这一系列的数据操作绑定在同一个数据事务DBLUW里,这样当提交出问题后,数据库事务DBLUW会自动回滚,这样就保证了数据的一致性),实现复杂情况数据更新的一致性
5.2.1.SAP LUW的绑定方式
5.2.1.1.Function
可以使用CALL FUNCTION update_function IN UPDATE TASK将多个数据更新绑定到一个database LUW中

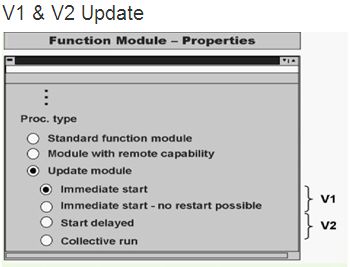
此类型的更新函数Update Function中主要实现对数据库数据进行更新操作
² Immediate start:表示V1方式,将此更新函数设置为高优先级V1并运行在同一个SAP LUW中。更新出错后,可以在SM13里重新执行
² Immediate start -no restrat possible:V1方式,将此更新函数设置为高优先级V1并运行在同一个SAP LUW中。出错后不可以在SM13里重新执行
² Start delayed:V2方式,将此更新函数设置为低优先级V2并run in their own update transactions。V1方式更新完成后触发。出错后更新函数可以重启
² Collective run:V2方式,将此更新函数设置为低优先级V2并run in their own update transactions。需使用Collective(RSM13005)程序手动或JOB方式执行
V1与V2区别:
² V1优先级高于V2,V2被设计为依赖于V1,适合执行需要在V1完成后进行的操作
² V1更新使用V1进程处理,V1进程名字一般为UPD,V1进程绑定独立的数据库进程。在V1进程中调度的更新函数如果更新失败,回滚,不再进行V2操作。成功则提交更改到数据库,同时删除所有的SAP锁
² V2更新使用V2进程处理,如果没有配置V2进程则共用V1进程,V2进程名字为UP2,V2更新在独立DB LUW中,V2更新回滚后不会影响到V1更新提交的数据,由于V1更新结束后会删除SAP的锁,所以V2更新是在没有逻辑锁的情况下进行的,V2更新出错后可以在SM13中重新执行
² V1 的执行模式可以为异步、同步或本地;V2只能为异步执行
CALL FUNCTION ... IN UPDATE TASK的Function并不会立即执行,这只是先将它记录到内存(本地方式)或数据库表中(非本地方式),等到COMMIT WORK语句执行时才真正执行。如果在程序执行过程中,没有在Update Function 后面执行COMMIT WORK,则function module不会执行
此种类型的输入参数只能是值传递方式,不允许为引用传递,所以输入参数对应的“传递值”要钩上,并且传递的内容还不能是地址,即不允许为TYP EREF TO方式,只能是TYPE方式
5.2.1.2.subroutine
PERFORM subr ON { {COMMIT [LEVEL idx]} | ROLLBACK }.
子过程subr不会被马上执行,而是直到COMMIT WORK 或者是ROLLBACK WORK。可以使用LEVEL参数指定优先级,优先级按升序进行排列,较小的会优先执行。如果同样名字的subroutine被注册了多次,在COMMIT WORK时只执行一次,IN UPDATE TASK方式执行的Funciton没有这个限制
由于子过程绑定不需要写数据库表,所以比较更新函数绑定,性能上要高一些,缺点是你不能传递任何参数,它们所使用的必须是global data object,或可通过ABAP memory来共享参数
5.2.2.开启新的SAP LUW
没有专门类似开启数据库事务的语句(Begin trasaction),SAP LUW会在以下情况自动开启:
²提交COMMIT或回滚ROLLBACK后会开启另一个新的SAP LUW事务
²事务调用会重新开启一个新的SAP LUW
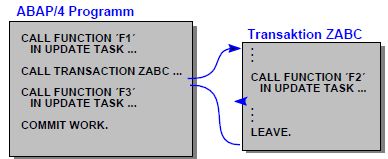
上图中F2不会被执行,因为它处于另一个事务中执行,但没有使用COMMIT WORK,而F1、F3会被执行,因为主调程序中使用了COMMIT WORK。所以事务调用会重新开启一个新的SAP LUW。
dialog modules与上面调用事务(CALL transaction)、调用executable programs (reports)不同的是:dialog modules中不会开启新的SAP LUW,如果dialog modules中调用了update function modules(CALL FUNCTION ... IN UPDATE TASK),则要等到主调程序中的COMMIT WORK时才会真正执行,哪怕在dialog modules中调用了COMMIT WORK也是没有用(不会启动update task)。
另外,由于数据共享问题,尽量不要在dialog modules中使用PERFORM XXX ON COMMIT。
5.2.3. 同步或异步更新(提交)
COMMIT WORK 异步更新,该语句执行后不会等待所有更新函数都执行完后才继续执行后面的代码
COMMIT WORK AND WAIT同步更新,该语句执行后会等待所有更新函数都执行完后才继续执行后面的代码,执行结果可以通过sy-subrc来判断事务提交是否成功
5.2.4.本地、非本地方式提交
本地方式:如果在调用UPDATE FUNCTION之前,先调用SET UPDATE TASK LOCAL.语句,这样所有在该语句后使用CALL FUNCTION...IN UPDATE TASK注册的更新函数不会记录到数据库中,而是记录在内存中,在Commit work之后,会从内存取得待执行的函数。在默认情况下,local update不会被设置,在使用COMMIT WORK之后 SET UPDATE TASK LOCAL的效果会被清除掉
本地方式更新只能采用同步方式,即使没有在Commit work后指定了and wait参数,仍然是同步执行
非本地方式:未使用SET UPDATE TASK LOCAL.语句。此方式下,注册的Update Function的名字以及接口实参都会以日志的形式记录到特殊的表。非本地方式即可同步也可异步COMMIT
² 本地方式不将待执行的更新函数写到数据表中,减少了I/O操作,效率上较高,但由于采用的是同步方式,程序需等待更新结果,用户交互时的会感觉程序运行较慢
² 非本地方式会将更新结果记录到数据表中,可以通过SM13查看更新情况,同时由于可以进行异步更新,用户交互时感觉会比较快
6. 逻辑数据库
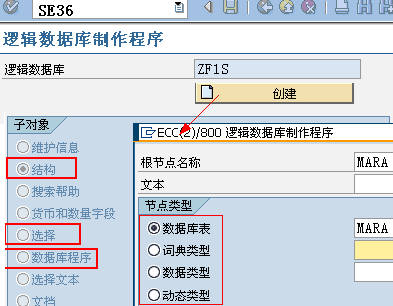
6.1.组成
SLDB
6.2. 结构

决定了数据从哪些数据库表、视图中提取数据,以及这些表、视图之间的层次关系(层次将决定数据读取的顺序)
数据库表(T类型节点)、词典类型(S类型节点),比如节点类型为S的节点:root_node,数据类型为INT4:
![]()
LDB的数据库程序的最TOP Include文件包括以下语句:
NODES root_node.
另外,在LDB数据库程序包括了以下过程:
FORM put_root_node.
DO 10 TIMES.
root_node = sy-index.
PUT root_node."会去调用报表程序中的 GET root_node. 事件块
ENDDO.
ENDFORM.
在与此LDB关连的可执行程序:
![]()
REPORT demo_nodes.
NODES root_node.
GET root_node.
WRITE root_node.
6.3.选择屏幕(Selections)
定义了LDB的选择屏幕,该选择屏幕的布局由LDB的结构决定,一旦将LDB链接到报表程序后,该选择屏幕会自动嵌入到默认选择屏幕1000中
第一次进入选择屏幕程序时,系统会为每个LDB生成一个名为DB<LDB_Name>SELInclude选择屏幕包含文件:
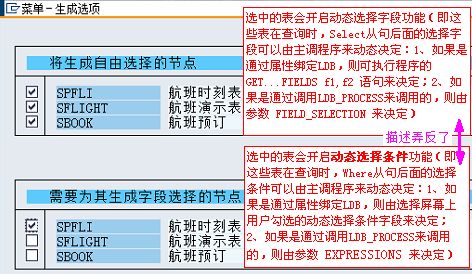
而且,所有表(T类型的节点)的主键都会出现在SELECT-OPTIONS语句中,成为屏幕选择字段(自动生成的需要去掉注释,并设置屏幕选择字段名):

除了上面自动生成的LDB屏幕字段外,还可以使用以下面语句来扩展LDB选择屏幕:
6.3.1.PARAMETERS屏幕参数扩充
增加一个单值输入条件框(PARAMETERS语句一般在LDB中只用于除节点表外的非表字段屏幕参数),在PARAMETERS语句中必须使用选项FOR NODE XXX 或者 FOR TABLE XXX 来指定这些扩展参数属性哪个节点的:PARAMETERS CITYTO LIKE SPFLI-CITYTO FOR NODE SPFLI.
注:SELECT-OPTIONS没有FOR NODE这样的用法
具体请参数后面的LDB选择屏幕章节
6.3.2.SELECTION-SCREEN格式化屏幕
使用SELECTION-SCREEN语句来格式化屏幕
具体请参数后面的LDB选择屏幕章节
6.3.3.DYNAMIC SELECTIONS动态选择条件
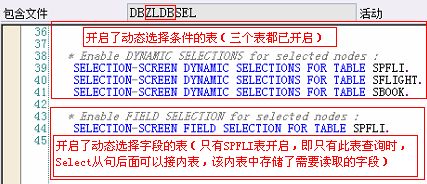
SELECTION-SCREEN DYNAMIC SELECTIONS FOR NODE|TABLE
上面LDB数据库程序中的RSDS_WHERE条件内表来自RSDS类型组,相应源码如下:
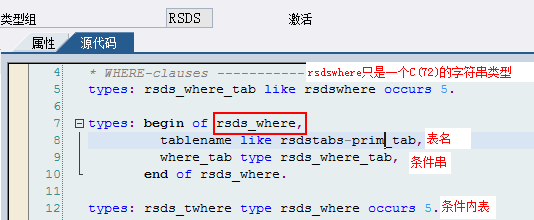
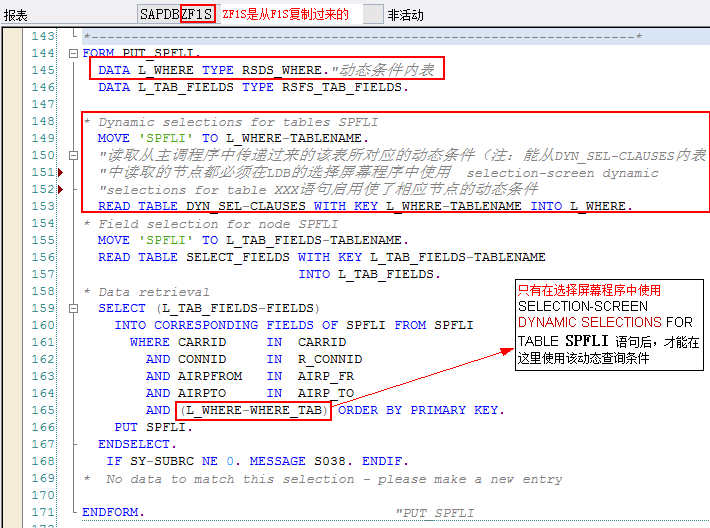
另外,上面LDB数据库程序中要能从DYN_SEL-CLAUSES内表读取数据,则必须在LDB选择屏幕里开启相应节点的动态选择条件:

其中,DYN_SEL-CLAUSES内表行结构如下:

6.3.3.1.DYN_SEL
PUT_
TYPE-POOLS RSDS.
DATA DYN_SEL TYPE RSDS_TYPE.
你不必在程序中定义它就可以直接使用,但它只能在LDB数据库程序中使用,而不能用在报表程序中。RSDS_TYPE数据类型是在类型组RSDS中定义的:
TYPE-POOL RSDS .
TYPES: RSDS_WHERE_TAB LIKE RSDSWHERE OCCURS 5."RSDSWHERE 类型为C(72)
TYPES: BEGIN OF RSDS_WHERE,
TABLENAME LIKE RSDSTABS-PRIM_TAB,
WHERE_TAB TYPE RSDS_WHERE_TAB,
END OF RSDS_WHERE.
TYPES: RSDS_TWHERE TYPE RSDS_WHERE OCCURS 5.
TYPES: BEGIN OF RSDS_TYPE,
CLAUSES TYPE RSDS_TWHERE,
TEXPR TYPE RSDS_TEXPR,
TRANGE TYPE RSDS_TRANGE,
END OF RSDS_TYPE.
RSDS_TYPE是一个深层结构的结构体,里面三个字段都是内表类型,其中以下两个字段重要:
6.3.3.1.1.RSDS_TYPE-CLAUSES
为Where从句部分,实则存储了可直接用在WHERE从句中的动态Where条件内表,可以在Where动态语句中直接使用,该组件为内表,存储了用户在选择屏幕上选择的LDB动态选择字段
每个被选择的LDB屏幕动态选择字段都会形成一个条件,并存储到RSDS_TYPE-CLAUSES-WHERE_TAB内表中,WHERE_TAB内表中存储的就是直接可以用在Where从句中的动态选择条件中
每个表(节点)都会有自己的CLAUSES-WHERE_TAB动态条件内表,这是通过CLAUSES-TABLENAME区别的
现假设有名为 ZHK 的LDB,SCARR为该LDB的根节点,且仅有SPFLI一个子节点。LDB选择屏幕 Include文件DBZHKSEL内容如下:
SELECT-OPTIONS S_CARRID FOR SCARR-CARRID.
SELECT-OPTIONS S_CONNID FOR SPFLI-CONNID.
"需要先开始动态选择条件功能
SELECTION-SCREEN DYNAMIC SELECTIONS FOR TABLE SCARR.
LDB数据库程序SAPDBZHK中,PUT_SCARR过程中使用dynamic selection的过程如下:
FORM PUT_SCARR.
STATICS: DYNAMIC_SELECTIONS TYPE RSDS_WHERE,FLAG_READ. "定义成静态类型的是防止再次进入此Form时,再次初始化DYNAMIC_SELECTIONS结构,即只执行一次初始化代码
IF FLAG_READ = SPACE.
DYNAMIC_SELECTIONS-TABLENAME = 'SCARR'.
READ TABLE DYN_SEL-CLAUSES WITH KEY DYNAMIC_SELECTIONS-TABLENAME INTO DYNAMIC_SELECTIONS.
FLAG_READ = 'X'.
ENDIF.
SELECT * FROM SCARR WHERE CARRID IN S_CARRID AND (DYNAMIC_SELECTIONS-WHERE_TAB). "使用动态Where条件
PUT SCARR.
ENDSELECT.
ENDFORM.
6.3.3.1.2.RSDS_TYPE-TRANGE
该字段是一个内表,存储了CLAUSES的原数据,CLAUSES内表里的数据实质就是来源于TRANGE内表,只是CLAUSES已经将每个表字段的条件拼接成了一个或多个条件串了(形如:“XXX字段 = XXX条件”),但是TRANGE内表与RANGES tables相同,存储的是字段最原始的条件值,使用时,在WHERE从句中使用 IN 关键字来使用这些条件值(这与SELECT-OPTIONS类型的屏幕参数用户是完全一样的)。
但是,使用TRANGE没有直接使用CLAUSES灵活,因为使用TRANGE时,WHERE从句里的条件表字段需要事先写好,这实质上不是动态条件了,可以参考以下实例,与上面CLAUSES用法相比就更清楚了:现修改上面的示例:
SELECT-OPTIONS S_CARRID FOR SCARR-CARRID.
SELECT-OPTIONS S_CONNID FOR SPFLI-CONNID.
"需要先开始动态选择条件功能
SELECTION-SCREEN DYNAMIC SELECTIONS FOR TABLE SCARR.
LDB数据库程序SAPDBZHK中,PUT_SCARR过程中使用dynamic selection的过程如下:
FORM PUT_SCARR.
STATICS: DYNAMIC_RANGES TYPE RSDS_RANGE, "存储某个表的所有屏幕字段的Ranges
DYNAMIC_RANGE1 TYPE RSDS_FRANGE,"存储某个屏幕字段的Ranges
DYNAMIC_RANGE2 TYPE RSDS_FRANGE,
FLAG_READ."确保DYN_SEL只读取一次
IF FLAG_READ = SPACE.
DYNAMIC_RANGES-TABLENAME = 'SCARR'.
"先取出 SCARR 表的所有屏幕字段的Ranges
READ TABLE DYN_SEL-TRANGE WITH KEY DYNAMIC_RANGES-TABLENAME INTO DYNAMIC_RANGES.
"再读取出属于某个字段的Ranges
DYNAMIC_RANGE1-FIELDNAME = 'CARRNAME'.
READ TABLE DYNAMIC_RANGES-FRANGE_T WITH KEY DYNAMIC_RANGE1-FIELDNAME
INTO DYNAMIC_RANGE1.
DYNAMIC_RANGE2-FIELDNAME = 'CURRCODE'.
READ TABLE DYNAMIC_RANGES-FRANGE_T WITH KEY DYNAMIC_RANGE2-FIELDNAME
INTO DYNAMIC_RANGE2.
FLAG_READ = 'X'.
ENDIF.
SELECT * FROM SCARR
WHERE CARRID IN S_CARRID
AND CARRNAME IN DYNAMIC_RANGE1-SELOPT_T"使用IN 关键字使用Ranges内表
AND CURRCODE IN DYNAMIC_RANGE2-SELOPT_T."(与select-options屏幕参数是一样的用法)
PUT SCARR.
ENDSELECT.
ENDFORM.
6.3.4.FIELD SELECTION动态选择字段
SELECTION-SCREEN FIELD SELECTION FOR NODE|TABLE
在可执行报表程序里,可以通过GET node [FIELDS f1 f2 ...] 语句中的 FIELDS选项来指定要读取字段;
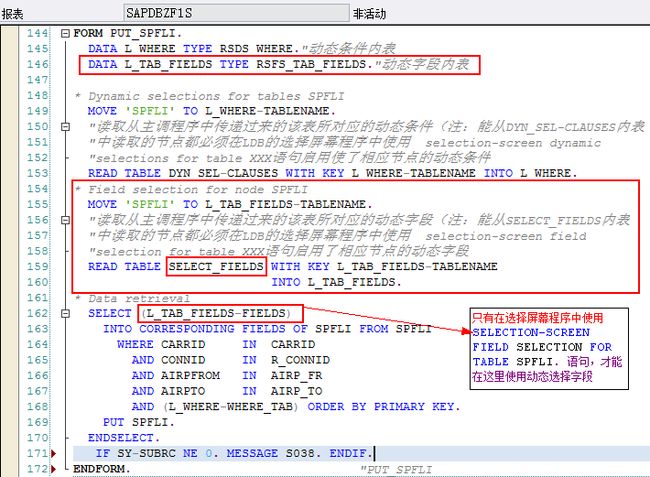
另外,上面LDB数据库程序中要能从SELECT_FIELDS内表读取数据,则必须在LDB选择屏幕里开启相应节点的动态选择字段:

其中,SELECT_FIELDS内表行结构如下:
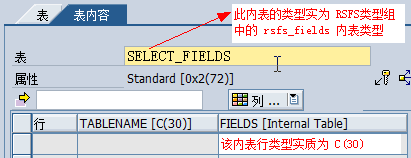

6.3.4.1.SELECT_FIELDS
PUT_
TYPE-POOLS RSFS.
DATA SELECT_FIELDS TYPE RSFS_FIELDS.
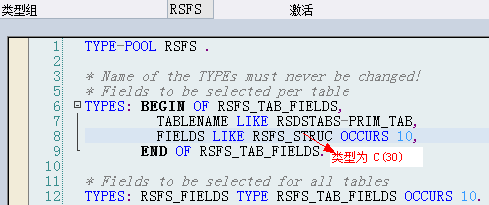
RSDS_FIELDS中的FIELDS里存储的就是GET…FIELDS…语句传递过来的用户指定的查询字段,FIELDS内表可以直接使用在 SELECT…从句中。
现假设有名为 ZHK 的LDB,SCARR为该LDB的根节点,且仅有SPFLI一个子节点。LDB选择屏幕 Include文件 DBZHKSEL内容如下:
SELECT-OPTIONS S_CARRID FOR SCARR-CARRID.
SELECT-OPTIONS S_CONNID FOR SPFLI-CONNID.
"需要先开始动态选择字段功能
SELECTION-SCREEN FIELD SELECTION FOR TABLE SPFLI.
LDB数据库程序SAPDBZHK中,PUT_SCARR过程中使用dynamic selection的过程如下:
FORM PUT_SPFLI.
STATICS: FIELDLISTS TYPE RSFS_TAB_FIELDS,
FLAG_READ."确保SELECT_FIELDS只读取一次
IF FLAG_READ = SPACE.
FIELDLISTS-TABLENAME = 'SPFLI'.
"读取相应表的动态选择字段
READ TABLE SELECT_FIELDS WITH KEY FIELDLISTS-TABLENAME INTO FIELDLISTS.
FLAG_READ = 'X'.
ENDIF.
SELECT (FIELDLISTS-FIELDS)"动态选择字段
INTO CORRESPONDING FIELDS OF SPFLI FROM SPFLI
WHERE CARRID = SCARR-CARRID AND CONNID IN S_CONNID.
PUT SPFLI.
ENDSELECT.
ENDFORM.
在相应的可执行报表程序里,相应的代码可能会是这样的:
TABLES SPFLI.
GET SPFLI FIELDS CITYFROM CITYTO.
...
GET语句中的FIELDS选项指定了除主键外需要查询来的字段,主键不管是否选择都会被从数据库表中读取出来,可以由下面报表程序中的代码来证明:
DATA: ITAB LIKE SELECT_FIELDS,
ITAB_L LIKE LINE OF ITAB,
JTAB LIKE ITAB_L-FIELDS,
JTAB_L LIKE LINE OF JTAB.
START-OF-SELECTION.
ITAB = SELECT_FIELDS. "在报表程序中也可以直接使用LDB程序中的全局变量!
LOOP AT ITAB INTO ITAB_L.
IF ITAB_L-TABLENAME = 'SPFLI'.
JTAB = ITAB_L-FIELDS.
LOOP AT JTAB INTO JTAB_L.
WRITE / JTAB_L.
ENDLOOP.
ENDIF.
ENDLOOP.
如果报表程序中的GET语句是这样的:GET SPFLI FIELDS CITYFROM CITYTO.,则输入结果为:
CITYTO
CITYFROM
MANDT
CARRID
CONNID
可以从输出结果看出,主键MANDT、CARRID、CONNID会自动的加入到SELECT_FIELDS内表中,一并会从数据库中读取出来
6.4.数据库程序中重要FORM
• FORM INIT
在选择屏幕处理前仅调用一次(在PBO之前调用)
• FORM PBO
在选择屏幕每次显示之前调用,即LDB选择屏幕的PBO事件块
• FORM PAI
用户在选择屏幕上输入之后调用,即LDB选择屏幕的PAI事件块(之后?)。
该FORM带两个接口参数FNAME and MARK将会传到subroutine 中。FNAME存储了选择屏幕中用户所选择SELECT-OPTION与PARAMETERS的屏幕字段名,MARK标示了用户选择的是单值还是多值条件:MARK = SPACE意味着用户输入了一个简单单值或者范围取值,MARK = '*'意味着用户在Multiple Selection screen 的输入(即多个条件值);FNAME = '*' 和 MARK = 'ANY',表示所有的屏幕参数都已检验完成,即可以对屏幕整体参数做一个整体的检测了(这里的意思应该就是相当于AT SELECTION-SCREEN)。
• FORM PUT_
最顶层节点
PUT
此语句用是PUT_
PUT语句是该Form(PUT_
当PUT_
首先,根节点所对应的PUT_
1. 如果LDB数据库程序包含了AUTHORITY_CHECK_
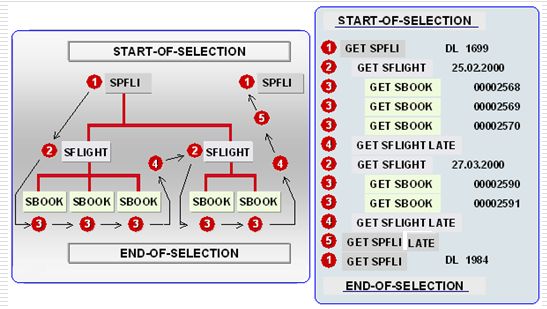




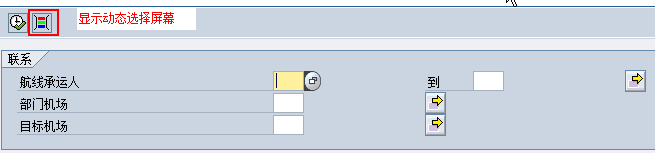
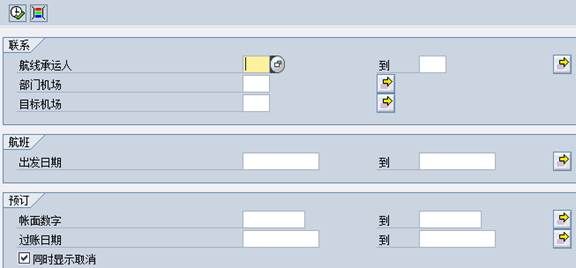


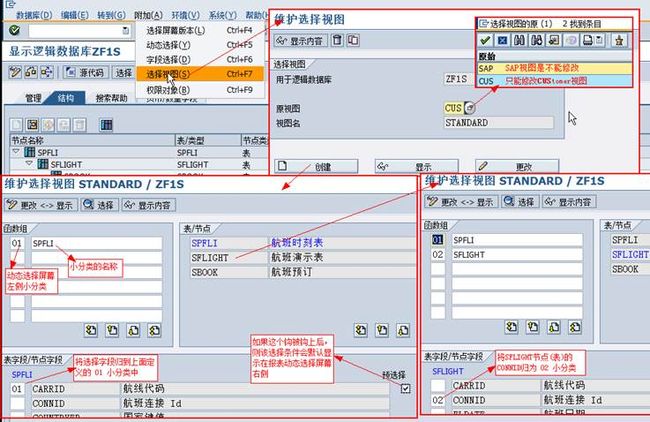
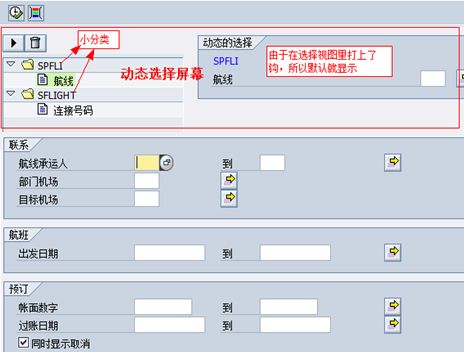


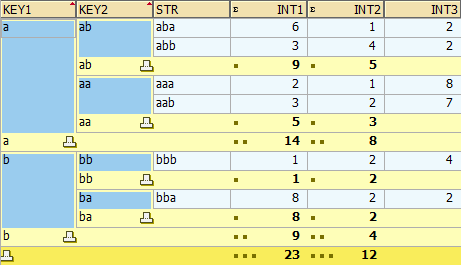
| IS_VARIANT I_SAVE I_DEFAULT |
IS_LAYOUT IT_OUTTAB IT_FIELDCATALOG |
IT_SORT |
8.5. 事件绑定、触发、回调处理
CLASS cl_event_handle DEFINITION. "定义事件处理类
PUBLIC SECTION.
"ALV工具栏初始化事件,如增加按钮并设定属性
METHODS handle_toolbar FOR EVENT toolbar OF cl_gui_alv_grid
IMPORTING e_object e_interactive.
"ALV工具栏按钮点击事件
METHODS handle_user_command FOR EVENT user_command OF cl_gui_alv_grid
IMPORTING e_ucomm.
"ALV表格双击事件
METHODS handle_double_click FOR EVENT double_click OF cl_gui_alv_grid
IMPORTING e_row e_column es_row_no.
ENDCLASS.
CLASS cl_event_handle IMPLEMENTATION."事件处理类实现部分
METHOD handle_toolbar.
gs_toolbar-function = 'B_SUM'."按钮的FunctionCode
gs_toolbar-icon = icon_display."按钮图标
gs_toolbar-text = '总行数'."按钮标签
gs_toolbar-butn_type = '0'."定义按钮类型,0为标准按钮
APPEND gs_toolbar TO e_object->mt_toolbar."添加按钮到工具栏中
ENDMETHOD.
METHOD handle_user_command.
DATA: sum TYPE i .
IF e_ucomm = 'B_SUM'.
...
ENDIF.
ENDMETHOD.
METHOD handle_double_click.
....
ENDMETHOD.
ENDCLASS.
CREATE OBJECT container_r EXPORTING container_name = 'CONTAINER_1'."创建ALV容器对象
CREATE OBJECT grid_r EXPORTING i_parent = container_r. "创建ALV控件
CALL METHOD grid_r->set_table_for_first_displayCHANGING it_outtab = gt_sflight[].
SET HANDLER :event_handle->handle_toolbar FOR grid_r, "注册处理器
event_handle->handle_user_command FOR grid_r,
event_handle->handle_double_click FOR grid_r.
CALL METHOD grid_r->set_toolbar_interactive. "调用此方法才能激活工具栏上增加的自定义按钮
8.6. CL_GUI_DOCKING_CONTAINER容器
Docking容器最大特点是在代码中可以动态创建容器,不需要像创建自定义容器CL_GUI_CUSTOM_CONTAINER那样,在创建时需要将其绑定到一个预先绘制好的用户自定义控件区域中
8.7.覆盖(拦截)预设按钮的功能FunCode:BEFORE_USER_COMMAND
在before_user_command事件中截取标准的功能,完成其他功能,然后使用方法set_user_command将功能代码修改为空(如何拦截事件,则参考事件绑定、触发、回调处理章节)
FORM handle_before_user_command USING i_ucomm TYPE syucomm .
CASE e_ucomm .
WHEN '&INFO' .
CALL FUNCTION 'ZSFLIGHT_PROG_INFO'.
CALL METHOD gr_alvgrid->set_user_commandEXPORTING i_ucomm = space.
ENDCASE .
ENDFORM .
8.8. 数据改变事件data_changed、data_changed_finished
Alv grid有两个事件:data_changed和ata_changed_finished.第一个事件在可编辑字段的数据发生变化时触发,可用来检查数据的输入正确性,第二个事件是当数据修改完成后触发
如果数据没有被修改,当失去焦点或回车时,那么它不会走data change,而是直接触发data change finish事件
可以通过CL_GUI_ALV_GRID类的REGISTER_EDIT_EVENT方法来设置在失去焦点或回车时,触发数据改变事件:
²按回车触发: i_event_id = cl_gui_alv_grid=>mc_event_enter
²单元格失去焦点: i_event_id = cl_gui_alv_grid=>mc_event_modifies
必须设置一种方式,要不然数据变化事件不会被触发事件
然后注册CL_GUI_ALV_GRID的data_changed、data_changed_finished事件,实现事件处理器方法,在数据发生改变时就会触发这两上事件
8.9.单元格可编辑
与非OO ALV是一样的,请参照
9. 问题
9.1. ALV自带导出文件时字段数据末尾被截断问题
发现有前导0时,导出会被截断:现发现VBAK-VBELN 与 MARA-MFRNR都有这个问题,可能原因是他们带有转换输出与输入规则所导致
另一种解决办法:
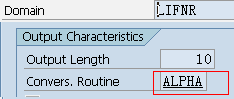
9.2. Smartform 中Template无法显示减号后面内容
在Smartform中的Template里,如果输入的变量内容含有减号,则减号后面的内容会被丢掉

问题原因:输出的内容超出了Template单元格的长度
解决办法:更改TEMPLATE的长度,或者换成 TABLE
9.3. Smartform金额或者数量字段显示不出来

数据是数量时候要在全局定义-货币/数量页签里面把要打印的数量定义成QUAN如下图

在SMARTFORM中,数量和金额类型的字段在显示的时候会和其他字段不在同一个水平面上,解决的方法:&ITAB-MENGE(C)& ,下面是SMARTFORM字段参数设置的几个注意事项:
1、使用SFSY-FORMPAGES显示总页数的时候,如果页数大于9,,将会在前10页显示成星号。解决办法:可以添加 3ZC,&SFSY-PAGE(3ZC)&/&SFSY-FORMPAGES(3ZC)&,不过可能会出现字体颠倒或者 重叠的现象,用一个单独的窗口来存放显示页码的文本,并且把窗口的类型设置为L(最终窗口)就OK了。
2、如果金额或者数量字段显示不出来的话,可以在“货币/数量字段”标签中指定相应的数据类型。
3、Field not outputting more than 255 characters in a loop. This is happening because when you send a string to smartform with length >255 characters then it takes only first 255 characters. I overcomed this problem by splitting the string which was of around 500 char into two and then sending it to smartform as individual vairables and displaying the two variables one after the other in the smartform.
将文本字段拆分成几个字符变量再连接在一起显示。
9.4. 更新数据库表时,工作区或内表的结构需参考数据库表来定义
使用使用MODIFY更新数据库表时,工作区或内表的行结构与数据库表结构中各字段声明顺序要相同,否则更新会错位,该内表最好参照数据库词典结构类型来声明,这样就不会有问题。
9.5. DELETE ADJACENT DUPLICATES…去重复
DELETE ADJACENT DUPLICATES FROM
注,在未使用COMPARING 选项时,要删除重复数据之前,一定要按照内表关键字声明的顺序来进行排序,才能删除重复数据,否则不会删除掉;如果指定了COMPARING 选项,则需要根据指定的比较字段顺序进行排序(如COMPARING
9.6.Text使用Excel打开乱码问题
如果使用GUI_DOWNLOAD函数下载文本文件,或者是发送邮件的附件,在英文XP操作系统中使用英文Excel软件打开时,请使用 UTF-16LE编码,否则可能出现乱码情况。
data: l_codepage(4) type n .
data: l_encoding(20).
"根据编码名获取对应的CodePage
callfunction'SCP_CODEPAGE_BY_EXTERNAL_NAME'
EXPORTING
external_name = 'UTF-16LE'
IMPORTING
sap_codepage = l_codepage.
l_encoding = l_codepage.
data: convout type ref to cl_abap_conv_out_ce.
convout = cl_abap_conv_out_ce=>create( encoding = l_encoding ).
convout->write( data = lv_content )."将字符按照l_encoding编码格式转换为X类型(二进制)
xstr = convout->get_buffer( ).
"在码流最前面加上编码信息,该编码由文本编辑软件在打开文件时使用
concatenate cl_abap_char_utilities=>byte_order_mark_little
xstr into xstr in byte mode.
9.7. VBFA与EKPO联合查询问题
由于VBFA-POSNN 与 EKPO-EBELP字段的类型相同,但长度不一样(VBFA-POSNN是6位的数字类型,而EKPO-EBELP为5位数字类型,但VBAP-POSNR行项目号是6位数字类型,不会出现此类问题),所以它们不能进行关联查询,相似的还有VBFA- POSNV也是6位的。下面这个关联查询是查不出数据的,只能分两次查询:
SELECT SINGLE vbeln posnn txz01 menge
INTO (it_result-ebeln, it_result-ebelp, it_result-txz01 , it_result-menge_2)
FROM vbfa AS v INNER JOIN ekpo AS e ON v~vbeln = e~ebeln AND v~posnn = e~ebelp AND e~knttp = 'E'"Where条件是根据销售单查找前置单据——采购单,V为采购单凭证类型
WHERE vbelv = it_result-vbeln AND posnv = it_result-posnr AND vbtyp_n = 'V'.
HNTTP:采购凭证中的帐户设置类型,E——生产/销售所需物料的采购
分成两个可以正常查询:
SELECT SINGLE vbeln posnn
INTO (it_result-ebeln, it_result-ebelp)
FROM vbfa AS v"Where条件是:先根据销售单查找到前置采购单的单号与行项目号
WHERE vbelv = it_result-vbeln AND posnv = it_result-posnr AND vbtyp_n = 'V'.
SELECT SINGLE txz01 menge
INTO (it_result-txz01, it_result-menge_2)
FROM ekpo"Where条件是:再根据前面查出来的采购单号与行项目号,查出EKPO其他详细信息
WHERE ebeln = it_result-ebeln AND ebelp = it_result-ebelp AND knttp = 'E'.
10.技巧
10.1.让READ TABLE...WITH KEY可使用OR条件或其他非“=”操作符
READ TABLE...WITH KEY... 后面不能接OR条件操作符,也不能使用其他非等于的比较操作符,因原是该语句即使在查询出多条时也只取第一条,所以限制了 WITH KEY 后面条件使用。下面是错误的语法:
READ TABLE it_tab WITH KEY k1 = 'C' OR k2 = 'C'.
可以使用下面方式代替:
LOOP AT il_item_status WHERE k1 = 'C' OR k2 = 'C'.
...
EXIT.
ENDLOOP.
10.2.SELECT SINGLE ... WHERE...无法排序问题
SELECT SINGLE ... WHERE ...
使用SINGLE是表示根据表的关键字来查询,这样才能确保只有一条数据,所以当使用SINGLE时,语法上不能再使用ORDER BY语句(因为没有必要了),如果查询时不是根据关键字来查询,且查询时先排序再取一条时,我们只能使用另一种语法:
SELECT * FROM tj02t INTO CORRESPONDING FIELDS OF TABLE gt_result UP TO 1 ROWS
WHERE SPRAS = 'E' ORDER BY ISTAT.
如果是取某个最大值或最小值,则可以使用聚合函数更简洁:
SELECT MIN( edatu ) INTO (g_tabcon_mps_wa-edatu)FROM vbep
WHERE vbeln = ztab_mps-vbeln AND posnr = ztab_mps-posnr.
10.3.当心Where后的条件内表为空时
在Select、If、Delete 内表、read、look at内表语句中的Where条件中,如果使用的Range是一个空的条件内表,则 xx IN range恒为真,那么xx NOT IN range则恒为假。
注:不会像FOR ALL ENTRIES那样,忽略其他的条件表达式,其他条件还是起作用
10.4.快速查找SO所对应的交货单DN及PO
快速查找SO(VBAP)所对应的DN(LIPS):虽然可以通过vbap-vbeln = lips-vgbel AND vbap-posnr = lips-vgpos来关联查找,但LIPS-VGBEL、LIPS-VGPOS非主键,查找起来非常慢(但根据DN来查找所的SO是很快的,因为此时为主键查找)但可以通过VBFA单据流表来查找DN,这样会非常快,因为这是根据主键来查找的:
vbfa~vbelv = vbap-vbeln AND vbfa~posnv = vbap-posnr AND vbfa~vbtyp_v ='C' AND vbfa~vbtyp_n = 'J'
另外,根据SO查找PO时,可以根据EKKN-VBELN= VBAP-VBELN AND EKKN-VBELP=VBAP-POSNR到SO与PO中间表EKKN里去找,但查找条件为非主键也非索引,所以找起来时很慢,可以通过VBFA单据流表进行查找,因为VBFA在vbeln、posnn 字段上创建了索引(虽然查询时WHERE从句条件字段不是按主键字段顺序——使用的是后半部分主键,所以用不到主键索引,但是是按非主键索引字段顺序书写,所以还是可以用到索引):vbfa~vbeln = vbap-vbeln AND vbfa~posnn = vbap-posnr AND vbfa~vbtyp_v ='V' AND vbfa~vbtyp_n = 'C'
10.5.X类型的C类型视图
"江 <--> 6C5F
"正 <--> 6B63
*DATA: x(4) TYPE x VALUE '6C5F'.
DATA: x(2) TYPE x VALUE '6C5F'.
FIELD-SYMBOLS:
"有时将X类型分配给C类型时会出错(长度需要是4的倍数,所以定义成4的倍数
"即可解决这个问题,但有时定义的长度只能是某个特定数,所以此时只能使用后面这种方式)
"编译时报错误:The length of "X" in bytes must be a multiple of the size of
"a Unicode character, regardless of the size of the Unicode character.
*ASSIGN x to
"只能先定义一个C类型变量,再将这个C类型变量分配给X类型字段符号,这样就可
"以随便在x类型之间捣腾了,但此时C变量不是X变量的真正视图了(经过了拷贝)
DATA: c(1) .
FIELD-SYMBOLS:
ASSIGN c to
"江 6C5F注:如果输出的是乱码,则是字节序的问题,需写成5F6C(如Windows操作系统中)
WRITE: /(2) c,
"正 6B63注:如果输出的是乱码,则是字节序的问题,需写成636B(如Windows操作系统中)
x = '6B63'.
WRITE: /(2) c,
10.6.字符串连接:&& 替代 CONCATENATE
有如将整型(I)与一个字符串(String)进行连接,此时不能直接使用CONCATENATE进行连接,因为CONCATENATE 操作的是字符类型,所以需要将整型转换为字符型后才能使用CONCATENATE 进行连接,但这里需要注意的,当正整型变量转换为字符类型时,符号位会转换为空格,这时使用CONCATENATE 接连得到的字符串可能会多出一个空格;当将整型变量与字符串进行连接时,最好使用 && 操作符,除了直接能连接外,还不会出现多余空格的问题:
DATA: i TYPE i VALUE '10'.
DATA: str TYPE string VALUE 'string'.
DATA: tmp TYPE string.
str = i && str.
WRITE: / str.
tmp = i.
CONCATENATE tmp str INTO str.
WRITE: / str.

10.7. Variant变式中动态日期
报表程序的选择屏幕中,输出条件后可以点击保存按钮,会弹出创建变式的屏幕,如果条件中有日期字段,日期字段可以随着时间变化,日期字段的值也可以动态的变化,如对于每天都要跑的Job报表很有用,每天查询当天。当然也可以通过报表程序的INIT事件里动态获取当前日期,但可能需要修改程序

除用在中Job外,变式还可以用在Tcode中
11.优化
降低CPU负荷(减少循环次数)、降低DB负荷(减少IO操作)、降低内存使用(减少内表大小)
11.1.数据库
1. 不要使用 SELECT * ...,选择需要的字段, SELECT * 既浪费CPU,又浪费网络带宽资源,还需占用大量的ABAP内存
2. 不要使用SELECT DISTINCT ...,会绕过缓存,可使用 SORT BY + DELETE ADJACENT DUPLICATES 代替
3. 少用相关子查询,因为子查询对外层查询结果集中的每条记录都会执行一次
4. 少用嵌套SELECT … ENDSELECT,可以使用联合查询或FOR ALL ENTRIES来替换,减少循环次数
5. 如果确定只查一条数据时,使用 SELECT SINGLE... 或者是 SELECT ...UP TO 1 ROWS ...
6. 统计时,直接使用SQL聚合函数,而不是将数据读取出来后在程序里再进行统计
7. 使用游标读取数据,这样省掉了将从数据库中的取记录放入内表的INTO语句这一过程开销
8. 多使用inner join,必要时才使用left join
9. inner join获取数据时,尽量不要用太多的表关联,特别是大表关联,关联顺序为:小表-大表
10.where 条件里面多用索引、主键,顺序也要遵循小表-大表
11.inner join条件放置的位置应该按照 On、Where、Having的顺序放,因为SQL条件的的执行一般是按这个顺序来执行的,将条件放在最开始执行,则可过滤掉大部数据;但要注意Left Outer Join,是否可以将ON中的条件移动到Where从句则要考虑(如果真能放在Where从句中,则应该使用Inner Join,而非Left Outer Join,因为Where条件会过滤掉那些包括在右表中不存在的左表数据),因为此时条件放在On后面与放在Where语句后面结果是不一样的(因为不管on中的条件是否为真,左表中在右边表不存在的数据也会被返回,但如放在where条件中,则会对On产生的数据再次过滤的条件,会滤掉不满足条件的记录——包括左表在右表中找不到的记录,这时已经没有left join的含义)
12. 要根据主键或索引字段查找数据,且WHERE从句中的条件字段需按INDEX字段顺序书写,且将索引字段条件靠前(左边),如:在VBFA表中查找SO所对应的交货单DN,因为如果直接到LIPS中找时,SO的订单中号与行号在LIPS中非主键,但在VBFA是部分主键(VBFA中根据部分主键查找 SO -> DN; 根据索引查找 SO -> PO,VBFA-VBELN+VBFA-POSNN组合字段上创建了索引,即根据SO找PO时,不要从EKKN关联表中查找,而是通过VBFA中查找。后来查看EKKN,发现在VBELN+VBELP字段上创建了索引,所以从VBFA与EKKO查找应该差不多,主要看哪个表数据量少的问题了)
检查条件组合字段是否是主键,或者是上在上面创建了索引,避免条件组合字段即不是主键又没有索引
13. SELECT语句WHERE条件,应该先将主键相关条件放在前面 然后按照比较符 = 、< 、>、 <> 、LIKE IN 的顺序排列WHERE条件
14.使用部分索引字段问题:如果一个索引是由多个字段组成的,只使用一部分关键字段来进行查询时,也是可以使用到索引,但使用时要注意要按照索引定义的顺序且取其前面部分
15. 请根据索引字段进行ORDER BY,否则通过程序进行SORT BY。与其在数据库在通过非索引字段进行排序,不如在程序中使用SORT BY语句进行排序,因为此情况下应用服务器上的执行速度要比数据库服务器快(应用服务器上采用的是内存排序)
16.避免在索引字段上使用:
l not、<>、!=、IS NULL、IS NOT NULL,可以用> 与 < 来替代
l 避免使用 LIKE,但LIKE '销售组1000'和LIKE '销售组1000%'可以用到,而LIKE '%销售组1000'(百分号前置)则用不到索引
l 不要使用OR来连接多个索引字段(但同一字段多个值之间可以使用OR);对于同一索引字段,可以使用IN来替代OR:

l带有BETWEEN 的WHERE 条件不能通过索引来搜索?也可使用IN代替
17.避免使用以下语句,因为使用这些语句时,不能使用 Table Buffer:
l Aggregate expressions
l Select distinct
l Select … for update
l Order by、group by、having从句
l Joins,使用JOIN时,会绕过SAP缓存,可以使用FOR ALL ENTRIES来代替
l WHERE从句中使用Sub queries(子查询)
l WHERE从句中使用IS NULL条件
18.在下面情况下使用FOR ALL ENTRIES IN:
l在循环内表 LOOP...AT Itab中循环访问数据库时
l簇表是禁止JOIN的表类型, 当需要联接簇表查询数据时,如:BSEG(会计凭证)、KONV(条件表)
簇表一般是由多个表组成,簇表中的数据来自于多个表,有点像视图,但不能直接通过簇表进行数据维护
lJOIN超过3个表会出现性能问题, 当使用JOIN联接的表超过3个时
l如果两个表的数据非常大时(上百万),使用JOIN进行联合查询会很慢,此时改用FOR ALL ENTRIES IN
19.使用内表批量操作数据库,而不要使用工作区一条条操作,如:
SELECT ... INTO TABLE itab
INSERT dbtab FROM TABLE itab
DELETE dbtab FROM TABLE itab
UPDATE/MODIFY dbtab FROM TABLE itab
20.如果你使用 CLIENT SPECIFIED,需在WHERE从句第一个位置上指明 MANDT条件,否则使用不到索引
11.2.程序
1. READ TABLE ...WITH [TABLE] KEY...BINARY SEARCH读取标准内表使用二分查找
2. 在循环(LOOP AT ...WHERE..)或查询(READ TABLE ...)某内表时,如果未使用索引(排序表、哈希表)或二分查找,则在查询组合字段创建第二索引,查询时通过USE KEY或WITH [TABLE] KEY选项使用第二索引,这样在查询时会自动进行二分查找或哈希找查
在没有用二分查找的情况下,可在查询组合字段上创建第二索引(哈希或排序索引),则在读取或循环内表时会自动使用二分查找或哈希查找算法
3. 查找时,优先考虑使用哈希表进行查找,再考虑使用排序表进行二分查找,因为哈希查找的时间复杂度为(O (1)),不会因数据的增加而受到影响;而二分查找虽然比顺序搜索快很多,但随着数据的增加会慢下来,其时间复杂度为(O (log2n));标准内表的时间复杂度为O(n)。注:如果只使用到部分关键字为搜索条件,哈希表则会全表扫描,此时应该使用二分找查
4. FOR ALL ENTRIES:需要判断内表是否为空,否则会查询出所有数据
5. LOOP AT itab... ASSIGNING ...、READTABLE ...ASSIGNING ... 在循环或读取内表时,使用字段符号来替换表工作区,将数据分配给字段符号Field Symbols,减少数据来回传递
6. 尽量避免嵌套循环,如必须时,将循环次数少的放在外层,次数多的放在内层,这样可以减少在不同循环层之间的频繁地切换及内部循环次数
7. 条件语句中多使用短路与或,“与”连接时将为假的机率大的条件放在前面,“或”连接时将为真的机率大的条件放在前面
8. 少使用递归算法,递归时会增加调用栈层次,降低了性能,可使用队列或栈来避免递归
9. 尽量不要使用通用类型(如FIELD-SYMBOLS、及形式参数),使用具体限定类型;比较时尽量使用同一数据类型:IF c = c.比IF i = c.快,原因是未发生类型转换
10.不要使用混合类型进行计算与比较,除非有必须
11.尽量使用静态语句,少用动态编程,动态编辑虽然灵活,但性能有所下降
12.在对字符进行操作进,尽量使用String代替C固定长度类型,如:concatenate[kənˈkatɪneɪt]语句对固定长度的C连接时,会去扫描那些非空字符出来再进行连接,速度没有String快
13.READ/MODIFY TABLE时使用TRANSPORTING只读取或修改必要的字段 [trænsˈpɔ:t]
14.尽量避免使用MOVE-CORRESPONDING和 SELECT...INTO CORRESPONDING FIELDS OF [TABLE] (SELECT时,查询几个字段就定义具有这几个字段的内表,而不是直接使用基于数据库表类型创建的内表,否则如果直接使用 INTO TABLE语法检查时会警告,但结果是没有问题的)。CORRESPONDING语句在系统内部存在隐式操作: 逐个字段的检查元素名称匹配; 检查元素类型匹配;元素类型转换;[ˌkɔrisˈpɔndiŋ]
15.最好不要向排序内表中插入(INSERT ... INTO TABLE ...)数据,因为在插入时会进行排序,速度会随着数据量的增加而慢下来,所以最好只向标准内表或哈希表中插入数据
16.将某个内表中的全部记录或部分记录追加到另一内表时,使用INSERT/APPEND LINES OF … 代替循环逐条追加;如果是全新赋值,直接对内表使用“=”进行赋值操作即可
17.调用类方法要快于Function:
Calling Methods of global Classes: call method CL_PERFORMANCE_TEST=>M1.
Calling Function Modules: call function 'FUNCTION1'.
18.通过运行事务代码SLIN(或者直接通过SE38的菜单),进行代码静态检查,根据SAP提供的反馈信息,优化代码
19.通过老式方式定义内表时,使用OCCURS 0 而非OCCURS n :[əˈkə:s] 重现
lOCCURS n 代表初始化内表的空间大小为n(空间固定),当内表存储记录条数超出n时,系统将依靠页面文件存放超出部分的数据。 当系统内存资源十分紧缺的时候,我们可以使用OCCURS n的初始化方法, 但是这样的效率稍微慢
lOCCURS 0 代表初始化内表的空间大小为无限,当内表存储记录条数不断增加时, 内表所使用的内存空间不断扩大, 直到系统无法分配为止。使用内存比使用页面交换更快一些, 但是要考虑系统的资源状态
20.使用完成后及时清空释放内表所占用的空间:FREE
21.使用CASE…WHEN语句代替 IF…ELSEIF…;使用WHILE…ENDWHILE 代替 DO…ENDDO
22.LOOP循环内表时加上Where条件减少CPU负荷,而不是在循环里通过IF语句来过滤数据
12.屏幕
12.1.AT SELECTION-SCREEN、PAI、AT USER-COMMAND触发时机
当点击屏幕上元素(包括按钮、单选复选按钮、下拉列表、菜单、工具条)时,选择屏幕触发的是AT SELECTION-SCREEN(不是AT USER-COMMAND 事件),对话屏幕触发的PAI事件,列表屏幕触发的才是AT USER-COMMAND事件
12.2.SELECTION-SCREEN格式化屏幕、激活预设按钮
SELECTION-SCREEN SKIP 空行
SELECTION-SCREEN ULINE 水平线
SELECTION-SCREEN COMMENT text FOR FIELD sel 文本标签
SELECTION-SCREEN PUSHBUTTONbt_text USER-COMMAND fcode 按钮
SELECTION-SCREEN BEGIN OF LINE 多元素行
SELECTION-SCREEN BEGIN OF BLOCK block 屏幕块
SELECTION-SCREEN BEGIN OF TABBED BLOCK tblock Tabstrip
SELECTION-SCREEN FUNCTION KEY n 激活工具栏中预设按钮
SELECTION-SCREEN BEGIN OF SCREEN dynnr [AS SUBSCREEN] 定义屏幕或子屏幕
12.3. PARAMETERS
PARAMETERS {para[(len)]}|{para [LENGTH len]}
type_options [{ TYPE type [DECIMALS dec] }| { LIKE dobj }| { LIKE (name) }]
screen_options[{ {[OBLIGATORY|NO-DISPLAY] [VISIBLE LENGTH vlen]}
| {AS CHECKBOX [USER-COMMAND fcode]}
| {RADIOBUTTON GROUP group [USER-COMMAND fcode]}
| {AS LISTBOX VISIBLE LENGTH vlen [USER-COMMAND fcode][OBLIGATORY]}}
[MODIF ID modid]]
value_options[DEFAULT val][LOWER CASE][MATCHCODE OBJECT hp][MEMORY ID pid][VALUE CHECK]
OBLIGATORY:如果某个屏幕输入元素处于隐藏状态,即使它是必输入的,则在提交时也不会提示你必输入(但如果是必须的,在隐藏前一要输入,否则会出错并要求重新输入),只有在显示状态时且不输入时才会提示
MODIF ID key:设置修改组代码,方便屏幕的元素的批量修改,key中设定的代码将被赋给系统内表SCREEN-GROUP1字段
MATCHCODE OBJECT:指定一个search_help
MEMORY ID pid:通过SAP Memory进行同一用户会话不同窗口间的参数传递
VALUE CHECK:开启系统自动检验(如果屏幕元素参照的数据元素所对应的Domain设置了fixed Values、Value Table)
PARAMETERS: p_check as CHECKBOX USER-COMMAND chk
PARAMETERS: p_radio1 TYPE c RADIOBUTTON GROUP g1 USER-COMMAND rbt,
p_radio2 TYPE c RADIOBUTTON GROUP g1.
PARAMETERS p_carri2 LIKE spfli-carrid
AS LISTBOX VISIBLE LENGTH 20
USER-COMMAND lst
12.4. SELECT-OPTIONS
SELECT-OPTIONS selcrit FOR {dobj|(name)}
screen_options[OBLIGATORY|NO-DISPLAY][VISIBLE LENGTH vlen][NO-EXTENSION][NO INTERVALS][MODIF ID id]
value_options [DEFAULT val1 [TO val2] [OPTION opt] [SIGN sgn]][LOWER CASE]
[MATCHCODE OBJECT search_help][MEMORY ID pid]
该语句会生成一个名为selcrit选择条件内表,具体请参数OPEN SQL章节中的 RANG条件内表
NO-EXTENSION:限制选择表为单行,元素输入后面不会出现![]() 按钮 [iksˈtenʃən]
按钮 [iksˈtenʃən]
NO INTERVALS:只会出现LOW字段,To后面的HIGH字段不出现在选择屏幕上,但是用户仍然可以在Mutiple Selection窗口中输入范围选择。也就是说:只要有![]() 按钮,就可以选择多个条件与范围值 [ˈintəvəl]
按钮,就可以选择多个条件与范围值 [ˈintəvəl]
OBLIGATORY:只有前面一个框框中出现钩,第二个框没有,也就是说该选项只能LOW字段有效 [əˈblɪgəˌtɔ:ri:]
DEFAULT:
TABLES: mara,marc.
SELECT-OPTIONS:werks FOR marc-werks OBLIGATORY DEFAULT 1001 TO 1007 SIGN I OPTION BT.
SELECT-OPTIONS:p2 FOR mara-matnr MODIF.
AT SELECTION-SCREEN OUTPUT.
p2-low = 'aaaa'.
APPEND p2 .
MEMORY ID:将第一个输入框中的数据存放到SAP MEMORY中共享
12.4.1.输入ABAP程序默认值时,需要加上“=”
![]()
如果输入框中输入的值恰为ABAP程序中相应字段所对应的初始值时(如字符类型为空串,时间与数字类型为“0”串时),需要在第一个框前面选择![]() 操作符,否则程序将会忽略这个值的输入,即查询所有的
操作符,否则程序将会忽略这个值的输入,即查询所有的
12.4.2.选择条件内表多条件组合规则
((Select Single Values OR…) OR(Select Intervals OR…))( AND NOT Exclude Single Values) … ( AND NOT Exclude Intervals) …



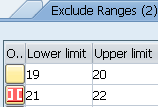
("MATNR" = '1' OR "MATNR" >= '2' OR "MATNR" <= '3' OR "MATNR" > '4' OR "MATNR" < '5' OR "MATNR" <> '6' OR "MATNR" <> '7' OR "MATNR" LIKE '23%' OR NOT ( "MATNR" LIKE '24_' ) OR "MATNR" BETWEEN '8' AND '9' OR NOT ( "MATNR" BETWEEN '10' AND '11' )) AND "MATNR" <> '12' AND "MATNR" < '13' AND "MATNR" > '14' AND "MATNR" <= '15' AND "MATNR" >= '16' AND "MATNR" = '17' AND "MATNR" = '18' AND NOT ( "MATNR" LIKE '25%' ) AND "MATNR" LIKE '26_'AND NOT ("MATNR" BETWEEN '19' AND '20' ) AND "MATNR" BETWEEN '21' AND '22'
12.4.3.使用SELECT-OPTIONS替代PARAMETERS
实际上PARAMETERS 类型的参数完全可以使用SELECT-OPTIONS来替代,下面就是使用这种替换方式,外表看上去与PARAMETERS是一样的,但双击后可以出现操作符选择界面,所以唯一不同点就是这个可以选择操作符,而且这样做的好处是:当不输入值时,查询所有的,但PARAMETERS值为空是查询就是为空(或0)的值(如果此时要忽略这个条件,则要将单值转换为Rang或者是分两种情况来写SQL条件):
TABLES: marc.
SELECT-OPTIONS: s_werks FOR marc-werks NO INTERVALS NO-EXTENSION.
12.5.各种屏幕元素演示
TABLES: mara,marc.
DATA: g_pg(24).
SELECTION-SCREEN BEGIN OF BLOCK bk1 WITH FRAME TITLE text-001.
PARAMETERS: p_bukrs LIKE t001-bukrs OBLIGATORY."Company code
SELECT-OPTIONS:
s_werks FOR marc-werks OBLIGATORY NO INTERVALS,
s_matnr FOR mara-matnr NO-EXTENSION ,
s_segme FOR g_pg."参照普通变量
PARAMETERS: p_line(6).
SELECTION-SCREEN SKIP 1.
PARAMETERS: p_x1 RADIOBUTTON GROUP gp1 DEFAULT 'X',
p_x2 RADIOBUTTON GROUP gp1.
PARAMETERS: p_old TYPE c AS CHECKBOX.
PARAMETERS: p_oldhir LIKE grpdynp-name_coall MODIF ID m1 DEFAULT 'ABB_CHINA.XXXX'.
SELECTION-SCREEN:SKIP 1.
SELECTION-SCREEN BEGIN OF LINE.
PARAMETERS: p_dwload AS CHECKBOX.
SELECTION-SCREEN COMMENT 5(29) text-001.
PARAMETERS: p_file TYPE string.
SELECTION-SCREEN END OF LINE.
SELECTION-SCREEN END OF BLOCK bk1.
12.6. 按钮、单选复选框、下拉框的FunCode
如果复选框与单选按钮没有设置Function Code,则它们就会像普通的输入框一样,即使状态发生了改变,也不会触发PAI事件
对话屏幕中的按钮、复选框、单选按钮、下拉框的Function Code都是通过屏幕元素 attributes来设置的;选择屏幕中的FunCode则通过USER-COMMAND选项来设置
12.6.1.选择屏幕中的按钮
SELECTION-SCREEN:PUSHBUTTON 2(12) but1 USER-COMMAND cli1.
INITIALIZATION.
but1 = 'Button 1'."可直接设置按钮上的标签文本
AT SELECTION-SCREEN.
CASE sy-ucomm.
WHEN 'CLI1'.
ENDCASE.
12.6.2.选择屏幕中的单选/复选按钮:点击时显示、隐藏其他屏幕元素
更多请参考动态修改屏幕章节
PARAMETERS show_all AS CHECKBOX USER-COMMAND flag.
PARAMETERS hide RADIOBUTTON GROUP rd USER-COMMAND flag2 DEFAULT 'X'.
PARAMETERS show RADIOBUTTON GROUP rd .
SELECTION-SCREEN BEGIN OF BLOCK b1 WITH FRAME .
PARAMETERS: p1 TYPE c LENGTH 10 ,
p2 TYPE c LENGTH 10.
SELECTION-SCREEN END OF BLOCK b1.
SELECTION-SCREEN BEGIN OF BLOCK b2 WITH FRAME TITLE t.
PARAMETERS: p3 TYPE c LENGTH 10 MODIF ID bl2,
p4 TYPE c LENGTH 10 MODIF ID bl2.
SELECTION-SCREEN END OF BLOCK b2.
SELECTION-SCREEN BEGIN OF BLOCK b3 WITH FRAME .
PARAMETERS: p5 TYPE c LENGTH 10 MODIF ID bl3,
p6 TYPE c LENGTH 10 MODIF ID bl3.
SELECTION-SCREEN END OF BLOCK b3.
INITIALIZATION.
t = '----ALL----'.
"单先与复选框、下拉列表项点击触发PAI后,接下来还会触发屏幕的PBO(回车也是这样),但如果点击的是执行按钮,则不会接着触发屏幕的PBO,除非没有输出或在Basic List列表页面上点击返回按钮时,才会触发PBO
AT SELECTION-SCREEN OUTPUT.
LOOP AT SCREEN.
IF show_all = 'X' AND screen-group1 = 'BL2'.
screen-active = '1'."显示
MODIFY SCREEN.
ELSEIF screen-group1 = 'BL2'.
screen-active = '0'."隐藏
MODIFY SCREEN.
ENDIF.
IF show = 'X' AND screen-group1 = 'BL3'.
screen-active = '1'.
MODIFY SCREEN.
ELSEIF screen-group1 = 'BL3'.
screen-active = '0'.
MODIFY SCREEN.
ENDIF.
ENDLOOP.
12.6.3.选择屏幕中下拉列表:AS LISTBOX
如果参照的字段只有检查表,没有搜索帮助时,且检查表有对应的T表,则Value为T表第一个文本字段值?
下拉框基本上与F4搜索帮助数据一致,但发现参照某些表字段时(如spfli-cityfrom)下拉框中没有值:
PARAMETERS p_carri1 LIKE SPFLI-CARRID.
PARAMETERS p_carri2 LIKE spfli-carrid
AS LISTBOX VISIBLE LENGTH 20
USER-COMMAND onli
DEFAULT 'LH'.
除了通过参数表字段外,还可以通过VRM_SET_VALUES函数为下拉框初始化列表项
12.7. 屏幕流逻辑
PROCESS BEFORE OUTPUT.
PROCESS AFTER INPUT.
PROCESS ON HELP-REQUEST.
PROCESS ON VALUE-REQUEST.
12.7.1.FIELD
FIELD
使用FIELD语句后,屏幕字段
FIELD
仅只有未出现在FIELD语句中的屏幕字段才会在PAI事件块处理前传输到ABAP程序中去。所以当某个屏幕字段出现在FIELD语句中,并且在该 FIELD语句未执行完之前,不要在PAI dialog modules中使用该屏幕字段(该屏幕字段相关的FIELD语句执行完成之后才可以在后续的PAI dialog modules调用中使用),否则,ABAP程序同名字段中的值使用的是前一次对话屏幕中所设置的值。
12.7.2.MODULE
FIELD dynp_field MODULE mod [ {ON INPUT}
| {ON REQUEST}
| {ON *-INPUT}
| {ON {CHAIN-INPUT|CHAIN-REQUEST}}
| {AT CURSOR-SELECTION}.
• ON INPUT:只要该字段不为初始值就会触发module
• ON REQUEST:该字段发生变化后触发module
FIELD
CHAIN.
FIELD:
MODULE
FIELD:
MODULE
...
ENDCHAIN.
只要
CHAIN.
FIELD:
FIELD
MODULE
ENDCHAIN.
12.7.3.ON INPUT与ON CHAIN-INPUT区别
CHAIN.
FIELD: f1,f2.
FIELD: f3 MODULE mod1 ON INPUT. 只有f3为非初始值时才调用mod1
ENDCHAIN.
CHAIN.
FIELD:f1,f2.
FIELD:f3 MODULE mod1 ON CHAIN-INPUT. f1,f2,f3中任一字段包含非初始值时都调用mod1
ENDCHAIN
如果不在 CHAIN中时,不能像下面这样写:
FIELD a. "FIELD与MODULE只能写在同一语句当中
MODULE check_a ON INPUT.
只有在CHAIN中时,MODULE语句才可以单独出现(不与FIELD在同一语句中),且只能是CHAIN-INPUT:
MODULE mod1 ON CHAIN-INPUT.
12.8.EXIT-COMMAND
12.8.1.MODULE AT EXIT-COMMAND
对话屏幕中,对于E类型的Function Code,可以使用如下语句在PAI事件块中来触发:
MODULE
不管该语句在screen flow logic的PAI事件块里的什么地方,都会在字段的约束自动检测之前执行,因此,此时其他的屏幕字段的值不会被传递到ABAP程序中去,当该MODULE执行完后,如果未退出该屏幕,则会进行正常PAI(即PAI事件块里没有带EXIT-COMMAND选项的MODULE语句)事件块。
该语句在字段约束自动检测之前会被执行,一般用来正常退屏幕来使用,如果未使用LEAVE语句退出屏幕,则会在这之后还会继续进行字段的自动检测,检测完后还会继续PAI的处理(即执行PAI事件块中不带EXIT-COMMAND选项的MODULE语句)
12.8.2.AT SELECTION-SCREEN ON EXIT-COMMAND
在选择屏幕上,对于E类型的FunCode(如点击![]() )会触发AT SELECTION-SCREEN ON EXIT-COMMAND事件
)会触发AT SELECTION-SCREEN ON EXIT-COMMAND事件
12.9.OK_CODE
如果是回车(命令行中未输入内容时回车)时,由于FunctionCode为空,所以SYST-UCOMM 、SY-UCOMM、OK_CODE都不会被重置;如果非回车,但FunctionCode也是空时,SYST-UCOMM、SY-UCOMM会被重置,但OK_CODE还是不会被重置,所以OK_CODE只有在FunCode非空时才会被重置
12.9.1.ok_code使用前需拷贝
如果一个屏幕中的某个按钮未设置Function Code时也是可以触发PAI事件时,并且由于其Function Code此时为空而不会去设置OK_CODE(但此时SYST-UCOMM 或 SY-UCOMM还是会被重新设置为空),这样的话OK_CODE中的值还为上一次触发PAI时所设置的Function Code。所以一般情况下在使用OK_CODE之前,先将OK_CODE拷贝到SAVE_OK变量中(在后面的程序使用SAVE_OK而不是OK_CODE),并随后将OK_CODE清空,以便为下一次PAI事件所使用做准备
其实还有一种方案可能替换这种使用前拷贝方案:就是还是针对OK_CODE编程,不另外定义save_ok,而是在每个屏幕的 PBO 里将ABAP中的OK_CODE清空。
12.10.Search help (F4)
12.10.1. VALUE CHECK、fixed Values、Value Table
PARAMETERS p_1 TYPE zmy_dm_200 VALUE CHECK."注:SELECT-OPTIONS没有此选项
如果选择屏幕字段参考数据元素所对应的Domaim设置了固定值(fixed Values)或值表(Value Table)时,使用VALUE CHECK选项后,会验证输入值是否在固定值或值表范围之内
若要使值表检查生效,则首先需要将此Domain引用到表字段,再对此表字段通过![]() 按钮进行外键分配,并且外键一定是来自的值表的主键,最后使用PARAMETERS定义屏幕参数时要参照此表(从表)字段(类型参照了该DataElement的字段),否则如果只是直接参照所对应的DataElement是不起作用,即Value Table一定要经过转换为Check Table后再起作用,并且PARAMETERS要参照此表字段。比如这上面PARAMETERS示例语句中直接使用的是zmy_dm_200这个DataElement,这样即使该DataElement所对应的Domain设置了ValueTable,ValueCheck不会起使用,也不会显示F4帮助(但如果设置了Fixed Value则会显示F4帮助)
按钮进行外键分配,并且外键一定是来自的值表的主键,最后使用PARAMETERS定义屏幕参数时要参照此表(从表)字段(类型参照了该DataElement的字段),否则如果只是直接参照所对应的DataElement是不起作用,即Value Table一定要经过转换为Check Table后再起作用,并且PARAMETERS要参照此表字段。比如这上面PARAMETERS示例语句中直接使用的是zmy_dm_200这个DataElement,这样即使该DataElement所对应的Domain设置了ValueTable,ValueCheck不会起使用,也不会显示F4帮助(但如果设置了Fixed Value则会显示F4帮助)
注:如果要使用VALUE CHECK选项,则Domain的类型只能是C或者N类型,否则运行会抛异常。

PARAMETERS c TYPE sflight-carrid VALUE CHECK."应该是这样,参照的是从表字段(主表为值表)
PARAMETERS c TYPE s_conn_id VALUE CHECK."而不应该直接参照DataElement,不会出现F4帮助,也不会进行Value Check
12.10.2.检查表Check Table --- Value Table
也可以在Domain中指定一个值表(Value Table)作为字段取值范围的限制,但是与指定固定值的方式不同的是:为一个Domain简单地指定一个取值表不会导致用户的输入被自动校验,也不会自动出现F4 Help。只有通过表外键![]() 按钮将该Value Table指定为主表之后,一个值表才能真正成为Check Table。所以要想成为真正有效的Check Table,必须要做两个操作:
按钮将该Value Table指定为主表之后,一个值表才能真正成为Check Table。所以要想成为真正有效的Check Table,必须要做两个操作:
一是要为字段对应的Domain设置Value Table(即主表,其实这一步不是必须的,在通过![]() 按钮指定主表时,可以不用指定为字段所参照的元素所对应Domain所设置的Value Table,而是指定其他的主表也是可以的——但最好不要这样做,Value Check时会出其他问题),二是要为表字段通过
按钮指定主表时,可以不用指定为字段所参照的元素所对应Domain所设置的Value Table,而是指定其他的主表也是可以的——但最好不要这样做,Value Check时会出其他问题),二是要为表字段通过![]() 为它设置外键。
为它设置外键。
实质上Domain上设置的 Value Table的作用,就是在创建透明表时,字段如果参照了该Domain,则这个Value Table默认可以成为Check Table:

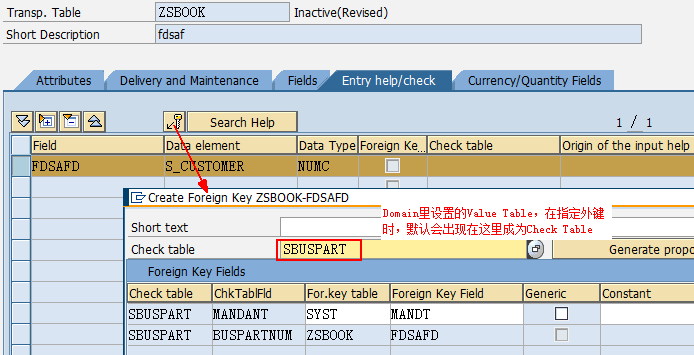
这是个默认建议,在指定外键关键时,可以指定另外的表作为Check Table
12.10.3.SE11检查表与搜索帮助关系
当某个表字段有检查表,并且又有搜索帮助,则数据一般来自源于检查表,而F4的输入输出格式则由搜索帮助来决定!
PARAMETERS p_carid TYPE sbook-carrid VALUE CHECK.
PARAMETERS p_cuter TYPE sbook-counter VALUE CHECK.
命中清单中的ID列即CARRID背景色不是蓝色,所以选择一条时,不会自动填充屏幕字段P_CARID,原因是对应的Search Help中的CARRID参数对应的EXP没有打上钩:
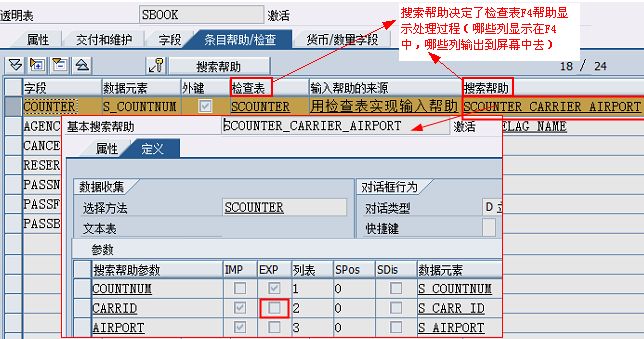
如果将这个钩打上,则会相应列背景色会为蓝色,且会自动填充,达到联动效果。

一般当某个外键所参照主表的主键上如果设置了搜索帮助(如上面COUNTER外键所引用的主表主键字段SCOUNTER-COUNTNUM已分配搜索帮助“SCOUNTER_CARRIER_AIRPORT”: ),则这个主表主键上的搜帮助会自动带到从表中相应外键上来,请看上面的SBOOK-COUNTER外键字段的搜索帮助也为“SCOUNTER_CARRIER_AIRPORT”,该搜索帮助决定了整个F4 Help处理及显示过程(如哪些列将作为联动查询条件、哪些列将显示在F4列表中、F4列表中的哪些列会输出到相应屏幕字段中)。另外,虽然主表主键上的搜索帮助会带到相应外键上来,但带过来后还可以修改,比如上面示例中带过来的搜索帮助中,CARRID参数所对应的EXP没有钩上,所以不能使用命中清单中的ID列来自动填充示例中的屏幕字段P_CARID,所以我们可以新建一个搜索帮助,并将CARRID搜索参数所对应的EXP钩上,则可达到自动上屏幕的效果;
),则这个主表主键上的搜帮助会自动带到从表中相应外键上来,请看上面的SBOOK-COUNTER外键字段的搜索帮助也为“SCOUNTER_CARRIER_AIRPORT”,该搜索帮助决定了整个F4 Help处理及显示过程(如哪些列将作为联动查询条件、哪些列将显示在F4列表中、F4列表中的哪些列会输出到相应屏幕字段中)。另外,虽然主表主键上的搜索帮助会带到相应外键上来,但带过来后还可以修改,比如上面示例中带过来的搜索帮助中,CARRID参数所对应的EXP没有钩上,所以不能使用命中清单中的ID列来自动填充示例中的屏幕字段P_CARID,所以我们可以新建一个搜索帮助,并将CARRID搜索参数所对应的EXP钩上,则可达到自动上屏幕的效果;
另外,有些外键所参照的主表主键没有指定搜索帮助,此时参照从表的屏幕字段的F4 Help就只有简单的一列了(如何让检查表SCURX中的CURRDEC字段也显示出来,请看后面的F4搜索帮助联动的决定因素),如下面SBOOK-LOCCURKEY字段:
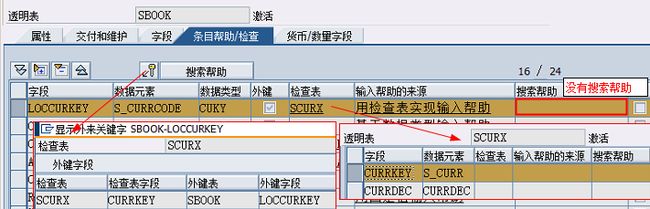
PARAMETERS p_cur TYPE sbook-LOCCURKEYVALUE CHECK.
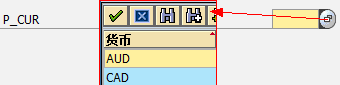
12.10.4.F4搜索帮助联动的决定因素
上节SE11检查表与搜索帮助关系中,屏幕字段参考sbook-LOCCURKEY时,搜索帮助输出列表只有简单一列,如果要让主表中的SCURX-CURRDEC列也显示出来,则需要为sbook-LOCCURKEY字段绑定一个搜索帮助,该搜索帮助数据来源于主表(或检查表)SCURX,搜索参数包括CURRKEY、CURRDEC两列,并且让这两列在F4输出列表中显示(即在搜索参数“列表”栏位编号):
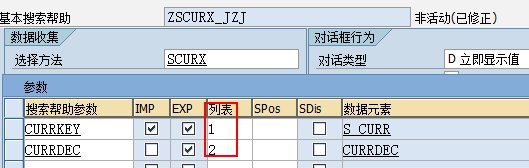
由于SBOOK不能直接修改,ZSBOOK从SBOOK拷贝过来,将搜索帮助ZSCURX_JZJ绑定到ZSBOOK-LOCCURKEY:

PARAMETERS p_cur TYPE zsbook-LOCCURKEYVALUE CHECK.
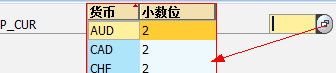
上面检查表中的SCURX-CURRDEC列(即F4中的小数位)已显示来了,但如何让其背景色为蓝色(虽然上面已将搜索参数CURRDEC的EXP打上了钩,但底色还是白色的),即选择时自动填充到屏幕上去?由于上面在将搜索帮助ZSCURX_JZJ绑定到从表字段zsbook-LOCCURKEY字段上时,搜索帮助中的搜索参数CURRDEC(即主表中的字段SCURX-CURRDEC)在从表ZSBOOK找不到相应的外键,所以上图绑定过程中,搜索参数CURRDEC为空。但在这里可以手动分配一个,由于在从表ZSBOOK中找不到此字段,所以就暂时参照自己(主表SCURX-CURRDEC)吧:
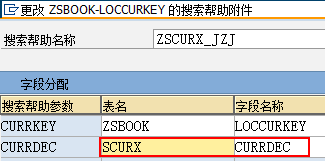
如果此时选择屏幕的代码还是上面那样:
PARAMETERS p_cur TYPE zsbook-LOCCURKEY VALUE CHECK.
则F4搜索输出列表中的“小数位”列底色还是白色,但如果加上以下屏幕参数,但会变以蓝色,并可联动(如果搜索帮助的CURRDEC参数的IMP打上钩,还可以实现联动查询):
PARAMETERS p_cur2 TYPE SCURX-CURRDEC VALUE CHECK
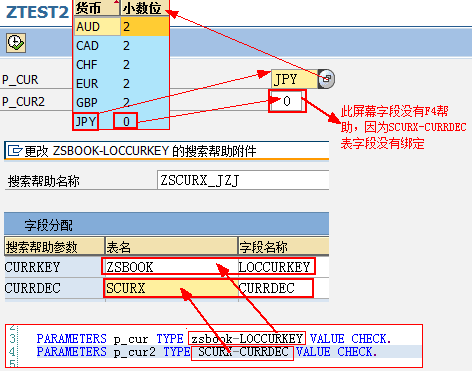
此时的下拉框也会只有两列:
PARAMETERS p_cur3 TYPE zsbook-LOCCURKEY as LISTBOX VISIBLE LENGTH 20.
所以,联动的决定性条件是要求选择屏幕上的字段要参照SE11为表字段所绑定搜索帮助过程中所分配的表字段,如下图中的zsbook-loccurkey、scurx-currdec,这两个字段分别与搜索帮助的CURRKEY、CURRDEC参数绑定了,所以屏幕上参照这两个表字段时,就会具有联动效果了:
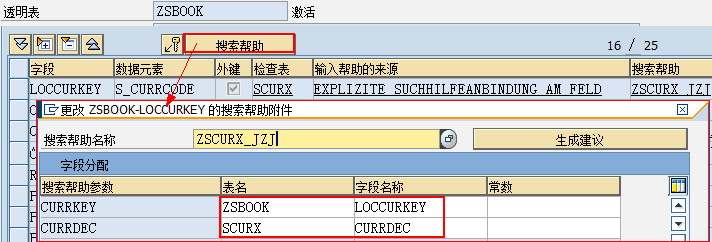
12.11.搜索帮助参数说明
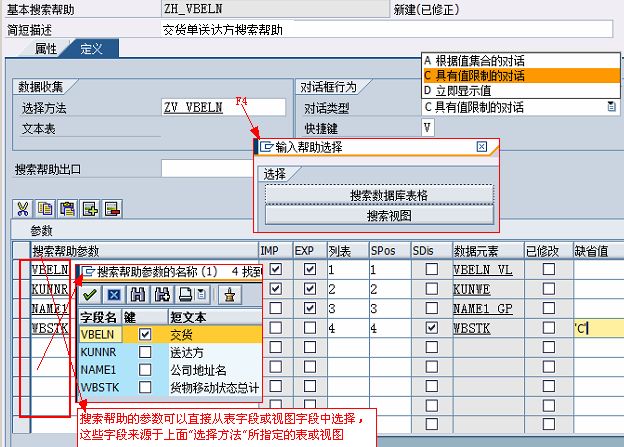
² IMP:输入参数。表示屏幕上相应字段是否作为搜索帮助的过滤条件(即报表选择屏幕上的字段的值是否从报表选择屏幕上传递到搜索帮助中去)
如果是F4字段时,屏幕字段中的值包含“*”时,才会将F4字段传递到Search Help中。除开F4屏幕字段外,而其他只要是Link到了相应的Search Help参数的屏幕字段,只要相应屏幕字段中有值,则会传入到搜索中作为过滤条件(而其他非F4屏幕字段所对应的Help参数不管是否钩上IMP都会传递?)

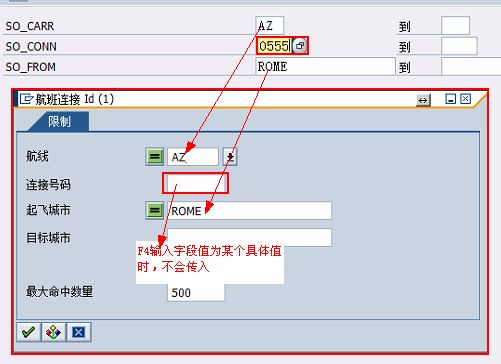
² EXP:输出参数,表示搜索帮助的此列会从搜索帮助中传递到报表选择屏幕上(表示F4选中一条记录后显示到屏幕上文本框中的值——背景字段为浅蓝色的列的数据会被输出,输出的数据可能是多列。注:只有当EXP钩上且相应字段出现在了屏幕上,才会自动填充到相应屏幕字段,如果没有钩上——没钩上的字段背景色为白色,即使相应参数字段出现在了屏幕上,选择命中清单时也不会自动填充),且F4字段一定要将EXP钩上(否则选择后F4字段不能上屏)。
² LPOS(列表):F4输出命中清单中各列的显示顺序,如果为0或留空的列则不会显示
² SPOS:相应的字段是否在搜索帮助选择屏幕上显示出来,在命中清单显示之前,如果弹出限制对话框,则可以进一步修改那些从选择屏幕上带过来的条件值。此数字就是限制搜索帮助选择条件屏幕字段摆放顺序,如果为0或留空的列则不会出在限制条件页中
² SDis:如果勾选了,则在弹出的限制对话框中对应的字段用户不可输入,是只读的。
12.12.F4IF_SHLP_EXIT_EXAMPLE帮助出口
12.12.1.修改数据源
FUNCTION zfvbeln_find_exit.
*"----------------------------------------------------------------------
*"*"Local Interface:
*" TABLES
*" SHLP_TAB TYPE SHLP_DESCT
*" RECORD_TAB STRUCTURE SEAHLPRES
*" CHANGING
*" VALUE(SHLP) TYPE SHLP_DESCR
*" VALUE(CALLCONTROL) LIKE DDSHF4CTRL STRUCTURE DDSHF4CTRL
*"----------------------------------------------------------------------
"此内表用于存储命中清单数据.注:字段的名称一定要与搜索参数名一样,但顺序可以不同,
DATA: BEGIN OF lt_tab OCCURS 0,
wbstk TYPE wbstk,
lfdat TYPE lfdat_v,
vbeln TYPE vbeln_vl,
END OF lt_tab.
"用于存储从选择屏幕上传进的屏幕字段的选择条件值
DATA: r_vbeln TYPE RANGE OF vbeln_vl WITH HEADER LINE,
r_lfdat TYPE RANGE OF lfdat_v WITH HEADER LINE,
r_wbstk TYPE RANGE OF wbstk WITH HEADER LINE,
wa_selopt LIKE LINE OF shlp-selopt."
"callcontrol-step该字段的值是由系统设置,并且你可以在程序中进行修改它。出口函数会在处理的每一步(时间点)都会调用一次
IF callcontrol-step = 'SELECT'."如果有弹出限制对话框,则会在弹出限制对话框中点击确认按钮后step值才为SELECT
"shlp-selopt存储的是经过映射转换后选择屏幕上字段的值,而不是直接为
"选择屏幕字段名,而是转映射为Help参数名后再存储到 selopt 内表中,
"屏幕字段到Help参数映射是通过 shlp-interface 来映射的
LOOP AT shlp-selopt INTO wa_selopt.
CASE wa_selopt-shlpfield.
WHEN 'VBELN'."由于屏幕字段已映射为了Help相应参数,所以这里不是S_VBELN
MOVE-CORRESPONDING wa_selopt TO r_vbeln.
APPEND r_vbeln.
WHEN 'LFDAT'.
MOVE-CORRESPONDING wa_selopt TO r_lfdat.
APPEND r_lfdat.
WHEN 'WBSTK'.
MOVE-CORRESPONDING wa_selopt TO r_wbstk.
APPEND r_wbstk.
ENDCASE.
ENDLOOP.
"根据屏幕上传进的条件查询数据
SELECT likp~vbeln likp~lfdat vbuk~wbstk INTO CORRESPONDING FIELDS OF TABLE lt_tab
FROM likp INNER JOIN vbuk ON likp~vbeln = vbuk~vbeln
WHERE likp~vbeln IN r_vbeln AND
likp~lfdat IN r_lfdat AND
vbuk~wbstk IN r_wbstk.
"该函数的作用是将内表 lt_tab 中的数据转换成record_tab,即将某内表中的数据显示在命中清单中
CALL FUNCTION 'F4UT_RESULTS_MAP'
TABLES
shlp_tab = shlp_tab
record_tab = record_tab
source_tab = lt_tab
CHANGING
shlp = shlp
callcontrol = callcontrol.
"注:下一个时间点一定要直接设置为 DISP,否则命中清单不会有值,也不显示出来
"从表面上看,SELECT时间点下一个就是DISP时间点,按理是不需要设置为DISP,
"但如果不设置为DISP,出口函数在执行完后,系统会转入DISP时间点执行(即再次调用此出口函数)
",但再次进入此出口函数时,record_tab内表已经被清空了(是否可以通过判断callcontrol-step的值来决定走什么新的逻辑代码来解决此问题?)。如果这里直接设置为DISP,就好比欺骗了系统一样,告诉系统当前执行的正是DISP时间点,而不是SELECT,系统就不会再转到DISP时间点了而是直接显示
callcontrol-step = 'DISP'. "DISP:在命中清单显示之前调用,表示数据已经查出,下一步就该显示了。该时间用于控制搜索帮助的输出结果。例如,在输出搜索结果时对用户检查权限,删除未授权的数据
ENDIF.
ENDFUNCTION.
12.12.2.删除重复
FUNCTION zeh_lxsecond.
IF callcontrol-step = 'DISP'.
SORT RECORD_TAB.
DELETE ADJACENT DUPLICATES FROM RECORD_TAB COMPARING ALL FIELDS."zsecond.
EXIT.
ENDIF.
ENDFUNCTION.
12.13.搜索帮助优先级
先PROCESS ON VALUE-REQUEST,AT SELECTION-SCREEN ON VALUE-REQUEST
再PARAMETERS/ SELECT-OPTIONS MATCHCODE OBJECT
先检查表Check Table,再表(或结构)字段是否绑定了搜索帮助
先data element是否绑定了帮助,再domain是否存在fixed values
最后才是DATS、TIMS
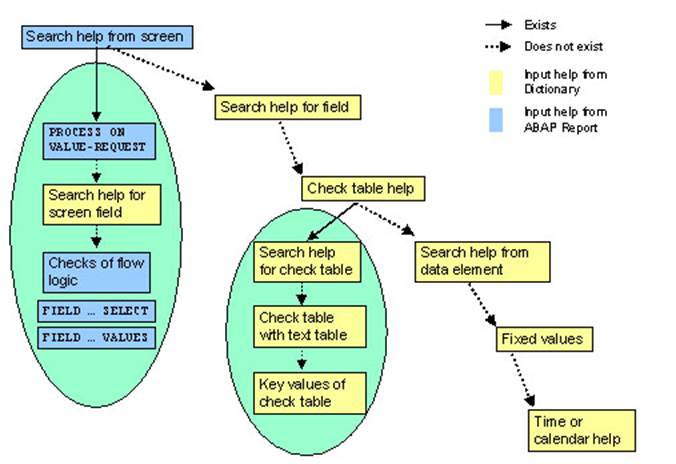
Domain只设置Value Table也可以出F4,同时Data Element绑定了搜索帮助,则DataElement上绑定的搜索帮助优先于Domain上的Value Table????????
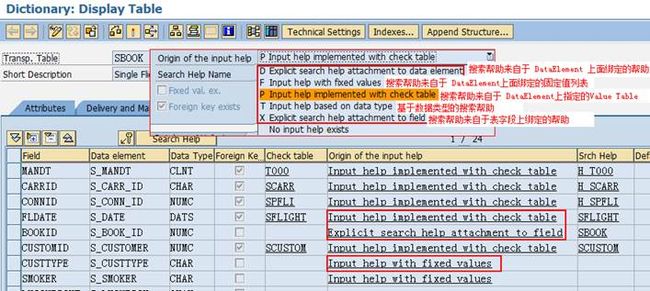
12.14.搜索帮助创建函数
在屏幕的ON VALUE-REQUEST事件里可以通过下面几个函数来创建搜索帮助:
F4IF_FIELD_VALUE_REQUEST:函数的作用是在运行时,可以动态的为某个屏幕字段指定Search Help,这个被引用的Help来自某个表(或结构)字段上绑定的Help
F4IF_INT_TABLE_VALUE_REQUEST:在程序运行时,将某个内表动态的用作Search help的数据来源,即使用该函数可以将某个内表转换为Search help,可实现联动效果
TR_F4_HELP:简单实现Search Help,数据来源于内表
12.15.在POV事件里读取屏幕字段中的值函数
在POV(包括选择屏幕上 AT SELECTION-SCREEN ON VALUE-REQUEST事件)事件中,屏幕上的字段的值不像PAI里那样可以直接读取到,所以使用以下两个函数来读写:
DYNP_VALUES_READ、DYNP_VALUES_UPDATE
12.16.动态修改屏幕
选择屏幕、对话屏幕都有对应的SCREEN内表,下面是几个重要属性:
NAME:Name of the screen field。如果参数是select-options类型参数,则参数名以LOW与HIGH后缀来区分。
GROUP1:选择屏幕元素通过MODIF ID选项设置GROUP1(对话屏幕通过属性设置),将屏幕元素分为一组,方便屏幕的元素的批量修改
REQUIRED:控制文本框、下拉列表屏幕元素的必输性,使用此属性后会忽略OBLIGATORY选项。取值如下:
0:不必输,框中前面也没有钩
1:必输,框中前面有钩,系统会自动检验是否已输入,相当于OBLIGATORY选项
2:不必输,但框中前面有钩,系统不会检查是否已输入,此时需要手动检验
INPUT:控制屏幕元素(包括复选框、单选框、文本框)的可输性
ACTIVE:控制屏幕元素的可见性
REQUIRED选项的应用:该选项可以解决这个问题:在点击某个单选框(p_rd1)后显示某个必输字段(p_lclfil),但当这个必输框显示出来后,如果点击p_rd2想隐藏它时,此时输入框中必须有值,否则系统会自动检验要求重新输入。现要求输入框没有输入值的情况下,也可在点击p_rd2时隐藏它,则解决的办法是:将输入框的这个属性设置为2(显示必须的钩,但系统不会自动进行必输验证),去掉OBLIGATORY选项(不去掉也会被忽略),并在AT SELECTION-SCREEN ON field事件里时手动进行为空验证
"一定要设置 USER-COMMAND ,否则点击之后,不会触发屏幕PAI事件,PAI事件不触发则会导致
"屏幕的AT SELECTION-SCREEN OUTPUT也就不会被触发(非执行按钮的FunCode触发时都会刷新
"屏幕,所以再次显示屏幕时再次执行PBO)
PARAMETERS p_rd1 RADIOBUTTON GROUP gp1 USER-COMMAND mxx."用来隐藏 p_lclfil
PARAMETERS p_rd2 RADIOBUTTON GROUP gp1 DEFAULT 'X'."用来显示 p_lclfil
"当通过程序动态修改屏幕元素属性 required 后,会忽略掉这里的 OBLIGATORY 选项
*PARAMETERS p_lclfil(128) AS LISTBOX VISIBLE LENGTH 20 MODIF ID mxy OBLIGATORY .
PARAMETERS p_lclfil(128) MODIF ID mxy OBLIGATORY .
PARAMETERS: c AS CHECKBOX."没什么作用,用来测试 CHECKBOX 的可输入性
"当 C2 被钩选时,屏幕上的其他输入元素均不可输入
PARAMETERS: c2 AS CHECKBOX USER-COMMAND ddd DEFAULT 'X'.
AT SELECTION-SCREEN OUTPUT.
LOOP AT SCREEN .
"当 C2 没有钩选时,其他元素都设置为可输入
IF screen-name <> 'C2' AND c2 IS INITIAL .
screen-input = 1.
MODIFY SCREEN.
ELSEIF screen-name <> 'C2' AND c2 IS NOT INITIAL .
screen-input = 0."C2钩选时,所以屏幕输入元素禁止输入
MODIFY SCREEN.
ENDIF.
"控制下拉列表(文本框也是一样)的必输性:外观上打钩,但不自动校验
IF p_rd2 = 'X' AND screen-group1 = 'MXY'.
"显示
screen-active = '1'.
* screen-input = '1'."显示前设为可输入
screen-required = '2'."外观上打钩,但不自动校验
MODIFY SCREEN.
ELSEIF screen-group1 = 'MXY'. "
"隐藏
screen-active = '0'.
screen-required = '2'.
MODIFY SCREEN.
ENDIF.
ENDLOOP.
AT SELECTION-SCREEN ON p_lclfil.
IF p_rd2 IS NOT INITIAL"手动检验:但当点击单选按钮与复选框 C2 时,不校验
AND sy-ucomm <> 'MXX' AND sy-ucomm <> 'DDD' AND p_lclfil IS INITIAL.
MESSAGE e055(00).
ENDIF.
12.17.子屏幕
除通过屏幕的属性将某个屏幕设置为子屏幕外,还可以通过程序创建一个子屏幕:
SELECTION-SCREEN BEGIN OF SCREEN dynnr AS SUBSCREEN.
...
SELECTION-SCREEN END OF SCREEN dynnr.
l子屏幕可以嵌入到Tabstrip中使用:
SELECTION-SCREEN BEGIN OF TABBED BLOCK tblock FOR n LINES.
SELECTION-SCREEN TAB (len) tab USER-COMMAND fcode DEFAULT SCREEN dynnr.
... tab:Tab的标题;len:Tab标题显示的宽度;Tab页签内容的行数由n来决定;DEFAULT SCREEN:给Tab静态分配子屏幕
SELECTION-SCREEN END OF BLOCK tblock.
l通过CALL SUBSCREEN语句将子屏幕嵌入到对话屏幕中:
PROCESS BEFORE OUTPUT.
CALL SUBSCREEN INCLUDING [
...子屏幕都需要放在主屏幕中的某个指定的区域元素中
为了调用子屏幕的PAI事件,需要在主屏幕的PAI flow logic里如下调用:
PROCESS AFTER INPUT.
CALL SUBSCREEN .
...
普通选择屏幕,可以使用CALL SELECTION-SCREEN来单独调用
12.18.屏幕跳转
LEAVE SCREEN.
or
LEAVE TO SCREEN
LEAVE SCREEN语句会结束当前屏幕并调用下一屏幕,next scree可以是static next screen,或者是dynamic next screen,如果是动态的,你必须在使用LEAVE SCREEN语句前使用SET SCREEN语句来重写static next screen
LEAVE TO SCREEN语句会结束当前屏幕并跳转到指定的下一屏幕
SET SCREEN
LEAVE SCREEN.
这两个语句不会结束屏幕序列,它们仅仅是转向同一屏幕序列中的另一屏幕。屏幕序列是否结束要看
可以用LEAVE TO SCREEN 0来结束当前SCREEN SEQUENCE
12.18.1.CALL SCREEN误用
每次碰到CALL SCREEN语句就会产生新的SCREEN SEQUENCE,而且SAP系统设置了SCREEN SEQUENCE堆栈不能超过50个,一旦超过就会出溢出错误,所以不要使用 CALL SCREEN 进行屏幕的切换
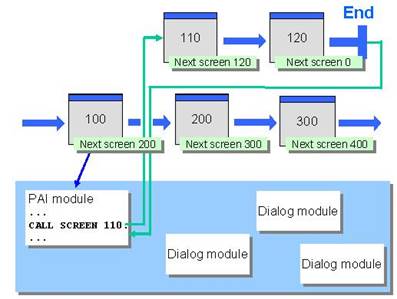
为了避免产生新的SCREEN SEQUENCE,针对上图,可以使用LEAVE...SCREEN进行屏幕切换,而不是CALL SCREEN:
SET SCREEN 110."该语句只是动态制定下一个屏幕,但不结束当前屏幕处理(即不立即跳转下一屏幕),只有LEAVE SCREEN才会结束屏幕的处理(后面的语句才不会执行)
LEAVE SCREEN.
或者使用:LEAVE TO SCREEN 110.相当于上面两包的组合:SET SCREEN 110. LEAVE SCREEN.
请使用SET SCREEN XXX / LEAVE SCREEN,LEAVE TO SCREEN XXX来在同一屏幕序列里动态的进行屏幕切换跳转,而不要使用CALL SCREEN XXX进行屏幕序列的跳转与切换
12.18.2.CALL SCREEN/SET SCREEN/LEAVE TO SCREEN区别
CALL SCREEN XXXX将在Screen调用栈(CALL STACK)上面添加一层调用(进栈,即重新开启一个新的屏幕序列),调用XXXX的PBO和PAI,如果XXXX的Next Screen不为0,那么将继续其Next Screen的PBO和PAI,如此继续~~~当最后碰到Next Screen为0时,该层调用将从调用栈中退出(出栈),然后系统将继续执行CALL SCREEN XXXX之后的语句。
SET SCREEN XXXX设置调用栈当前层次的Next Screen为XXXX,它并不影响调用栈的层数(即不会重新开启一个新的屏幕序列,只做屏幕之间的切换,而不是屏幕序列之间的切换),除非XXXX为0,那将导致调用栈退掉一层(出栈)。要注意的是,PAI中SET SCREEN XXXX后的语句,系统将照样执行,只有执行完毕该PAI整个逻辑后,才考虑Next Screen的PBO和PAI。
LEAVE TO SCREEN XXX与SET SCREEN XXX比较类似(也不会重新开启一个新的屏幕序列,只做屏幕之间的切换,而不是屏幕序列之间的切换),所不同的是,LEAVE TO SCREEN XXXX将强行中断当前SCREEN的PAI,直接执行XXXX的PBO和PAI。换言之,PAI中LEAVE TO SCREEN XXXX后面的语句,系统将不会执行到。
LEAVE SCREEN.后面的语句也不会执行
注:上面语句的XXX也可以是选择屏幕的屏幕号,而不只是对话屏幕号
CALL SCREEN是将正在运行的画面挂起,进入所调用的画面,当使用LEAVE TO SCREEN 0时,能够返回原主调画面,可理解为嵌套调用;而LEAVE TO SCREEN是立即结束本画面的执行,调用所指定的画面,在调用画面中,无法再返回原主调画面。
12.19.修改标准选择屏幕的GUI Status
选择屏幕的GUI status是由系统自动生成的,标准选择屏幕的PBO事件里(即AT SELECTION-SCREEN OUTPUT)的SETPF-STATUS语句将不会再起作用。如果想修改标准选择屏幕的GUIstatus(或去激活标准选择屏幕上的GUI Status上预设的功能),则可以在选择屏幕的PBO(AT SELECTION-SCREEN OUTPUT)事件里调用RS_SET_SELSCREEN_STATUS函数来实现。
12.20.事件分类
12.20.1.报表事件
INITIALIZATION.
START-OF-SELECTION.
END-OF-SELECTION.
12.20.2.选择屏幕事件
在INITIALIZATION和START-OF-SELECTION之间触发,对应于对话屏幕的 PBO、PAI、POH、POV事件
AT SELECTION-SCREEN { OUTPUT }
| { ON {para|selcrit} }
| { ON END OF selcrit }
| { ON BLOCK block }
| { ON RADIOBUTTON GROUP radi }
| { ON {HELP-REQUEST|VALUE-REQUEST}
{ FOR {para|selcrit-low|selcrit-high} }
| { ON EXIT-COMMAND }
| { }.
12.20.3.逻辑数据库事件
GET node [LATE] [FIELDS f1 f2 ...].
12.20.4.列表事件
TOP-OF-PAGE.
END-OF-PAGE.
AT LINE-SELECTION.
AT USER-COMMAND.
AT pf
12.20.5.事件流图

12.21.事件终止
12.21.1.RETURN
RETURN用来退出当前执行的程序块,例如一个FORM、METHOD、报表事件块,不管是否出现在循环(LOOP)中,RETURN都会退出当前执行的程序块,而不仅仅是退出循环(如果是在Form、METHOD中,只会退出Form、METHOD,不会退出Form、METHOD被调用所在的报表事件块,即退Form、METHOD后继续向被调用点后面执行)
12.21.2.STOP
l INITIALIZATION中的STOP会导致跳转到AT SELECTION-SCREEN OUTPUT事件块;
l 如果STOP在AT SELECTION-SCREEN OUTPUT块里,则只是退出当前块(STOP后面语句不执行而已),仅接着是显示选择屏幕;
l AT SELECTION-SCREEN [ON]…选择屏幕事件块中的STOP也只是退出当前事件块,继续后面的事件块;
l 另外,即使STOP在循环中,还是在FORM,METHOD,也是直接从被调用的点退出所在事件块,而不仅仅只退出当前循环、FORM、METHOD,这与直接在事件块中的效果是一样的;
RETURN用来退出当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT,不管是否出现在循环(LOOP)中,RETURN都会退出当前执行的程序块,而不仅仅是退出循环。
虽然ABAP中EXIT 和RETURN都可以用来实现退出当前执行的语句块,但SAP的帮助文件建议只在循环中使用EXIT ,其他情况下要退出当前执行进程,使用RETURN 。
12.21.3.EXIT
l INITIALIZATION中的EXIT会导致跳转到AT SELECTION-SCREEN OUTPUT事件块;
l 如果EXIT在AT SELECTION-SCREEN OUTPUT块里,则只是退出当前块(EXIT后面语句不执行而已),仅接着是显示选择屏幕;
l AT SELECTION-SCREEN [ON]…选择屏幕事件块中的EXIT也只是退出当前事件块,继续后面的事件块;
l 从START-OF-SELECTION开始往后的事件块,如果出现EXIT,则会开始listprocessor(列表处理),并跳转到相应的List输出界面(前提条件是要在退出前已经向屏幕输出内容了,否则也不会跳转);注:END-OF-SELECTION事件块也会被跳过
l 另外,如果EXIT在循环(DO、WHILE、LOOP)里,只是跳出当前循环而已;
l 如果是在FORM,METHOD中,而非循环中,则退出当前的FORM、METHOD,其作用与RETURN类似
1) EXIT如果出现在循环中,退出的是整个循环操作,.程序会从循环结束处开始继续执行,其作用相当于Java与C++中的break。
2)EXIT如果出现在循环之外,退出的是当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT,其作用与RETURN类似。
12.21.4.CHECK
CHECK跳转的前提是
l CHECK只是跳出当前事件块,继续下一个事件块的处理,相当于方法的return;
l 另外,如果CHECK在循环(DO、WHILE、LOOP)里,只是跳出当前循环而已;
l 如果CHECK出现在循环以外,退出的是当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT。
1)CHECK 后面要跟一个表达式,当表达式值为假(false)时,CHECK发生作用,退出循环(LOOP)或处理程序(Processing Block)。
2)如果CHECK出现在循环中,则发生作用时,退出的是当前一次循环操作,程序会继续执行下一次循环操作,其作用类似于Continue (Java 或C++中continue也是如此).
3)如果CHECK出现在循环以外,则发生作用时,退出的是当前执行的程序块(processing block),例如一个FORM,METHOD,或EVENT。
12.21.5.LEAVE
LEAVE PROGRAM. 退出整个程序
LEAVE TO TRANSACTION ta
LEAVE LIST-PROCESSING. 从list processor回到dialog processor
LEAVE TO LIST-PROCESSING 控制权从dialog processor转交给list processor
LEAVE { SCREEN | {TO SCREEN dynnr} }
12.21.5.1.REJECT
REJECT是用在逻辑数据库GET event blocks中,与EXIT和CHECK不一样的是(EXIT和CHECK如果是在循环中时,只是退出循环;如果是在FORM中,则只是退出当前FORM),REJECT可以从循环或者一个FORM中直接跳出所在的GET事件块:
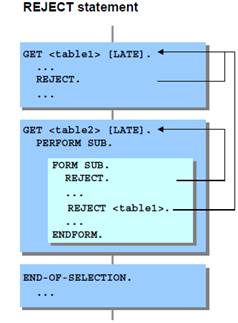
REJECT [
终结逻辑数据库当前节点数据行的处理
如果省略选项
13.列表屏幕
在START/END-OF-SELECTION事件处理块中,用WRITE语句向列表缓冲区(List Buffer)输出要显示的内容,当该事件结束的时候,所有在列表缓冲区中的内容将被显示到一个基本列表屏幕(Basic List)上
当用户在基础列表屏幕上双击一行或按功能键“F2”时,将会触发ABAP事件AT LINE-SELECTION,如果还想进一步显示该行数据的详细信息,则可以继续使用WRITE语句输出要显示的内容,这次生成另外一个详细列表屏幕(Details List Screen)。此详细列表屏幕将覆盖其上一层的基础列表屏幕,若在其界面的工具条上点“返回”或按功能键F3,将返回到基础列表屏幕。
在详细列表屏幕上,当用户双击一行数据或按功能键F2,AT LINE-SELECTION事件将会再次触发,因此还可以继续生成下一级的详细列表屏幕
ABAP提供了全屏变量sy-lsind来区别屏幕的层次,sy-lsind的值主要用于在 AT LINE-SELECTION事件处理块中进行程序流程控。0表示为基础列表屏幕,1表示第一级详细列表屏幕,依次类推,最多可以有20个详细列表
13.1.标准LIST

至少包括二行standard header,第一行standard header包括了listheader和pagenumber,第二行standard header是一条水平线。当程序是可执行报表程序时,listheader存储在SY-TITLE中。如果有必要,可以给standardheader添加最多四行的columnheaders与一条水平线。在水平或垂直滚动时standardheader是不会动的。
13.2.自定义LIST
TOP-OF-PAGE.
REPORT
REPORT
REPORT
SY-PAGNO系统变量存储了当前页码
END-OF-PAGE. 触发的条件是数据要满一页时才触发,否则不会被触发
NEW-PAGE
RESERVE
NEW-PAGE [NO-TITLE|WITH-TITLE] [NO-HEADING|WITH-HEADING] WITH-TITLE、NO-TITLE:控制NEW-PAGE新开启的页面以及后面使用NEW-PAGE开启的页面是否使用标准的list header
NO-HEADING、WITH-HEADING:控制NEW-PAGE新开启的页面以及后面使用NEW-PAGE开启的页面是否使用标准的column header
NEW-PAGE LINE-COUNT
NEW-PAGE LINE-SIZE
13.3.LIST事件
AT PF
键盘上的F
AT LINE-SELECTION
当用户在LIST屏幕上的某行上按F2或者鼠标双击时,就会触发该事件块,并且此时的function code默认名为PICK
AT USER-COMMAND
除上面PF
除了通过手动触发LIST屏幕事件之外,还可以直接通过编程的方式来触发:
SET USER-COMMAND
该语句会在当前列表事件块里的所有输出结束后生效(这意味着该语句放在输出语句的前后都没有关系),并在列表显示之前触发与
13.4.Detail Lists 创建
凡事在AT PF
13.5. 标准的 List Status
如果在报表程序中没有设置(Basic List与Detail List都未设置时)GUI status,则系统会将list screen的Status设置为系统内置的default list status;在其他类型的程序中(如当你在Screen中创建一个list时),你可以明确的调用下面语句来设置成系统内置的default list status:
SET PF-STATUS space.
该语句定义了Standard List所拥有的默认functions,系统所提供的内置default list status如下(这些功能都已实现,可直接使用):

13.6.列表屏幕上的数据与程序间的传递
13.6.1.SY-LISEL
SY-LISEL类型为C(255),它是将整行的内容都存储下来了,所以要取得每个Field,则需要通过offset方式来截取
13.6.2.HIDE
HIDE
变量
当单击List屏幕中的行时,如果对应的行设置了隐藏字段,则HIDE隐藏字段变量
注:局部变量不能存储到HIDE区域中
语句要在数据行被WRITE语句输出到列表缓冲区后,在后面紧着编写(为了隐藏的数据与当前输入的数据一致),并且当被双击时,保存在隐藏域中的字段的值将自动被传回到原始字段中
隐藏域实质上是一个内表,其行结构包含了三个字段:被选中行的行号、字段名、字段值,当保存数据时,每个被保存的字段在隐藏域中形成一行:

上图中已将wa_spfli-carrid、wa_spfli-connid存入了隐藏域中了,所以在双击行后,可以直接使用AT LINE-SELECTION.事件中使用
13.6.3.READ LINE
READ LINE ]. 该语句会将事件触发所在的List((index SY-LILLI))中的第 为了将dialog processor控制权转交给list processor,你可在PBO dialog modules 中调用下面这样的语句: LEAVE TO LIST-PROCESSING[AND RETURN TO SCREEN 该语句可以使用在PBO 或者PAI event中,它的作用是在当前屏幕的PAI processing(一般在PBO块里使用SUPPRESS DIALOG.或LEAVE SCREEN.语句后不会显示这个屏幕,此时在PBO事件块结束后立即显示Basic List)结束后开始list processor并显示Basic List。调用该语句所在屏幕的PBO and PAI modules中的list output都会被输出到Basic List中缓存起来,待该屏幕处理完后显示(如果没有在PBO中使用SUPPRESS DIALOG.或LEAVE SCREEN.语句,则在PAI结束后显示;如果使用了这两个语句,则会在PBO块结束后就会显示) 可以使用以下两种方式来离开list processing: • 在basiclist中点击Back,Exit,orCancel • 在list processing程序中使用:LEAVE LIST-PROCESSING. 以上两种方式都会使控制权从list processor转交到dialog processor。 在默认的情况下,不带AND RETURN TO SCREEN选项的LEAVE TO LIST-PROCESSING语句在当list processor 处理结束后(如关闭list列表输出窗体时),dialog processor将会又会返回到LEAVE TO LIST-PROCESSING语句调用所在屏幕的PBO事件块,并重新执行PBO事件块(所以这样使用会出现死循环:关不掉List列表输出窗口);选项AND RETURN TO SCREEN允许你指定当前屏幕序列(即LEAVE TO LIST-PROCESSING语句调用所在屏幕所在的屏幕序列)中的某个屏幕,当list processor 处理结束后,dialog processor将会回到指定的屏幕并执行其相应的PBO事件块 打印参数设置: SET_PRINT_PARAMETERS GET_PRINT_PARAMETERS 从程序中启动打印:NEW-PAGEPRINTON 00消息ID中的001消息本身未设置任何消息串,这条消息可以传递8个参数,在用于拼接消息时很有用 MESSAGE e001(00) WITH 'No local currecny maintained for company:' p_bukrs. 直接显示消息常量,不引用消息ID与消息号 MESSAGE 'aaaa' TYPE 'S'. MESSAGE MESSAGE s002(00). MESSAGE ID DATA: t(1) VALUE 'S', DATA mtext TYPE string. 此种方式不会影响到消息本身的处理性为,只是改变了消息的显示图标类型,如下面只是改变了S类型消息在状态栏中以错误图标来显示(本来是绿色状态图标): MESSAGE msg TYPE 'S' DISPLAY LIKE 'E'. MESSAGE ID 'SABAPDEMOS' TYPE MESSAGE_TYPE NUMBER '777' 当使用该选项后,并且如果在调用的地方(CALL FUNCTION或者是 CALL METHOD的地方)使用了EXCEPTION选项来捕获RAISING抛出的异常,则不再以MESSAGE的原有形式来显示消息,而是被主调捕获后进一步处理或者是程序Dump(A、E、W、I、S类型都能被捕获到,但X类型的Message不会走到被主调者捕获这一步,因为在被调程序中就宕掉了);反过来,当主调者未使用EXCEPTION选项(或者使用了但未捕获到所抛出的异常),则RAISING选项会被忽略,MESSAGE语句会按照无RAISING选项时那样运行(弹框还是在状态栏中显示、以及程序是否终止等性为、还是转换为error_message抛出) 如果加了选项RAISING时:MESSAGE... RAISING 1、如果调用时没有带exception 2、如果调用时加上了exception 下面程序中,第一次调用时中会弹出消息框(因为没有使用EXCEPTIONS选项捕获),而第二次不会弹出消息框,也不会在状态栏中显示,而是被后继程序捕获后输出: CLASS c1 DEFINITION. CALL FUNCTION func [EXCEPTIONS exc1,exc2...与OTHERS异常只能捕获到MESSAGE...RAISING选项或RAISE语句抛出的异常,而error_message是无法捕获MESSAGE...RAISING与RAISE抛出的异常的 MESSAGE中的RAISING CALL FUNCTION 'ZJZJ_FUNC1' 可以在Message语句没有使用RAISING选项的情况下(或使用exc1...exci或others但未捕获到),在主调程序中的CALL FUNCTION ...Exception参数列表中使用隐式异常error_message选项来捕获Message,但error_message是否能捕获到Message(实为是否设置sy-subrc = n_error),与消息类型有关: 1、对于W、I、S类型的消息,将不显示消息(本来是要显示的),也不会去设置 sy-subrc = n_error,但此时还是会将消息的相关信息存储到SY-MSGID, SYMSGTY,SY-MSGNO, and SY-MSGV1 to SY-MSGV4这些系统变量中 2、对于A、E类型消息,也将不显示提示消息,但会抛出ERROR_MESSAGE异常,即这两类型的消息会自动被转换为error_message异常抛出,并终最被CALL FUNCTION 中Exception异常列表中的error_message异常所捕获,并设置sy-subrc = n_error。此时还会将消息的相关信息存储到SY-MSGID, SYMSGTY,SY-MSGNO, and SY-MSGV1 to SY-MSGV4这些系统变量中 此时,对于A类型消息而言,ROLLBACK WORK语句将会隐式执行 3、对于X类型消息将会抛出runtime error,并且程序会dump 消息类型 非屏幕PAI事件 PBO、 AT SELECTION-SCREEN OUTPUT、INITIALIZATION、START-OF-SELECTION、 GET、 END-OF-SELECTION、 TOP-OF-PAGE、 END-OF-PAGE 对话/选择屏幕 PAI、 AT SELECTION-SCREEN [ON] List列表事件 AT LINE-SELECTION、 AT USER-COMMAND、 AT PF TOP-OF-PAGE DURING LINE-SELECTION 显示 显示在对话框中还是状态栏中 处理 是终止程序还是继续 显示 处理 显示 处理 X 不显示信息 触发运行时错误并伴随着dump 不显示信息 触发运行时错误并伴随着dump 不显示信息 触发运行时错误并伴随着dump A Dialogbox以对话框形式显示 程序终止 Dialogbox以对话框形式显示 程序终止 Dialogbox以对话框形式显示 程序终止 E PBO:与A相同,否则显示在状态栏中 程序终止 在状态栏中显示 PAI处理结束,并且控制权返回到当前对话/选择屏幕继续输入 在状态栏中显示 事件块处理终止,返回上一级别的List W PBO:与S相同,否则显示在状态栏中 程序终止 在状态栏中显示 PAI处理结束,并且控制权返回到当前对话/选择屏幕可继续输入,但可按回车键继来忽略警告继续运行后面程序而不必输入 在状态栏中显示 事件块处理终止,返回上一级别的List I PBO:与S相同,否则以对话框的形式显示 程序会继续向下执行 Dialog box对话框中显示 程序会继续向下执行 Dialog box对话框中显示 程序会继续向下执行 S 消息会显示在下一屏幕的状态栏中,如果没有下一屏幕,则显示在当前屏幕的状态栏中 程序会继续向下执行 消息会显示在下一屏幕的状态栏中,如果没有下一屏幕,则显示在当前屏幕的状态栏中 程序会继续向下执行 消息会显示在下一屏幕的状态栏中,如果没有下一屏幕,则显示在当前屏幕的状态栏中 程序会继续向下执行 两种方式触发异常: lRAISE l MESSAGE...RAISING 一旦主调程序捕获了异常,以上两种触发异常的方式都会返回到主调程序,并且不会返回值(Function Module参数输出)。MESSAGE ..... RAISING语句也不会再显示消息,而是将相关的信息填充到SY-MSGID, SY-MSGTY,SY-MSGNO, and SY-MSGV1 to SY-MSGV4这些系统变量中(即使是I,S,W三种消息类型也会设置这些系统变量) RAISE [RESUMABLE] EXCEPTION { { TYPE cx_class [EXPORTING p1 = a1 p2 = a2 ...]} | oref }. cx_class为异常Class,EXPORTING为构造此异常类的构造参数,oref可以是已存在的异常Class引用。 RAISE EXCEPTION语句一般用来抛出基于Class的异常类class-based exceptions,而RAISE一般是直接用来抛出 non-class-based exceptions(在函数中使用) DATA result TYPE p DECIMALS 2. DATA: exc TYPE REF TO cx_sy_dynamic_osql_semantics, 表示可恢复的异常,可以在CATCH块里使用RESUME语句直接跳到抛出异常语句后面继续执行,RESUME后面语句不再被执,CLEANUP块也不会被执行。该选项只能用于BEFORE UNWIND类型的CATCH块中: DATA oref TYPE REF TO cx_root. 结果只输出 1 DATA myref TYPE REF TO cx_sy_arithmetic_error. CATCH SYSTEM-EXCEPTIONS [exc1 = n1 exc2 = n2 ...][OTHERS = n_others]. DATA: result TYPE i. 如果Form中出现了运行时错误,但Form签名又没有使用RAISING向上抛,则程序会直接挂掉,所以最好是向上抛 FORM subform RAISING cx_static_check cx_dynamic_check. ENDFORM. Funcion函数不会主动向外抛出运行时错误,所以要先在Function手动CATCH,再手动向外抛,如果出现运行时错误不抛出,则Function与会直接宕掉 l CX_STATIC_CHECK l CX_DYNAMIC_CHECK l CX_NO_CHECK CX_NO_CHECK类似于Java中的Error,CX_DYNAMIC_CHECK类似于Java中的RuntimeException,CX_STATIC_CHECK类似于Java检测性异常Exception [daiˈnæmik] 自己定义的异常一般继承CX_STATIC_CHECK、CX_DYNAMIC_CHECK,但CX_NO_CHECK也可以创建,不像Java CX_STATIC_CHECK是一个抽象类。在程序中使用RAISE EXCEPTION 手动抛出这类异常时,方法或过程接口上一定要显示的通过RAISING 来向上层抛出异常、或者直接在方法或过程中进行处理也可以,否则静态编译时就会出现警告。 CX_NO_CHECK类型的异常一般表示系统资源不足引起的,不能在方法或过程接口后面抛出CX_NO_CHECK类型的异常,它会被隐含的抛出与传递。系统中已有预定义这类异常。 如果程序逻辑能够排除可能性的潜在性错,相应的异常就可能不用处理或继续抛出,此类情况下可以使用CX_DYNAMIC_CHECK类型的异常,这与Java中的运行时异常相似,一旦发生也该类异常,表示问题出现在程序的本身设计上,程序设计不严谨(如没有判断空指针问题)。ABAP大多数的系统预定义的异类都是属于该类型异常,这就意味着不需要处理或抛出ABAP语句可能出现的每一种异常,但一旦发生了该类异常,则表示程序的出现了问题,程序执行的结果将不会在正确。 自定义的全局异常类名以ZCX_ 作为前缀 如果是通过Class Builder创建的全局异常类时,由于构造器是默认创建好的(异常相关参数已经固定下来了),不能传递自定义参数,所以异常文本ID只能通过TEXTID传递(参考触发类异常),但局部异常类没有这个限制。 如果某个变量参照的数据元素所对应的Domain具有转换规则,那么在输出时(如Write输出、ALV展示、文本框中显示),最后显示的结果会自动发生转换,如参照 ekpo-meins 表字段的变量赋值时就会发生转换,因为 ekpo-meins 所对应的元素Doamin设置了转换规则: 所以,在显示输出这样的数据时要注意,如果要显示原始数据,则不能参照该表字段来定义变量,而是自己定义。 DATA:i_meins LIKE ekpo-meins, 在调试过程中发现都是原始数据,自动转换发生在Write输出时: 输出时会发生自动转换,那么,在输入时,如从选择屏幕上录入的数据是参照带有规则转换的Domain的数据元素创建的选择屏幕字段时,从界面录入到ABAP程序中时,会自动按照转换规则进行转换,如下面从界面上输入的是 PC (外部格式的单位),但录入到ABAP程序中时,自动转换为ST(内部格式的部位),但再次Write输出时,又将 ST转换为PC输出(从内部转换为外部格式): 除了上面通过借助于参照带有转换规则的表字段进行自动转换外,实质上可以通过转换规则对应的输入输出函数进行手动转换,如VBAK-vbeln的转换规则: CONVERSION_EXIT_ALPHA_INPUT:输入转换,前面补齐零 此函数将字符类型的变量转换成SAP数据库中内部格式数据,如定单号vbeln的类型为 Char 10,如果输入的vbeln为6位,则会在前面补4个零(注:该函数的转换规则为:如果含有其他非数字,则不会补零,只有全部是数字时才补,这可以通过VBELN查看到),Number类型的不需要,因为在ABAP程序中N类型不足时长度时默认就会在前面补零(如 POSNR),而且Number类型的默认值就是全为零,而C类型不足时会以后面全补空格 CONVERSION_EXIT_ALPHA_OUTPUT:输出转换,去掉前导零 DATA: vbeln TYPE vbak-vbeln. WRITE 该语句根据Unit 来设置 该选项的使用限制如下: • • 如果 • 如果 从上面的限制条件来看,该格式化输出只针对 "必须是P类型 DATA: i_menge LIKE ekpo-menge VALUE '1.000'. 问:通过se11 我们可以看到ekpo中menge的数据元素是BSTMG,BSTMG的域是长度13小数位3位。在程序中我参照ekpo-menge定义的变量显示的时候后面都有3位小数,而我希望输出时与me23n一样,即去掉小数点后面多余的零,请问大侠们有没有比较好的办法。为什么me23n中“PO数量”显示的时候没有多余的零,而他们的数据元素是一样的。 答:MENGE实际上是个存储度量衡值的字段,他的基本数据类型是QUAN,他的小数位数并不是你看到的3,而是由这个字段关联的度量衡单位决定的,以MENGE为例,你可以在SE11的最右边一个Tab页,Currency/Quantity Fields里看到,他关联的单位是EKPO-MEINS DATA: i_menge LIKE ekpo-menge, SELECT menge meins meins FROM ekpo INTO(i_menge,i_meins,i_meins2) WHERE ebeln = '4500012164'. 在ALV中显示时,如果是金额或数量时,需通过Fieldcat设置cfieldname 、ctabname ;qfieldname、qtabname这样在显示时才会正确 也可直接使用Domain所配置的转换规则所对应的输入输出转换函数CONVERSION_EXIT_CUNIT_INPUT、 CONVERSION_EXIT_CUNIT_OUTPUT来手动对单位进行转换: PARAMETERS: p_in TYPE p DECIMALS 3, WRITE 输出金额 注意:这里的 DATA: p(6) TYPE p DECIMALS 5. TCURX:货币小数位表 TCURC:货币代码表 TCURR:汇率表 SAP表里存储的并不是货币的最小单位,一般是以货币最大单位(也是常用计量单元)来存储,不过在存储之前会使用经过转换:比如存储的金额是 100,则存储到表之前会除以一个转换因子后再存入数据表中(该转换因子是通过CURRENCY_CONVERTING_FACTOR函数获得的,如比CNY的转换因子为1,JPY为100),所以如果要读取出来自已进行展示,则需要再次乘以这个因子才能得到真正的金额数。另外,数据库中存储的虽然不是最小单位,但取出来后都是放在P类型的变量中的,所以取出来在内存中统计是不会有精度丢失的(P类型相当于Java中的BigDecimal类类型)。 TCURX-CURRDEC中存储的小数位实质上是根据同种币种的最大单位与最小的换算率= 10X来计算得到的,式中的X即TCURX-CURRDEC表字段中的小数位,如CNY中的最大单位元与最小单位分相差100倍,所以100 = 10X,X就为2,最后TCURX-CURRDEC存储的就是2(但如果值为2是可以不需要在TCURX表中配置的,所以查不到CNY的配置数据,因为不配置时默认值也是2);另外,JPY日元没有最小单位,所以最大单位与最小单位的换算率就是1(1 = 10X),所以X就为0,所以TCURX-CURRDEC存储的就是0。而转换因子计算式为:转换因子 = 100/10X,(CNY人民币:100/10X=100/102 =1,JPY日元:100/10X=100/100 =100),即转换因子 = 100/货币的最大单位与最小单位换算率,金额入库时需要除以这个转换因子,读取出来展示前需要乘以这个转换因子 数据库中用来存储金额的字段的类型都是P(.2),即带两位小数,因为转换因子最大也就是100(除以100后,即为小数点后2位),有的是零点几(在存入之前会将真实金额除以这个转换因子后再存入),所以存储类型为两位小数的数字类型即可。ABAP程序中用来存储从表中读取出来的内部金额的变量类型一定要具有两位类型的,否则在使用诸如CONVERT_TO_LOCAL_CURRENCY、CONVERT_TO_FOREIGN_CURRENCY转换函数或者是格式化输出时,都会有问题,所以在ABAP程序中定义这些用来存储数据库表中所存内部金额变量时,最好参照相应词典类型。 DATA: netpr LIKE vbap-netpr,"实际的类型为p(6.2) "第一种还原方式 一般而言,币种的小数位为2,所以系统默认的位数也是2,但是有一些特殊币种如日元JPY,没有小数位。只要小数位不等于2,需要在系统中特殊处理(通过转换因子进行转换,具体请参看后面SAP提供的函数 currency_converting_factor 实现过程)。在编程中 lList中,当输出CURR字段时,记得指定对应的货币: 如: WRITE: vbap-netwr CURRENCY vbap-waerk. lScreen中,对于CURR字段,需要设置对应的货币字段: lALV中,需要对FIELD CATALOG进行设置 如:ls_cfieldname = 'WAERS'. "这里的WAERS是内表中的另一货币字段,里面存储了相应金额的货币代码 货币的是:fieldcat-cfieldname、fieldcat-ctabname(内表名,可以不设置) 顺便数量也是相似的方法来处理的: 数量的是:fieldcat-qfieldname、fieldcat-qtabname(内表名,可以不设置) 下面是SAP转换因子函数,在金额存储与在ALV展示时都会自动除以与乘以这个转换因子: FUNCTION currency_converting_factor.
[FIELD VALUE 13.7. 从Screen Processing 屏幕处理切换到Lists列表输出
13.8.LIST 打印输出
14.Messages
14.1.00消息ID中的通用消息

14.2.消息常量
14.3.静态指定
14.4.动态指定
id(2) VALUE '00',
num(3) VALUE '002'.
MESSAGE ID id TYPE t NUMBER num.14.5.消息拼接MESSAGE …INTO
CALL FUNCTION ... EXCEPTIONS error_message = 4.
IF sy-subrc = 4.
MESSAGE ID sy-msgid TYPE sy-msgty NUMBER sy-msgno
INTO msgtext
WITH sy-msgv1 sy-msgv2 sy-msgv3 sy-msgv4.
ENDIF. 14.6.修改消息显示性为…DISPLAY LIKE…
14.7. RAISING
WITH MESSAGE_TYPE MESSAGE_PLACE MESSAGE_EVENT
RAISING MESS.
PUBLIC SECTION.
CLASS-METHODS m1 EXCEPTIONS exc1.
ENDCLASS.
CLASS c1 IMPLEMENTATION.
METHOD m1.
MESSAGE 'Message in a Method' TYPE 'I' RAISING exc1.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
c1=>m1( )."第一次调用
c1=>m1( EXCEPTIONS exc1 = 4 )."第二次调用
IF sy-subrc = 4.
write: / '被捕获'.
ENDIF.14.8.CALL FUNCTION…EXCEPTIONS
[exc1= n1 exc2= n2]
[others= n_others] ]
[ERROR_MESSAGE = n_error].
EXCEPTIONS
error_message = 5
"被e捕获,如果注释掉下面E类型异常捕获列表,则会被error_message捕获
e = 4
d = 6.14.8.1.error_message = n_error捕获消息
14.9.各种消息的显示及处理
14.10.异常处理
14.10.1.RAISE [EXCEPTION]…触发异常
14.10.1.1.触发类异常
DATA oref TYPE REF TO cx_root.
DATA text TYPE string.
DATA i TYPE i.
TRY .
i = 1 / 0.
CATCH cx_root INTO oref.
text = oref->get_text( ).
WRITE: '---' , text.
RAISE EXCEPTION oref.
ENDTRY.
text TYPE string.
TRY.
RAISE EXCEPTION TYPE cx_sy_dynamic_osql_semantics
EXPORTING textid = cx_sy_dynamic_osql_semantics=>unknown_table_name token = 'Test'.
CATCH cx_sy_dynamic_osql_semantics INTO exc.
text = exc->get_text( ).
MESSAGE text TYPE 'I'.
ENDTRY.


14.10.1.2.RESUMABLE选项
DATA text TYPE string.
DATA i TYPE i.
TRY .
RAISE RESUMABLE EXCEPTION TYPE cx_demo_constructor
EXPORTING
my_text = sy-repid.
i = i + 1.
WRITE: / i.
CATCH BEFORE UNWIND cx_demo_constructor INTO oref .
text = oref->get_text( ).
IF i < 1.
RESUME.
ENDIF.
WRITE:/ '--'.
ENDTRY.14.10.2.捕获异常
14.10.2.1.类异常捕获TRY…CATCH
DATA err_text TYPE string.
DATA result TYPE i.
TRY.
result = 1 / 0.
CATCH cx_sy_arithmetic_error INTO myref.
err_text = myref->get_text( ).
ENDTRY.14.10.2.2.老式方式捕获runtime errors(运行时异常)
…
ENDCATCH.
CATCH SYSTEM-EXCEPTIONS arithmetic_errors = 5.
result = 1 / 0.
ENDCATCH.
IF sy-subrc = 5.
WRITE / 'Division by zero!'.
ENDIF.14.10.3.向上抛出异常
...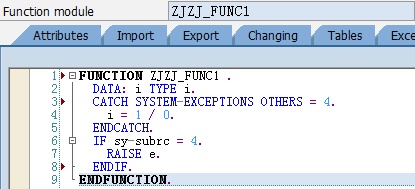
14.10.4.类异常
15.数据格式化、转换
15.1.数据输入输出转换
15.1.1.输出时自动转换
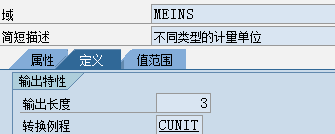
i_meins2 TYPE c LENGTH 3.
START-OF-SELECTION.
SELECT meins meins FROM ekpo INTO (i_meins,i_meins2) WHERE ebeln = '4500012164'.
"输出时, i_meins会自动发生转换,但 i_meins2 不会
WRITE: i_meins,i_meins2.
ENDSELECT.
SKIP.
DATA: i_meins3 LIKE ekpo-meins.
"注:这里只能是内部单位ST,而不是PC,因为Write时是输出转换(即内->外的转换)
i_meins3 = 'ST'.
"只要是参考过 ekpo-meins 的变量,Write输出时自动转换
WRITE:/ i_meins3.
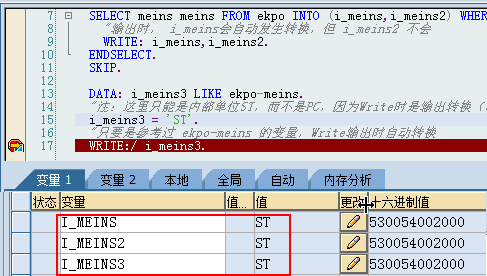
15.1.2.输入时自动转换

15.1.3.通过转换规则输入输出函数手动转换
DATA: str TYPE string VALUE '600000'.
CALL FUNCTION 'CONVERSION_EXIT_ALPHA_INPUT'
EXPORTING input = str
IMPORTING output = vbeln.
"自动输出转换,输出最初始数据,但程序内部已发生变化
WRITE: / vbeln."600000
15.2.数量小位数格式化
DATA: p1 TYPE p LENGTH 8 DECIMALS 2.
p1 = '1.10'.
"如果
WRITE:/ p1 UNIT 'D10'."1.10
DATA: p3 TYPE p LENGTH 8.
p3 = '1'.
WRITE:/ p3 UNIT 'D10'."1
DATA:p2 TYPE p LENGTH 8 DECIMALS 4.
p2 = '1.1000'.
"多余的小数位全部是零时,会被截断
WRITE:/ p2 UNIT 'D10'."1.100
p2 = '1.1001'.
"多余的小数部分不是零时,也会直接忽略该选项
WRITE:/ p2 UNIT 'D10'."1.1001
"注:UNIT选项后面一定要是内部单位ST,而不是外部单位PC,因为这里是WRITE输出,
"即内部转换外部,将数据库表存储的原数据格式化输出显示
WRITE: / i_menge UNIT 'ST'."1
WRITE: / i_menge."1.00015.2.1.案例

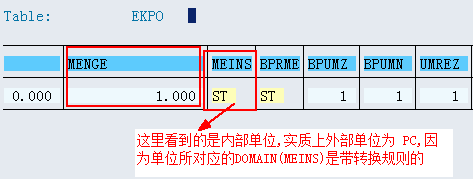
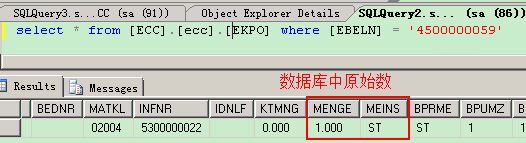
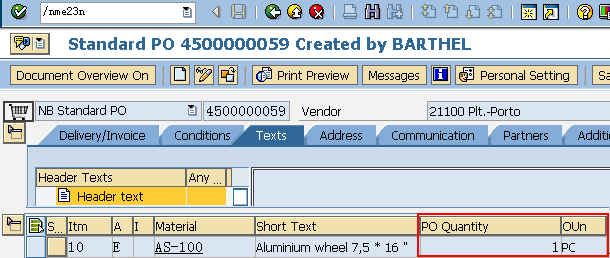
i_meins LIKE ekpo-meins,
i_meins2 TYPE c LENGTH 3. "没有参照表字段ekpo-meins,所以Write输出时不会自动输出转换
"带单位的数量需要根据单位进行格式化输出,这样才与ME23N 中显示的数据一样
WRITE: / i_menge UNIT i_meins,i_meins, i_menge,i_meins2.
ENDSELECT.![]()

15.3.单位换算:UNIT_CONVERSION_SIMPLE
unit_in LIKE t006-msehi DEFAULT 'M',"米
unit_out LIKE t006-msehi DEFAULT 'MM',"毫米
round(1) TYPE c DEFAULT 'X'.
DATA: result TYPE p DECIMALS 3.
CALL FUNCTION 'UNIT_CONVERSION_SIMPLE'
EXPORTING
input = p_in
round_sign = round"舍入方式(+ up, - down, X comm, SPACE.)
unit_in = unit_in
unit_out = unit_out
IMPORTING
output = result.
WRITE: 'Result: ',result.![]()
15.4. 货币格式化
p = '1.234'.
WRITE: p CURRENCY 'aa'."1,234.0015.4.1.从表中读取日元并正确的格式化输出


waers LIKE vbap-waerk,
jpy_netpr TYPE i,
netpr1(6) TYPE p DECIMALS 3.
"通过SQL从数据库查询出来的是真实存储在表里的数据,没有经过其他转换,日元存到数据库中时缩小了100倍,所以要还原操作界面上输入的日元金额,则需要使用后面的格式化输出
SELECT SINGLE netpr waerk INTO (netpr,waers) FROM vbap WHERE waerk = 'JPY' AND vbeln = '0500001326'.
WRITE: waers,netpr."数据库中的值,被缩小了100倍
WRITE: / 'Format:', netpr CURRENCY waers.
"第二种转换方式:也可以通过以下函数先获取JPY货币代码的转换因子,再直乘以这个因子也可
DATA: isoc_factor TYPE p DECIMALS 3.
CALL FUNCTION 'CURRENCY_CONVERTING_FACTOR'
EXPORTING
currency = waers
IMPORTING
factor = isoc_factor.
jpy_netpr = netpr * isoc_factor."乘以100倍,因为在存入表中时缩小了100倍
WRITE: / 'Calc factor:', jpy_netpr.
"格式化输出实质上是与存储金额的变量本身的类型小数位有关:上面将从表中读出的金额(小数两位)赋值给变量netpr1(小数三位),格式化后会扩大10倍(因为多了一位小数位)。所以格式化正确输出的前提是要用来接收从表中读取的金额变量的类型要与数据表相应金额字段类型相同,否则格式化输出会出错
netpr1 = netpr.
WRITE: / netpr1, netpr1 CURRENCY waers."格式化的结果是错误的
15.4.2.SAP 货币转换因子

*"----------------------------------------------------------------------
*"*"Lokale Schnittstelle:
* IMPORTING
*" VALUE(CURRENCY) LIKE TCURR-TCURR
*" EXPORTING
*" VALUE(FACTOR) TYPE ISOC_FACTOR
*" EXCEPTIONS
*" TOO_MANY_DECIMALS
*"----------------------------------------------------------------------
DATA: cur_factor TYPE isoc_factor.
*- determine Decimal place in currency from TCURX
CLEAR tcurx.
"首先根据币种到db表tcurx中读取相应的小数位数currdec
SELECT SINGLE * FROM tcurx WHERE currkey EQ currency.
"如果没有维护相应币别信息则默认currdec = 2
IF sy-subrc NE 0.
tcurx-currdec = 2.
ENDIF.
"如果currdec 大于了 5就报错
IF tcurx-