【视频行为识别5】(双流网络)Two-stream Convolution Networks for Action Recognition in Videos(2014)
Two-stream Convolution Networks for Action Recognition in Videos
论文链接:Two-Stream Convolutional Networks for Action Recognition in Videos
背景:
视频相比于图像而言,是一帧帧图像的集合。因此,很自然可以想到从两个维度去提取视频信息:
- 空间:单帧图像包含的信息;
- 时间:多帧图像之间包含的运动信息;
所以文章就想能否同时利用视频的空间信息与时间信息,来更好的提取视频特征,进而进行视频分类任务。
主要贡献:
(1)提出基于two-stream结构的CNN,由空间和时间两个维度的网络组成。
(2)验证了即使在较小规模的训练数据集上,在多帧稠密光流上训练的卷积神经网络可以获得非常好的性能。
(3)展示了多任务学习(multiple learning),应用于不同的运动分类数据集,可以同时提升数据集的规模和检测性能。
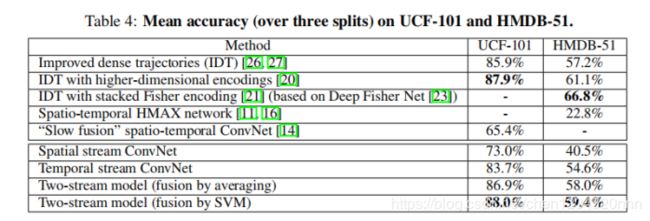
UCF-101和HMDB-51两个数据集上取得state-of-the-art效果,也是深度学习进入行为识别的转折点。
网络结构图:

视频信息可以分为空间和时间两个部分:
1)空间部分:通过单帧图像表达图像中的场景和对象的信息。
2)时间部分:通过多帧来表示对象的运行信息和时序行为。
本文网络结构:
1)双流(two stream)网络结构:每个流都有一个CNN网络,其尾部接一个softmax输出概率分布值,最后对两个网络的softmax值进行融合。考虑两种融合方法:平均average和使用SVM(作者实验中SVM效果更好)。
2)空间流网络(Spatial stream ConvNet):输入为单张RGB图像,经过一系列卷积、全连接层后接一个sofrmax输出概率分布值。
3)时间流网络(Temporal stream ConvNet):输入为多帧图像间的光流(optical flow),同样经过一系列卷积、全连接层后接一个sofrmax输出概率分布值。(作者实验部分对比了不同帧数光流的效果,最后取光流数L=10).
4)空间流和时间流使用的CNN网络结构基本一致,除了光流的conv2中没有使用normalization层。
网络中最后的class score fusion将两个stream的score值融合在一起,文章一共尝试了:average、SVM这两种方法,最后貌似SVM效果更佳。
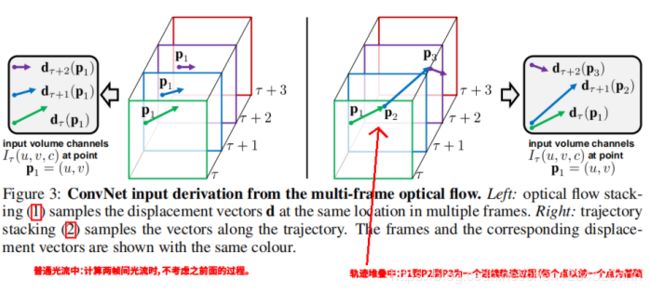
光流的堆叠方式(optical flow stacking):

1)上图(a)为第k-1帧图像,图(b)为第k帧图像。图(c)为两帧之间蓝色框中的光流信息。
而图(d)为光流的水平方向分量dx,图(e)为光流的垂直方向分量dy(较高强度对应正值,较低强度对应负值)。
2)对于空间尺寸为W×H,时序长度为L帧的视频片段。每个帧间光流会有水平方向分量dx和垂直方向分量dy。将L帧中的dx和dy堆叠起来就得到长度为2L的channel,则光流网络的输入就为W×H×2L。
PS:作者文章中还讨论了另外一种形式----》轨迹堆叠(Trajectory stacking),这种方式,就是从第1到L帧中,轨迹是一个连续的过程(作者最后没有使用这种方式,所以这里也就不细讲了),如图:
实验:
对比光流中不同帧数的效果:
L=1时效果相对较差,L=5时效果提升较大,L=10时相较于L=5的提升已经不太大了,本文中L取10.

对比两个流网络的融合方式:

实验结果表明:SVM的方法更好。
结果部分:
具体细节没什么好讲的了,2014年提出的方法,打败了传统方法中最好的IDT,也开启了双流网络的处理思路。
总结:
本文出自2014年,在此之前传统方法效果最好的为IDT。本文最大的贡献就是提出了two stream的结构,然后实验验证双流在小数据集中训练的也能取得不错的效果,另外训练时在两个不同的数据集分别采用了两个softmax进行训练,最后貌似对这两个softmax值取了平均,所谓的多任务识别(这个在现在貌似不太必要细说了)。