2019阿里云峰会·上海开发者大会于7月24日盛大开幕,本次峰会与未来世界的开发者们分享开源大数据、IT基础设施云化、数据库、云原生、物联网等领域的技术干货,共同探讨前沿科技趋势。本文整理自开源大数据专场中阿里巴巴高级技术专家杨克特(鲁尼)先生的精彩演讲,主要讲解了Apache Flink过去和现在的发展情况,同时分享了对Apache Flink未来发展方向的理解。
《Apache Flink 的过去现在和未来》PPT下载
以下内容根据演讲视频以及PPT整理而成。
一、Flink的过去
1.Flink 的出现
Apache Flink项目在捐献给Apache之前,是由柏林工业大学博士生发起的项目,当时的Flink系统还是一个基于流式Runtime的批处理引擎,主要解决的也是批处理的问题。2014年,Flink被捐献给Apache,并迅速成为Apache 的顶级项目之一。2014年8月份,Apache发布了第一个Flink版本,Flink 0.6.0,在有了较好的流式引擎支持后,流计算的价值也随之被挖掘和重视;同年12月,Flink发布了0.7版本,正式推出了DataStream API,这也是目前Flink应用的最广泛的API。
2.Flink 0.9
State的支持和处理是流计算系统难以回避的存在,早期的流计算系统会将State的维护和管理交给用户,如Storm和Spark Streaming。这种做法会带来两个问题,一方面提高了编写流计算系统的门槛;另一方面,如果用户自己维护State,容错成本和系统提供Exactly Once 语义的成本将会提高。因此,2015年6月发布的Flink 0.9版本引入了内置State支持,并支持多种State 类型,如ValueState、MapState、ListState 等。
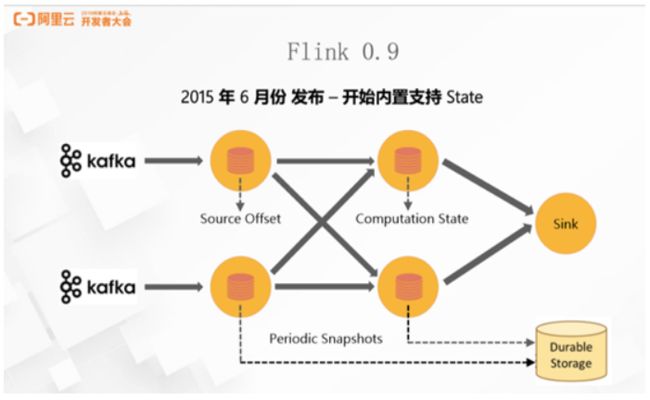
同时为了支持 Exactly Once 的一致性语义,还需要将本地的 State 组装成一个全局的 Checkpoint。Flink 0.9中引入的Global Checkpoint机制是基于经典的Chandy-Lamport算法进行的改进。如图,Flink 会在数据源中定期插入Barrier,框架在看到 Barrier 后会对本地的 State 做一个快照,然后再将 Barrier 往下游发送。我们可以近似的认为处理 Checkpoint 的Barrier只会引出一个消息处理的 overhead,这和正常的消息处理量相比几乎可以忽略不计。在引入 Chandy-Lamport 算法以后,Flink 在保证 Exactly Once 的前提下,提供高吞吐和延迟便不再是一个 tradeoff,可以同时保证高吞吐和低延迟,而其它系统在做类似设计时,往往需要在吞吐和延迟之间做取舍,高一致性会影响吞吐量,反之在大的吞吐下无法保证一致性。

3.Flink 1.0的基石
Flink 1.0 版本加入了基于事件时间的计算支持,引入了 Watermark 机制,可以高效的容忍乱序数据和迟到数据。Flink 1.0同时还内置支持了各种各样的 window,开箱即用的滚动、滑动、会话窗口等,还可以灵活地自定义窗口。再加上 Flink 0.9 中加入的 State API 和高效的 Checkpoint 支持,这一切构成了 Flink 1.0 版本的基石。

二、阿里巴巴与Flink
2015年之后,阿里巴巴开始注意到 Flink 计算引擎,并且非常认可 Flink 系统设计理念的先进性,看好其发展前景,因此阿里巴巴内部开始大量使用 Flink,同时也对 Flink 做了大刀阔斧的改进。
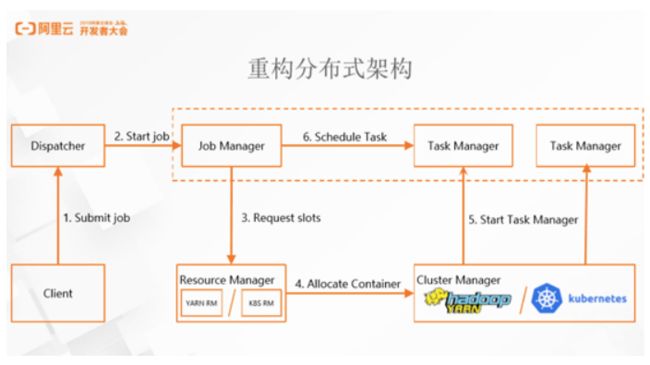
1. 重构分布式架构
在阿里和社区合作之后,考虑到阿里内部业务数据庞大、线上压力非常大,因此第一个大刀阔斧的改进就是重构分布式架构。早期的Flink在各个角色之间没有清晰的划分,大部分职责集中在同一角色中,比如作业的调度,资源的申请、Task 的分配等内容,并且,这个角色还需要管理集群里的所有作业,在作业量非常大的阿里内部场景,很快就暴露了这样的瓶颈。在重构分布式架构过程中,阿里有意识的将调度作业和申请资源的角色进行分离,设定了Job Manager和Resource Manager两个职责,此后Resource Manager可以完全进行插件化处理,方便对接各种资源调度系统,如YARN和Kubernetes。以对接Kubernetes为例,只需写一个插件,所有的作业便可以顺畅的运营在整个环境中,大大简化了流程。同时,这个架构还支持每一个作业使用独立的 Job Manager 和 Resource Manager,这样也大大提升了扩展性,一个集群可以轻松支持成千上万的作业。
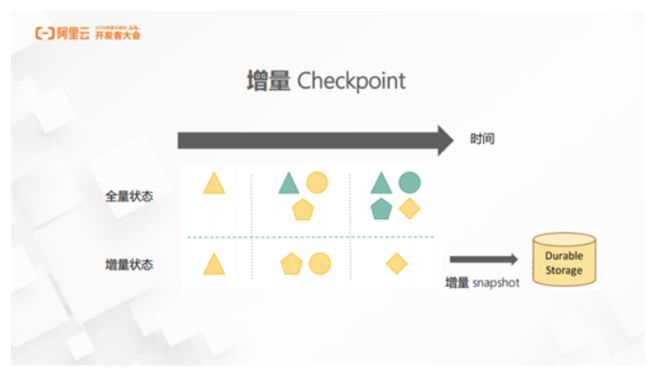
2. 增量 Checkpoint
为了解决数十 TB 量级 State 数据,阿里在 Flink 中引入了增量 Checkpoint 机制。在早期版本中,Flink 在执行 Checkpoint 的时候,会将每个 Task 本地的 State 数据全量拷贝到可靠存储上。当 State 的量级上到 TB 之后,每次都备份全量的数据显然是一个无法接受的方案。增量 Checkpoint 机制也比较容易理解,就是在每一次 Checkpoint 时,不将所有 State 数据都刷新到可靠的存储上,而只将这个 Checkpoint 周期内新增的 State 数据进行备份。而在作业碰到异常重启恢复的时候,再使用全量的数据进行恢复。有了这个机制之后,Flink 便可以轻松处理数十 TB 的量级 State 数据。这个问题也是当时制约我们内部机器学习系统的最大因素,解决这一问题之后,Flink 流式应用的范围变得更加广泛。
3. 基于 credit 的流控机制
Flink 1.0 版本会在多个 Worker 之间共享一个 TCP channel。如果多个 Operator 在一个Task Manager 中,Operator 之间的网络连接又是 TCP 共享,当其中一个 Operator 产生反压,就会影响到同一个进程中其它 Operator 的处理效率,导致运行不稳定。因此在网络层,阿里引入了基于信用的流控机制,每个 Operator 不能无限制的往 TCP channel 中发送数据。每个 Operator 有自己的信用,当它向下游发送数据时需要减信用,当下游真正消费数据后,这个信用分数才会加回来,上游才可以继续往这个虚拟 Channel 中发送数据。Flink 引入精细的流控机制之后,作业的吞吐或延迟都变得更加稳定,不会因为某一个算子的临时抖动导致整个作业的不稳定。

4. Streaming SQL
阿里巴巴集团内部有大量的作业,作为平台维护方,如果用户作业出现问题,需要第一时间查看用户的代码找出问题。但是用户代码数量不一,多则上万行,少则上百行,使得维护成本非常高。所以阿里选择统一的 Streaming SQL 作为开发语言,通过查看用户的 SQL 就能够了解用户的意图。选择 SQL 还有很多其他好处,比如 SQL 会集成一个优化器,让系统和框架帮助用户优化作业,提升用户的执行效率。
这里需要说明一下 Streaming SQL 的语义,这也是一些刚接触 Streaming SQL 的用户的典型问题。简单来说,Streaming SQL和传统的批处理 SQL 语义上是一致的,只是在执行模式和结果输出方式上有所不同。比如下图是一个用户的分数表,需要做简单的分数求和,同时计算结果的最后更新时间。在 SQL 语句中,SUM(Score) 计算分数,同时取 MAX(Time),与批处理不同之处在于,流式数据的实时性使 Streaming SQL 在运行时无法一下子看到所有数据,如在 12:01 时,Streaming SQL 会数出一个空记录,以为这时候系统连一条记录都没有看到。随着记录源源不断的到来,在12:04时输出第一次的结果,这是对12:04之前记录的数据都进行了计算。在12:07时,可以看到当前表中所有的数据,对结果进行一次更新输出。假设 USER_SCORES 表一开始就存在,那么批处理运行的结果与流计算最终的结果是一样的,这也就说明了流批一体的 SQL 语义的一致性。

5. Flink 在阿里的服务情况
在 2018 年双 11,阿里巴巴服务规模已经超过万台集群。单作业已经达到了数十 TB 的状态数据,所有的作业加起来更是达到了 PB 级。每天需要处理超过十万亿的事件数据。在双 11 的零点峰值时,数据处理量已经达到了 17 亿条每秒。

在过去,Flink 基本上围绕着 Continuous Processing 和 Streaming Analytics 领域展开,包括 DataStream API 和后来提出的 Streaming SQL。Flink 不仅在 Continuous Processing 和 Streaming Analytics 领域站稳了脚跟,并且成为了当前领域的领先者。

三、Flink的现在
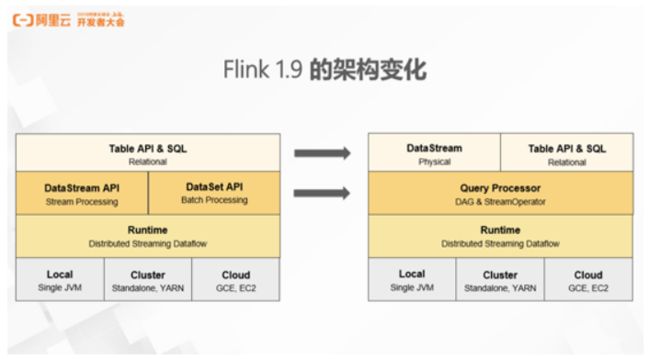
1. Flink 1.9的架构变化
目前 Flink 最新的版本是1.9,Flink 在这个版本上做了较大的架构调整。首先,Flink 之前版本的 Table API 和 SQL API 是构建于两个底层的 API 之上,即 DataStream API 和 DataSet API。Flink 1.9 经历了较大的架构调整之后,Table API 和 DataStream API 已成为同级的 API。不同之处在于 DataStream API 提供的是更贴近物理执行计划的 API,引擎完全基于用户的描述能执行作业,不会过多的进行优化和干预。Table API 和 SQL 是关系表达式 API,用户使用这个 API 描述想要做一件什么事情,由框架在理解用户意图之后,配合优化器翻译成高效的具体执行图。这两套 API 在未来都会同时提供流计算和批处理的支持,在此基础之上,Flink 会共享统一的 DAG 层和 Stream Operator,Runtime 层则保留了分布式的 Streaming DataFlow。
2. 统一 Operator 抽象
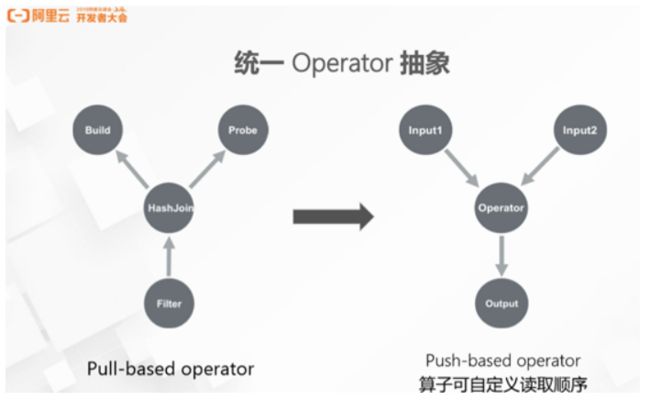
Flink 架构的改动引发了统一 Operator 抽象问题,因为原来的 Operator 抽象只适用于Flink 的 Streaming 作业,Flink 的 DataSet API 并没有使用原来的 Operator 抽象。Flink 早期的代码参考了经典数据库的方式,所有的算子都是以 pull 的模式执行。如下图, Filter 算子尝试找上游拉取数据,上游算子 HashJoin 会尝试往两端(Build 端和 Probe 端)拉取数据,做 Join。在低延迟和高吞吐要求的情况下,Flink 的 Streaming 作业通过推的方式执行,框架在读取到数据之后会以 push 的方式推给所有需要的 Operator。为了统一 Operator 抽象,让 Streaming Operator 也能做到 HashJoin 的操作,阿里在协议上做了扩展,扩展的语义中算子可以通知框架想要的输入顺序。下图中,HashJoin 通知 Framework 优先将 Build 端数据推给自己,在 HashJoin 处理完 Build 端,同时构建好 Hashtable 之后,再把Probe端的数据推给 HashJoin。以往开发人员支持流或批处理时很多算子需要写两套程序,统一 Operator 抽象之后,算子可以实现复用,帮助开发人员提高开发效率,达到事半功倍的效果。
3. Table API & SQL 1.9新特性
- 全新的 SQL 类型系统:Table API & SQL 1.9 引入了全新的 SQL 的类型系统。以往的Table 层的类型系统复用了 Runtime 的 TypeInformation,但在实际操作过程当中遇到较多的限制。引入全新的 SQL 类型系统可以更好的对齐 SQL 语义。
- DDL初步支持:这个版本中 Flink 还引入了 DDL 的初步支持,用户可以使用 Create Table 或 Drop Table 等简单的语法定义表格或删除表。
- Table API增强:Table API 原来仅为关系表达式的 API,Table API & SQL 1.9中现在加入了 Map,FlatMap 等更加灵活的 API。
- 统一的Catalog API:Table API & SQL 1.9 引入了统一的 Catalog API 之后,可以方便的和其它的 Catalog 对接。比如常见的 Hive,可以通过统一的 Catalog API,实现与 Hive.metastore 交互的插件,让 Flink 可以直接读取和处理 Hive 中的表。
- Blink planner:Table API 增加了 Blink planner 的支持,因为在底层的 Runtime 做了较大的变化后,上层需要 SQL 的 Planner 与底层的 Runtime 进行对接。为了确保原来的 Table API 用户尽量不受影响,社区完整保留了原来的 Flink Planner。但同时又引入了新的 Blink planner,与新的 Runtime 设计进行对接。

Blink Planner Feature
Blink planner 增加了较多的新功能。首先,Blink planner 对数据结构进行了二进制化、增加了更丰富的内置函数、在聚合时引入了 Minibatch 优化、采取多种解热点手段来解决聚合过程中碰到的热点数据等。另外,流计算中的维表关联的应用非常广泛,开发者需要对数据流进行数据量维度的扩增,所以 Blink Planner 也支持了维表关联。TopN 在电商领域应用非常广泛,通过 Blink Planner 提供的 TopN 功能就可以轻松完成统计成交额排名前几的商家这样的功能。在对 TopN 功能进行简单的扩展之后,Blink Planner 还支持了高效的流式去重。值得一提的是,Blink Planner 已经能够完整的支持批处理,目前阿里内部版本已经可以跑通完整的 TPC-H 和 TPC-DS 这样标准的 Benchmark 测试集。

4. 批处理优化
Flink 在 Runtime 层针对批处理实现了较多的优化。批处理中最经典问题便是错误处理的恢复。如下图,Flink 在拓扑中可以比较灵活的调配每个边的传输类型,在 A 跟 B 之间以网络直连,B 跟 C 之间插入 Cache 层,在输出端输出 Cache 数据,减少 FailOver 传播的代价。假设在 D 节点发生了错误,从 D 节点向上回溯到需要重新计算的范围,当回溯到 Cache 层时,如果 B1 的结果已经存在于 DFS 里或者 Cache 到了其它地方,错误的回溯则不需要再继续进行。为了确保一致性,到 Cache 层之后还需继续向下回溯一遍,对下游还未执行或执行一半的作业进行简单的重启,如果没有 Cache 支持,节点之间都是网络连接,当 D 节点发生错误时,错误会蔓延到整张图,而在有 Cache 支持的情况下只需重启其中很小的子图,可以大大提高 Flink 面对错误时的恢复效率。

插件化Shuffle Manager:Flink 1.9 版本增加了 Shuffle 插件,用户自己可以实现中间的Shuffle 层,通过专门的 Service 接收中间的数据。当然也可以复用基于 Yarn 的 Shuffle Service。

5. 生态
Flink 1.9 版本在生态方面有较大的投入,比如增加了 Hive 的兼容性。在引入统一的Catelog API 之后,Flink 已经可以直接读取 Hive Metastore。用户可以通过 Flink SQL 处理 Hive 中的数据,同时处理完数据之后 Flink 能够将数据写回 Hive 表,写回的方式可以兼容 Hive 的数据格式,若有后续的 Hive 作业,用户可以在 Hive 表上继续操作。另外,为了给用户提供更好的开发体验,Flink 和 Zeppelin 进行了整合,用户可以直接在 Notebook 中使用 Flink SQL,也可以使用 Python API 编写 Flink 的作业。
6. 中文社区
Flink 社区对中文用户非常重视。Flink 社区官网中已经增加了中文版文档的支持。另外,社区开通了 Flink 中文用户邮件列表,用户订阅邮件列表后,可以使用中文描述问题,社区中会有非常多的热心爱好者帮助解答问题。

Flink 在实时计算和流计算领域的领先地位已毋庸置疑,后面对批处理支持将会重点关注。从 Flink 1.9 版本中可以看到,无论是推出更强大的 SQL 执行引擎,还是在 Runtime 层对错误恢复更友好的支持,都表明了 Flink 1.9 版本对于批处理的重视程度,而这仅仅是开始。
四、Flink 未来发展方向
1. Micro Services 案例
如下图,电商系统中有订单层、订单交易系统、库存系统、支付系统和物流系统。首先Micro services 之间以事件方式驱动系统之间的调用。用户触发一个订单,订单系统收到订单做计算逻辑,再调用库存系统,以上操作是典型的事件驱动模型。为了保证性能和稳定性,在不同的 Micro Services 中需要使用 RPC Call,如果使用同步的 RPC Call,则需要解决线程数据量膨胀问题,所以需要在 Micro Services 之间会引入 Async Call。由于每个 Micro Service 的处理能力有限,比如当订单跟库存的 RPC 比例是 1:10 比例时,我们不能无限制的向下游系发送 RPC 调用,因此需要引入一套流控的机制,适当放缓发送的 RPC 的量。但用户流量难以预测,最佳解决方案是每个 Micro Service 都可以单独的扩容和缩容。回到订单系统,当订单系统压力较大时,对订单层做扩容,或者当库存处于流量低峰时,可以进行服务能力的缩减,所有的系统都需要数据的持久化,而系统背后都离不开 DB 的支持。
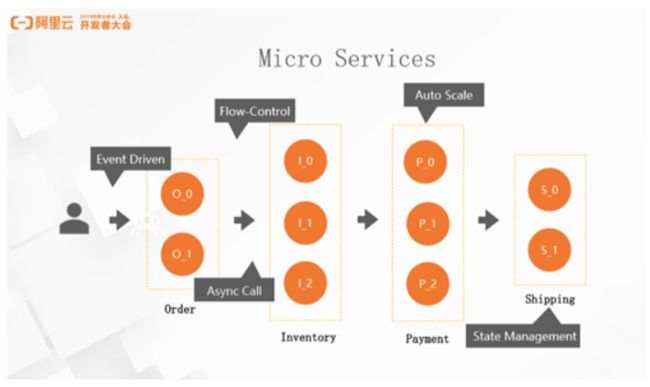
总结起来,Micro Service 需要几点核心要素。第一,事件驱动,第二是系统间的异步传输,同时需要具备较好的流控机制,在节点之间和节点内做动态的扩缩容,最后需要有自己的 DB,可以理解为 Micro Service 需要有对 State 的支持,能够存储历史状态。
不难发现,Micro Service 的需求 Flink 都能够覆盖。首先,Flink 是以消息为驱动的系统,同时有非常精细的流控机制;因为网络之间天然的解耦,Flink 的数据传输都是异步进行;除此之外,Flink 还可以单独为每一个算子增加并发或者缩减并发,内置 State 的支持等等。Micro Services 的场景远远大于流计算和批处理的场景,相信在不远的将来 Flink 的社区也会朝这个方向做更多的探索和尝试,实现对 Event-driven Application 服务场景的支持。

Apache Flink 首届极客挑战赛
持续学习、和同行交流的机会,由贾扬清助阵,阿里云计算平台事业部、天池平台、intel 联合举办的首届 Apache Flink 极客挑战赛重磅来袭!
聚焦机器学习与计算性能两大时下热门领域,参与比赛,让自己成为技术多面手,还有机会赢得 10W 奖金。

原文链接
本文为云栖社区原创内容,未经允许不得转载。