InceptionNet
InceptionNet诞生于2014年,当年ImageNet竞赛冠军,Top5错误率为6.67%
InceptionNet引入了Inception结构块,在同一层网络内使用不同尺寸的卷积核,提升了模型感知力使用了批标准化缓解了梯度消失
- Inception V1(GoogleNet)——构建了1x1、3x3、5x5的 conv 和3x3的 pooling 的分支网络module,同时使用MLPConv和全局平均池化,扩宽卷积层网络宽度,增加了网络对尺度的适应性;
- Inception V2——提出了Batch Normalization,代替Dropout和LRN,其正则化的效果让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高,同时借鉴VGGNet使用两个3x3的卷积核代替5x5的卷积核,在降低参数量同时提高网络学习能力;
- Inception V3——引入了 Factorization,将一个较大的二维卷积拆成两个较小的一维卷积,比如将3x3卷积拆成1x3卷积和3x1卷积,一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力,除了在 Inception Module 中使用分支,还在分支中使用了分支(Network In Network In Network);
- Inception V4——研究了 Inception Module 结合 Residual Connection,结合 ResNet 可以极大地加速训练,同时极大提升性能,在构建 Inception-ResNet 网络同时,还设计了一个更深更优化的 Inception v4 模型,能达到相媲美的性能。
网络结构
InceptionNet的基本单位是Inception结构块,在同一层网络中使用了不同尺寸的卷积核,可以提取不同尺寸的特征信息
通过1x1卷积核作用到输入特征图的每个像素点,通过设定少于输入特征图的深度达到降维减少了参数量和计算量
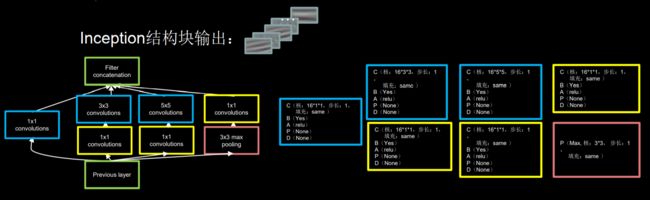
Inception结构块设计
class ConvBNAct(Model):
def __init__(self, ch, kernel_size=3, strides=1, padding='same'):
super(ConvBNAct, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernel_size, strides=strides, padding='same'),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False)
return x
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNAct(ch, kernel_size=1, strides=strides)
self.c2_1 = ConvBNAct(ch, kernel_size=1, strides=strides)
self.c2_2 = ConvBNAct(ch, kernel_size=3, strides=1)
self.c3_1 = ConvBNAct(ch, kernel_size=1, strides=strides)
self.c3_2 = ConvBNAct(ch, kernel_size=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.p4_2 = ConvBNAct(ch, kernel_size=1, strides=strides)
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.p4_2(x4_1)
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
精简InceptionNet
包含四个Inception结构快,每两个结构块组成一个block,每个block的第一个结构块步长是2,使输出特征数据减半,第二个结构块步长是1,因此将输出特征图深度加深(self.out_channels *= 2),尽可能保证特征抽取信息的承载量一致
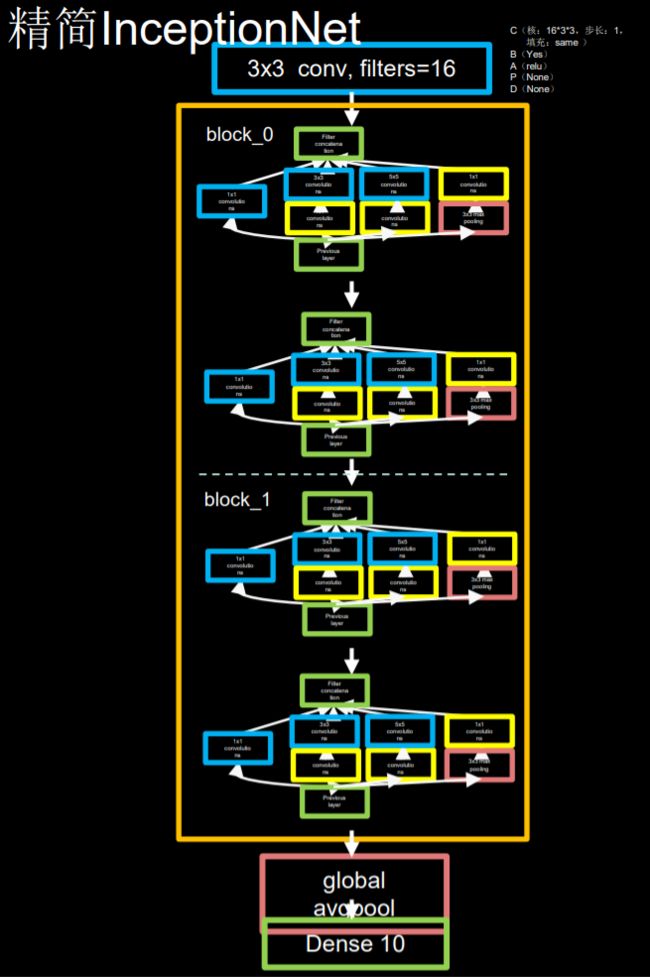
网络搭建示例
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Conv2D, MaxPool2D, Activation, BatchNormalization, Dropout
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ConvBNAct(Model):
def __init__(self, ch, kernel_size=3, strides=1, padding='same'):
super(ConvBNAct, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernel_size, strides=strides, padding='same'),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False)
return x
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNAct(ch, kernel_size=1, strides=strides)
self.c2_1 = ConvBNAct(ch, kernel_size=1, strides=strides)
self.c2_2 = ConvBNAct(ch, kernel_size=3, strides=1)
self.c3_1 = ConvBNAct(ch, kernel_size=1, strides=strides)
self.c3_2 = ConvBNAct(ch, kernel_size=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.p4_2 = ConvBNAct(ch, kernel_size=1, strides=strides)
def call(self, x):
x1 = self.c1(x)
x2_1 = self.c2_1(x)
x2_2 = self.c2_2(x2_1)
x3_1 = self.c3_1(x)
x3_2 = self.c3_2(x3_1)
x4_1 = self.p4_1(x)
x4_2 = self.p4_2(x4_1)
x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3)
return x
class Inception10(Model):
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(Inception10, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNAct(init_ch)
self.blocks = tf.keras.models.Sequential()
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
self.out_channels *= 2
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = Inception10(num_blocks=2, num_classes=10)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = './checkpoint/Inception10.ckpt'
if os.path.exists(checkpoint_save_path + ".index"):
print('------------- load the model ------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=128, epochs=5, validation_data=(x_test, y_test),
validation_freq=1, callbacks=[cp_callback])
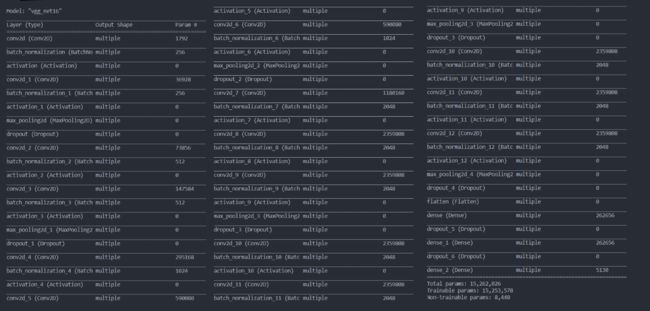
model.summary()
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
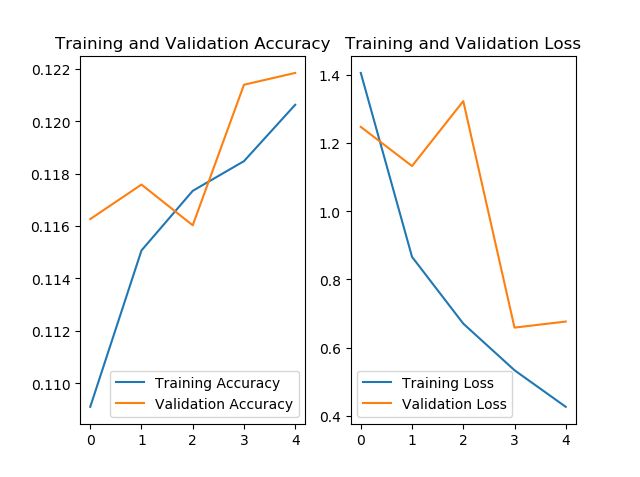
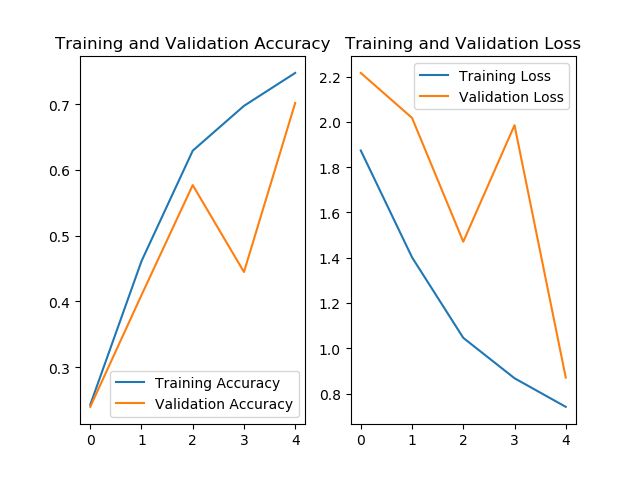
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
运行结果
ResNet
ResNet诞生于2015年,当年ImageNet竞赛冠军,Top5错误率为3.57%
网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果,从前面的网络可以看出网络越深而效果越好的一个实践证据。但是实验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。这个现象可以在下图中直观看出来:56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。

假设现在有一个浅层网络,想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。因此不得不承认肯定是目前的训练方法有问题,才使得深层网络很难去找到一个好的参数。
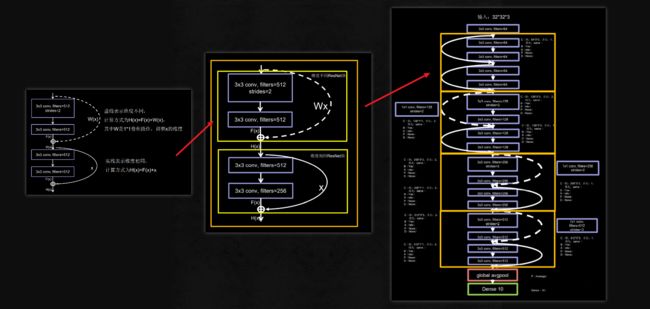
何凯明由此提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为\(x\)时其学习到的特征记为 \(H(x)\) ,现在我们希望其可以学习到残差 \(F(x) = H(x) - x\) ,这样其实原始的学习特征是 \(F(x) + x\) 。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图4所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。

ResNet18的网络结构
网络搭建示例
import tensorflow as tf
import numpy as np
import os
from tensorflow.keras.layers import Flatten, Conv2D, Dense, Activation, MaxPool2D, Dropout, BatchNormalization
from tensorflow.keras import Model
from matplotlib import pyplot as plt
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ResBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual)
return out
class ResNet(Model):
def __init__(self, block_list, initial_filters=64):
super(ResNet, self).__init__()
self.num_blocks = len(block_list)
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.Sequential()
for block_id in range(len(block_list)):
for layers_id in range(block_list[block_id]):
if block_list != 0 and layers_id == 0:
block = ResBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResBlock(self.out_filters, residual_path=False)
self.blocks.add(block)
self.out_filters *= 2
self.p1 = tf.keras.layers.AveragePooling2D()
self.f1 = Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
def Resnet18():
return ResNet([2, 2, 2, 2])
def Resnet34():
return ResNet([3, 4, 6, 3])
model = Resnet18()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = './checkpoint/ResNet18.ckpt'
if os.path.exists(checkpoint_save_path + '.index'):
print('--------------- load the model -----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
运行结果