干货!超实用的mysql学习基础知识笔记总结!
- 一、数据库的操作
1、创建数据库
create databases 数据库名 charater set utf8;
2、使用数据库
use 数据库名;
3、修改数据库用户密码
mysqladmin -u 用户名 -p password 新密码 执行后输入旧密码
4、查看表结构
desc student;
二、数据定义语言(DDL)
1、创建表
create table 表名(
字段1 数据类型(大小),
字段2 数据类型(大小),
字段3 数据类型(大小),
字段4 数据类型(大小),
primary key(字段名),
constrain 外键名 foreign key(表1字段) references 表2名(表2字段);
);
2、添加新的字段(列)结构
alter table 表名 add 字段名 数据类型(大小) default’默认值’;
3、修改字段(列)结构
alter table 表名 modify 字段名 数据类型(大小);
4、删除字段(列)结构
alter table 表名 drop 字段名 数据类型(大小);
5、修改字段名(列) 结构
alter table 表名 change 原始字段名 新的字段名 数据类型(大小);
6、修改表名字
rename table 原始表名 to 修改表名;
7、删除表
drop table 表名;
8、创建索引
alter table 表名 add index 索引名(字段名,排序方式/ASC/DESC)
9、添加主键
alter table 表名 add constraint primary key(字段名);
10、添加外键
alter table 表名 add constrain 外键名 foregin key(表1字段名)references 表2名(字段名);
注意括号!!
11、修改成自动增长
alter table 表名 modify 字段名 数据类型(可不写)auto_increment
12、删除约束
Alter table 表名 drop 约束名;
三、数据操作语言(DML)
1、添加表数据
insert into 表名(字段1、字段2、字段3) values(‘数据1’,‘数据2’,‘数据3’);
如果添加多条记录,可在 values(),后加一个逗号;
字符类型和日期类型的字段数据需要用单引号’’;
2、更新表数据
update 表名 set 表字段1=新数据1,表字段2=新数据2 where 更新条件;
3、删除表数据
delete from 表名 where 表字段=值;表结构仍在,表数据仍可找回
truncate table 表名;表结构仍在,表数据不可找回,效率快。
三、数据查询语言(DQL)
并不会改变表的数据,只会发送数据到客户端,查询出的表是虚拟结果集,存放在内存中
1、查询所有数据
select * from 表名 ;
2、条件查询
select 字段名1、字段名2、字段名3 from 表名 where 你想要的条件;
条件类型有:
=(等于),!=(不等于),<>(不等于),<(小于),<=(小于等于),>(大于),>=(大于等于)
between … and 在什么范围
in(set)值的范围
is null(为空) is not null (不为空)
and 与
or 或
not 非
3、模糊查询
select * from where name like ‘______’;查询有几个字符的
4、消除重复查询
select distinct 字段1 from 表名
5、排序
关键字为:order by 排序类型:ASC,DESC
6、聚合函数
count():统计指定列不为NULL的记录行数;
MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算
MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算
SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG():计算指定列的平均值,如果指定列类型学不是数值类型,那么计算结果为0;
7、分组
关键字 group by 字段名;
select sex from student group by sex;
8、group_concat()+group by
select sex,group_concat(name) from student group by sex;
9、group by + 聚合函数
select sex,group_concat(name),count() from student group by sex;
10、group by + having
where和having(用做筛选)的区别:
1、having是在分组后对数据进行过滤,where是在分组前对数据进行过滤
2、having后面可以使用分组函数(统计函数),where不可以
3、where的堆分组前记录的条件,如果某行记录没有满足where子句的条件,那么这行记录不会参与分组的;而having是对分组后数据的约束.
11、select书写逻辑和执行顺序
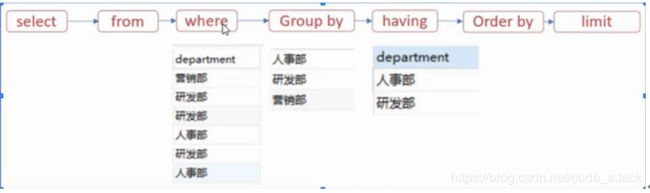
12、limit使用

四、数据的完整性
概念:保证数据输入到数据库中的正确性
如何添加数据的完整性:在创建表时给表添加的约束
完整性的分类:实体完整性、域完整性、引用完整性
1、 实体完整性
什么是实体完整性:表中的一行(每行记录)代表一个实体
实体完整性的作用:标识每一行数据不重复,行级约束
约束类型:主键约束(primary key),唯一约束(unique),自动增长列(auto_increment)
主键约束:特点,每个表中要有一个主键,数据唯一不能为null,还有一种是联合主键
添加方式:
1.1、create table(字段名1 数据类型 primary key,字段名2 数据类型);
1.2、create table(字段名1 数据类型,字段名2 数据类型,primary key(字段名1,字段名2))
联合主键就是用2个或2个以上的字段组成主键。用这个主键包含的字段作为主键,这个组合在数据表中是唯一,且加了主键索引。
可以这么理解,比如,你的订单表里有很多字段,一般情况只要有个订单号bill_no做主键就可以了,但是,现在要求可能会有补充订单,使用相同的订单号,那么这时单独使用订单号就不可以了,因为会有重复。那么你可以再使用个订单序列号bill_seq来作为区别。把bill_no和bill_seq设成联合主键。即使bill_no相同,bill_seq不同也是可以的。
1.3、Alter table 表名 add constraint primary key(字段名);
1.4、唯一约束:
概念:指定列的数据不能重复,但是可以为空值
创建方式:
Create table 表名(字段名1 数据类型 primary key,字段名2 数据类型 unique);
1.5、自动增长列:
特点:指定列的数据自动增长,即使数据被删除,还是会用删除的序号往下
创建方式:
1、 create table 表名(字段1 数据类型 primary key auto_increment,字段2 数据类型 unique);
2、 域完整性
概念:限制此单元格的数据是否正确,不对照此列的其它单元格比较,域代表当前单元格
3、 参照完整性
3.1概念:是指表与表之间的一种对应关系,通常情况下可以通过设置两表之间的主键、外键关系、或者编写两表的触发器来实现,有对应参照完整性的两张表格,在对他们进行数据的插入、更新、删除的过程中,系统都会将修改表格与另一张表格进行对照,从而阻止一些不正确的数据操作
3.2特性:
数据库的主键和外键类型一定要一致;
两个表的引擎必须得是InnoDB类型
设置参照完整性后,外键当中的内值,必须是主键当中的内容
一个表设置当中的字段设置为主键,设置主键的为主表
创建表时,设置外键,设置外键的为子表
五、多表查询
1、表之间的关系:

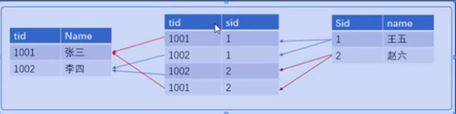
2、多表查询:
2.1、合并结果集

注意事项:被合并的两个结果,列数、列数据类型必须相同
2.2、连接查询
隐式连接-去除笛卡儿集 select * from 表1,表2 where 表1.字段1=表2.字段2
又称99查询法,
连接方式有:内连接,外连接,自然连接
2.2.1内连接:分有等值连接,非等值连接,自连接
等值连接:
关键字:inner join …. ON
例子:select * from 表1 INNER JOIN 表2 ON 表1.字段1=表2.字段2
(与多表联查约束主外键是一样的,只是写法改变了,可以省略inner)
2.2.2、外连接
2.2.2.1、左连接:
关键字:left join … on
含义:两表满足条件相同的数据查出来,如果左边表当中有不相同的数据,也把左边表当中的数据查出来,右边表当中只查出满足条件的内容。
例子:select * from 表1 left join 表2 on 表1.字段1=表2.字段2;
2.2.2.2.2、右连接:
关键字:right join …on
含义:表满足条件相同的数据查出来,如果右边表当中有不相同的数据,也把右边表当中的数据查出来,左边表当中只查出满足条件的内容。
例子:select * from 表1 right join 表2 on 表1.字段1=表2.字段2;
2.2.2.3、多表查询1
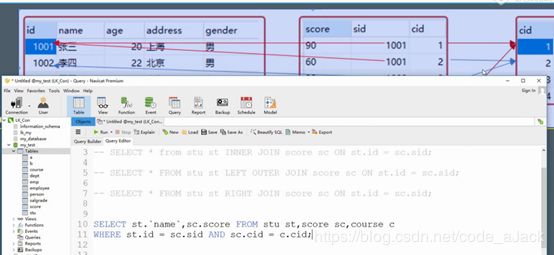
也可以使用内连接
Select * from 表 1
Join 表2 on 表1.字段1=表2.字段1
Join 表3 on 表1.字段1=表3.字段1
2.2.2.4、多表查询2
2.2.3、自然连接
2.3、子查询
2.4、自连接
六、权限操作

6.1、创建用户:
命令:create user ‘用户名’@’主机’ identified by ‘密码’;
Grant 权限(如select、insert)
On 表名
To ‘用户名’@’主机’
With grant option;
Flush privileges(刷新权限,可写可不写);
6.2、删除用户
命令: drop user ‘用户名’@’主机’;
6.3、查看权限
Show grants
7、视图



视图的创建:
语法:Creatae view 视图名
As
Select * from 表名;
视图数据的修改:
Create or replace view 视图名 as select * from….;
视图的删除:
Drop view 视图名;
8、存储过程
8.1
什么是存储过程:
一组可编程的函数,是为了完成特定功能的SQL语句集
存储过程就是有名字的一段代码,用来完成一个特定功能
8.2存储过程的好处

8.3存储过程的创建
Delimiter 代码的作用是修改命令的解释符,比如 delimiter $ 就把;修改成$了
代码创建存储过程:
Delimiter C r e a t e p r o c e d u r e 存 储 过 程 名 字 B e g i n S e l e c t ∗ f r o m e m p ; / / 存 储 过 程 的 功 能 E n d Create procedure 存储过程名字 Begin Select * from emp; //存储过程的功能 End Createprocedure存储过程名字BeginSelect∗fromemp;//存储过程的功能End
8.4调用存储过程:
Call 存储过程名;
8.5查看存储过程:

8.6删除存储过程:
Drop procedure 存储过程名字;
8.7存储过程声明变量:
声明一个变量:Declare 变量名 数据类型(大小) default’默认值’;
声明多个变量:Declare 变量名1,变量名2 数据类型(大小) default’默认值’;
8.8给存储过程的变量分配值
1、Set 变量名=’值’;
2、select avg(salary) into 变量名 from emp; 把查询语句结果的值赋给变量
8.9存储过程参数
有三种类型 in、out、inout
定义:
Delimiter C r e a t e p r o c e d u r e g e t n a m e ( i n n a m e v a r c h a r ( 230 ) ) B e g i n S e l e c t ∗ f r o m e m p w h e r e e n a m e = n a m e ; E n d Create procedure getname(in name varchar(230)) Begin Select * from emp where ename=name; End Createproceduregetname(innamevarchar(230))BeginSelect∗fromempwhereename=name;End
调用:Call getname(‘李白’);
8.10自定义函数 End while; 调用: Select 函数名(参数); 9、索引 创建索引: 删除索引: 10、常用函数 函数介绍: 函数分类:字符串函数、数值函数、日期和时间函数、流程函数、其他函数 字符串函数: 流程函数: 11、事务 12、子查询
定义:
Delimiter $$
Create function 函数名 (n int ) returns varchar(255)
Begin
Declare 变量名 数据类型(大小)
Declare 变量名 数据类型(大小)
While i
End $$
什么是索引?

索引的优势和劣势

索引的分类

索引的操作
Create index 索引名 on 表名(字段1,字段2);
Alter table 表名 add index 索引名(字段1);
Drop index索引名on 表名;


1、事先提供好的一些功能可以直接使用
2、函数可以用在SELECT语句及其子句
3、也可以用在Update,Delete 语句中
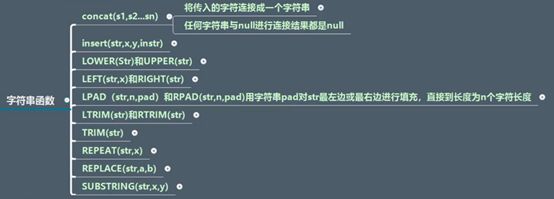
数值函数:

日期和时间函数:
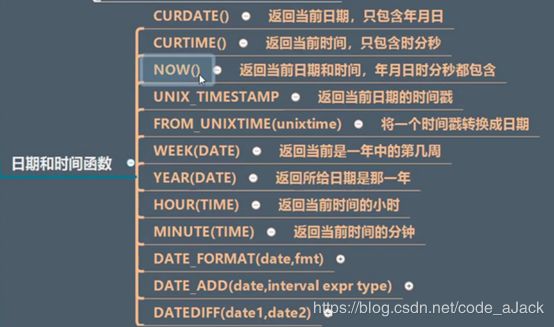

常用函数:
概念:




