经典再读 | NASNet:神经架构搜索网络在图像分类中的表现

(图片付费下载于视觉中国)
作者 | Sik-Ho Tsang
译者 | Rachel
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】从 AutoML 到 NAS,都是企业和开发者的热门关注技术,以往我们也分享了很多相关内容。而这篇文章将对 Google Brain 发布的 NASNet 进行介绍。NASNet 在 CVPR2018 发表,至今已经有超过400次引用。
在神经架构搜索中,作者在较小的数据集上对神经网络架构的模块进行搜索,之后将该网络结构迁移到一个更大的数据集上。在 NASNet 中,作者首先对 CIFAR-10 中最佳的卷积层或神经元进行搜索,之后通过将该神经元复制多次并连接在一起以应用在 ImageNet 数据集上。该研究还提出了“ScheduledDropPath” 这一新的正则化技术,该方法有效地改善了 NASNet 的生成效果。相较于以往的神经网络架构,NASNet 生成的神经网络模型更简洁,运算复杂度更低(以每秒浮点运算次数衡量)。
1、神经元上的神经架构搜索(Neural Architecture Search, NAS)
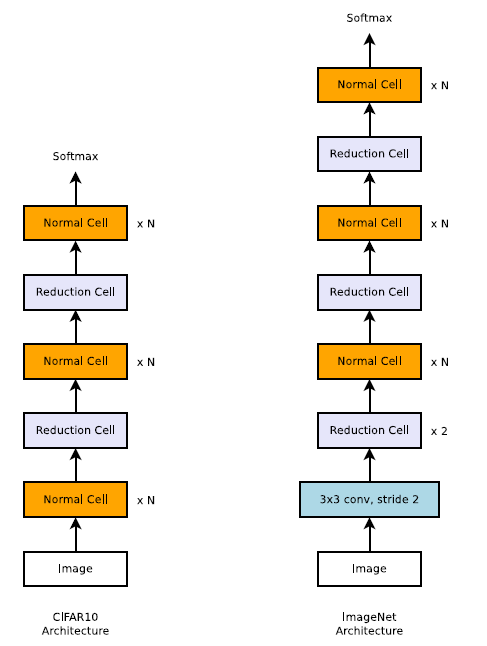
可缩放的 CIFAR10 和 ImageNet 模型架构
如上图所示, NASNet 仅对模型的整体结构进行了设置,具体的模块或神经元并未预定义,其定义是通过强化学习搜索方法完成的。例如,序列重复的次数 N 和初始的卷积核形状都是自由参数,用于模型的缩放。
网络中的神经元分为普通神经元(normal cell)和下采样神经元(reduction cell)两种:
-
普通神经元:返回维度相同的特征映射的卷积层
-
下采样神经元:返回的特征映射的维度的高和宽均除以2
在 NASNet 中,仅对上述两种神经元的结构或内部特征进行搜索,搜索过程使用一个 RNN 控制器进行控制。
2、控制器模型架构(Controller Model Architecture)
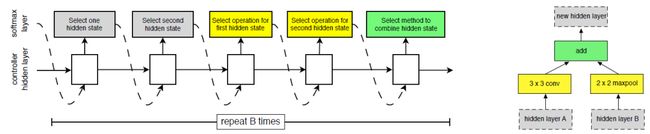
使用控制器模型架构迭代搭建由卷积神经元组成的模块
在 NASNet 中,由 RNN 构成的控制器通过使用两个初始的隐藏状态,迭代地对余下的卷积神经元的结构进行预测,具体步骤如下:
-
步骤1: 从 hi, hi-1 或之前创建的模块的隐藏状态中选择一个隐藏状态
-
步骤2: 重复步骤1,再选择一个隐藏状态
-
步骤3: 为步骤1中选择的隐藏状态选择一个运算方式;
-
步骤4: 为步骤2中选择的隐藏状态选择一个运算方式;
-
步骤5: 选择一个运算以结合步骤3和步骤4的输出,并作为一个新的隐藏状态
其中,步骤3和步骤4可选的运算包括:

上述运算仅针对一个模块。
在该部分使用的 RNN 控制器为一个包含100个隐藏神经元的单层 LSTM 网络,在每一次预测中,该网络包含 2*5B 个对于两类卷积神经元的 softmax 预测,一般取 B=5 。
RNN 控制器产生的 10B 个预测都分别对应一个概率。一个子网络(child network)的联合概率是这10B个softmax单元的概率乘积。RNN控制器使用这一联合概率计算梯度。
作者使用子网络的验证准确度对RNN控制器的梯度进行调整和更新,使得RNN控制器给效果较好的子网络赋予较高的概率,给效果较差的子网络赋予较低的概率。
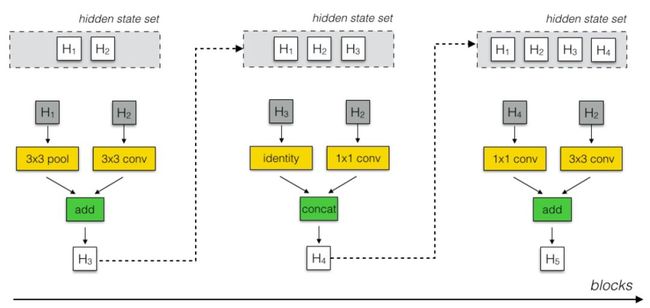
NASNet 搜索空间缩略图
网络的主要结构通过多次迭代模块(block)生成,如上图所示。模块包含三个操作:控制器选择一对隐藏状态(深灰色部分),对隐藏状态的操作(黄色部分)以及一个结合操作(绿色部分)。从模块中得到的隐藏状态被存入可能的隐藏状态的集合中,用于后续的迭代过程。
总而言之,在该部分中,NASNet通过使用RNN控制器尝试找到一个最佳的操作组合来得到一个效果较好的神经元,以替代传统的手工调参方法。
3、NASNet-A, NASNet-B 和 NASNet-C
对神经网络结构的搜索使用了500个GPU,共持续了4天,运行了2000个GPU时长,最终得到了多个候选的卷积神经元,最终形成了三种不同结构的普通神经元和下采样神经元,包括NASNet-A, NASNet-B和NASNet-C。
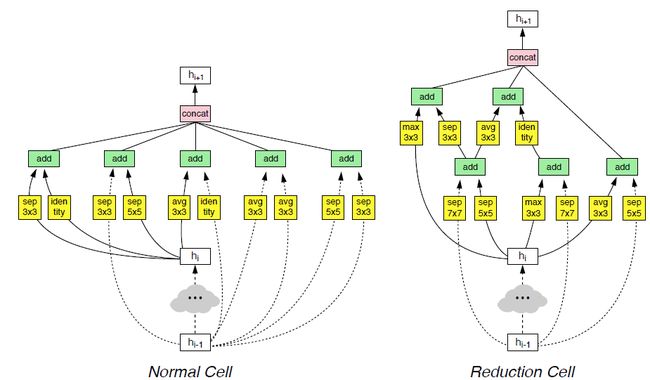
NASNer-A
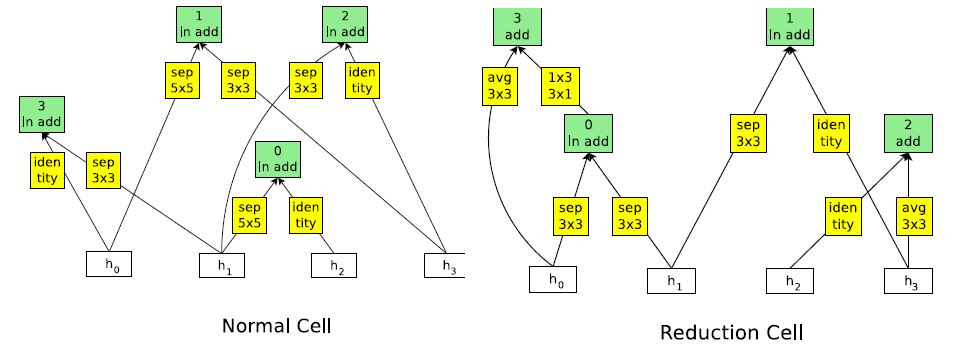
NASNet-B(包含4个输入和4个输出)
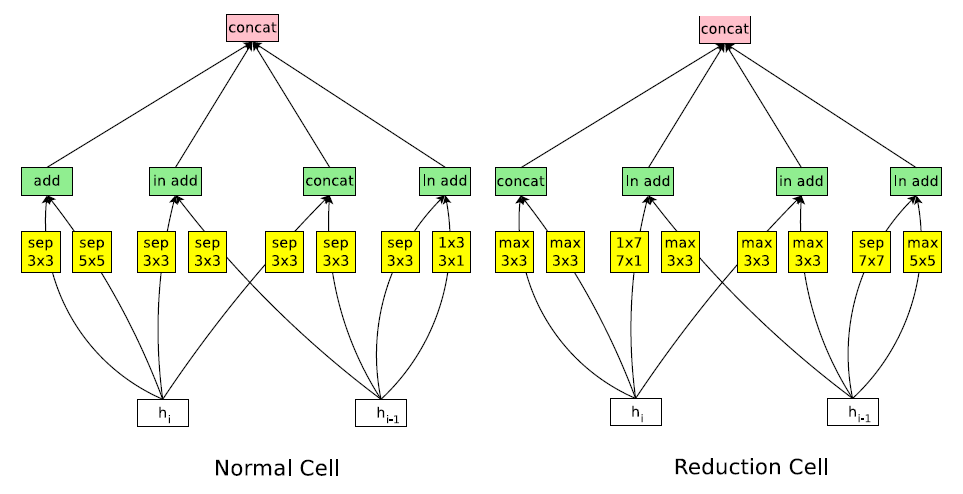
NASNet-C
4、实验结果
4.1 ScheduledDropPath
在训练过程中,作者使用了 ScheduledDropPath 这一正则化方法。在该方法中,神经元的每个路径都依据一个线性增长的值进行dropout。该方法显著提升了训练的准确率。
4.2 CIFAR-10
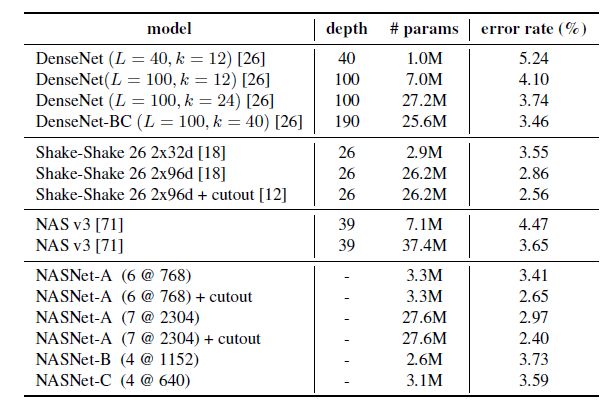
CIFAR-10
使用截断(cutout)的数据增强方法的 NASNet-A(7@2304) 模型将错误率降低至 2.4%,超越了包括 DenseNet 和 Shake-Shake 在内的现有模型。其中,7代表 N=7,表示神经元的重复次数,2304代表网络的倒数第二层使用的卷积层的数量。
4.3 ImageNet
作者将 CIFAR-10 的模型结构迁移到了 ImageNet, 但对网络的权重重新进行了训练。
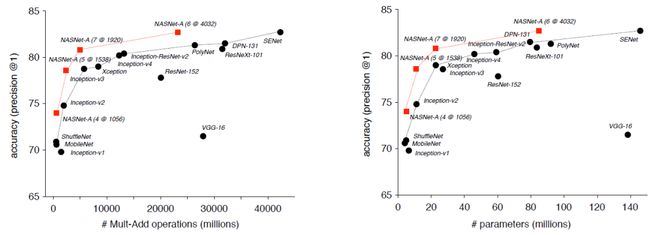
准确率与计算量(左图)和参数数量(右图)的对比
在模型效果相近时,相较于其他的模型, NASNet 使用了更少的浮点计算和参数。另外,在 CIFAR-10 中得到的卷积神经元在 ImageNet 上展现了很好的泛化能力。
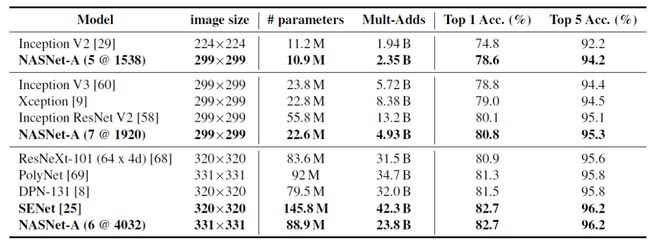
从上表可以发现,规模最大的模型在 ImageNet 上的的准确率达到了 82.7% ,比在此之前表现最佳的模型 DPN 高出1.2%,与未公开的研究中的模型相比较, NASNet和 SENet达到了相同的准确率。
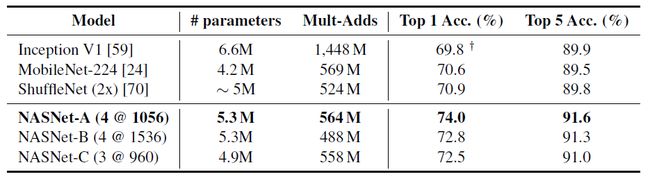
在限制计算设置的情形下 NASNet 和其他模型的对比
从上表可以看到, NASNet 在模型规模相似或具有更小网络的情形下获得了比已有模型更好的表现,包括 Inception-v1, MobileNetV1 和 ShuffleNetV1。
4.4 MS COCO Object Detection
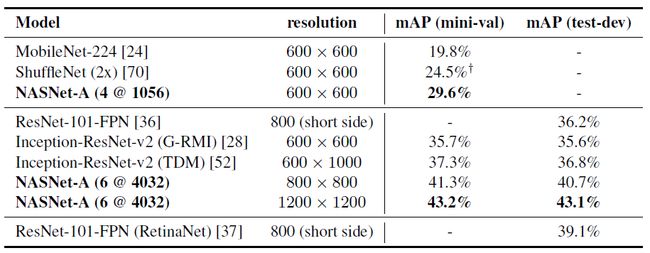
mAP 在 COCO mini-val 数据集和 test-dev 数据集上的表现
NASNet 得到的图片结果展示



通过使用 Faster R-cnn, NASNet-A 的效果超越了 MobileNetV1, ShuffleNet V1, ResNet 和 Inception-ResNet-v2。
原文链接:
https://medium.com/@sh.tsang/review-nasnet-neural-architecture-search-network-image-classification-23139ea0425d
(*本文为AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
倒计时!由易观携手CSDN联合主办的第三届易观算法大赛还剩 7 天,冠军团队将获得3万元!
本次比赛主要预测访问平台的相关事件的PV,UV流量(包括Web端,移动端等),大赛将会提供相应事件的流量数据,以及对应时间段内的所有事件明细表和用户属性表等数据,进行模型训练,并用训练好的模型预测规定日期范围内的事件流量。

推荐阅读
知乎算法团队负责人孙付伟:Graph Embedding在知乎的应用实践
必看,61篇NeurIPS深度强化学习论文解读都这里了
打破深度学习局限,强化学习、深度森林或是企业AI决策技术的“良药”
激光雷达,马斯克看不上,却又无可替代?
卷积神经网络中十大拍案叫绝的操作
Docker是啥?容器变革的火花?
5大必知的图算法,附Python代码实现
阿里云弹性计算负责人蒋林泉:亿级场景驱动的技术自研之路
40 岁身体死亡,11 年后成“硅谷霍金”,他用一块屏幕改变 100 万人
AI大神如何用区块链解决模型训练痛点, AI+区块链的正确玩法原来是这样…… | 人物志

你点的每个“在看”,我都认真当成了喜欢