android初中级面试必备
1. Activity
# Activity的四大启动模式,以及应用场景?
Activity的四大启动模式:
-
standard:标准模式,每次都会在活动栈中生成一个新的Activity实例。通常我们使用的活动都是标准模式。
-
singleTop:栈顶复用,如果Activity实例已经存在栈顶,那么就不会在活动栈中创建新的实例。比较常见的场景就是给通知跳转的Activity设置,因为你肯定不想前台Activity已经是该Activity的情况下,点击通知,又给你再创建一个同样的Activity。
-
singleTask:栈内复用,如果Activity实例在当前栈中已经存在,就会将当前Activity实例上面的其他Activity实例都移除栈。常见于跳转到主界面。
-
singleInstance:单实例模式,创建一个新的任务栈,这个活动实例独自处在这个活动栈中。
2. 屏幕适配
# 平时如何有使用屏幕适配吗?原理是什么呢?
平时的屏幕适配一般采用的头条的屏幕适配方案。简单来说,以屏幕的一边作为适配,通常是宽。
原理:设备像素px和设备独立像素dp之间的关系
px = dp * density
假设UI给的设计图屏幕宽度基于360dp,那么设备宽的像素点已知,即px,dp也已知,360dp,所以density = px / dp,之后根据这个修改系统中跟density相关的知识点即可。
3. Android消息机制
# Android消息机制介绍?
Android消息机制中的四大概念:
-
ThreadLocal:当前线程存储的数据仅能从当前线程取出。
-
MessageQueue:具有时间优先级的消息队列。
-
Looper:轮询消息队列,看是否有新的消息到来。
-
Handler:具体处理逻辑的地方。
过程:
-
准备工作:创建Handler,如果是在子线程中创建,还需要调用Looper#prepare(),在Handler的构造函数中,会绑定其中的Looper和MessageQueue。
-
发送消息:创建消息,使用Handler发送。
-
进入MessageQueue:因为Handler中绑定着消息队列,所以Message很自然的被放进消息队列。
-
Looper轮询消息队列:Looper是一个死循环,一直观察有没有新的消息到来,之后从Message取出绑定的Handler,最后调用Handler中的处理逻辑,这一切都发生在Looper循环的线程,这也是Handler能够在指定线程处理任务的原因。
# Looper在主线程中死循环为什么没有导致界面的卡死?
-
导致卡死的是在Ui线程中执行耗时操作导致界面出现掉帧,甚至ANR,Looper.loop()这个操作本身不会导致这个情况。
-
有人可能会说,我在点击事件中设置死循环会导致界面卡死,同样都是死循环,不都一样的吗?Looper会在没有消息的时候阻塞当前线程,释放CPU资源,等到有消息到来的时候,再唤醒主线程。
-
App进程中是需要死循环的,如果循环结束的话,App进程就结束了。
建议阅读:
《Android中为什么主线程不会因为Looper.loop()里的死循环卡死?》
https://www.zhihu.com/question/34652589
# IdleHandler介绍?
介绍:
IdleHandler是在Hanlder空闲时处理空闲任务的一种机制。
执行场景:
-
MessageQueue没有消息,队列为空的时候。
-
MessageQueue属于延迟消息,当前没有消息执行的时候。
会不会发生死循环:
答案是否定的,MessageQueue使用计数的方法保证一次调用MessageQueue#next方法只会使用一次的IdleHandler集合。
4. View事件分发机制和View绘制原理
刚哥的《Android开发艺术探索》已经很全面了,建议阅读。
5. Bitmap
# Bitmap的内存计算方式?
在已知图片的长和宽的像素的情况下,影响内存大小的因素会有资源文件位置和像素点大小。
像素点大小:
常见的像素点有:
-
ARGB_8888:4个字节
-
ARGB_4444、ARGB_565:2个字节
资源文件位置:
不同dpi对应存放的文件夹

比如一个一张图片的像素为180*180px,dpi(设备独立像素密度)为320,如果它仅仅存放在drawable-hdpi,则有:
横向像素点 = 180 * 320/240 + 0.5f = 240 px
纵向像素点 = 180 * 320/240 + 0.5f = 240 px
如果它仅仅存放在drawable-xxhdpi,则有:
横向像素点 = 180 * 320/480 + 0.5f = 120 px
纵向像素点 = 180 * 320/480 + 0.5f = 120 px
所以,对于一张180*180px的图片,设备dpi为320,资源图片仅仅存在drawable-hdpi,像素点大小为ARGB_4444,最后生成的文件内存大小为:
横向像素点 = 180 * 320/240 + 0.5f = 240 px
纵向像素点 = 180 * 320/240 + 0.5f = 240 px
内存大小 = 240 * 240 * 2 = 115200byte 约等于 112.5kb
建议阅读:
《Android Bitmap的内存大小是如何计算的?》
https://ivonhoe.github.io/2017/03/22/Bitmap&Memory/
# Bitmap的高效加载?
Bitmap的高效加载在Glide中也用到了,思路:
-
获取需要的长和宽,一般获取控件的长和宽。
-
设置BitmapFactory.Options中的inJustDecodeBounds为true,可以帮助我们在不加载进内存的方式获得Bitmap的长和宽。
-
对需要的长和宽和Bitmap的长和宽进行对比,从而获得压缩比例,放入BitmapFactory.Options中的inSampleSize属性。
-
设置BitmapFactory.Options中的inJustDecodeBounds为false,将图片加载进内存,进而设置到控件中。
2
Android进阶
Android进阶中重点考察Android Framework、性能优化和第三方框架。
1. Binder
# Binder的介绍?与其他IPC方式的优缺点?
Binder是Android中特有的IPC方式,引用《Android开发艺术探索》中的话(略有改动):
从IPC角度来说,Binder是Android中的一种跨进程通信方式;Binder还可以理解为虚拟的物理设备,它的设备驱动是/dev/binder;从Android Framework来讲,Binder是Service Manager连接各种Manager和对应的ManagerService的桥梁。从面向对象和CS模型来讲,Client通过Binder和远程的Server进行通讯。
基于Binder,Android还实现了其他的IPC方式,比如AIDL、Messenger和ContentProvider。
与其他IPC比较:
-
效率高:除了内存共享外,其他IPC都需要进行两次数据拷贝,而因为Binder使用内存映射的关系,仅需要一次数据拷贝。
-
安全性好:接收方可以从数据包中获取发送发的进程Id和用户Id,方便验证发送方的身份,其他IPC想要实验只能够主动存入,但是这有可能在发送的过程中被修改。
# Binder的通信过程?Binder的原理?
图片:

其实这个过程也可以从AIDL生成的代码中看出。
原理:
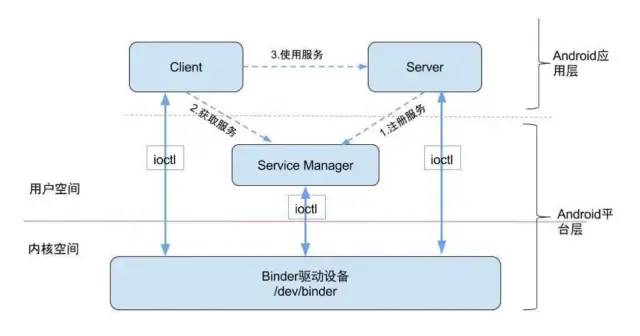
Binder的结构:
-
Client:服务的请求方。
-
Server:服务的提供方。
-
Service Manager:为Server提供Binder的注册服务,为Client提供Binder的查询服务,Server、Client和Service Manager的通讯都是通过Binder。
-
Binder驱动:负责Binder通信机制的建立,提供一系列底层支持。
从上图中,Binder通信的过程是这样的:
-
Server在Service Manager中注册:Server进程在创建的时候,也会创建对应的Binder实体,如果要提供服务给Client,就必须为Binder实体注册一个名字。
-
Client通过Service Manager获取服务:Client知道服务中Binder实体的名字后,通过名字从Service Manager获取Binder实体的引用。
-
Client使用服务与Server进行通信:Client通过调用Binder实体与Server进行通信。
更详细一点?
Binder通信的实质是利用内存映射,将用户进程的内存地址和内核的内存地址映射为同一块物理地址,也就是说他们使用的同一块物理空间,每次创建Binder的时候大概分配128的空间。数据进行传输的时候,从这个内存空间分配一点,用完了再释放即可。
2. 序列化
# Android有哪些序列化方式?
为了解决Android中内存序列化速度过慢的问题,Android使用了Parcelable。
| 对比 | Serializable | Parcelable |
|---|---|---|
| 易用性 | 简单 | 不是很简单 |
| 效率 | 低 | 高 |
| 场景 | IO、网络和数据库 | 内存中 |
3. Framework
Zygote孕育进程过程?

# Activity的启动过程?

建议阅读:
《3分钟看懂Activity启动流程》
https://www.jianshu.com/p/9ecea420eb52
# App的启动过程?
介绍一下App进程和System Server进程如何联系:

App进程
-
ActivityThread:依赖于Ui线程,实际处理与AMS中交互的工作。
-
ActivityManagerService:负责Activity、Service等的生命周期工作。
-
ApplicationThread:System Server进程中ApplicatonThreadProxy的服务端,帮助System Server进程跟App进程交流。
-
System Server:Android核心的进程,掌管着Android系统中各种重要的服务。

具体过程:
-
用户点击App图标,Lanuacher进程通过Binder联系到System Server进程发起startActivity。
-
System Server通过Socket联系到Zygote,fork出一个新的App进程。
-
创建出一个新的App进程以后,Zygote启动App进程的ActivityThread#main()方法。
-
在ActivtiyThread中,调用AMS进行ApplicationThread的绑定。
-
AMS发送创建Application的消息给ApplicationThread,进而转交给ActivityThread中的H,它是一个Handler,接着进行Application的创建工作。
-
AMS以同样的方式创建Activity,接着就是大家熟悉的创建Activity的工作了。
# Apk的安装过程?
建议阅读:
《Android Apk安装过程分析》
https://www.jianshu.com/p/953475cea991
# Activity启动过程跟Window的关系?
建议阅读:
《简析Window、Activity、DecorView以及ViewRoot之间的错综关系》
https://juejin.im/post/5dac6aa2518825630e5d17da
# Activity、Window、ViewRoot和DecorView之间的关系?
建议阅读:
《总结UI原理和高级的UI优化方式》
https://www.jianshu.com/p/8766babc40e0
4. Context
# 关于Context的理解?
建议阅读:
《Android Context 上下文 你必须知道的一切》
https://blog.csdn.net/lmj623565791/article/details/40481055
5. 断点续传
# 多线程断点续传?
基础知识:
-
Http基础:在Http请求中,可以加入请求头Range,下载指定区间的文件数。
-
RandomAccessFile:支持随机访问,可以从指定位置进行数据的读写。
有了这个基础以后,思路就清晰了:
-
通过HttpUrlConnection获取文件长度。
-
自己分配好线程进行制定区间的文件数据的下载。
-
获取到数据流以后,使用RandomAccessFile进行指定位置的读写。
6. 性能优化
# 平时做了哪些性能优化?
建议阅读:
《Android 性能优化最佳实践》
https://juejin.im/post/5b50b017f265da0f7b2f649c
7. 第三方库
一定要在熟练使用后再去查看原理。
# Glide
Glide考察的频率挺高的,常见的问题有:
-
Glide和其他图片加载框架的比较?
-
如何设计一个图片加载框架?
-
Glide缓存实现机制?
-
Glide如何处理生命周期?
-
...
建议阅读:
《Glide最全解析》
https://blog.csdn.net/sinyu890807/category_9268670.html
《面试官:简历上最好不要写Glide,不是问源码那么简单》
https://juejin.im/post/5dbeda27e51d452a161e00c8
# OkHttp
OkHttp常见知识点:
-
责任链模式
-
interceptors和networkInterceptors的区别?
建议看一遍源码,过程并不复杂。
# Retrofit
Retrofit常见问题:
-
设计模式和封层解耦的理念
-
动态代理
建议看一遍源码,过程并不复杂。
# RxJava
RxJava难在各种操作符,我们了解一下大致的设计思想即可。
建议寻找一些RxJava的文章。
# Android Jetpack(非必须)
我主要阅读了Android Jetpack中以下库的源码:
-
Lifecycle:观察者模式,组件生命周期中发送事件。
-
DataBinding:核心就是利用LiveData或者Observablexxx实现的观察者模式,对16进制的状态位更新,之后根据这个状态位去更新对应的内容。
-
LiveData:观察者模式,事件的生产消费模型。
-
ViewModel:借用Activty异常销毁时存储隐藏Fragment的机制存储ViewModel,保证数据的生命周期尽可能的延长。
-
Paging:设计思想。
以后有时间再给大家做源码分析。
建议阅读:
《Android Jetpack源码分析系列》
https://blog.csdn.net/mq2553299/column/info/24151
3
Java基础
Java基础中考察频率比较高的是Object、String、面向对象、集合、泛型和反射。
1. Object
# equals和==的区别?equals和hashcode的关系?
-
==:基本类型比较值,引用类型比较地址。
-
equals:默认情况下,equals作为对象中的方法,比较的是地址,不过可以根据业务,修改equals方法。
equals和hashcode之间的关系:
默认情况下,equals相等,hashcode必相等,hashcode相等,equals不是必相等。hashcode基于内存地址计算得出,可能会相等,虽然几率微乎其微。
2. String
# String、StringBuffer和StringBuilder的区别?
-
String:String属于不可变对象,每次修改都会生成新的对象。
-
StringBuilder:可变对象,非多线程安全。
-
StringBuffer:可变对象,多线程安全。
大部分情况下,效率是:StringBuilder>StringBuffer>String。
3. 面向对象的特性
# Java中抽象类和接口的特点?
共同点:
-
抽象类和接口都不能生成具体的实例。
-
都是作为上层使用。
不同点:
-
抽象类可以有属性和成员方法,接口不可以。
-
一个类只能继承一个类,但是可以实现多个接口。
-
抽象类中的变量是普通变量,接口中的变量是静态变量。
-
抽象类表达的是is-a的关系,接口表达的是like-a的关系。
# 关于多态的理解?
多态是面向对象的三大特性:继承、封装和多态之一。
多态的定义:允许不同类对同一消息做出响应。
多态存在的条件:
-
要有继承。
-
要有复写。
-
父类引用指向子类对象。
Java中多态的实现方式:接口实现,继承父类进行方法重写,同一个类中的方法重载。
4. 集合
# HashMap的特点是什么?HashMap的原理?
-
HashMap的特点:
-
基于Map接口,存放键值对。
-
允许key/value为空。
-
非多线程安全。
-
不保证有序,也不保证使用的过程中顺序不会改变。
简单来讲,核心是数组+链表/红黑树,HashMap的原理就是存键值对的时候:
-
通过键的Hash值确定数组的位置。
-
找到以后,如果该位置无节点,直接存放。
-
该位置有节点即位置发生冲突,遍历该节点以及后续的节点,比较key值,相等则覆盖。
-
没有就新增节点,默认使用链表,相连节点数超过8的时候,在jdk 1.8中会变成红黑树。
-
如果Hashmap中的数组使用情况超过一定比例,就会扩容,默认扩容两倍。
当然这是存入的过程,其他过程可以自行查阅。这里需要注意的是:
-
key的hash值计算过程是高16位不变,低16位和高16位取抑或,让更多位参与进来,可以有效的减少碰撞的发生。
-
初始数组容量为16,默认不超过的比例为0.75。
5. 泛型
# 说一下对泛型的理解?
泛型的本质是参数化类型,在不创建新的类型的情况下,通过泛型指定不同的类型来控制形参具体限制的类型。也就是说在泛型的使用中,操作的数据类型被指定为一个参数,这种参数可以被用在类、接口和方法中,分别被称为泛型类、泛型接口和泛型方法。
泛型是Java中的一种语法糖,能够在代码编写的时候起到类型检测的作用,但是虚拟机是不支持这些语法的。
泛型的优点:
-
类型安全,避免类型的强转。
-
提高了代码的可读性,不必要等到运行的时候才去强制转换。
# 什么是类型擦除?
不管泛型的类型传入哪一种类型实参,对于Java来说,都会被当成同一类处理,在内存中也只占用一块空间。通俗一点来说,就是泛型只作用于代码编译阶段,在编译过程中,对于正确检验泛型结果后,会将泛型的信息擦除,也就是说,成功编译过后的class文件是不包含任何泛型信息的。
6. 反射
# 动态代理和静态代理
静态代理很简单,运用的就是代理模式:
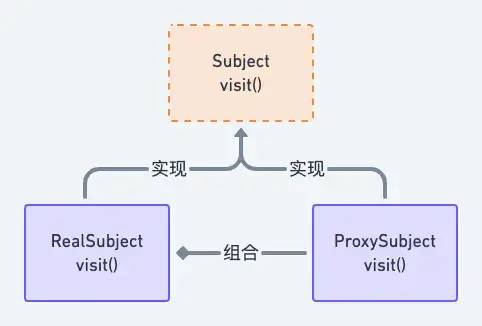
声明一个接口,再分别实现一个真实的主题类和代理主题类,通过让代理类持有真实主题类,从而控制用户对真实主题的访问。
动态代理指的是在运行时动态生成代理类,即代理类的字节码在运行时生成并载入当前的ClassLoader。
动态代理的原理是使用反射,思路和上面的一致。
使用动态代理的好处:
-
不需要为RealSubject写一个形式完全一样的代理类。
-
使用一些动态代理的方法可以在运行时制定代理类的逻辑,从而提升系统的灵活性。
4
Java并发
Java并发中考察频率较高的有线程、线程池、锁、线程间的等待和唤醒、线程特性和阻塞队列等。
1. 线程
# 线程的状态有哪些?
附上一张状态转换的图:

# 线程中wait和sleep的区别?
wait方法既释放cpu,又释放锁。
sleep方法只释放cpu,但是不释放锁。
# 线程和进程的区别?
线程是CPU调度的最小单位,一个进程中可以包含多个线程,在Android中,一个进程通常是一个App,App中会有一个主线程,主线程可以用来操作界面元素,如果有耗时的操作,必须开启子线程执行,不然会出现ANR,除此以外,进程间的数据是独立的,线程间的数据可以共享。
2. 线程池
线程池的地位十分重要,基本上涉及到跨线程的框架都使用到了线程池,比如说OkHttp、RxJava、LiveData以及协程等。
# 与新建一个线程相比,线程池的特点?
-
节省开销:线程池中的线程可以重复利用。
-
速度快:任务来了就能开始,省去创建线程的时间。
-
线程可控:线程数量可空和任务可控。
-
功能强大:可以定时和重复执行任务。
# 线程池中的几个参数是什么意思,线程池的种类有哪些?
线程池的构造函数如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
参数解释如下:
-
corePoolSize:核心线程数量,不会释放。
-
maximumPoolSize:允许使用的最大线程池数量,非核心线程数量,闲置时会释放。
-
keepAliveTime:闲置线程允许的最大闲置时间。
-
unit:闲置时间的单位。
-
workQueue:阻塞队列,不同的阻塞队列有不同的特性。
线程池分为四个类型:
-
CachedThreadPool:闲置线程超时会释放,没有闲置线程的情况下,每次都会创建新的线程。
-
FixedThreadPool:线程池只能存放指定数量的线程池,线程不会释放,可重复利用。
-
SingleThreadExecutor:单线程的线程池。
-
ScheduledThreadPool:可定时和重复执行的线程池。
# 线程池的工作流程?

图片来自《线程池是怎样工作的》
https://www.jianshu.com/p/9de89960ec01
简而言之:
-
任务来了,优先考虑核心线程。
-
核心线程满了,进入阻塞队列。
-
阻塞队列满了,考虑非核心线程(图上好像少了这个过程)。
-
非核心线程满了,再触发拒绝任务。
3. 锁
# 死锁触发的四大条件?
-
互斥锁
-
请求与保持
-
不可剥夺
-
循环的请求与等待
# synchronized关键字的使用?synchronized的参数放入对象和Class有什么区别?
synchronized关键字的用法:
-
修饰方法
-
修饰代码块:需要自己提供锁对象,锁对象包括对象本身、对象的Class和其他对象。
放入对象和Class的区别是:
-
锁住的对象不同:成员方法锁住的实例对象,静态方法锁住的是Class。
-
访问控制不同:如果锁住的是实例,只会针对同一个对象方法进行同步访问,多线程访问同一个对象的synchronized代码块是串行的,访问不同对象是并行的。如果锁住的是类,多线程访问的不管是同一对象还是不同对象的synchronized代码块是都是串行的。
# synchronized的原理?
任何一个对象都有一个monitor与之相关联,JVM基于进入和退出mointor对象来实现代码块同步和方法同步,两者实现细节不同:
-
代码块同步:在编译字节码的时候,代码块起始的地方插入monitorenter
指令,异常和代码块结束处插入monitorexit指令,线程在执行monitorenter指令的时候尝试获取monitor对象的所有权,获取不到的情况下就是阻塞 -
方法同步:synchronized方法在method_info结构有AAC_synchronized标记,线程在执行的时候获取对应的锁,从而实现同步方法
# synchronized和Lock的区别?
主要区别:
-
synchronized是Java中的关键字,是Java的内置实现;Lock是Java中的接口。
-
synchronized遇到异常会释放锁;Lock需要在发生异常的时候调用成员方法Lock#unlock()方法。
-
synchronized是不可以中断的,Lock可中断。
-
synchronized不能去尝试获得锁,没有获得锁就会被阻塞;Lock可以去尝试获得锁,如果未获得可以尝试处理其他逻辑。
-
synchronized多线程效率不如Lock,不过Java在1.6以后已经对synchronized进行大量的优化,所以性能上来讲,其实差不了多少。
# 悲观锁和乐观锁的举例?以及它们的相关实现?
悲观锁和乐观锁的概念:
-
悲观锁:悲观锁会认为,修改共享数据的时候其他线程也会修改数据,因此只在不会受到其他线程干扰的情况下执行。这样会导致其他有需要锁的线程挂起,等到持有锁的线程释放锁
-
乐观锁:每次不加锁,每次直接修改共享数据假设其他线程不会修改,如果发生冲突就直接重试,直到成功为止
举例:
-
悲观锁:典型的悲观锁是独占锁,有synchronized、ReentrantLock。
-
乐观锁:典型的乐观锁是CAS,实现CAS的atomic为代表的一系列类
# CAS是什么?底层原理?
CAS全称Compare And Set,核心的三个元素是:内存位置、预期原值和新值,执行CAS的时候,会将内存位置的值与预期原值进行比较,如果一致,就将原值更新为新值,否则就不更新。
底层原理:是借助CPU底层指令cmpxchg实现原子操作。
4. 线程间通信
# notify和notifyAll方法的区别?
notify随机唤醒一个线程,notifyAll唤醒所有等待的线程,让他们竞争锁。
# wait/notify和Condition类实现的等待通知有什么区别?
synchronized与wait/notify结合的等待通知只有一个条件,而Condition类可以实现多个条件等待。
5. 多线程间的特性
# 多线程间的有序性、可见性和原子性是什么意思?
-
原子性:执行一个或者多个操作的时候,要么全部执行,要么都不执行,并且中间过程中不会被打断。Java中的原子性可以通过独占锁和CAS去保证
-
可见性:指多线程访问同一个变量的时候,一个线程修改了变量的值,其他线程能够立刻看得到修改的值。锁和volatile能够保证可见性
-
有序性:程序执行的顺序按照代码先后的顺序执行。锁和volatile能够保证有序性
# happens-before原则有哪些?
Java内存模型具有一些先天的有序性,它通常叫做happens-before原则。
如果两个操作的先后顺序不能通过happens-before原则推倒出来,那就不能保证它们的先后执行顺序,虚拟机就可以随意打乱执行指令。happens-before原则有:
-
程序次序规则:单线程程序的执行结果得和看上去代码执行的结果要一致。
-
锁定规则:一个锁的lock操作一定发生在上一个unlock操作之后。
-
volatile规则:对volatile变量的写操作一定先行于后面对这个变量的对操作。
-
传递规则:A发生在B前面,B发生在C前面,那么A一定发生在C前面。
-
线程启动规则:线程的start方法先行发生于线程中的每个动作。
-
线程中断规则:对线程的interrupt操作先行发生于中断线程的检测代码。
-
线程终结原则:线程中所有的操作都先行发生于线程的终止检测。
-
对象终止原则:一个对象的初始化先行发生于他的finalize()方法的执行。
前四条规则比较重要。
# volatile的原理?
可见性
如果对声明了volatile的变量进行写操作的时候,JVM会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写入到系统内存。
多处理器的环境下,其他处理器的缓存还是旧的,为了保证各个处理器一致,会通过嗅探在总线上传播的数据来检测自己的数据是否过期,如果过期,会强制重新将系统内存的数据读取到处理器缓存。
有序性
Lock前缀的指令相当于一个内存栅栏,它确保指令排序的时候,不会把后面的指令拍到内存栅栏的前面,也不会把前面的指令排到内存栅栏的后面。
6. 阻塞队列
# 通常的阻塞队列有哪几种,特点是什么?
-
ArrayBlockQueue:基于数组实现的有界的FIFO(先进先出)阻塞队列。
-
LinkedBlockQueue:基于链表实现的无界的FIFO(先进先出)阻塞队列。
-
SynchronousQueue:内部没有任何缓存的阻塞队列。
-
PriorityBlockingQueue:具有优先级的无限阻塞队列。
# ConcurrentHashMap的原理
数据结构的实现跟HashMap一样,不做介绍。
JDK 1.8之前采用的是分段锁,核心类是一个Segment,Segment继承了ReentrantLock,每个Segment对象管理若干个桶,多个线程访问同一个元素的时候只能去竞争获取锁。
JDK 1.8采用了CAS + synchronized,插入键值对的时候如果当前桶中没有Node节点,使用CAS方式进行更新,如果有Node节点,则使用synchronized的方式进行更新。