训练tesseract
tesseract识别率,通过样本数量提升,呈对数型增长,所以根据你的验证码的复杂程度来确定你的训练样本数量
因为本身tesseract的识别精度很低,所以很有必要进行训练
验证码:是由背景图片和字符图片复合而成,训练的时候我们要告诉每个验证码样本里,字符的位置(上下左右四个参数)和字符的值
定位元素的位置:
下载工具jTessBoxEditor. http://sourceforge.net/projects/vietocr/files/jTessBoxEditor/,这个工具是用来训练样本用的,由于该工具是用Java开发的,需要安装JAVA虚拟机才能运行。
1.采集样本,通过python图片循环抓取写入,写入的时候把图片命名为 .tif 结尾
def data_sear():
if not os.path.exists('samples'):
os.makedirs('samples')
for i in range(1,351):
result = urllib2.urlopen("http://。。。。网址。。。").read()
file1 = open('samples/result%d.tif'%i,'wb')
file1.write(result)
file1.close()
2.合并 tif(为了方便通过软件产生每个元素的位置)
打开jtessboxeditor,点击Tools->Merge Tiff ,按住shift键选择前文提到的101个tif文件,并把生成的tif合并到新目录下,命名为langyp.fontyp.exp0.tif。
注意:langyp 是本人定义的语言名称,fontyp是本人定义的字体名称,后续都会用到,你可以修改成你喜欢的名字。
遇到warning没有关系
3.生成box文件(每个元素的位置)
执行命令生成langyp.fontyp.exp0.box文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 batch.nochop makebox
4,软件识别的错误很多,我们要自己处理box文件
切换到jTessBoxEditor工具的Box Editor页,点击open,打开前面的tiff文件langyp.fontyp.exp0.tif,工具会自动加载对应的box文件。
检查box数据,如下图所示,数字8被误认成字母H,手工修改H成8,并保存。
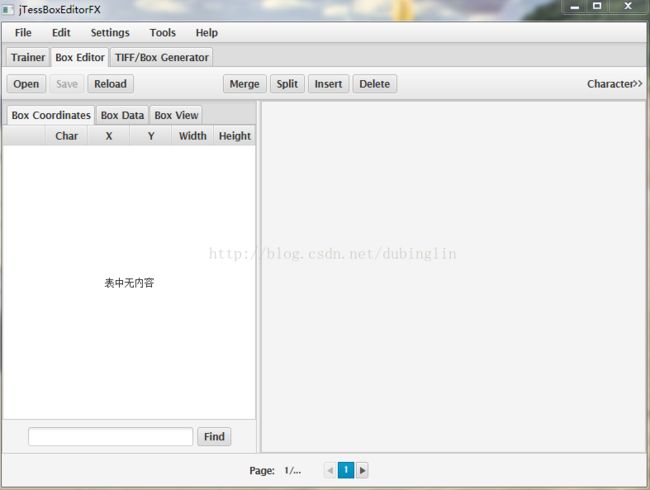
注意:修改:选中要修改的元素,点击右上角character》》后面的》》,会出现参数,在这里面修改,通过上下左右可以连续增减参数
下面的page,每个page就是你的每个验证码,你验证码的数量和page不一样,是应为一些识别不了的空白,这个软件略过了
记得要及时点击上面的save按钮,保存
5.生成font_properties(告诉tesseract,你的box语法)
执行echo命令生成font_properties。
echo fontyp 0 0 0 0 0 >font_properties
也可以手工新建一个名为font_properties的文本文件(注意该文件没有扩展名),内容为字体名fontyp,后面带5个0,分别代表字体的粗体、斜体等属性,这里全部是0
6.生成训练文件执行命令,生成langyp.fontyp.exp0.tr训练文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 nobatch box.train
7.生成字符集执行命令,生成名为unicharset的字符集文件。
unicharset_extractor langyp.fontyp.exp0.box
8.生成shape文件
执行命令,生成shape文件
shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
9.生成聚集字符特征文件
执行命令,生成3个特征字符文件,unicharset、inttemp、pffmtable
mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
10.生成字符正常化文件
执行命令,生成正常化特征文件normproto。
cntraining langyp.fontyp.exp0.tr
11.更名
执行命令,把步骤9,步骤10生成的特征文件进行更名。
rename normproto fontyp.normproto
rename inttemp fontyp.inttemp
rename pffmtable fontyp.pffmtable
rename unicharset fontyp.unicharset
rename shapetable fontyp.shapetable
执行命令,生成fontyp.traineddata文件。
combine_tessdata fontyp.
注意:
a、fontyp.traineddata文件最终要拷贝tesseract安装目录的tessdata目录下,才能被tesseract找到。
b、命令行最后必须带一个点。