Hadoop2.2.0 HA高可用分布式集群搭建(hbase,hive,sqoop,spark)
1 需要软件
Hadoop-2.2.0
Hbase-0.96.2(这里就用这个版本,跟Hadoop-2.2.0是配套的,不用覆盖jar包什么的)
Hive-0.13.1
Zookeepr-3.4.6(建议使用Zookeepr-3.4.5,这样就不用替换storm和hive里面的zookeepr-3.4.5.jar了)
Sqoop1.4.5
Scala-2.10.4
Spark-1.0.2-bin-hadoop2
Jdk1.7.0_51
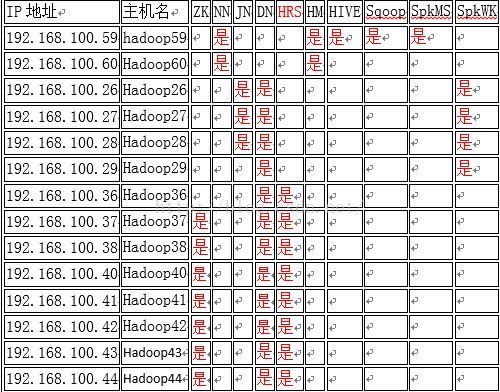
2 集群结构图
NN : NameNode
JN : JournalNode
DN : DataNode
ZK : ZooKeeper
HM:HMster
HRS:HregionServer
SpkMS:Spark Master
SpkWK:Spark worker
3 Zookeeper-3.4.6
添加环境变量
##set zookeepr enviroment
export ZOOKEEPER_HOME=/home/cloud/zookeeper346
export PATH=$PATH:$ZOOKEEPER_HOME/bin
3.1 zoo.cfg 配置文件的修改
cloud@hadoop37:~/zookeeper346/conf> ls
configuration.xsl log4j.properties zookeeper.out zoo_sample.cfg
cloud@hadoop37:~/zookeeper346/conf> cpzoo_sample.cfg zoo.cfg
cloud@hadoop37:~/zookeeper346/conf> vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/cloud/zookeeper346/zkdata
dataLogDir=/home/cloud/zookeeper346/logs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop37:2888:3888
server.2=hadoop38:2888:3888
server.3=hadoop40:2888:3888
server.4=hadoop41:2888:3888
server.5=hadoop42:2888:3888
server.6=hadoop43:2888:3888
server.7=hadoop44:2888:3888
3.2 dataDir目录下创建 myid文件
cloud@hadoop37:~/zookeeper346/zkdata> vi myid
cloud@hadoop37:~/zookeeper346/zkdata> ll
total 12
-rw-r--r-- 1 cloud hadoop 2May 28 18:54 myid
cloud@hadoop37:~/zookeeper346/zkdata>
3.3 复制(SCP)到其它的服务器下去
cloud@hadoop37:~ > scp -r/home/cloud/zookeeper346 cloud@hadoop38:~/
cloud@hadoop37:~ > scp -r/home/cloud/zookeeper346 cloud@hadoop40:~/
cloud@hadoop37:~ > scp -r/home/cloud/zookeeper346 cloud@hadoop41:~/
cloud@hadoop37:~ > scp -r/home/cloud/zookeeper346 cloud@hadoop42:~/
cloud@hadoop37:~ > scp -r/home/cloud/zookeeper346 cloud@hadoop43:~/
cloud@hadoop37:~ > scp -r/home/cloud/zookeeper346 cloud@hadoop44:~/
然后只要修改…data/myid文件成对应的id就好了
hadoop37中写入 1,
hadoop38中写入 2,
以此类推 …
4 Hadoop-2.2.0
添加环境变量
##set hadoop enviroment
export HADOOP_HOME=/home/cloud/hadoop220
export YARN_HOME=/home/cloud/hadoop220
export HADOOP_MAPARED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_PREFIX=${HADOOP_HOME}
exportHADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
exportHADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
export PATH=$PATH:$HADOOP_HOME/bin
4.1 修改7个配置文件
~/hadoop220/etc/hadoop/hadoop-env.sh
~/ hadoop220/etc/hadoop/core-site.xml
~/ hadoop220/etc/hadoop/hdfs-site.xml
~/ hadoop220/etc/hadoop/mapred-site.xml
~/ hadoop220/etc/hadoop/yarn-env.sh
~/ hadoop220/etc/hadoop/yarn-site.xml
~/ hadoop220/etc/hadoop/slaves
4.1.1修改hadoop-env.sh配置文件(jdk 路径)
cloud@hadoop59:~/hadoop220/etc/hadoop> pwd
/home/cloud/hadoop220/etc/hadoop
[root@masterhadoop]# vi hadoop-env.sh
…
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running adistributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.7.0_51
4.1.2修改core-site.xml文件修改 (注意fs.defaultFS的配置)
cloud@hadoop59:~/hadoop220/etc/hadoop> vi core-site.xml
4.1.3修改hdfs-site.xml配置文件
cloud@hadoop59:~/hadoop220/etc/hadoop> vihdfs-site.xml
###这里暂时只用了data1~data3,后面如果需要填加data盘的话,只需###要修改配置文件,并且重启集群即可。
4.1.4修改 mapred-site.xml配置文件
cloud@hadoop59:~/hadoop220/etc/hadoop> cpmapred-site.xml.template mapred-site.xml
cloud@hadoop59:~/hadoop220/etc/hadoop> vi mapred-site.xml
4.1.5修改yarn-env.sh配置文件
cloud@hadoop59:~/hadoop220/etc/hadoop> viyarn-env.sh
# some Java parameters
export JAVA_HOME=/usr/java/jdk1.7.0_51
4.1.6修改yarn-site.xml配置文件
cloud@hadoop59:~/hadoop220/etc/hadoop> viyarn-site.xml
4.1.7修改slaves配置文件
cloud@hadoop59:~/hadoop220/etc/hadoop> vislaves
hadoop26
hadoop27
hadoop28
hadoop29
hadoop36
hadoop37
hadoop38
hadoop40
hadoop41
hadoop42
hadoop43
hadoop44
5 Hadoop配置结束,开始启动各个程序(笔记只保留重要日志信息)
5.1 在每个节点上启动Zookeeper
cloud@hadoop37:~/zookeeper346> pwd
/home/cloud/zookeeper346
cloud@hadoop37:~/zookeeper346>bin/zkServer.sh start
JMX enabled by default
Using config: /home/cloud/zookeeper346/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
其它服务器也这样启动,这里就不写了…
# 验证Zookeeper是否启动成功1
在hadoop41上查看zookeeper的状态发现是leader
cloud@hadoop41:~> zkServer.sh status
JMX enabled by default
Using config: /home/cloud/zookeeper346/bin/../conf/zoo.cfg
Mode: leader
cloud@hadoop41:~>
在其他的机器上查看zookeeper的状态发现是follower
#验证Zookeeper是否启动成功2
cloud@hadoop41:~> zookeeper346/bin/zkCli.sh
Connecting to localhost:2181
2015-06-01 15:50:50,888 [myid:] - INFO [main:Environment@100] - Clientenvironment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT
2015-06-01 15:50:50,895 [myid:] - INFO [main:Environment@100] - Clientenvironment:host.name=hadoop41
2015-06-01 15:50:50,895 [myid:] - INFO [main:Environment@100] - Clientenvironment:java.version=1.7.0_51
2015-06-01 15:50:50,900 [myid:] - INFO [main:Environment@100] - Clientenvironment:java.vendor=Oracle Corporation
2015-06-01 15:50:50,900 [myid:] - INFO [main:Environment@100] - Clientenvironment:java.home=/usr/java/jdk1.7.0_51/jre
2015-06-01 15:50:50,900 [myid:] - INFO [main:Environment@100] - Clientenvironment:java.class.path=/home/cloud/zookeeper346/bin/../build/classes:/home/cloud/zookeeper346/bin/../build/lib/*.jar:/home/cloud/zookeeper346/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/cloud/zookeeper346/bin/../lib/slf4j-api-1.6.1.jar:/home/cloud/zookeeper346/bin/../lib/netty-3.7.0.Final.jar:/home/cloud/zookeeper346/bin/../lib/log4j-1.2.16.jar:/home/cloud/zookeeper346/bin/../lib/jline-0.9.94.jar:/home/cloud/zookeeper346/bin/../zookeeper-3.4.6.jar:/home/cloud/zookeeper346/bin/../src/java/lib/*.jar:/home/cloud/zookeeper346/bin/../conf::/usr/java/jdk1.7.0_51/lib:/usr/java/jdk1.7.0_51/jre/lib
2015-06-01 15:50:50,901 [myid:] - INFO [main:Environment@100] - Clientenvironment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2015-06-01 15:50:50,901 [myid:] - INFO [main:Environment@100] - Clientenvironment:java.io.tmpdir=/tmp
2015-06-01 15:50:50,901 [myid:] - INFO [main:Environment@100] - Clientenvironment:java.compiler=
2015-06-01 15:50:50,901 [myid:] - INFO [main:Environment@100] - Clientenvironment:os.name=Linux
2015-06-01 15:50:50,902 [myid:] - INFO [main:Environment@100] - Clientenvironment:os.arch=amd64
2015-06-01 15:50:50,902 [myid:] - INFO [main:Environment@100] - Clientenvironment:os.version=3.0.13-0.27-default
2015-06-01 15:50:50,902 [myid:] - INFO [main:Environment@100] - Clientenvironment:user.name=cloud
2015-06-01 15:50:50,902 [myid:] - INFO [main:Environment@100] - Clientenvironment:user.home=/home/cloud
2015-06-01 15:50:50,903 [myid:] - INFO [main:Environment@100] - Clientenvironment:user.dir=/home/cloud
2015-06-01 15:50:50,906 [myid:] - INFO [main:ZooKeeper@438] - Initiating clientconnection, connectString=localhost:2181 sessionTimeout=30000watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@75e5d16d
Welcome to ZooKeeper!
2015-06-01 15:50:50,959 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@975]- Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will notattempt to authenticate using SASL (unknown error)
2015-06-01 15:50:50,969 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socketconnection established to localhost/0:0:0:0:0:0:0:1:2181, initiating session
JLine support is enabled
2015-06-01 15:50:51,009 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Sessionestablishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid =0x44d9d846f630001, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 2]
出现这样的提示的话,那么zookeeper就启动成功了
5.2 在hadoop59上格式化Zookeeper(这里一定要在namenode配置的机器上执行,否则会报错,是一个bug)
Bug详情见https://issues.apache.org/jira/browse/HDFS-6731
cloud@hadoop59:~/hadoop220/bin >hdfs zkfc-formatZK
/cloud/hadoop220/contrib/capacity-scheduler/*.jar
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/home/cloud/hadoop220/lib/native
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:java.io.tmpdir=/tmp
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:java.compiler=
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:os.name=Linux
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:os.arch=amd64
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:os.version=3.0.76-0.11-default
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:user.name=cloud
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:user.home=/home/cloud
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Clientenvironment:user.dir=/home/cloud/hadoop220/bin
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Initiating clientconnection,connectString=hadoop37:2181,hadoop38:2181,hadoop40:2181,hadoop41:2181,hadoop42:2181,hadoop43:2181,hadoop44:2181sessionTimeout=5000watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@58d48756
15/06/01 09:42:20 INFO zookeeper.ClientCnxn: Opening socketconnection to server hadoop37/192.168.100.37:2181. Will not attempt toauthenticate using SASL (unknown error)
15/06/01 09:42:20 INFO zookeeper.ClientCnxn: Socket connectionestablished to hadoop37/192.168.100.37:2181, initiating session
15/06/01 09:42:20 INFO zookeeper.ClientCnxn: Session establishmentcomplete on server hadoop37/192.168.100.37:2181, sessionid = 0x14d9d846f810001,negotiated timeout = 5000
15/06/01 09:42:20 INFO ha.ActiveStandbyElector: Session connected.
15/06/01 09:42:20 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
15/06/01 09:42:20 INFO zookeeper.ZooKeeper: Session:0x14d9d846f810001 closed
15/06/01 09:42:20 INFO zookeeper.ClientCnxn: EventThread shut down
5.3 验证zkfc是否格式化成功
cloud@hadoop59:~/hadoop220/bin > pwd
/home/cloud/hadoop220/bin
cloud@hadoop41:~> zookeeper346/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, zookeeper]
[zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha
[mycluster]
可以看到使用ls命令后多了一个hadoop-ha,这样就成功了
5.4 完全分布式启动Hadoop(切记顺序不能乱)
5.4.1 在hadoop26,hadoop27,hadoop28 上分别启动 journalnode
# 启动hadoop26的journalNode
cloud@ hadoop26:~/hadoop220/sbin >hadoop-daemon.sh startjournalnode
cloud@ hadoop26:~/hadoop220/logs > tail –n 100 hadoop-cloud-journalnode-hadoop26.log(查看日志是否报错,不报错你就赢了一半了)
# 同样在hadoop27,hadoop28上启动journalNode
cloud@hadoop26:~ > jps
37213 Jps
34646 JournalNode
5.4.2 在hadoop59,hadoop60上分别格式化和启动namenode
从hadoop59和hadoop60中任选一个即可,这里选择的是hadoop59
# 格式化跟启动hadoop59上的namenode
cloud@hadoop59:~/hadoop220/sbin> ../bin/hdfsnamenode –format
。。。。
15/06/01 10:41:35 INFO namenode.FSNamesystem:dfs.namenode.safemode.min.datanodes = 0
15/06/01 10:41:35 INFO namenode.FSNamesystem:dfs.namenode.safemode.extension =30000
15/06/01 10:41:35 INFO namenode.FSNamesystem: Retry cache onnamenode is enabled
15/06/01 10:41:35 INFO namenode.FSNamesystem: Retry cache will use0.03 of total heap and retry cache entry expiry time is 600000 millis
15/06/01 10:41:35 INFO util.GSet: Computing capacity for mapNamenode Retry Cache
15/06/01 10:41:35 INFO util.GSet: VM type = 64-bit
15/06/01 10:41:35 INFO util.GSet: 0.029999999329447746% max memory =958.5 MB
15/06/01 10:41:35 INFO util.GSet: capacity = 2^15 = 32768 entries
15/06/01 10:41:36 INFO common.Storage: Storage directory /home/cloud/hadoop220/dfs/name has been successfullyformatted.
15/06/01 10:41:36 INFO namenode.FSImage: Saving image file/home/cloud/hadoop220/dfs/name/current/fsimage.ckpt_0000000000000000000 usingno compression
15/06/01 10:41:36 INFO namenode.FSImage: Image file/home/cloud/hadoop220/dfs/name/current/fsimage.ckpt_0000000000000000000 of size197 bytes saved in 0 seconds.
15/06/01 10:41:36 INFO namenode.NNStorageRetentionManager: Going toretain 1 images with txid >= 0
15/06/01 10:41:36 INFO util.ExitUtil: Exiting with status 0
15/06/01 10:41:36 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop59/192.168.100.59
************************************************************/
cloud@hadoop59:~/hadoop220/sbin>./hadoop-daemon.sh start namenode
cloud@hadoop60:~/hadoop220/sbin> ../bin/hdfsnamenode -bootstrapStandby
************************************************************/
15/06/01 10:45:15 INFO namenode.NameNode: registered UNIX signalhandlers for [TERM, HUP, INT]
15/06/01 10:45:16 WARN util.NativeCodeLoader: Unable to loadnative-hadoop library for your platform... using builtin-java classes whereapplicable
=====================================================
About to bootstrap Standby ID hadoop60 from:
Nameservice ID:mycluster
Other Namenode ID:hadoop59
Other NN's HTTP address:hadoop59:50070
Other NN's IPC address: hadoop59/192.168.100.59:8020
Namespace ID:1044230165
Block pool ID:BP-492642856-192.168.100.59-1433126496003
Cluster ID:CID-35daa6f0-5104-4081-9e64-e25999bc6b7e
Layout version: -47
=====================================================
15/06/01 10:45:17 INFO common.Storage: Storagedirectory /home/cloud/hadoop220/dfs/name has been successfully formatted.
15/06/01 10:45:17 INFO namenode.TransferFsImage: Opening connectionto http://hadoop59:50070/getimage?getimage=1&txid=0&storageInfo=-47:1044230165:0:CID-35daa6f0-5104-4081-9e64-e25999bc6b7e
15/06/01 10:45:17 INFO namenode.TransferFsImage: Transfer took 0.17sat 0.00 KB/s
15/06/01 10:45:17 INFO namenode.TransferFsImage: Downloaded filefsimage.ckpt_0000000000000000000 size 197 bytes.
15/06/01 10:45:17 INFO util.ExitUtil: Exiting with status 0
15/06/01 10:45:17 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop60/127.0.0.1
************************************************************/
cloud@hadoop60:~/hadoop220/sbin> ./hadoop-daemon.shstart namenode
5.5 打开浏览器,访问hadoop59和hadoop60的50070端口
这时候hadoop59和hadoop60机器的namenode都是standby的状态。
如果都能访问到,说明你namenode启动成功了。
5.6 namenode(hadoop59)转换成active(这里不需要手动将namenode转换为active状态了,因为我们是交给Zookeeper管理,在后面会启动ZooKeeperFailoverController)
5.7 启动所有的 datanodes
cloud@hadoop26:~/hadoop220/sbin> hadoop-daemons.shstart datanode
(查看日志,没报错你就赢了,其他节点类似,其实也可以直接在namenode上执行start-dfs.sh命令,这个命令会同时启动namenode,journanode,datanode,zkfc进程)
cloud@hadoop44:~> jps
3963 DataNode
29926 QuorumPeerMain
4340 NodeManager
5869 Jps
cloud@hadoop44:~>
5.8 实验一下手动切换namenode的状态(这里也不需要做,Zookeeper管理的,自动切换,下面会讲到)
5.9 yarn启动
cloud@hadoop59:~/hadoop220/sbin> start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-resourcemanager-hadoop59.out
hadoop40: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop40.out
hadoop26: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop26.out
hadoop38: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop38.out
hadoop43: starting nodemanager, logging to /home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop43.out
hadoop41: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop41.out
hadoop42: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop42.out
hadoop27: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop27.out
hadoop28: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop28.out
hadoop44: starting nodemanager, logging to /home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop44.out
hadoop36: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop36.out
hadoop37: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop37.out
hadoop29: starting nodemanager, logging to/home/cloud/hadoop220/logs/yarn-cloud-nodemanager-hadoop29.out
5.9.1 访问hadoop59的8088端口查看ResourceManager的UI界面
5.10 启动ZooKeeperFailoverController(在hadoop59,hadoop60上执行命令)
5.10.1在rs229上执行命令
cloud@hadoop59:~/hadoop220/sbin>hadoop-daemon.sh start zkfc
starting zkfc, logging to starting zkfc, logging to/home/cloud/hadoop220/logs/hadoop-cloud-zkfc-hadoop59.out
cloud@hadoop59:~/hadoop220/sbin> tail -n 50 /home/cloud/hadoop220/logs/hadoop-cloud-zkfc-hadoop59.log
(前面省略)
2015-06-01 15:02:56,213 INFOorg.apache.hadoop.ha.ZKFailoverController: Local service NameNode at hadoop59/192.168.100.59:8020entered state: SERVICE_HEALTHY
2015-06-01 15:02:56,260 INFO org.apache.hadoop.ha.ActiveStandbyElector:Checking for any old active which needs to be fenced...
2015-06-01 15:02:56,287 INFOorg.apache.hadoop.ha.ActiveStandbyElector: No old node to fence
2015-06-01 15:02:56,287 INFOorg.apache.hadoop.ha.ActiveStandbyElector: Writing znode/hadoop-ha/mycluster/ActiveBreadCrumb to indicate that the local node is themost recent active...
2015-06-01 15:02:56,300 INFOorg.apache.hadoop.ha.ZKFailoverController: Trying to make NameNode at hadoop59/192.168.100.59:8020active...
2015-06-01 15:02:56,838 INFOorg.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNodeat hadoop59/192.168.100.59:8020 to active state
cloud@hadoop59:~/hadoop220/sbin> jps
24037 NameNode
25168 DataNode
26012 NodeManager
25891 ResourceManager
23343 JournalNode
27026 DFSZKFailoverController
29367 QuorumPeerMain
27208 Jps
5.10.2在hadoop60上执行命令
cloud@hadoop59:~/hadoop220/sbin> hadoop-daemon.sh start zkfc
starting zkfc, logging to /home/cloud/hadoop220/logs/hadoop-root-zkfc-hadoop60.out
cloud@hadoop59:~/hadoop220/sbin> tail –n 100/home/cloud/hadoop220/logs/hadoop-root-zkfc-hadoop60.log
cloud@hadoop60:~> jps
11910 NameNode
83673 Jps
13562 DFSZKFailoverController
cloud@hadoop60:~>
5.11 查看namenode的状态
cloud@hadoop59:~/hadoop220/sbin> hdfs haadmin-DFSHAAdmin -getServiceState hadoop59
15/06/01 16:15:59 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
active
cloud@hadoop59:~/hadoop220/sbin>
cloud@hadoop60:~> hdfs haadmin -DFSHAAdmin-getServiceState hadoop60
15/06/01 16:16:31 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
standby
cloud@hadoop60:~>
发现hadoop59变成active状态了,而hadoop60还是standby状态
5.12 验证HDFS是否好用
cloud@hadoop59:~/hadoop220/sbin> hadoop fs -mkdir /test
cloud@hadoop59:~/hadoop220/sbin> hadoop fs -ls /
Found 1 items
drwxr-xr-x - cloudsupergroup 0 2015-06-01 15:16/test
5.13 验证YARN是否好用
cloud@hadoop59:~/hadoop220/sbin> pwd
/home/cloud/hadoop220/sbin
cloud@hadoop59:~/hadoop220/bin>./hadoopjar../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 10 100
…(不重要的部分就省略了,能出这个值就是对的,虚拟机可能会卡着不动,也可能会卡死,属于正常现象,内存消耗比较大)
Job Finished in 25.361 seconds
valueof Pi is 3.14800000000000000000
5.14 验证HA高可用性,是否自动故障转移
5.14.1 查看hadoop59和hadoop60的namenode状态
cloud@hadoop59:~/hadoop220/sbin> hdfs haadmin-DFSHAAdmin -getServiceState hadoop59
15/06/01 16:15:59 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
active
cloud@hadoop59:~/hadoop220/sbin>
cloud@hadoop60:~> hdfs haadmin -DFSHAAdmin-getServiceState hadoop60
15/06/01 16:16:31 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
standby
cloud@hadoop60:~>
发现hadoop59从为active状态,而hadoop60为standby状态
在hadoop59上直接kill掉namenode进程
cloud@hadoop59:~> jps
5419 NameNode
7026 ResourceManager
11262 DFSZKFailoverController
30503 Jps
cloud@hadoop59:~> kill -9 5419
cloud@hadoop59:~> jps
7026 ResourceManager
31384 Jps
11262 DFSZKFailoverController
进程已经被kill掉了
5.14.2 在hadoop60机器上查看是否namenode变成了active状态
cloud@hadoop60:~> hdfs haadmin -DFSHAAdmin -getServiceStatehadoop60
15/06/01 15:23:27 WARN util.NativeCodeLoader: Unable to loadnative-hadoop library for your platform... using builtin-java classes whereapplicable
active
cloud@hadoop60:~>
发现hadoop59无法访问,而hadoop60 从standby转换成active状态,成功了
重新启动hadoop59的namenode,发现编程了standby状态了
cloud@hadoop59:~> hadoop220/sbin/hadoop-daemon.sh start namenode
starting namenode, logging to/home/cloud/hadoop220/logs/hadoop-cloud-namenode-hadoop59.out
cloud@hadoop59:~> hdfs haadmin -DFSHAAdmin -getServiceStatehadoop59
15/06/01 15:25:49 WARN util.NativeCodeLoader: Unable to loadnative-hadoop library for your platform... using builtin-java classes whereapplicable
standby
cloud@hadoop59:~> jps
7026 ResourceManager
11262 DFSZKFailoverController
33679 NameNode
34820 Jps
cloud@hadoop59:~>
6 Hbase-0.96.2-hadoop2(启动双HMaster的配置,hadoop59是主HMaster,hadoop60是从HMaster)
6.1 解压,添加环境变量
cloud@hadoop59:~> tar –zxvf hbase-0.96.2-hadoop2-bin.tar.gz
cloud@hadoop59:~> ll
总用量 171532
drwxr-xr-x 2 cloudhadoop 4096 5月 28 10:46 bin
drwxr-xr-x 12 cloud hadoop 4096 6月 1 10:43 hadoop220
-rw-r--r-- 1 cloud hadoop96070556 5月 2817:43 hadoop-2.2.0.tar.gz
drwxr-xr-x 7 cloudhadoop 4096 6月 2 09:57 hbase-0.96.2-hadoop2
-rw-r--r-- 1 cloud hadoop79367504 6月 2 09:56 hbase-0.96.2-hadoop2-bin.tar.gz
drwxr-xr-x 2 cloudhadoop 4096 5月 28 17:16 id_rsa
-rwxr-xr-x 1 cloudhadoop 145 6月 1 17:18 scpfile.sh
-rwxr-xr-x 1 cloudhadoop 134 5月 29 15:16scphadoop.sh
-rwxr-xr-x 1 cloudhadoop 166 5月 29 14:48testssh.sh
cloud@hadoop59:~ > sudo vi /etc/profile
##set hbase enviroment
export HBASE_HOME=/home/cloud/hbase0962
export PATH=$PATH:$HBASE_HOME/bin
6.2 修改hbase-env.sh 文件
[root@rs229 conf]# pwd
/usr/local/adsit/yting/apache/hbase/hbase-0.96.2-hadoop2/conf
[root@master conf]# vi hbase-env.sh
将注释去掉,并把路径修改正确
export JAVA_HOME=/usr/java/jdk1.7.0_51
exportHBASE_CLASSPATH=/home/cloud/hadoop220/etc/hadoop
export HBASE_MANAGES_ZK=false
6.3 配置hbase-site.xml 文件
##(此处要与上述zookeeper安装过程中在zoo.cfg中配置的dataDir保持一致)
6.4 配置regionservers
[root@rs229 conf]# cat regionservers
hadoop36
hadoop37
hadoop38
hadoop40
hadoop41
hadoop42
hadoop43
hadoop44
6.5 创建hdfs-site.xml的链接
cloud@hadoop59:~/hbase0962/conf> ln~/hadoop220/etc/hadoop/hdfs-site.xml hdfs-site.xml
这里也可以将hdfs-site.xml直接copy到hbase的conf目录下面,不过没有建立软连接方便,因为直接copy的话,一旦修改了hdfs-site.xml文件,又要手工同步更新hbase的conf目录下面的hdfs-site.xml
6.6 新建backup-masters文件,为了识别配用hmaster
cloud@hadoop59:~> vi hbase0962/conf/backup-masters
hadoop60
6.7 配置profile文件,以便可以直接使用相关的命令(这里就不说了)
6.8 jar包覆盖
这个版本hbase-0.96.2不需要覆盖hadoop相关的jar包,跟hadoop-2.2.0的版本jar包是一样的,但是我们用的是zookeeper3.4.6,而hbase的lib目录下面是zookeeper-3.4.5.jar,所以更换一下zookeeper的jar包
cloud@hadoop44:~>scp zookeeper346/zookeeper-3.4.6.jar cloud@hadoop59:~/hbase0962/lib/
cloud@hadoop59:~/hbase0962/lib>mv zookeeper-3.4.5.jar zookeeper-3.4.5.jar.bak
cloud@hadoop59:~/hbase0962/lib> llzookeeper-3.4.*
-rw-r--r-- 1 cloud hadoop 779974 12月 11 2013zookeeper-3.4.5.jar.bak
-rw-r--r-- 1 cloud hadoop 1340305 6月 2 10:41 zookeeper-3.4.6.jar
cloud@hadoop59:~/hbase0962/lib>
6.9 将hbase安装文件夹分发到各个regionservers
cloud@hadoop59:~> scp -r hbase0962 cloud@hadoop60:~/
其他类似
6.10 启动hbase
cloud@hadoop59:~> hbase0962/bin/start-hbase.sh
cloud@hadoop59:~> start-hbase.sh
starting master, logging to/home/cloud/hbase0962/logs/hbase-cloud-master-hadoop59.out
hadoop43: starting regionserver, logging to/home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop43.out
hadoop37: starting regionserver, logging to /home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop37.out
hadoop40: starting regionserver, logging to/home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop40.out
hadoop41: starting regionserver, logging to /home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop41.out
hadoop44: starting regionserver, logging to/home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop44.out
hadoop42: starting regionserver, logging to/home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop42.out
hadoop38: starting regionserver, logging to/home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop38.out
hadoop36: starting regionserver, logging to/home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop36.out
hadoop60: starting master, logging to/home/cloud/hbase0962/logs/hbase-cloud-master-hadoop60.out
主节点
cloud@hadoop59:~> jps
45952 DFSZKFailoverController
49796 ResourceManager
97252 HMaster
43879 NameNode
97606 Jps
查看一下日志,没报错就差不多了
cloud@hadoop59:~> tail /home/cloud/hbase0962/logs/hbase-cloud-master-hadoop59.log
2015-06-02 14:30:44,041 DEBUG [AM.ZK.Worker-pool2-t10]master.AssignmentManager: Znodetest,,1433214676168.c6541fc62282f10ad4206d626cc10f8b. deleted, state:{c6541fc62282f10ad4206d626cc10f8b state=OPEN, ts=1433226643993,server=hadoop36,60020,1433226640106}
2015-06-02 14:30:44,041 INFO [AM.ZK.Worker-pool2-t10] master.RegionStates: Onlinedc6541fc62282f10ad4206d626cc10f8b on hadoop36,60020,1433226640106
2015-06-02 14:30:44,048 DEBUG [AM.ZK.Worker-pool2-t8] zookeeper.ZKAssign:master:60000-0x44d9d846f630015,quorum=hadoop41:2181,hadoop40:2181,hadoop38:2181,hadoop37:2181,hadoop44:2181,hadoop43:2181,hadoop42:2181,baseZNode=/hbase Deleted unassigned node d04443392f7ca74d3aa191c35e44d2af inexpected state RS_ZK_REGION_OPENED
2015-06-02 14:30:44,049 DEBUG [AM.ZK.Worker-pool2-t11]master.AssignmentManager: Znodehbase:namespace,,1433213927105.d04443392f7ca74d3aa191c35e44d2af. deleted,state: {d04443392f7ca74d3aa191c35e44d2af state=OPEN, ts=1433226644000,server=hadoop40,60020,1433226639160}
2015-06-02 14:30:44,049 INFO [AM.ZK.Worker-pool2-t11] master.RegionStates: Onlinedd04443392f7ca74d3aa191c35e44d2af on hadoop40,60020,1433226639160
2015-06-02 14:30:44,145 DEBUG [master:hadoop59:60000]hbase.ZKNamespaceManager: Updating namespace cache from node default with data:\x0A\x07default
2015-06-02 14:30:44,149 DEBUG [master:hadoop59:60000]hbase.ZKNamespaceManager: Updating namespace cache from node hbase with data:\x0A\x05hbase
2015-06-02 14:30:44,282 INFO [master:hadoop59:60000] zookeeper.RecoverableZooKeeper: Node/hbase/namespace/default already exists and this is not a retry
2015-06-02 14:30:44,301 INFO [master:hadoop59:60000] zookeeper.RecoverableZooKeeper: Node/hbase/namespace/hbase already exists and this is not a retry
2015-06-02 14:30:44,308 INFO [master:hadoop59:60000] master.HMaster:Master has completed initialization
其他regionserver节点
cloud@hadoop44:~> jps
29926 QuorumPeerMain
8133 NodeManager
7871 DataNode
24067 Jps
23826 HregionServer
查看regionserver的日志,没报错就差不多了
cloud@hadoop44:~> tail/home/cloud/hbase0962/logs/hbase-cloud-regionserver-hadoop44.log
2015-06-02 14:30:44,429 INFO [Replication.RpcServer.handler=0,port=60020] ipc.RpcServer:Replication.RpcServer.handler=0,port=60020: starting
2015-06-02 14:30:44,430 INFO [Replication.RpcServer.handler=1,port=60020] ipc.RpcServer:Replication.RpcServer.handler=1,port=60020: starting
2015-06-02 14:30:44,430 INFO [Replication.RpcServer.handler=2,port=60020] ipc.RpcServer:Replication.RpcServer.handler=2,port=60020: starting
2015-06-02 14:30:44,486 INFO [regionserver60020] Configuration.deprecation: fs.default.name isdeprecated. Instead, use fs.defaultFS
2015-06-02 14:30:44,500 INFO [regionserver60020] regionserver.HRegionServer: Serving as hadoop44,60020,1433226639598,RpcServer on hadoop44/192.168.100.44:60020, sessionid=0x34d9d846f16000c
2015-06-02 14:30:44,501 DEBUG [regionserver60020]snapshot.RegionServerSnapshotManager: Start Snapshot Managerhadoop44,60020,1433226639598
2015-06-02 14:30:44,501 DEBUG [regionserver60020]procedure.ZKProcedureMemberRpcs: Starting procedure member'hadoop44,60020,1433226639598'
2015-06-02 14:30:44,501 DEBUG [regionserver60020]procedure.ZKProcedureMemberRpcs: Checking for aborted procedures on node:'/hbase/online-snapshot/abort'
2015-06-02 14:30:44,501 INFO [SplitLogWorker-hadoop44,60020,1433226639598]regionserver.SplitLogWorker: SplitLogWorker hadoop44,60020,1433226639598starting
2015-06-02 14:30:44,503 DEBUG [regionserver60020]procedure.ZKProcedureMemberRpcs: Looking for new procedures underznode:'/hbase/online-snapshot/acquired'
查看一下zookeeper是否有建一个hbase目录
cloud@hadoop41:~> zkCli.sh
。。。。
Welcome to ZooKeeper!
2015-06-02 11:04:36,373 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Openingsocket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt toauthenticate using SASL (unknown error)
2015-06-02 11:04:36,383 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socketconnection established to localhost/0:0:0:0:0:0:0:1:2181, initiating session
JLine support is enabled
2015-06-02 11:04:36,425 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Sessionestablishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid =0x44d9d846f630008, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[hbase, hadoop-ha, zookeeper]
[zk: localhost:2181(CONNECTED) 1]
6.11 查看hbase的web管理界面
界面可以看出很多信息,包括regionserver,还有backupmasters。
6.12 hbase shell 验证 1(查看hbase的版本跟状态)
cloud@hadoop59:~> hbase shell
2015-06-02 11:06:28,661 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated.Instead, use io.native.lib.available
HBase Shell; enter 'help
Type "exit
Version 0.96.2-hadoop2, r1581096, Mon Mar 24 16:03:18 PDT 2014
hbase(main):001:0> create 'test', 'cf'
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in[jar:file:/home/cloud/hbase0962/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/home/cloud/hadoop220/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for anexplanation.
2015-06-02 11:11:14,690 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library foryour platform... using builtin-java classes where applicable
0 row(s) in 2.8660 seconds
=> Hbase::Table - test
hbase(main):002:0> list
TABLE
test
1 row(s) in 0.1010 seconds
=> ["test"]
hbase(main):003:0>
hbase(main):004:0> version
0.96.2-hadoop2, r1581096, Mon Mar 24 16:03:18 PDT 2014
hbase(main):005:0> status
8 servers, 0 dead, 0.3750 average load
6.13 hbase shell 验证 2(建表插入数据获取数据实时)
hbase(main):007:0> put'test','rowkey1','cf:id','1'
0 row(s) in 0.3270 seconds
hbase(main):008:0> put'test','rowkey1','cf:name','zhangsan'
0 row(s) in 0.0210 seconds
hbase(main):009:0> scan 'test'
ROW COLUMN+CELL
rowkey1 column=cf:id,timestamp=1433215397406, value=1
rowkey1 column=cf:name,timestamp=1433215436532, value=zhangsan
1 row(s) in 0.1110 seconds
hbase(main):010:0>
6.14 验证HMaster自动切换
6.14.1 hadoop60上的日志查看
cloud@hadoop60:~> tail/home/cloud/hbase0962/logs/hbase-cloud-master-hadoop60.log
2015-06-02 14:30:39,705 INFO [master:hadoop60:60000] http.HttpServer: Added global filter 'safety'(class=org.apache.hadoop.http.HttpServer$QuotingInputFilter)
2015-06-02 14:30:39,710 INFO [master:hadoop60:60000] http.HttpServer: Added filter static_user_filter(class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) tocontext master
2015-06-02 14:30:39,711 INFO [master:hadoop60:60000] http.HttpServer: Added filter static_user_filter(class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) tocontext static
2015-06-02 14:30:39,731 INFO [master:hadoop60:60000] http.HttpServer: Jetty bound to port 60010
2015-06-02 14:30:39,731 INFO [master:hadoop60:60000] mortbay.log: jetty-6.1.26
2015-06-02 14:30:40,291 INFO [master:hadoop60:60000] mortbay.log: [email protected]:60010
2015-06-02 14:30:40,292 DEBUG [master:hadoop60:60000]master.HMaster: HMaster started in backup mode. Stalling until master znode is written.
2015-06-02 14:30:40,407 INFO [master:hadoop60:60000] zookeeper.RecoverableZooKeeper: Node/hbase/master already exists and this is not a retry
2015-06-02 14:30:40,408 INFO [master:hadoop60:60000] master.ActiveMasterManager:Adding ZNode for /hbase/backup-masters/hadoop60,60000,1433226638688 in backupmaster directory
2015-06-02 14:30:40,421 INFO [master:hadoop60:60000]master.ActiveMasterManager: Another master is the active master,hadoop59,60000,1433226634553; waiting to become the next active master
这里说明zookeeper已经接管了,并且把hadoop60作为一个备份的Hbase了,并且这里提示waiting to become thenextactive master(等待变成下一个活动的master),然后我们可以将hadoop59上的hmaster进程给kill掉,当然,也可以使用 ./hbase-daemon.shstop master 来结束hadoop59上的hmaster进程
6.14.2 kill掉hadoop59上的hmaster进程,看看hadoop60上的日志会有什么变化
cloud@hadoop59:~> hbase0962/bin/hbase-daemon.shstop master
stopping master.
cloud@hadoop59:~> jps
1320 Jps
45952 DFSZKFailoverController
49796 ResourceManager
43879 NameNode
cloud@hadoop59:~>
# 下面是hadoop60上日志变化后的信息
cloud@hadoop60:~>tail -n 50/home/cloud/hbase0962/logs/hbase-cloud-master-hadoop60.log
(省略。。。。。。)
2015-06-0214:47:48,103 INFO [master:hadoop60:60000] master.RegionStates: Onlinedc6541fc62282f10ad4206d626cc10f8b on hadoop36,60020,1433226640106
2015-06-0214:47:48,105 DEBUG [master:hadoop60:60000] master.AssignmentManager: Found{ENCODED => c6541fc62282f10ad4206d626cc10f8b, NAME =>'test,,1433214676168.c6541fc62282f10ad4206d626cc10f8b.', STARTKEY => '',ENDKEY => ''} out on cluster
2015-06-02 14:47:48,105INFO [master:hadoop60:60000]master.AssignmentManager: Found regions out on cluster or in RIT; presumingfailover
2015-06-0214:47:48,237 DEBUG [master:hadoop60:60000] hbase.ZKNamespaceManager: Updatingnamespace cache from node default with data: \x0A\x07default
2015-06-0214:47:48,241 DEBUG [master:hadoop60:60000] hbase.ZKNamespaceManager: Updatingnamespace cache from node hbase with data: \x0A\x05hbase
2015-06-0214:47:48,289 INFO [master:hadoop60:60000] zookeeper.RecoverableZooKeeper: Node /hbase/namespace/defaultalready exists and this is not a retry
2015-06-0214:47:48,308 INFO [master:hadoop60:60000] zookeeper.RecoverableZooKeeper: Node/hbase/namespace/hbase already exists and this is not a retry
2015-06-0214:47:48,318 INFO [master:hadoop60:60000]master.HMaster: Master has completed initialization
只看红色标注的地方,意思就是说当我们kill掉hadoop59上的hmaster的时候,唤醒等待的hmaster线程,然后找到了等待的hmaster(hadoop60)),然后 zookeeper就接管并且将hadoop6上的hmaster从等待状态切换为激活状态了,然后就ok了。(当然也可以多开几个备用的hmaster,只需要在backup-masters配置文件中添加即可)
下面验证配用hbase是否可用
cloud@hadoop60:~> hbase shell
2015-06-02 14:51:36,014 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated.Instead, use io.native.lib.available
HBase Shell; enter 'help
Type "exit
Version 0.96.2-hadoop2, r1581096, Mon Mar 24 16:03:18 PDT 2014
hbase(main):001:0> status
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in[jar:file:/home/cloud/hbase0962/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/home/cloud/hadoop220/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for anexplanation.
2015-06-02 14:51:40,658 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library foryour platform... using builtin-java classes where applicable
8 servers, 0 dead, 0.3750 average load
hbase(main):002:0> scan 'test'
ROW COLUMN+CELL
rowkey1 column=cf:id, timestamp=1433215397406, value=1
rowkey1 column=cf:name, timestamp=1433215436532, value=zhangsan
1 row(s) in 0.2120 seconds
hbase(main):003:0>
7 Hive-0.13.1
7.1 解压apache-hive-0.13.1-bin.tar.gz
cloud@hadoop59:~> tar -zvxf apache-hive-0.13.1-bin.tar.gz
cloud@hadoop59:~> mv apache-hive-0.13.1-bin hive0131
7.2 添加环境变量,通过模版文件复制出对应的文件
cloud@hadoop59:~ > sudo vi /etc/profile
##set hive enviroment
export HIVE_HOME=/home/cloud/hive0131
export PATH=$PATH:$HIVE_HOME/bin
cloud@hadoop59:~/hive0131/conf> cphive-exec-log4j.properties.template hive-exec-log4j.properties
cloud@hadoop59:~/hive0131/conf> cphive-log4j.properties.template hive-log4j.properties
cloud@hadoop59:~/hive0131/conf> cphive-env.sh.template hive-env.sh
cloud@hadoop59:~/hive0131/conf> cphive-default.xml.template hive-site.xml
cloud@hadoop59:~/hive0131/conf> ll
总用量 248
-rw-r--r-- 1 cloud hadoop 107221 6月 3 2014 hive-default.xml.template
-rw-r--r-- 1 cloud hadoop 2378 6月 2 15:14 hive-env.sh
-rw-r--r-- 1 cloud hadoop 2378 1月 30 2014 hive-env.sh.template
-rw-r--r-- 1 cloud hadoop 2662 6月 2 15:16hive-exec-log4j.properties
-rw-r--r-- 1 cloud hadoop 2662 5月 13 2014 hive-exec-log4j.properties.template
-rw-r--r-- 1 cloud hadoop 3050 6月 2 15:16hive-log4j.properties
-rw-r--r-- 1 cloud hadoop 3050 5月 13 2014 hive-log4j.properties.template
-rw-r--r-- 1 cloud hadoop 107221 6月 2 15:14 hive-site.xml
7.3 修改hive-env.sh配置文件
cloud@hadoop59:~/hive0131/conf> vi hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/home/cloud/hadoop220
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/home/cloud/hive0131/conf
7.4 修改hive-site.xml文件
注意1 : 如果使用mysql的话需要在${HIVE_HOME}/lib目录下加入mysql的jdbc链接jar包
cloud@hadoop59:~> mv ~/mysql-connector-java-5.1.25.jarhive0131/lib/
注意2 : mysql必须授权远程登录,如果你是的MySQL与hive是同一个服务器,还需要本地登录授权
cloud@hadoop59:~> mysql –uroot
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hivedbuser'@'localhost'IDENTIFIED BY 'hivedbuser' WITH GRANTOPTION;
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hivedbuser'@'hadoop59'IDENTIFIED BY 'hivedbuser' WITH GRANTOPTION;
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO'hivedbuser'@'%' IDENTIFIED BY 'hivedbuser' WITH GRANT OPTION;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit;
7.5 创建数据仓库目录
cloud@hadoop59:~/hive0131> mkdir logs
cloud@hadoop59:~ > hadoop fs -mkdir /user/hive
cloud@hadoop59:~ > hadoop fs -mkdir/user/hive/warehouse
7.6 替换zookeeper的jar包
还要替换zookeeper的jar包
cloud@hadoop59:~> cphbase0962/lib/zookeeper-3.4.6.jar hive0131/lib/
cloud@hadoop59:~> mvhive0131/lib/zookeeper-3.4.5.jar hive0131/lib/zookeeper-3.4.5.jar.bak
cloud@hadoop59:~> llhive0131/lib/zookeeper-3.4.*
-rw-r--r-- 1 cloud hadoop 779974 1月30 2014 hive0131/lib/zookeeper-3.4.5.jar.bak
-rw-r--r-- 1 cloud hadoop 1340305 6月 2 16:03hive0131/lib/zookeeper-3.4.6.jar
7.7 Hive测试
7.7.1 进入Hive Shell
先启动hive元数据服务,后台启动
cloud@hadoop59:~> hive --service metastore&
[1] 19003
cloud@hadoop59:~> Starting Hive Metastore Server
15/06/02 16:52:12 INFO Configuration.deprecation: mapred.reduce.tasksis deprecated. Instea
15/06/02 16:52:12 INFO Configuration.deprecation:mapred.min.split.size is deprecated. Inst
15/06/02 16:52:12 INFO Configuration.deprecation:mapred.reduce.tasks.speculative.execution
15/06/02 16:52:12 INFO Configuration.deprecation:mapred.min.split.size.per.node is depreca
15/06/02 16:52:12 INFO Configuration.deprecation:mapred.input.dir.recursive is deprecated.
15/06/02 16:52:12 INFO Configuration.deprecation:mapred.min.split.size.per.rack is depreca
15/06/02 16:52:12 INFO Configuration.deprecation:mapred.max.split.size is deprecated. Inst
15/06/02 16:52:12 INFO Configuration.deprecation:mapred.committer.job.setup.cleanup.needed
15/06/02 16:52:13 WARN conf.HiveConf: DEPRECATED:hive.metastore.ds.retry.* no longer has a
cloud@hadoop59:~> hive
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.reduce.tasks is deprecated. Instea
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.min.split.size is deprecated. Inst
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.reduce.tasks.speculative.execution
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.min.split.size.per.node is depreca
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.input.dir.recursive is deprecated.
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.min.split.size.per.rack is depreca
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.max.split.size is deprecated. Inst
15/06/02 16:53:16 INFO Configuration.deprecation:mapred.committer.job.setup.cleanup.needed
15/06/02 16:53:17 WARN conf.HiveConf: DEPRECATED:hive.metastore.ds.retry.* no longer has a
Logging initialized using configuration infile:/home/cloud/hive0131/conf/hive-log4j.proper
hive> show tables;
OK
Time taken: 1.158 seconds
hive> show databases;
OK
default
Time taken: 0.047 seconds, Fetched: 1 row(s)
7.7.2 创建数据库
hive> create database testdb;
OK
Time taken: 0.401 seconds
hive> show databases;
OK
default
testdb
Time taken: 0.041 seconds, Fetched: 2 row(s)
7.7.3 建表
hive> create table testtb(id string,name string)
> rowformat delimited
>fields terminated by ','
>stored as textfile;
OK
Time taken: 0.573 seconds
这里是创建的一个外部表
7.7.4 Load数据到表testtb
hive> load data local inpath'/home/cloud/hivetest.txt' overwrite into table testtb;
Copying data from file:/home/cloud/hivetest.txt
Copying file: file:/home/cloud/hivetest.txt
Loading data to table testdb.testtb
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://mycluster/user/hive/warehouse/testdb.db/testtb
Table testdb.testtb stats: [numFiles=1, numRows=0,totalSize=34, rawDataSize=0]
OK
Time taken: 1.347 seconds
hive>
7.7.5 查询数据是否加载成功
hive> select * from testtb;
OK
100 zhangshan
101 lisi
102 wangwu
Time taken: 0.472 seconds, Fetched: 3 row(s)
8.Sqoop-1.4.5
8.1 下载安装包及解压
cloud@hadoop59:~>tar -zxvf sqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz
cloud@hadoop59:~>mv sqoop-1.4.5.bin__hadoop-2.0.4-alpha sqoop145
8.2 配置环境变量和配置文件
cloud@hadoop59:~>sudovi /etc/profile
##set sqoop enviroment
export SQOOP_HOME=/home/cloud/sqoop145
export PATH=$PATH:$SQOOP_HOME/bin
cloud@hadoop59:~> cd sqoop145/
cloud@hadoop59:~/sqoop145> cd conf/
cloud@hadoop59:~/sqoop145/conf>cp sqoop-env-template.sh sqoop-env.sh
cloud@hadoop59:~/sqoop145/conf>vi sqoop-env.sh
# SetHadoop-specific environment variables here.
#Set path to wherebin/hadoop is available
exportHADOOP_COMMON_HOME=/home/cloud/hadoop220
#Set path to wherehadoop-*-core.jar is available
exportHADOOP_MAPRED_HOME=/home/cloud/hadoop220
#set the path towhere bin/hbase is available
exportHBASE_HOME=/home/cloud/hbase0962
#Set the path towhere bin/hive is available
exportHIVE_HOME=/home/cloud/hive0131
#Set the path forwhere zookeper config dir is
export ZOOCFGDIR=/home/cloud/zookeeper346
(如果数据读取不设计hbase和hive,那么相关hbase和hive的配置可以不加,如果集群有独立的zookeeper集群,那么配置zookeeper,反之,不用配置)。
8.3 copy需要的lib包到Sqoop/lib
所需的包: Oracle的jdbc包、mysql的jdbc包(oracle的jar包:ojdbc6.jar,mysql的jar包mysql-connector-java-5.1.25.jar)
cloud@hadoop59:~/sqoop145/conf>cp ~/hive0131/lib/mysql-connector-java-5.1.25.jar ../lib/
这里只复制了MySQL的链接包
8.4 添加环境变量
cloud@hadoop59:~> sudo vi /etc/profile
添加如下内容
##set sqoopenviroment
exportSQOOP_HOME=/home/cloud/sqoop145
exportPATH=$PATH:$SQOOP_HOME/bin
8.5 测试sqoop的使用
前提:导入mysql jdbc的jar包
① 测试数据库连接
<1>列出mysql中的所有数据库
cloud@hadoop59:~> sqoop list-databases --connect jdbc:mysql://hadoop59:3306/ --username hivedbuser--password hivedbuser
Warning: /home/cloud/sqoop145/../hcatalog does notexist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCataloginstallation.
Warning: /home/cloud/sqoop145/../accumulo does notexist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of yourAccumulo installation.
Warning: /home/cloud/zookeeper346 does not exist!Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of yourZookeeper installation.
15/06/03 10:35:45 INFO sqoop.Sqoop: Running Sqoopversion: 1.4.5
15/06/03 10:35:45 WARN tool.BaseSqoopTool: Settingyour password on the command-line is insecure. Consider using -P instead.
15/06/03 10:35:46 INFO manager.MySQLManager:Preparing to use a MySQL streaming resultset.
information_schema
hivedb
mysql
performance_schema
report
scm
test
<2>列出mysql中某个库下所有表
cloud@hadoop59:~> sqoop list-tables--connect jdbc:mysql://hadoop59:3306/hivedb --username hivedbuser --passwordhivedbuser
cloud@hadoop59:~> sqoop list-tables --connectjdbc:mysql://hadoop59:3306/hivedb --username hivedbuser --password hivedbuser
Warning: /home/cloud/sqoop145/../hcatalog does notexist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCataloginstallation.
Warning: /home/cloud/sqoop145/../accumulo does notexist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of yourAccumulo installation.
Warning: /home/cloud/zookeeper346 does not exist!Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of yourZookeeper installation.
15/06/03 10:44:03 INFO sqoop.Sqoop: Running Sqoopversion: 1.4.5
15/06/03 10:44:03 WARN tool.BaseSqoopTool: Settingyour password on the command-line is insecure. Consider using -P instead.
15/06/03 10:44:04 INFO manager.MySQLManager:Preparing to use a MySQL streaming resultset.
BUCKETING_COLS
CDS
COLUMNS_V2
DATABASE_PARAMS
DBS
FUNCS
FUNC_RU
GLOBAL_PRIVS
PARTITIONS
PARTITION_KEYS
PART_COL_STATS
ROLES
SDS
SD_PARAMS
SEQUENCE_TABLE
SERDES
SERDE_PARAMS
SKEWED_COL_NAMES
SKEWED_COL_VALUE_LOC_MAP
SKEWED_STRING_LIST
SKEWED_STRING_LIST_VALUES
SKEWED_VALUES
SORT_COLS
TABLE_PARAMS
TAB_COL_STATS
TBLS
VERSION
②Sqoop的使用
<1>mysql–>hdfs
cloud@hadoop59:~>sqoop import --connect jdbc:mysql://hadoop59:3306/hivedb --username hivedbuser --password hivedbuser --table VERSION -m 1
。。。。。。
15/06/03 11:23:49INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, usemapreduce.job.working.dir
15/06/03 11:23:50INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1433151705225_0003
15/06/03 11:23:50INFO impl.YarnClientImpl: Submitted application application_1433151705225_0003to ResourceManager at hadoop59/192.168.100.59:8032
15/06/03 11:23:50INFO mapreduce.Job: The url to track the job:http://hadoop59:8088/proxy/application_1433151705225_0003/
15/06/03 11:23:50INFO mapreduce.Job: Running job: job_1433151705225_0003
15/06/03 11:23:58INFO mapreduce.Job: Job job_1433151705225_0003 running in uber mode : false
15/06/03 11:23:58INFO mapreduce.Job: map 0% reduce 0%
15/06/03 11:24:09INFO mapreduce.Job: map 100% reduce 0%
15/06/03 11:24:10INFO mapreduce.Job: Job job_1433151705225_0003 completed successfully
15/06/03 11:24:10INFO mapreduce.Job: Counters: 27
File System Counters
FILE: Number of bytes read=0
FILE: Number of byteswritten=92322
FILE: Number of read operations=0
FILE: Number of large readoperations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=26
HDFS: Number of read operations=4
HDFS: Number of large readoperations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps inoccupied slots (ms)=7586
Total time spent by all reduces inoccupied slots (ms)=0
Map-Reduce Framework
Map input records=1
Map output records=1
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=26
CPU time spent (ms)=1770
Physical memory (bytes)snapshot=160464896
Virtual memory (bytes)snapshot=711737344
Total committed heap usage(bytes)=201326592
File Input FormatCounters
Bytes Read=0
File Output Format Counters
Bytes Written=26
15/06/03 11:24:10INFO mapreduce.ImportJobBase: Transferred 26 bytes in 22.8962 seconds (1.1356bytes/sec)
15/06/03 11:24:10INFO mapreduce.ImportJobBase: Retrieved 1 records.
去hdfs的test目录查看一下结果
cloud@hadoop60:~>hadoop fs -ls /user/
15/06/03 11:24:22WARN util.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable
Found 2 items
drwxr-xr-x - cloud supergroup 0 2015-06-03 11:23 /user/cloud
drwxr-xr-x - cloud supergroup 0 2015-06-02 17:20 /user/hive
cloud@hadoop60:~>hadoop fs -ls /user/cloud
15/06/03 11:24:38WARN util.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable
Found 2 items
drwxr-xr-x - cloud supergroup 0 2015-06-03 11:24/user/cloud/VERSION
drwxr-xr-x - cloud supergroup 0 2015-06-02 15:54 /user/cloud/–p
cloud@hadoop60:~>hadoop fs -ls /user/cloud/VERSION
15/06/03 11:24:56WARN util.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 3 cloud supergroup 0 2015-06-03 11:24/user/cloud/VERSION/_SUCCESS
-rw-r--r-- 3 cloud supergroup 26 2015-06-03 11:24/user/cloud/VERSION/part-m-00000
cloud@hadoop60:~>hadoop fs -cat /user/cloud/VERSION/part-m-00000
15/06/03 11:25:29WARN util.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable
1,0.13.0,Set byMetaStore
9. Spark-1.0.2-bin-hadoop2
9.1解压scala,spark
cloud@hadoop59:~> tar -zvxf scala-2.10.4.tgz
cloud@hadoop59:~> mv scala-2.10.4 scala2104
cloud@hadoop59:~> tar -zvxfspark-1.0.2-bin-hadoop2.tgz
cloud@hadoop59:~> mv spark-1.0.2-bin-hadoop2 spark102
9.2环境变量的设置
sudo vi /etc/profile
加在最后
##set spark enviroment
export SCALA_HOME=/home/cloud/scala2104
export SPARK_HOME=/home/cloud/spark102
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin
刷新更改的环境变量配置 source/etc/profile
测试scala是否安装正确 scala –version
cloud@hadoop59:~>scala -version
Scala code runnerversion 2.10.4 -- Copyright 2002-2013, LAMP/EPFL
9.3 修改slaves文件
cloud@hadoop59:~>vi spark102/conf/slaves
##添加如下内容,启用4个worker,如果需要更多的worker,可以在此文件添加即可
hadoop26
hadoop27
hadoop28
hadoop29
9.4 修改spark-env.sh文件
cloud@hadoop59:~>cp spark102/conf/spark-env.sh.template spark102/conf/spark-env.sh
cloud@hadoop59:~>vi spark102/conf/spark-env.sh
添加如下信息
exportSCALA_HOME=/home/cloud/scala2104
export JAVA_HOME= /usr/java/jdk1.7.0_51
exportSPARK_MASTER_IP=hadoop59
exportSPARK_WORKER_MEMORY=10G
SPARK_WORKER_MEMORY是Spark在每一个节点上可用内存的最大,增加这个数值可以在内存中缓存更多的数据,但是一定要记住给Slave的操作系统和其他服务预留足够的内存。以后可以根据需要修改内存。
9.5将程序分发给每个节点
cloud@hadoop59:~> scp -r spark102/ cloud@hadoop26:~/
cloud@hadoop59:~> scp -r spark102/cloud@hadoop27:~/
cloud@hadoop59:~> scp -r spark102/cloud@hadoop28:~/
cloud@hadoop59:~> scp -r spark102/cloud@hadoop29:~/
9.6启动并测试
cloud@hadoop59:~/spark102/sbin>./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to/home/cloud/spark102/sbin/../logs/spark-cloud-org.apache.spark.deploy.master.Master-1-hadoop59.out
hadoop29: starting org.apache.spark.deploy.worker.Worker, logging to /home/cloud/spark102/sbin/../logs/spark-cloud-org.apache.spark.deploy.worker.Worker-1-hadoop29.out
hadoop28: starting org.apache.spark.deploy.worker.Worker, logging to/home/cloud/spark102/sbin/../logs/spark-cloud-org.apache.spark.deploy.worker.Worker-1-hadoop28.out
hadoop27: starting org.apache.spark.deploy.worker.Worker, logging to/home/cloud/spark102/sbin/../logs/spark-cloud-org.apache.spark.deploy.worker.Worker-1-hadoop27.out
hadoop26: starting org.apache.spark.deploy.worker.Worker, logging to /home/cloud/spark102/sbin/../logs/spark-cloud-org.apache.spark.deploy.worker.Worker-1-hadoop26.out
查看是否成功启动进程
## 监控页面URL
测试
<1>本地模式
cloud@hadoop59:~/spark102>./bin/run-example org.apache.spark.examples.SparkPi
Spark assembly has been built with Hive, includingDatanucleus jars on classpath
15/06/03 15:39:16 INFO spark.SecurityManager:Changing view acls to: cloud
15/06/03 15:39:16 INFO spark.SecurityManager:SecurityManager: authentication disabled; ui acls disabled; users with viewpermissions: Set(cloud)
15/06/03 15:39:16 INFO slf4j.Slf4jLogger:Slf4jLogger started
15/06/03 15:39:17 INFO Remoting: Starting remoting
15/06/03 15:39:17 INFO Remoting: Remoting started;listening on addresses :[akka.tcp://spark@hadoop59:35034]
15/06/03 15:39:17 INFO Remoting: Remoting nowlistens on addresses: [akka.tcp://spark@hadoop59:35034]
15/06/03 15:39:17 INFO spark.SparkEnv: RegisteringMapOutputTracker
15/06/03 15:39:17 INFO spark.SparkEnv: RegisteringBlockManagerMaster
15/06/03 15:39:17 INFO storage.DiskBlockManager:Created local directory at /tmp/spark-local-20150603153917-0dcc
15/06/03 15:39:17 INFO storage.MemoryStore:MemoryStore started with capacity 294.9 MB.
15/06/03 15:39:17 INFO network.ConnectionManager:Bound socket to port 20948 with id = ConnectionManagerId(hadoop59,20948)
15/06/03 15:39:17 INFO storage.BlockManagerMaster:Trying to register BlockManager
15/06/03 15:39:17 INFO storage.BlockManagerInfo:Registering block manager hadoop59:20948 with 294.9 MB RAM
15/06/03 15:39:17 INFO storage.BlockManagerMaster:Registered BlockManager
15/06/03 15:39:17 INFO spark.HttpServer: StartingHTTP Server
15/06/03 15:39:17 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 15:39:17 INFO server.AbstractConnector:Started [email protected]:58505
15/06/03 15:39:17 INFO broadcast.HttpBroadcast:Broadcast server started at http://192.168.100.59:58505
15/06/03 15:39:17 INFO spark.HttpFileServer: HTTPFile server directory is /tmp/spark-e6619005-c161-42db-9c95-28ad728a4111
15/06/03 15:39:17 INFO spark.HttpServer: StartingHTTP Server
15/06/03 15:39:17 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 15:39:17 INFO server.AbstractConnector:Started [email protected]:50136
15/06/03 15:39:18 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 15:39:18 INFO server.AbstractConnector:Started [email protected]:4040
15/06/03 15:39:18 INFO ui.SparkUI: Started SparkUIat http://hadoop59:4040
15/06/03 15:39:18 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
15/06/03 15:39:19 INFO spark.SparkContext: AddedJAR file:/home/cloud/spark102/lib/spark-examples-1.0.2-hadoop2.2.0.jar athttp://192.168.100.59:50136/jars/spark-examples-1.0.2-hadoop2.2.0.jar withtimestamp 1433317159010
15/06/03 15:39:19 INFO spark.SparkContext: Startingjob: reduce at SparkPi.scala:35
15/06/03 15:39:19 INFO scheduler.DAGScheduler: Gotjob 0 (reduce at SparkPi.scala:35) with 2 output partitions (allowLocal=false)
15/06/03 15:39:19 INFO scheduler.DAGScheduler:Final stage: Stage 0(reduce at SparkPi.scala:35)
15/06/03 15:39:19 INFO scheduler.DAGScheduler:Parents of final stage: List()
15/06/03 15:39:19 INFO scheduler.DAGScheduler:Missing parents: List()
15/06/03 15:39:19 INFO scheduler.DAGScheduler:Submitting Stage 0 (MappedRDD[1] at map at SparkPi.scala:31), which has nomissing parents
15/06/03 15:39:19 INFO scheduler.DAGScheduler:Submitting 2 missing tasks from Stage 0 (MappedRDD[1] at map atSparkPi.scala:31)
15/06/03 15:39:19 INFO scheduler.TaskSchedulerImpl:Adding task set 0.0 with 2 tasks
15/06/03 15:39:19 INFO scheduler.TaskSetManager:Starting task 0.0:0 as TID 0 on executor localhost: localhost (PROCESS_LOCAL)
15/06/03 15:39:19 INFO scheduler.TaskSetManager:Serialized task 0.0:0 as 1411 bytes in 4 ms
15/06/03 15:39:19 INFO scheduler.TaskSetManager:Starting task 0.0:1 as TID 1 on executor localhost: localhost (PROCESS_LOCAL)
15/06/03 15:39:19 INFO scheduler.TaskSetManager:Serialized task 0.0:1 as 1411 bytes in 1 ms
15/06/03 15:39:19 INFO executor.Executor: Runningtask ID 0
15/06/03 15:39:19 INFO executor.Executor: Runningtask ID 1
15/06/03 15:39:19 INFO executor.Executor: Fetchinghttp://192.168.100.59:50136/jars/spark-examples-1.0.2-hadoop2.2.0.jar withtimestamp 1433317159010
15/06/03 15:39:19 INFO util.Utils: Fetching http://192.168.100.59:50136/jars/spark-examples-1.0.2-hadoop2.2.0.jarto /tmp/fetchFileTemp2420806525891660860.tmp
15/06/03 15:39:20 INFO executor.Executor: Addingfile:/tmp/spark-286f5762-3d00-47af-a736-14cd0b9616d6/spark-examples-1.0.2-hadoop2.2.0.jarto class loader
15/06/03 15:39:20 INFO executor.Executor:Serialized size of result for 0 is 675
15/06/03 15:39:20 INFO executor.Executor:Serialized size of result for 1 is 675
15/06/03 15:39:20 INFO executor.Executor: Sendingresult for 0 directly to driver
15/06/03 15:39:20 INFO executor.Executor: Sendingresult for 1 directly to driver
15/06/03 15:39:20 INFO executor.Executor: Finishedtask ID 0
15/06/03 15:39:20 INFO executor.Executor: Finishedtask ID 1
15/06/03 15:39:20 INFO scheduler.TaskSetManager:Finished TID 0 in 1023 ms on localhost (progress: 1/2)
15/06/03 15:39:20 INFO scheduler.DAGScheduler:Completed ResultTask(0, 0)
15/06/03 15:39:20 INFO scheduler.TaskSetManager:Finished TID 1 in 1011 ms on localhost (progress: 2/2)
15/06/03 15:39:20 INFO scheduler.DAGScheduler:Completed ResultTask(0, 1)
15/06/03 15:39:20 INFO scheduler.TaskSchedulerImpl:Removed TaskSet 0.0, whose tasks have all completed, from pool
15/06/03 15:39:20 INFO scheduler.DAGScheduler: Stage0 (reduce at SparkPi.scala:35) finished in 1.050 s
15/06/03 15:39:20 INFO spark.SparkContext: Jobfinished: reduce at SparkPi.scala:35, took 1.256508394 s
Pi is roughly 3.14278
标红的表示计算出来的PI的值
<2>普通集群模式
在26机器上运行测试程序
cloud@hadoop26:~>spark102/bin/run-example org.apache.spark.examples.SparkPi 2 spark://hadoop59:7077
Spark assembly has been built with Hive, includingDatanucleus jars on classpath
15/06/03 16:15:38 INFO spark.SecurityManager:Changing view acls to: cloud
15/06/03 16:15:38 INFO spark.SecurityManager:SecurityManager: authentication disabled; ui acls disabled; users with viewpermissions: Set(cloud)
15/06/03 16:15:38 INFO slf4j.Slf4jLogger:Slf4jLogger started
15/06/03 16:15:38 INFO Remoting: Starting remoting
15/06/03 16:15:39 INFO Remoting: Remoting started;listening on addresses :[akka.tcp://spark@hadoop26:49653]
15/06/03 16:15:39 INFO Remoting: Remoting nowlistens on addresses: [akka.tcp://spark@hadoop26:49653]
15/06/03 16:15:39 INFO spark.SparkEnv: RegisteringMapOutputTracker
15/06/03 16:15:39 INFO spark.SparkEnv: RegisteringBlockManagerMaster
15/06/03 16:15:39 INFO storage.DiskBlockManager:Created local directory at /tmp/spark-local-20150603161539-4fcb
15/06/03 16:15:39 INFO storage.MemoryStore:MemoryStore started with capacity 294.9 MB.
15/06/03 16:15:39 INFO network.ConnectionManager:Bound socket to port 47657 with id = ConnectionManagerId(hadoop26,47657)
15/06/03 16:15:39 INFO storage.BlockManagerMaster:Trying to register BlockManager
15/06/03 16:15:39 INFO storage.BlockManagerInfo:Registering block manager hadoop26:47657 with 294.9 MB RAM
15/06/03 16:15:39 INFO storage.BlockManagerMaster:Registered BlockManager
15/06/03 16:15:39 INFO spark.HttpServer: StartingHTTP Server
15/06/03 16:15:39 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/06/03 16:15:39 INFO server.AbstractConnector:Started [email protected]:51501
15/06/03 16:15:39 INFO broadcast.HttpBroadcast:Broadcast server started at http://192.168.100.26:51501
15/06/03 16:15:39 INFO spark.HttpFileServer: HTTPFile server directory is /tmp/spark-a78f943a-d75c-44b5-be94-295e70468cd5
15/06/03 16:15:39 INFO spark.HttpServer: StartingHTTP Server
15/06/03 16:15:39 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 16:15:39 INFO server.AbstractConnector:Started [email protected]:33332
15/06/03 16:15:39 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 16:15:39 INFO server.AbstractConnector:Started [email protected]:4040
15/06/03 16:15:39 INFO ui.SparkUI: Started SparkUIat http://hadoop26:4040
15/06/03 16:15:40 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
15/06/03 16:15:40 INFO spark.SparkContext: AddedJAR file:/home/cloud/spark102/lib/spark-examples-1.0.2-hadoop2.2.0.jar athttp://192.168.100.26:33332/jars/spark-examples-1.0.2-hadoop2.2.0.jar withtimestamp 1433319340644
15/06/03 16:15:40 INFO spark.SparkContext: Startingjob: reduce at SparkPi.scala:35
15/06/03 16:15:40 INFO scheduler.DAGScheduler: Gotjob 0 (reduce at SparkPi.scala:35) with 2 output partitions (allowLocal=false)
15/06/03 16:15:40 INFO scheduler.DAGScheduler:Final stage: Stage 0(reduce at SparkPi.scala:35)
15/06/03 16:15:40 INFO scheduler.DAGScheduler:Parents of final stage: List()
15/06/03 16:15:40 INFO scheduler.DAGScheduler:Missing parents: List()
15/06/03 16:15:40 INFO scheduler.DAGScheduler:Submitting Stage 0 (MappedRDD[1] at map at SparkPi.scala:31), which has nomissing parents
15/06/03 16:15:40 INFO scheduler.DAGScheduler:Submitting 2 missing tasks from Stage 0 (MappedRDD[1] at map atSparkPi.scala:31)
15/06/03 16:15:40 INFO scheduler.TaskSchedulerImpl:Adding task set 0.0 with 2 tasks
15/06/03 16:15:40 INFO scheduler.TaskSetManager:Starting task 0.0:0 as TID 0 on executor localhost: localhost (PROCESS_LOCAL)
15/06/03 16:15:40 INFO scheduler.TaskSetManager:Serialized task 0.0:0 as 1411 bytes in 4 ms
15/06/03 16:15:40 INFO scheduler.TaskSetManager:Starting task 0.0:1 as TID 1 on executor localhost: localhost (PROCESS_LOCAL)
15/06/03 16:15:40 INFO scheduler.TaskSetManager:Serialized task 0.0:1 as 1411 bytes in 1 ms
15/06/03 16:15:40 INFO executor.Executor: Runningtask ID 1
15/06/03 16:15:40 INFO executor.Executor: Runningtask ID 0
15/06/03 16:15:40 INFO executor.Executor: Fetchinghttp://192.168.100.26:33332/jars/spark-examples-1.0.2-hadoop2.2.0.jar withtimestamp 1433319340644
15/06/03 16:15:40 INFO util.Utils: Fetching http://192.168.100.26:33332/jars/spark-examples-1.0.2-hadoop2.2.0.jarto /tmp/fetchFileTemp1780661119038827363.tmp
15/06/03 16:15:41 INFO executor.Executor: Addingfile:/tmp/spark-7953a752-aec1-4f17-994e-d167a30089b3/spark-examples-1.0.2-hadoop2.2.0.jarto class loader
15/06/03 16:15:41 INFO executor.Executor:Serialized size of result for 0 is 675
15/06/03 16:15:41 INFO executor.Executor:Serialized size of result for 1 is 675
15/06/03 16:15:41 INFO executor.Executor: Sendingresult for 1 directly to driver
15/06/03 16:15:41 INFO executor.Executor: Sendingresult for 0 directly to driver
15/06/03 16:15:41 INFO executor.Executor: Finishedtask ID 0
15/06/03 16:15:41 INFO executor.Executor: Finishedtask ID 1
15/06/03 16:15:41 INFO scheduler.TaskSetManager:Finished TID 1 in 848 ms on localhost (progress: 1/2)
15/06/03 16:15:41 INFO scheduler.DAGScheduler:Completed ResultTask(0, 1)
15/06/03 16:15:41 INFO scheduler.TaskSetManager:Finished TID 0 in 869 ms on localhost (progress: 2/2)
15/06/03 16:15:41 INFO scheduler.DAGScheduler:Completed ResultTask(0, 0)
15/06/03 16:15:41 INFO scheduler.TaskSchedulerImpl:Removed TaskSet 0.0, whose tasks have all completed, from pool
15/06/03 16:15:41 INFO scheduler.DAGScheduler:Stage 0 (reduce at SparkPi.scala:35) finished in 0.888 s
15/06/03 16:15:41 INFO spark.SparkContext: Jobfinished: reduce at SparkPi.scala:35, took 0.972514214 s
Pi is roughly 3.14706
<3>结合HDFS的集群模式
上传文件到hdfs
cloud@hadoop59:~> hadoop fs -put sparktest.txt /test/
15/06/03 16:09:34 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
cloud@hadoop59:~> hadoop fs-ls /test/
15/06/03 16:09:46 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
Found 1 items
-rw-r--r-- 3 cloud supergroup 1142015-06-03 16:09 /test/sparktest.txt
cloud@hadoop59:~> cat sparktest.txt
hello world
hello hadoop
i love hadoop
hadoop is good
i am studying hadoop
i am testing spark
i am testing hadoop
同样还是在26机器上运行
cloud@hadoop26:~/spark102/bin>MASTER=spark://hadoop59:7077 ./spark-shell
Spark assembly has been built with Hive, includingDatanucleus jars on classpath
15/06/03 16:20:44 INFO spark.SecurityManager:Changing view acls to: cloud
15/06/03 16:20:44 INFO spark.SecurityManager:SecurityManager: authentication disabled; ui acls disabled; users with viewpermissions: Set(cloud)
15/06/03 16:20:44 INFO spark.HttpServer: StartingHTTP Server
15/06/03 16:20:44 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 16:20:44 INFO server.AbstractConnector:Started [email protected]:56600
Welcome to
____ __
/__/__ ___ _____/ /__
_\ \/ _\/ _ `/ __/ '_/
/___/.__/\_,_/_/ /_/\_\ version 1.0.2
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-BitServer VM, Java 1.7.0_51)
Type in expressions to have them evaluated.
Type :help for more information.
15/06/03 16:20:47 INFO spark.SecurityManager:Changing view acls to: cloud
15/06/03 16:20:47 INFO spark.SecurityManager:SecurityManager: authentication disabled; ui acls disabled; users with viewpermissions: Set(cloud)
15/06/03 16:20:48 INFO slf4j.Slf4jLogger:Slf4jLogger started
15/06/03 16:20:48 INFO Remoting: Starting remoting
15/06/03 16:20:48 INFO Remoting: Remoting started;listening on addresses :[akka.tcp://spark@hadoop26:33452]
15/06/03 16:20:48 INFO Remoting: Remoting nowlistens on addresses: [akka.tcp://spark@hadoop26:33452]
15/06/03 16:20:48 INFO spark.SparkEnv: RegisteringMapOutputTracker
15/06/03 16:20:48 INFO spark.SparkEnv: RegisteringBlockManagerMaster
15/06/03 16:20:48 INFO storage.DiskBlockManager:Created local directory at /tmp/spark-local-20150603162048-942b
15/06/03 16:20:48 INFO storage.MemoryStore:MemoryStore started with capacity 294.9 MB.
15/06/03 16:20:48 INFO network.ConnectionManager:Bound socket to port 44880 with id = ConnectionManagerId(hadoop26,44880)
15/06/03 16:20:48 INFO storage.BlockManagerMaster:Trying to register BlockManager
15/06/03 16:20:48 INFO storage.BlockManagerInfo:Registering block manager hadoop26:44880 with 294.9 MB RAM
15/06/03 16:20:48 INFO storage.BlockManagerMaster:Registered BlockManager
15/06/03 16:20:48 INFO spark.HttpServer: StartingHTTP Server
15/06/03 16:20:48 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 16:20:48 INFO server.AbstractConnector:Started [email protected]:51278
15/06/03 16:20:48 INFO broadcast.HttpBroadcast:Broadcast server started at http://192.168.100.26:51278
15/06/03 16:20:48 INFO spark.HttpFileServer: HTTPFile server directory is /tmp/spark-b977f7a1-6f79-4dd2-8f52-5d5ca31760ff
15/06/03 16:20:48 INFO spark.HttpServer: StartingHTTP Server
15/06/03 16:20:48 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 16:20:48 INFO server.AbstractConnector:Started [email protected]:52783
15/06/03 16:20:49 INFO server.Server:jetty-8.y.z-SNAPSHOT
15/06/03 16:20:49 INFO server.AbstractConnector:Started [email protected]:4040
15/06/03 16:20:49 INFO ui.SparkUI: Started SparkUIat http://hadoop26:4040
15/06/03 16:20:50 WARN util.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-javaclasses where applicable
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Connecting to master spark://hadoop59:7077...
15/06/03 16:20:50 INFO repl.SparkILoop: Createdspark context..
Spark context available as sc.
scala> 15/06/03 16:20:50 INFOcluster.SparkDeploySchedulerBackend: Connected to Spark cluster with app IDapp-20150603162045-0000
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor added: app-20150603162045-0000/0 onworker-20150603160313-hadoop27-46545 (hadoop27:46545) with 32 cores
15/06/03 16:20:50 INFOcluster.SparkDeploySchedulerBackend: Granted executor IDapp-20150603162045-0000/0 on hostPort hadoop27:46545 with 32 cores, 512.0 MBRAM
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor added: app-20150603162045-0000/1 onworker-20150603040313-hadoop28-49969 (hadoop28:49969) with 32 cores
15/06/03 16:20:50 INFOcluster.SparkDeploySchedulerBackend: Granted executor IDapp-20150603162045-0000/1 on hostPort hadoop28:49969 with 32 cores, 512.0 MBRAM
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor added: app-20150603162045-0000/2 onworker-20150603160313-hadoop26-50793 (hadoop26:50793) with 32 cores
15/06/03 16:20:50 INFOcluster.SparkDeploySchedulerBackend: Granted executor IDapp-20150603162045-0000/2 on hostPort hadoop26:50793 with 32 cores, 512.0 MBRAM
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor added: app-20150603162045-0000/3 onworker-20150603040313-hadoop29-48828 (hadoop29:48828) with 32 cores
15/06/03 16:20:50 INFOcluster.SparkDeploySchedulerBackend: Granted executor IDapp-20150603162045-0000/3 on hostPort hadoop29:48828 with 32 cores, 512.0 MBRAM
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor updated: app-20150603162045-0000/2 isnow RUNNING
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor updated: app-20150603162045-0000/1 isnow RUNNING
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor updated: app-20150603162045-0000/0 isnow RUNNING
15/06/03 16:20:50 INFOclient.AppClient$ClientActor: Executor updated: app-20150603162045-0000/3 isnow RUNNING
15/06/03 16:20:54 INFOcluster.SparkDeploySchedulerBackend: Registered executor:Actor[akka.tcp://sparkExecutor@hadoop28:42157/user/Executor#-861933305] with ID1
15/06/03 16:20:54 INFOcluster.SparkDeploySchedulerBackend: Registered executor:Actor[akka.tcp://sparkExecutor@hadoop27:50201/user/Executor#1323975925] with ID0
15/06/03 16:20:54 INFOcluster.SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@hadoop26:41332/user/Executor#-1729326393]with ID 2
15/06/03 16:20:54 INFOcluster.SparkDeploySchedulerBackend: Registered executor:Actor[akka.tcp://sparkExecutor@hadoop29:34534/user/Executor#-926579556] with ID3
15/06/03 16:20:54 INFO storage.BlockManagerInfo:Registering block manager hadoop28:53888 with 294.9 MB RAM
15/06/03 16:20:54 INFO storage.BlockManagerInfo:Registering block manager hadoop27:35299 with 294.9 MB RAM
15/06/03 16:20:54 INFO storage.BlockManagerInfo:Registering block manager hadoop26:36586 with 294.9 MB RAM
15/06/03 16:20:54 INFO storage.BlockManagerInfo:Registering block manager hadoop29:49336 with 294.9 MB RAM
scala> var file=sc.textFile("hdfs://mycluster/test/sparktest.txt")
15/06/03 16:24:07 INFO storage.MemoryStore:ensureFreeSpace(141094) called with curMem=0, maxMem=309225062
15/06/03 16:24:07 INFO storage.MemoryStore: Blockbroadcast_0 stored as values to memory (estimated size 137.8 KB, free 294.8 MB)
file: org.apache.spark.rdd.RDD[String] = MappedRDD[1]at textFile at
scala> var count=file.flatMap(line=>line.split("")).map(word=>(word,1)).reduceByKey(_+_)
15/06/03 16:26:16 INFO mapred.FileInputFormat:Total input paths to process : 1
count: org.apache.spark.rdd.RDD[(String, Int)] =MapPartitionsRDD[6] at reduceByKey at
scala> count.collect()
15/06/03 16:26:32 INFO spark.SparkContext: Startingjob: collect at
15/06/03 16:26:32 INFO scheduler.DAGScheduler:Registering RDD 4 (reduceByKey at
15/06/03 16:26:32 INFO scheduler.DAGScheduler: Gotjob 0 (collect at
15/06/03 16:26:32 INFO scheduler.DAGScheduler:Final stage: Stage 0(collect at
15/06/03 16:26:32 INFO scheduler.DAGScheduler:Parents of final stage: List(Stage 1)
15/06/03 16:26:32 INFO scheduler.DAGScheduler:Missing parents: List(Stage 1)
15/06/03 16:26:32 INFO scheduler.DAGScheduler:Submitting Stage 1 (MapPartitionsRDD[4] at reduceByKey at
15/06/03 16:26:32 INFO scheduler.DAGScheduler:Submitting 2 missing tasks from Stage 1 (MapPartitionsRDD[4] at reduceByKey at
15/06/03 16:26:32 INFO scheduler.TaskSchedulerImpl:Adding task set 1.0 with 2 tasks
15/06/03 16:26:32 INFO scheduler.TaskSetManager:Starting task 1.0:0 as TID 0 on executor 1: hadoop28 (PROCESS_LOCAL)
15/06/03 16:26:32 INFO scheduler.TaskSetManager:Serialized task 1.0:0 as 2072 bytes in 4 ms
15/06/03 16:26:32 INFO scheduler.TaskSetManager:Starting task 1.0:1 as TID 1 on executor 2: hadoop26 (PROCESS_LOCAL)
15/06/03 16:26:32 INFO scheduler.TaskSetManager:Serialized task 1.0:1 as 2072 bytes in 1 ms
15/06/03 16:26:34 INFO scheduler.TaskSetManager:Finished TID 1 in 1767 ms on hadoop26 (progress: 1/2)
15/06/03 16:26:34 INFO scheduler.DAGScheduler:Completed ShuffleMapTask(1, 1)
15/06/03 16:26:34 INFO scheduler.TaskSetManager:Finished TID 0 in 1834 ms on hadoop28 (progress: 2/2)
15/06/03 16:26:34 INFO scheduler.DAGScheduler:Completed ShuffleMapTask(1, 0)
15/06/03 16:26:34 INFO scheduler.TaskSchedulerImpl:Removed TaskSet 1.0, whose tasks have all completed, from pool
15/06/03 16:26:34 INFO scheduler.DAGScheduler:Stage 1 (reduceByKey at
15/06/03 16:26:34 INFO scheduler.DAGScheduler:looking for newly runnable stages
15/06/03 16:26:34 INFO scheduler.DAGScheduler:running: Set()
15/06/03 16:26:34 INFO scheduler.DAGScheduler:waiting: Set(Stage 0)
15/06/03 16:26:34 INFO scheduler.DAGScheduler:failed: Set()
15/06/03 16:26:34 INFO scheduler.DAGScheduler:Missing parents for Stage 0: List()
15/06/03 16:26:34 INFO scheduler.DAGScheduler:Submitting Stage 0 (MapPartitionsRDD[6] at reduceByKey at
15/06/03 16:26:34 INFO scheduler.DAGScheduler:Submitting 2 missing tasks from Stage 0 (MapPartitionsRDD[6] at reduceByKey at
15/06/03 16:26:34 INFO scheduler.TaskSchedulerImpl:Adding task set 0.0 with 2 tasks
15/06/03 16:26:34 INFO scheduler.TaskSetManager:Starting task 0.0:0 as TID 2 on executor 1: hadoop28 (PROCESS_LOCAL)
15/06/03 16:26:34 INFO scheduler.TaskSetManager:Serialized task 0.0:0 as 1949 bytes in 0 ms
15/06/03 16:26:34 INFO scheduler.TaskSetManager:Starting task 0.0:1 as TID 3 on executor 0: hadoop27 (PROCESS_LOCAL)
15/06/03 16:26:34 INFO scheduler.TaskSetManager:Serialized task 0.0:1 as 1949 bytes in 0 ms
15/06/03 16:26:34 INFOspark.MapOutputTrackerMasterActor: Asked to send map output locations forshuffle 0 to spark@hadoop28:60418
15/06/03 16:26:34 INFO spark.MapOutputTrackerMaster:Size of output statuses for shuffle 0 is 148 bytes
15/06/03 16:26:34 INFO scheduler.DAGScheduler:Completed ResultTask(0, 0)
15/06/03 16:26:34 INFO scheduler.TaskSetManager:Finished TID 2 in 215 ms on hadoop28 (progress: 1/2)
15/06/03 16:26:34 INFOspark.MapOutputTrackerMasterActor: Asked to send map output locations forshuffle 0 to spark@hadoop27:59541
15/06/03 16:26:35 INFO scheduler.DAGScheduler:Completed ResultTask(0, 1)
15/06/03 16:26:35 INFO scheduler.TaskSetManager:Finished TID 3 in 818 ms on hadoop27 (progress: 2/2)
15/06/03 16:26:35 INFO scheduler.TaskSchedulerImpl:Removed TaskSet 0.0, whose tasks have all completed, from pool
15/06/03 16:26:35 INFO scheduler.DAGScheduler:Stage 0 (collect at
15/06/03 16:26:35 INFO spark.SparkContext: Jobfinished: collect at
res0: Array[(String, Int)]= Array((is,1), (am,3), (love,1), (hello,2), (testing,2), (world,1), (spark,1),(hadoop,5), (studying,1), (i,4), (good,1))
scala> :quit
上面就是计算结果,统计单词的个数