【小家Spring】Spring-jdbc的使用以及Spring事务管理的8种方式介绍(声明式事务+编程式事务)
每篇一句
代码首先是给人看的,然后才是给计算机读的
前言
前面已经讲述了Spring Aop的原理以及源码分析~
若对Spring AOP还不是太了解的话,强烈建议出门左拐,先掌握AOP相关内容,因为Spring的事务管理就是基于Spring AOP实现的
本文主要讲解Spring-JDBC的使用以及它对事务的管理。
主要分为两大块:
- Spring对jdbc的支持
- Spring对事务的支持
源码展示基于Spring版本号为:5.1.6.RELEASE 下同下同下同
源码展示基于Spring版本号为:5.1.6.RELEASE 下同下同下同
源码展示基于Spring版本号为:5.1.6.RELEASE 下同下同下同
环境准备
Pom里导入相关jar(基于之前的工程基础上导包):
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-jdbcartifactId>
<version>${spring.framework.version}version>
dependency>
配置文件:
@Configuration
public class JdbcConfig {
// 此处只是为了演示 所以不用连接池了===========生产环境禁止这么使用==========
@Bean
public DataSource dataSource() {
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUser("root");
dataSource.setPassword("root");
dataSource.setURL("jdbc:mysql://localhost:3306/jedi");
return dataSource;
}
//// 为了执行sql方便 此处采用JdbcTemplate进行===========
// 生产环境一下一般我们不需要此配置,因为一般我们会使用ORM框架~
// 但是如果是SpringBoot,这两个类默认都会配置上(导入了Spring-JDBC的jar即可) 比如MyBatis就是基于JDBC的
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean
public NamedParameterJdbcTemplate namedParameterJdbcTemplate(DataSource dataSource) {
return new NamedParameterJdbcTemplate(dataSource);
}
}
测试连接是否通畅:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = {RootConfig.class, JdbcConfig.class})
public class TestSpringBean {
@Autowired
private DataSource dataSource;
@Test
public void test1() throws SQLException {
System.out.println(dataSource); // com.mysql.jdbc.jdbc2.optional.MysqlDataSource@650eab8
System.out.println(dataSource.getConnection()); // com.mysql.jdbc.JDBC4Connection@72bc6553
System.out.println(jdbcTemplate); //org.springframework.jdbc.core.JdbcTemplate@66982506
System.out.println(namedParameterJdbcTemplate); //org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate@70cf32e3
}
}
Spring JDBC
为了使JDBC更加易于使用,Spring 在 JDBC API 上定义了一个抽象层,以此建立一个 JDBC 存取框架
说明:
在实际开发中,我们DAO层一般都会使用ORM框架(Mybatis,hibernate)等。在有些特殊的情况下,ORM框架的搭建略显笨重(比如下面我们演示Spring事务的时候)。这时最好的选择就是Spring中的jdbcTemplate了
JdbcTemplate和NamedParameterJdbcTemplate
jdbcTemplate提供的主要方法
- execute方法:可以用于执行任何SQL语句,一般用于执行DDL语句;
- update方法及batchUpdate方法:update方法用于执行新增、修改、删除等语句;batchUpdate方法用于执行批处理相关语句;
- query方法及queryForXXX方法:用于执行查询相关语句;
- call方法:用于执行存储过程、函数相关语句
Demo:
@Test
public void test1() throws SQLException {
String sql = "select * from user where id = ?";
// 默认情况下:它就是使用的PreparedStatement,所以不用担心Sql注入问题的
RowMapper<User> rowMapper = new BeanPropertyRowMapper<>(User.class);
List<User> list = jdbcTemplate.query(sql, rowMapper, 1);
User user = jdbcTemplate.queryForObject(sql, rowMapper, 1);
System.out.println(list);
System.out.println(user);
}
NamedParameterJdbcTemplate提供的主要方法
在经典的 JDBC 用法中, SQL 参数是用占位符 ? 表示,并且受到位置的限制. 定位参数的问题在于, 一旦参数的顺序发生变化, 就必须改变参数绑定,否则就绑定错了
在 Spring JDBC 框架中, 绑定 SQL 参数的另一种选择是使用具名参数(named parameter).
具名参数: SQL 按名称(以冒号开头)而不是按位置进行指定. 具名参数更易于维护, 也提升了可读性. 具名参数由框架类在运行时用占位符取代
NamedParameterJdbcTemplate:是Spring2.0提供的,比JdbcTemplate出现得晚。它可以使用全部jdbcTemplate方法
// @since 2.0
public class NamedParameterJdbcTemplate implements NamedParameterJdbcOperations {
// 它持有一个JdbcTemplate的引用,所以它能够执行它所有的方法
private final JdbcOperations classicJdbcTemplate;
...
}
Demo Show:
@Test
public void test1() throws SQLException {
String sql = "insert into user (name,age) values (:name,:age)";
User u = new User();
u.setName("fsx2");
u.setAge(20);
SqlParameterSource sqlParameterSource = new BeanPropertySqlParameterSource(u);
// 不需要id使用这个方法
//namedParameterJdbcTemplate.update(sql,sqlParameterSource);
// 这个可议把id输出出来
KeyHolder keyHolder = new GeneratedKeyHolder();
namedParameterJdbcTemplate.update(sql, sqlParameterSource, keyHolder);
int k = keyHolder.getKey().intValue();
System.out.println(k); //2 id就为2
}
NamedParameterJdbcTemplate和JdbcTemplate有
KeyHolder类,使用它我们可以获得主键,类似Mybatis中的useGeneratedKeys。
因为整体上直接使用JdbcTemplate来操作数据库的可能性几乎没有,所以此处只做一个简单的介绍,重点是后面的Spring事务的讲解~~
Spring事务
事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
通常情况下,如果在事务中抛出了未检查异常(继承自 **RuntimeException** 的异常),则默认将回滚事务。如果没有抛出任何异常,或者抛出了已检查异常,则仍然提交事务。这通常也是大多数开发者希望的处理方式,也是 EJB 中的默认处理方式
事务(Transaction)是并发控制的单位,是用户定义的一个操作序列。这些操作要么都做,要么都不做,是一个不可分割的工作单位。
数据库向用户提供保存当前程序状态的方法,叫事务提交(commit);当事务执行过程中,使数据库忽略当前的状态并回到前面保存的状态的方法叫事务回滚(rollback)
Spring配置文件中关于事务配置总是由三个组成部分:
- DataSource
- TransactionManager
- 动态代理(核心内容)
DataSource、TransactionManager这两部分只是会根据数据访问方式有所变化。DataSource实际为SessionFactory,TransactionManager的实现为 HibernateTransactionManager(MyBatis还是使用的DataSourceTransactionManager)
Spring Framework对事务管理提供了一致的抽象,其特点如下:
- 为不同的事务API提供一致的编程模型,比如JTA(Java Transaction API), JDBC, Hibernate, JPA(Java Persistence API和JDO(Java Data Objects)
- 支持声明式事务管理,特别是基于注解的声明式事务管理,简单易用
- 提供比其他事务API如JTA更简单的编程式事务管理API
- 与spring数据访问抽象的完美集成
下面示例的事务管理器通知配置为:
@Configuration
public class JdbcConfig {
...
// ==============Spring事务相关配置~~~==================
// 必须配置一个事务管理器:此处用的DataSourceTransactionManager来管理事务~~~
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(dataSource);
return dataSourceTransactionManager;
}
...
}
业务类为:
public interface HelloService {
Object hello();
}
@Service
public class HelloServiceImpl implements HelloService {
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public Object hello() {
// 向数据库插入一条记录
String sql = "insert into user (name,age) values ('fsx',21)";
jdbcTemplate.update(sql);
// 做其余的事情 可能抛出异常
System.out.println(1 / 0);
return "service hello";
}
}
Spring事务管理方式(声明式+编程式)
声明式事务(5种方式)
Spring同时支持编程式事务策略和声明式事务策略,只是大部分时候,我们都推荐采用声明式事务策略。它有十分明显的优势:
1、声明式事务能大大降低开发者的代码书写量,而且声明式事务几乎不影响应用的代码。因此,不论底层事务策略如何变化,应用程序都无需任何改变
2、应用程序代码无需任何事务处理代码,可以更专注于业务逻辑的实现
3、Spring可对任何POJO的方法提供事务管理,而且Spring的声明式事务管理无需容器的支持,可在任何环境下使用(无需要要web容器的支持)
4、Spring可指定事务在遇到特定异常时自动回滚。Spring不仅可在代码中使用setRollbackOnly回滚事务,也可在配置文件中(或者注解中)配置回滚规则
5、*由于Spring采用AOP的方式管理事务,因此,可以在事务回滚动作中插入用户自己的动作,而不仅仅是执行系统默认的回滚(此点非常的强大~~~~)*
Spring声明式事务管理的方式也有多种,下面主要介绍几种情况的使用方式:
- 单独配置每个Bean的代理(使用
TransactionProxyFactoryBean)
在Spring1.X中,声明式事务使用TransactionProxyFactoryBean来配置事务代理Bean。正如它的类名所暗示的,它是一个专门为目标Bean生成事务代理的工厂Bean。
既然TransactionProxyFactoryBean产生的是事务代理Bean,可见Spring的声明式事务策略是基于Spring AOP的。
// @since 21.08.2003 它出现的时间非常的早
public class TransactionProxyFactoryBean extends AbstractSingletonProxyFactoryBean implements BeanFactoryAware {
// 从内部可以看出来,它最终还是委托给TransactionInterceptor去管理事务的~~~
private final TransactionInterceptor transactionInterceptor = new TransactionInterceptor();
@Nullable
private Pointcut pointcut;
...
}
// 简单的说:它就是去生成的爱理对象的一个抽象实现。单例代理对象
// 它还有一个著名的实现类:`CacheProxyFactoryBean` 和 Cache相关的FactoryBean 不过他是从Spring3.1开始的
public abstract class AbstractSingletonProxyFactoryBean extends ProxyConfig
implements FactoryBean<Object>, BeanClassLoaderAware, InitializingBean {...}
示例配置如下(此处不使用XML配置,而使用Config类配置):
@Bean
public TransactionProxyFactoryBean transactionProxyFactoryBean(PlatformTransactionManager transactionManager) {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
// 设置事务管理器 去管理这个Bean的事务关系
transactionProxyFactoryBean.setTransactionManager(transactionManager);
// 设置目标对象
// 这里需要注意:这里设置了目标对象,你的HelloServiceImpl就不允许再交给Spring管理了 否则会有两个Bean,注入会报错的
transactionProxyFactoryBean.setTarget(new HelloServiceImpl());
// 设置事务相关的属性:transactionAttributes
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
return transactionProxyFactoryBean;
}
测试一把:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = {RootConfig.class, JdbcConfig.class})
public class TestSpringBean {
@Autowired
private HelloService helloService;
@Test
public void test1() {
System.out.println(helloService.getClass()); //class com.sun.proxy.$Proxy24
helloService.hello();
}
}
发现数据库里是没有插入记录的,从而我们就可以确定事务生效了。如果日志级别控为Debug,可以看到下面一句回滚日志:
17:49:22.002 [main] DEBUG o.s.j.d.DataSourceTransactionManager - Rolling back JDBC transaction on Connection [com.mysql.jdbc.JDBC4Connection@48f5bde6]
17:49:22.003 [main] DEBUG o.s.j.d.DataSourceTransactionManager - Releasing JDBC Connection [com.mysql.jdbc.JDBC4Connection@48f5bde6] after transaction
- 所有Bean共享一个代理基类
这其实是第一种方式的一种变体,只需要把需要代理的Bean继承自TransactionProxyFactoryBean,然后自己setTarget()一下。或者在设置一些通用属性了,类似如下:
// 此处transactionBase就是它:TransactionProxyFactoryBean,并且标记为 abstract="true"
<bean id="userDao" parent="transactionBase" >
<property name="target" ref="userDaoTarget" />
bean>
- 使用拦截器(AOP方式的直接使用)
// 配置一个事务的拦截器(相当于一个AOP的`环绕通知`)
@Bean
public TransactionInterceptor transactionInterceptor(PlatformTransactionManager transactionManager) {
TransactionInterceptor transactionProxyFactoryBean = new TransactionInterceptor();
// 设置事务管理器 去管理这个Bean的事务关系
transactionProxyFactoryBean.setTransactionManager(transactionManager);
// 设置事务相关的属性:transactionAttributes
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
return transactionProxyFactoryBean;
}
// 配置一个自动代理创建器 决定这个事务拦截器要作用于哪些Bean上
@Bean
public BeanNameAutoProxyCreator beanNameAutoProxyCreator() {
BeanNameAutoProxyCreator proxyCreator = new BeanNameAutoProxyCreator();
proxyCreator.setBeanNames("*ServiceImpl");
// 此处这个BeanName一定要对应上~~~~
proxyCreator.setInterceptorNames("transactionInterceptor");
return proxyCreator;
}
- 使用tx标签配置的拦截器
类似于xml的这种方式:
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED" />
tx:attributes>
tx:advice>
<aop:config>
<aop:pointcut id="interceptorPointCuts" expression="execution(* com.fsx.demo.*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="interceptorPointCuts" />
aop:config>
- 全注解
@Transactional(当下最常用的一种方式~~~)
该种方式也是今天要讲的一种主要的方式,下面会在详细讲述~
编程式事务(3种方式)
编程式事务使用TransactionTemplate或者直接使用底层的PlatformTransactionManager。对于编程式事务管理,spring推荐使用TransactionTemplate。
和编程式事务相比,声明式事务唯一不足地方是,它的最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别
但是即便有这样的需求,也存在很多变通的方法,比如,可以将需要进行事务管理的代码块独立为方法即可达到通用的效果
方式一:使用TransactionTemplate(推荐)
先配置一个TransactionTemplate这个Bean到容器~~
// 配置一个事务模版,用于编程式事务
// 这里面也可以通过构造函数传入一个TransactionDefinition接口的实例。表示事务的一些属性~~~~
@Bean
public TransactionTemplate transactionTemplate(PlatformTransactionManager transactionManager) {
TransactionTemplate transactionTemplate = new TransactionTemplate(transactionManager);
return transactionTemplate;
}
然后直接使用:
@Override
public Object hello() {
return transactionTemplate.execute(transactionStatus -> {
// 向数据库插入一条记录
String sql = "insert into user (name,age) values ('fsx',21)";
jdbcTemplate.update(sql);
// 做其余的事情 可能抛出异常
System.out.println(1 / 0);
return "service hello";
});
}
就这样,相当于里面的逻辑在事务里面执行。可以实现非常精细的控制了~~~~
// 继承自DefaultTransactionDefinition表示会有一个默认的事务属性~~~
public class TransactionTemplate extends DefaultTransactionDefinition
implements TransactionOperations, InitializingBean {
// 内部真正管理事务的,肯定还是PlatformTransactionManager
@Nullable
private PlatformTransactionManager transactionManager;
// 构造函数
public TransactionTemplate() {
}
public TransactionTemplate(PlatformTransactionManager transactionManager) {
this.transactionManager = transactionManager;
}
// 自己可以指定一个TransactionDefinition,覆盖默认的行为
public TransactionTemplate(PlatformTransactionManager transactionManager, TransactionDefinition transactionDefinition) {
super(transactionDefinition);
this.transactionManager = transactionManager;
}
// 真正给外面调用的,仅仅只有这一个方法而已~~~~用lambda来实现也非常的优雅~
@Override
@Nullable
public <T> T execute(TransactionCallback<T> action) throws TransactionException { ... }
...
}
方式二:使用PlatformTransactionManager
当然我们也可以操作底层的API,直接使用PlatformTransactionManager来自己管理事务~~~
@Autowired
private PlatformTransactionManager transactionManager;
@Override
public Object hello() {
// 构造一个准备使用此事务的定义信息~~~
DefaultTransactionDefinition transactionDefinition = new DefaultTransactionDefinition();
transactionDefinition.setReadOnly(false);
//隔离级别,-1表示使用数据库默认级别
transactionDefinition.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);
transactionDefinition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
// 根据此事务属性,拿到一个事务实例 注意此处的入参是一个:TransactionDefinition
TransactionStatus transaction = transactionManager.getTransaction(transactionDefinition);
try {
// =================做你的逻辑start 必须try住,但无需写finally=======================
// 向数据库插入一条记录
String sql = "insert into user (name,age) values ('fsx',21)";
jdbcTemplate.update(sql);
// 做其余的事情 可能抛出异常
System.out.println(1 / 0);
// =================做你的逻辑start=======================
// 提交事务
transactionManager.commit(transaction);
} catch (Exception e) {
// 若发现异常 事务进行回滚
transactionManager.rollback(transaction);
throw e;
}
return "service hello";
}
这样也实现了事务的控制。优点是更精细,缺点是侵入性太强,且编码负责。
方式三:利用Connection或者SqlSession源生的方式
这个就更底层了,需要自己去管事务、finally里关链接等。这里就不详细介绍了~~~~
关于数据库事务的自动提交(AutoCommit)
默认情况下,数据库处于自动提交模式。每一条语句处于一个单独的事务中,在这条语句执行完毕时,如果执行成功则隐式的提交事务;执行失败则隐式的回滚事务
对于正常的事务管理,是一组相关的操作处于一个事务之中,因此必须关闭数据库的自动提交模式。不过,这个我们不用担心,spring会将底层连接的自动提交特性设置为false
具体代码在:org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin()方法里有这么一段代码:
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
...
// Switch to manual commit if necessary. This is very expensive in some JDBC drivers,
// so we don't want to do it unnecessarily (for example if we've explicitly
// configured the connection pool to set it already).
// 切换JDBC Connection到手动commit的模式~~~~~
if (con.getAutoCommit()) {
txObject.setMustRestoreAutoCommit(true);
if (logger.isDebugEnabled()) {
logger.debug("Switching JDBC Connection [" + con + "] to manual commit");
}
con.setAutoCommit(false);
}
}
@Override
protected void doCleanupAfterCompletion(Object transaction) {
...
// 处理完成后,又会把这个连接切回到自动模式~~~ 毕竟用的连接池,要把它的状态还原
if (txObject.isMustRestoreAutoCommit()) {
con.setAutoCommit(true);
}
}
可议很清晰的发现,如果有需要,Spring会将该链接切换到手动模式。
有些数据连接池提供了关闭事务自动提交的设置,
最好在设置连接池时就将其关闭。但C3P0没有提供这一特性,只能依靠spring来设置
TransactionDefinition介绍
上面讲到的事务管理器接口PlatformTransactionManager通过getTransaction(TransactionDefinition definition)方法来得到事务,这个方法里面的参数是TransactionDefinition,这个类就定义了一些基本的事务属性。
事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。事务属性包含了5个方面,如图所示:
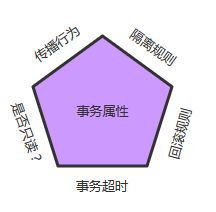
// 它的常用实现类为:DefaultTransactionDefinition
// TransactionAttribute接口也继承自此接口~~~
public interface TransactionDefinition {
// 7种类型的事务传播行为
int PROPAGATION_REQUIRED = 0; // 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。
int PROPAGATION_SUPPORTS = 1; //支持当前事务,如果当前没有事务,就以**非事务**方式执行
int PROPAGATION_MANDATORY = 2; //使用当前的事务,如果当前没有事务,就抛出异常
int PROPAGATION_REQUIRES_NEW = 3; //新建事务,如果当前存在事务,把当前事务挂起 ===== 这个也是使用较多的 相当于另起炉灶
int PROPAGATION_NOT_SUPPORTED = 4; //以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
int PROPAGATION_NEVER = 5; //以非事务方式执行,如果当前存在事务,则抛出异常
int PROPAGATION_NESTED = 6; //如果当前存在事务,则在嵌套事务(它是一个子事务,但他仍还是外部事务的一部分,外部事务提交了它才提交。。。注意和REQUIRES_NEW的区别~~~)内执行。
//如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作
// 4种:隔离级别
// PlatformTransactionManager的默认隔离级别(对大多数数据库来说就是ISOLATION_ READ_COMMITTED
// MySQL默认采用ISOLATION_REPEATABLE_READ,Oracle采用READ__COMMITTED级别
int ISOLATION_DEFAULT = -1;
//读未提交 最低的隔离级别。(事实上我们不应该称其为隔离级别) 可能导致脏,幻,不可重复读
int ISOLATION_READ_UNCOMMITTED = Connection.TRANSACTION_READ_UNCOMMITTED;
// 读已提交,大多数数据库的默认级别。可防止脏读,但幻读和不可重复读仍可以发生。
int ISOLATION_READ_COMMITTED = Connection.TRANSACTION_READ_COMMITTED;
// 可重复读。该隔离级别确保如果在事务中查询了某个数据集,你至少还能再次查询到相同的数据集,即使其他事务修改了所查询的数据。
// 可防止脏读,不可重复读,但幻读仍可能发生。
int ISOLATION_REPEATABLE_READ = Connection.TRANSACTION_REPEATABLE_READ;
// 序列化。代价最大、可靠性最高的隔离级别 所有的事务都是按顺序一个接一个地执行。避免所有不安全读取。
int ISOLATION_SERIALIZABLE = Connection.TRANSACTION_SERIALIZABLE;
// 默认的超时时间 -1表示不超时(单位是秒)
// 如果超过该时间限制但事务还没有完成,则自动回滚事务
int TIMEOUT_DEFAULT = -1;
int getPropagationBehavior(); //返回事务的传播行为(一共7种)
int getIsolationLevel(); // 返回事务的隔离级别。 事务管理器根据它来控制另外一个事务可以看到本事务内的哪些数据
int getTimeout(); // 返回超时时间(事务必须在多少秒内完成)
boolean isReadOnly(); // 事务是否只读(事务管理器能够根据这个返回值进行优化,确保事务是只读的)
@Nullable
String getName(); // 事务的名字 可以为null
}
事务四大特性:ACID
Atomicity(原子性):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用。Consistency(一致性):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。Isolation(隔离性):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏Durability(持久性):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中。
CAP:Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)
BASE理论:Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的缩写
在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起
附:Spring容器内事务相关Bean的截图
bean定义信息截图:((BeanDefinitionRegistry) (beanFactory)).getBeanDefinitionNames();
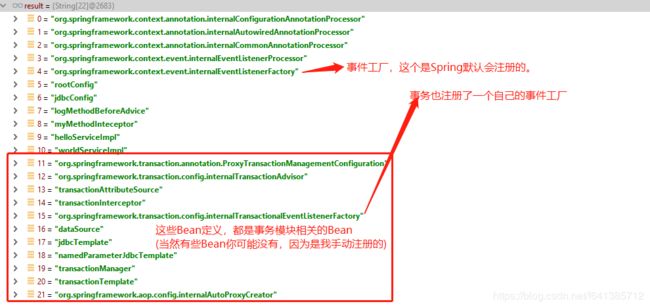
单例Bean截图:((SingletonBeanRegistry) beanFactory).getSingletonNames();
事务相关的新增的Bean同上,此处截图省略(因为都会以Bean定义信息形式注入)~
总结
Spring中的事务管理可以说是Spring Frameowork非常非常重要的一部分内容,它极大的简化了开发者对事务的管理,并且采用声明式,非侵入式的方式去管理事务,让一个简单的POJO就能够很方便的进行事务管理,可谓使用门槛非常非常低了
但是任何东西都是相对的,方便的同时更多的是屏蔽了实现。因此对于Spring事务管理的原理、认知还任重道远,还会继续~~~
知识交流

若群二维码失效,请加微信号(或者扫描下方二维码):fsx641385712。
并且备注:“java入群” 字样,会手动邀请入群
