spring boot 2.1学习笔记【十八】reactor3 响应式编程
springboot系列学习笔记全部文章请移步值博主专栏**: spring boot 2.X/spring cloud Greenwich。
由于是一系列文章,所以后面的文章可能会使用到前面文章的项目。springboot系列代码全部上传至GitHub:https://github.com/liubenlong/springboot2_demo
本系列环境:Java11;springboot 2.1.1.RELEASE;springcloud Greenwich.RELEASE;MySQL 8.0.5;
文章目录
- 搭建项目
- Flux与Mono
- 测试Flux和Mono,简单输出
- map和filter
- flatMap
- 异常
- StepVerifier单元测试
- Flux.interval 无限流
- zip压缩: 一对一合并数据流
- Schedulers线程池
- 切换调度器
- 异常处理
- 直接中断输出
- onErrorReturn提供缺省值
- onErrorResume
- onErrorMap捕获异常
- 捕获异常,不做处理
- doFinally
- 背压
- 总结
本文介绍reactor响应式编程风格。spring 5 响应式编程底层默认首选就是reactor ,所以很有必要学习一下。
Reactor 用于创建高效的响应式系统。Reactor 是一个用于JVM的完全非阻塞的响应式编程框架,具备高效的需求管理(即对 “背压(backpressure)”的控制)能力。它与 Java 8 函数式 API 直接集成,比如 CompletableFuture, Stream, 以及 Duration。它提供了异步序列 API Flux(用于[N]个元素)和 Mono(用于 [0|1]个元素),并完全遵循和实现了“响应式扩展规范”(Reactive Extensions Specification)。
Reactor 的 reactor-ipc 组件还支持非阻塞的进程间通信(inter-process communication, IPC)。 Reactor IPC 为 HTTP(包括 Websockets)、TCP 和 UDP 提供了支持背压的网络引擎,从而适合 应用于微服务架构。并且完整支持响应式编解码(reactive encoding and decoding)。
官网地址:project reactor
官网文档:Reactor 3 Reference Guide
搭建项目
引入依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-dependenciesartifactId>
<version>2.1.1.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
<dependency>
<groupId>io.projectreactorgroupId>
<artifactId>reactor-bomartifactId>
<version>Bismuth-RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>io.projectreactorgroupId>
<artifactId>reactor-coreartifactId>
dependency>
<dependency>
<groupId>io.projectreactorgroupId>
<artifactId>reactor-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.4version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.testnggroupId>
<artifactId>testngartifactId>
<version>6.8.7version>
<scope>testscope>
dependency>
dependencies>
编写个main方法
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
项目搭建完成。这里我们只写test方进行测试。
Flux与Mono
flux是一个能够发出 0 到 N 个元素的标准的 Publisher,它会被一个“错误(error)” 或“完成(completion)”信号终止。
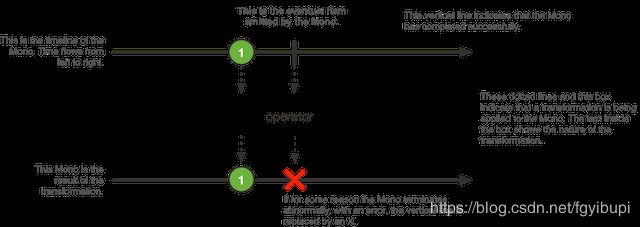
Mono 是一种特殊的 Publisher, 它最多发出一个元素,然后终止于一个 onComplete 信号或一个 onError 信号。
Flux和Mono是“数据流”的发布者,都可以发出三种“数据信号”:元素值、错误信号、完成信号,错误信号和完成信号都是终止信号,完成信号用于告知下游订阅者该数据流正常结束,错误信号终止数据流的同时将错误传递给下游订阅者。
Flux:

Mono:
测试Flux和Mono,简单输出
@Test
public void test1() {
Flux.just(1, 2, 3, 4, 5, 6).subscribe(System.out::print);
System.out.println();
Flux.just(1, 2, 3, 4, 5, 6).subscribe(System.out::print, System.out::println, () -> System.out.println("Completed"));
Mono.just(100).subscribe(System.out::println);
}
执行结果
11:04:52.073 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
123456
123456Completed
100
map和filter
@Test
public void test4() {
Flux.fromIterable(Arrays.asList(1, 2, 3, 4, 5, 6))
.filter(i -> i % 2 == 0)//过滤
.map(i -> i * i)//与map reduce中的map类型,逐个元素计算
.subscribe(System.out::println);
}
输出结果
4
16
36
Flux.just(1, 2, 3, 4, 5, 6)仅仅声明了这个数据流,此时数据元素并未发出,只有subscribe()方法调用的时候才会触发数据流。订阅前什么都不会发生。
flatMap
/**
* flatMap操作可以将每个数据元素转换/映射为一个流,然后将这些流合并为一个大的数据流。
* 流的合并是异步无序的
*
* @throws InterruptedException
*/
@Test
public void test5() throws InterruptedException {
Flux.just("flux", "mono")
.flatMap(s -> Flux.fromArray(s.split("\\s*"))//java中的future可以用这个替换。比如多个请求合并,串行改并行
.delayElements(Duration.ofMillis(100)))
.subscribe(System.out::println);
TimeUnit.SECONDS.sleep(1);//主线程阻塞1秒,因为是异步的,如果不阻塞则会等不到上面处理结果程序就结束了
}
输出结果
f
m
l
o
u
n
x
o
如果一个服务中需要调用多个独立的外部服务,然后组装结果返回。这种情况过去通常使用future,学习了reactor以后就可以使用flux的flatMap方法来实现了。
异常
@Test
public void test2() {
Mono.error(new Exception("my error")).subscribe(
System.out::print,
System.out::println,
() -> System.out.println("Completed"));
}
输出java.lang.Exception: my error
StepVerifier单元测试
响应式异步编程最麻烦的就是调试了。这里简单介绍一下使用StepVerifier进单元行测试。
@Test
public void testViaStepVerifier() {
StepVerifier.create(Flux.just(1, 2, 3, 4, 5, 6))
.expectNext(1, 2, 3, 4, 5, 6)//下一个期望的数据元素
.expectComplete()//测试下一个元素是否为完成信号
.verify();
StepVerifier.create(Mono.error(new Exception("some error")))
.expectErrorMessage("some error")//校验下一个元素是否为错误信号
.verify();
}
Flux.interval 无限流
Flux.interval(Duration) 生成的是一个 Flux, 是一个无限地周期性发出规律 tick 的时钟序列。
@Test
public void test7() throws InterruptedException {
Flux.interval(Duration.ofSeconds(1))
.map(aLong -> "a" + aLong) // 类似于map reduce 中的map,对flux发出的消息逐个处理
.subscribe(System.out::println);
TimeUnit.SECONDS.sleep(10);
}
这里设置了每隔1秒生成一个Long数据。由于这里sleep了10秒,所以会输出a0-a9。
zip压缩: 一对一合并数据流
@Test
public void testSimpleOperators() throws InterruptedException {
String desc = "zip: 将多个流一对一的合并起来";
// 使用这个来控制程序结束,替换之前的sleep操作
CountDownLatch countDownLatch = new CountDownLatch(1);
Flux.zip(
Flux.fromArray(desc.split("\\s+")),
// 使用Flux.interval声明一个每1000ms发出一个元素的long数据流;因为zip操作是一对一的,故而将其与字符串流zip之后,字符串流也将具有同样的速度;
Flux.interval(Duration.ofMillis(1000)))
// zip之后的流中元素类型为Tuple2,使用getT1方法拿到字符串流的元素
.subscribe(t -> System.out.println(t.getT1() + " " + t.getT2()), null, countDownLatch::countDown);
countDownLatch.await(); // 5
}
输出
Reactor 0
is 1
a 2
fully 3
non-blocking 4
reactive 5
//省略后续输出
使用zip将连个输出流进行压缩,一对一的组装成新的数据流。由于其中一个数据流树一秒发送一个,所以合并后的数据流也具有了相同的速度。
Schedulers线程池
Reactor, 就像 RxJava,也可以被认为是 并发无关(concurrency agnostic) 的。意思就是, 它并不强制要求任何并发模型。更进一步,它将选择权交给开发者。不过,它还是提供了一些方便 进行并发执行的库。
在 Reactor 中,执行模式以及执行过程取决于所使用的 Scheduler。 Scheduler 是一个拥有广泛实现类的抽象接口。 Schedulers 类提供的静态方法用于达成如下的执行环境:
当前线程(Schedulers.immediate())
可重用的单线程(Schedulers.single())。注意,这个方法对所有调用者都提供同一个线程来使用, 直到该调度器(Scheduler)被废弃。如果你想使用专一的线程,就对每一个调用使用 Schedulers.newSingle()。
弹性线程池(Schedulers.elastic()。它根据需要创建一个线程池,重用空闲线程。线程池如果空闲时间过长 (默认为 60s)就会被废弃。对于 I/O 阻塞的场景比较适用。 Schedulers.elastic() 能够方便地给一个阻塞 的任务分配它自己的线程,从而不会妨碍其他任务和资源,见 如何包装一个同步阻塞的调用?。
固定大小线程池(Schedulers.parallel())。所创建线程池的大小与 CPU 个数等同。
使用Schedulers将同步阻塞的getStringSync方法提交到异步线程池中执行:
/**
* Schedulers线程池
*
* @return
*/
private String getStringSync() {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Hello, Reactor!";
}
@Test
public void testSyncToAsync() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Mono.fromCallable(() -> getStringSync()) // 声明一个异步回调的mono
.subscribeOn(Schedulers.elastic()) // 将任务提交到内置的弹性线程池中执行
.subscribe(System.out::println, null, countDownLatch::countDown);
countDownLatch.await();
}
切换调度器
Reactor 提供了两种在响应式链中调整调度器 Scheduler的方法:publishOn和subscribeOn。它们都接受一个 Scheduler作为参数,从而可以改变调度器。
但是两者的作用范围是不同的,具体情况代码注释:
/**
* 切换调度器的操作符
*
* publishOn会影响链中其后的操作符,比如第一个publishOn调整调度器为elastic,则filter的处理操作是在弹性线程池中执行的;
* 同理,flatMap是执行在固定大小的parallel线程池中的;
* subscribeOn无论出现在什么位置,都只影响源头的执行环境,也就是range方法是执行在单线程中的,
* 直至被第一个publishOn切换调度器之前,所以range后的map也在单线程中执行。
*
* @throws InterruptedException
*/
@Test
public void test6() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Flux.range(1, 1000)
.map(i -> i * i)
.publishOn(Schedulers.elastic()).filter(i -> i % 2 == 0)
.publishOn(Schedulers.parallel()).flatMap(i -> Flux.just(i).delayElements(Duration.ofMillis(1000)))
.subscribeOn(Schedulers.single())
.subscribe(System.out::println, null, countDownLatch::countDown);
countDownLatch.await();
}
异常处理
直接中断输出
/**
* 异常处理
* 错误和完成两个都是终止符,不可同时存在
*/
@Test
public void testErrorHandling() {
Flux.range(1, 6)
.map(i -> 10 / (i - 3)) // 1
.map(i -> i * i)
.subscribe(System.out::println, System.err::println, () -> System.err.println("ok"));
}
输出:
25
100
java.lang.ArithmeticException: / by zero
错误和完成两个都是终止符,不可同时存在
onErrorReturn提供缺省值
onErrorReturn方法能够在收到错误信号的时候提供一个缺省值。此时终止信号不是error,而是complete
@Test
public void testErrorHandling1() {
Flux.range(1, 6)
.map(i -> 10 / (i - 3)) // 1
.onErrorReturn(0)
.map(i -> i * i)
.subscribe(System.out::println, System.err::println, () -> System.err.println("ok"));
}
输出
25
100
0 //这个是出错后的缺省值
ok //终止信号编程了complete!!
onErrorResume
onErrorResume:在收到错误信号的时候提供一个新的数据流。
可用于fallback处理, 类似于hystrix的fallback。或者类似于读取不到缓存则读取DB。
@Test
public void testErrorHandling2() {
Flux.range(1, 6)
.map(i -> 10 / (i - 3))
.onErrorResume(e -> Mono.just(new Random().nextInt(6))) // 提供新的数据流
.map(i -> i * i)
.subscribe(System.out::println, System.err::println, () -> System.err.println("ok"));
}
输出
25
100
25 //这个是新的数据源,或者说重新执行错误信号
ok //这里终止信号是complete
onErrorMap捕获异常
onErrorMap可以捕获异常,并再包装为某一个业务相关的异常,然后再抛出业务异常
public Flux callExternalService(String str) {
return Flux.range(1, 6)
.map(i -> 10 / (i - 3)) // 1
.map(i -> i * i);
}
/**
* 捕获,并再包装为某一个业务相关的异常,然后再抛出业务异常
* @throws InterruptedException
*/
@Test
public void testErrorHandling3() throws InterruptedException {
Flux.just("a")
.flatMap(k -> callExternalService(k))
// 重新包装
.onErrorMap(original -> new Exception("business error"))
.subscribe(System.out::println, System.err::println, () -> System.err.println("ok"));
TimeUnit.SECONDS.sleep(2);
}
输出
25
100
java.lang.Exception: business error
捕获异常,不做处理
这里写一个捕获异常,记录错误日志,然后继续抛出的例子。
doOnXxx是只读的,对数据流不会造成影响
@Test
public void testErrorHandling4() {
Flux.range(1, 6)
.map(i -> 10 / (i - 3))
.doOnError(throwable -> log.error(throwable.getMessage()))
.map(i -> i * i)
.subscribe(System.out::println, System.err::println, () -> System.err.println("ok"));
}
输出
25
100
11:35:19.195 [main] ERROR helloworld.MyTest - / by zero //这个是log.error打印的
java.lang.ArithmeticException: / by zero
doFinally
doFinally在序列终止(无论是 onComplete、onError还是取消)的时候被执行
@Test
public void testErrorHandling5() {
Flux.range(1, 6)
.map(i -> 10 / (i - 3)) // 1
.map(i -> i * i)
.doFinally(type -> {//doFinally在序列终止(无论是 onComplete、onError还是取消)的时候被执行
if (type == SignalType.CANCEL) // 2
log.info("SignalType.CANCEL");
else if(type == SignalType.ON_ERROR)
log.info("SignalType.ON_ERROR");
})
.take(1)//能够在发出N个元素后取消流。
.subscribe(System.out::println, System.err::println, () -> System.err.println("ok"));
}
输出
25
11:37:05.735 [main] INFO helloworld.MyTest - SignalType.CANCEL
ok
背压
背压(backpressure) 具体来说即 消费者能够反向告知生产者生产内容的速度的能力
订阅者可以无限接受数据并让它的源头 “满负荷”推送所有的数据,也可以通过使用 request 机制来告知源头它一次最多能够处理 n 个元素
上游数据源可以根据下游处理的速度进行生产数据,其实是一种“推送+拉取”的混合模式。
我们通过BaseSubscriber来实现该功能。前面讲到的所有subscribe方法都最终会转换为subscribe(BaseSubscriber)来执行。hookOnSubscribe和hookOnNext方法时必须要重写的,保证至少获取一个上游发送的一条数据。hookOnSubscribe用来获取第一个元素,hookOnNext配合request来逐个获取剩下的元素。
/**
* 背压测试:
* BaseSubscriber 是顶层的抽象类,上面介绍的所有subscribe方法最终都会转化为 subscribe(BaseSubscriber)执行
* BaseSubscriber 最少要重写hookOnSubscribe和hookOnNext
*/
@Test
public void testBackpressure() {
Flux.range(1, 6)
.doOnRequest(n -> System.out.println("Request " + n + " values..."))
.subscribe(new BaseSubscriber<>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed and make a request...");
request(1); //发起第一个请求
}
@Override
protected void hookOnNext(Integer value) { // 逐个处理剩余请求
try {
TimeUnit.SECONDS.sleep(1); // 模拟耗时操作
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Get value [" + value + "]");
request(1); // 随着接收到新的值,我们继续以每次请求一个元素的节奏从源头请求值。 这是背压核心
}
});
}
输出
Subscribed and make a request...
Request 1 values...
Get value [1]
Request 1 values...
Get value [2]
Request 1 values...
Get value [3]
Request 1 values...
Get value [4]
Request 1 values...
Get value [5]
Request 1 values...
Get value [6]
Request 1 values...
总结
从命令式编程到响应式编程的切换并不是一件容易的事,需要一个适应的过程。不过相信你通过本节的了解和实操,已经可以体会到使用Reactor编程的一些特点:
- 相对于传统的基于回调和Future的异步开发方式,响应式编程更加具有可编排性和可读性,配合lambda表达式,代码更加简洁,处理逻辑的表达就像装配“流水线”,适用于对数据流的处理;
- 在订阅(subscribe)时才触发数据流,这种数据流叫做“冷”数据流,就像插座插上电器才会有电流一样,还有一种数据流不管是否有订阅者订阅它都会一直发出数据,称之为“热”数据流,Reactor中几乎都是“冷”数据流;
- 调度器对线程管理进行更高层次的抽象,使得我们可以非常容易地切换线程执行环境;
- 灵活的错误处理机制有利于编写健壮的程序;
- “回压”机制使得订阅者可以无限接受数据并让它的源头“满负荷”推送所有的数据,也可以通过使用request方法来告知源头它一次最多能够处理 n 个元素,从而将“推送”模式转换为“推送+拉取”混合的模式。
springboot系列学习笔记全部文章请移步值博主专栏**: spring boot 2.X/spring cloud Greenwich。
由于是一系列文章,所以后面的文章可能会使用到前面文章的项目。springboot系列代码全部上传至GitHub:https://github.com/liubenlong/springboot2_demo
本系列环境:Java11;springboot 2.1.1.RELEASE;springcloud Greenwich.RELEASE;MySQL 8.0.5;