python-个人贷款违约预测模型
本次案例的数据来源为天善智能的课程《数据科学实战-python篇》,把课程认认真真的学习了一遍,看完老师讲的,自己再结合自己的思路,做出来的程序。
一、数据分析目标
通过脱敏过的数据,从贷款表loans、权限分配表disp、客户信息表clients、交易表trans中对数据进行描述性统计,得出对建模有用的数据,建立预测模型,预测正处于贷款期间的人的违约的概率。
二、业务理解
预测,就是在事情发生之前所做的事,案例的事件是贷款,所以,预测模型中所用的数据,应该是贷款的时间点之前的一段时间的情况。是否会违约是Y,贷款之前的一些信息为X。
是否违约,要从两个方面看,能不能还和想不想还。能不能还,就要分析这个人在贷款前的经济状况,是否稳定,还有就是所贷款的金额与自身的收入之间的关系。
经济状况是否稳定,可以看账户余额的均值与方差,求出变异系数,每个人的账户金额都不一样,所以不能用均值来判断,只能用金额的变动系数来判断经济状况的稳定。
所贷款的金额远远高于自己的收入,就有可能最后还不上,所以,需要求出货存比与贷存比来判断。
还得求出收入支出比,有收入才能有钱还贷款。
对于想不想还,就是看这个人的性格了。数据中没有关于这些数据,只有关于借贷人所在地区的基本信息,通过所在地区的犯罪率等信息,来间接判断性格的大概。
对于模型的选择,案例的情况属于分类,所以选择选择分类模型,而案例的这种这种情况,对于预测的结果,是主观进行判断的,可以用逻辑回归。
三、数据整理
数据的还款状态3种情况,A代表已经还款的,B和D则是已经确定的违约用户,C是正处于贷款期,还未超出还款期限。所以对数据进行转换,A=0,B、D=1,C=2。
result_sta={'A':0,'B':1,'D':1,'C':2}
loans['result']=loans.status.map(result_sta)对数据中的日期需要转换格式,才能进行后续的计算。因为需要的数据是借贷人贷款之前的数据,所以需要对交易日期的与借贷日期进行计算,取交易日期小与借贷日期的。
loans['date']=pd.to_datetime(loans['date'])
trans['trans_date']=pd.to_datetime(trans['trans_date'])而对于观察期的时间区间选择,在这里,将区间定位1年,一般定位预测期的1~5倍。所以需要交易日期在贷款的前一年到贷款的一年区间内。
data1= data1[(data1['date']>data1['trans_date'])&(data1['trans_date']>data1['date']-datetime.timedelta(days=365))]一个人可以申请多个账户,一个账户可以有多个客户,但是,一个账户只有一个所有者,只有所有者才能申请贷款,所以选出每个账户的所有者。
data=data[data['type']=='所有者']对于每个账户的交易类型,有两种情况,‘借’代表支出,‘贷’代表收入,而收入和支出的格式为¥的形式,所以先用正则表达式去除非数字的数据,将收入和支出标准化,以进行后续的计算。
trans['balance2'] = trans['balance'].map(lambda x: int(re.sub("\D", "", x)))
trans['amount2'] = trans['amount'].map(lambda x: int( re.sub("\D", "", x)))四、特征计算与选取
变异系数的计算:先计算每个账户余额的平均值和方差,然后用方差/均值。
data2 = data1.groupby('account_id')['balance2'].agg([('avg_balance','mean'), ('std_balance','std')])
data2['cov_balance']=data2['std_balance']/data2['avg_balance']#生活状况是否稳定收入支出比的计算:先计算出每个账户的收入和支出,然后用收入/支出。
type_sta={'贷':'in','借':'out'}
data1['type_re']=data1.type.map(type_sta)
data2['in']=data1[data1['type_re']=='in'].groupby(['account_id'])['amount2'].sum()
data2['out']=data1[data1['type_re']=='out'].groupby(['account_id'])['amount2'].sum()
data2['out_in']=data2['out']/data2['in']对于有些没有支出或收入的,则用0代替。
货存比与贷存比的计算:
data['lb']=data['amount']/data['avg_balance']
data['dr']=data['amount']/data['in']#欲望是否大于能力data=data[[ 'result','amount','district_id', 'avg_balance', 'std_balance', 'cov_balance', 'in', 'out', 'out_in', 'lb', 'dr']]五、模型的建立和评估
用于预测模型的训练集和测试集都是从A和BD中选取的,而C是最后模型用于预测的。
训练集随机选取几何的0.7,测试集为0.3。
data_model=data[data.result!=2]
for_predict=data[data.result==2]
train = data_model.sample(frac=0.7, random_state=1235).copy()
test = data_model[~ data_model.index.isin(train.index)].copy()
print(' 训练集样本量: %i \n 测试集样本量: %i' %(len(train), len(test)))模型选取的是逻辑回归。
from sklearn.linear_model.logistic import LogisticRegression
classifer = LogisticRegression()
classifer.fit(train.iloc[:,1:],train.iloc[:,0])本次模型的评估用的是ROC曲线,最后的曲线为:
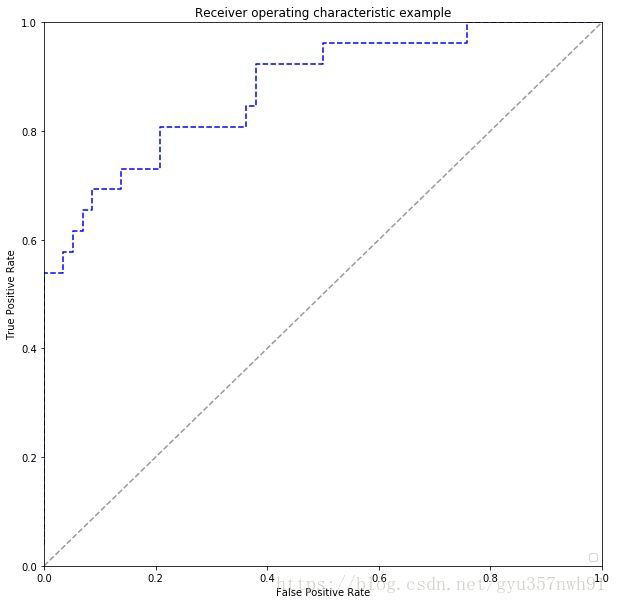
求得的AUC为0.8780