【文本信息抽取与结构化】深入了解关系抽取你需要知道的东西
常常在想,自然语言处理到底在做的是一件什么样的事情?到目前为止,我所接触到的NLP其实都是在做一件事情,即将自然语言转化为一种计算机能够理解的形式。这一点在知识图谱、信息抽取、文本摘要这些任务中格外明显。不同的任务的差异在于目标的转化形式不一样,因而不同的任务难度、处理方式存在差异。
这个系列文章【文本信息抽取与结构化】,在自然语言处理中是非常有用和有难度的技术,是文本处理与知识提取不可或缺的技术。
本篇介绍如何从文本中抽取出两个或者多个实体之间的关系,即关系抽取。
作者&编辑 | 小Dream哥
关系抽取概述
在前面的文章中,我们介绍了将文本结构化的大致过程以及信息抽取的、涉及到的技术,却没有介绍具体的技术细节。接下来我们来全面而细致的介绍相应的技术,今天我们关注关系抽取。
所谓关系抽取,就是抽取文本中两个或者多个实体之间的关系。例如:
中国的首都是北京
关系抽取即是从上述文本中,抽取出如下的实体关系的任务:
<中国,首都,北京>
关系抽取的方法大概有以下几类:
1.基于模板的方法
基于规则
基于依存句法
2.监督学习
机器学习
深度学习(pipline vs joint model)
3.半监督/无监督学习
Bootstrapping
Distant supervision
Unsupervised learning from web
下面我们一一来介绍这些方法。
基于模板的方法
1)基于自定义规则
通常来说,在语义上,表达两种实体的关系都有一些特定的说法,例如刚才的例子,描述国家和首都通常都会有这样的模式:
<国家>的首都/首付是<首都>
因此,基于自定义规则的方法,可以总结某类关系常用的说法,然后基于这些说法提炼出规则/正则表达式来进行关系抽取。
2)基于NER标签
很多时候,特定的关系是在某些特定的实体之间,例如:
1.首都(国家,城市)
2.创作(歌手,歌曲)
3.写作(作家,小说)
结合NER标签与具体的规则,常常能够取得不错的关系抽取效果。
此外,基于句法关系等模板的方法,这里不再详述。基于规则的方法有如下的优缺点:
优点:
1.准确率高
2.可以为特定领域定制
3.启动快,可以在小规模数据集上实现
缺点:
1.召回率低
2.特定领域的规则通常需要专家构建
3.难以维护
4.可移植性差
2 监督学习方法
1)传统机器学习
传统机器学习进行关系提取通常基于一些分类模型,包括朴素贝叶斯,SVM等。为了提高效率,通常会训练两个分类器,第一个分类器是1/0分类,判断命名实体间是否有关系;第二个分类器是多分类器,第一个分类器判断有关系再输入到这个分类器,预测关系的类别。这样做能够先排除大多数的实体对,进而加快分类器的训练过程。
基于传统机器学习方法的标准流程是:
1.预先定义好想提取的关系集合
2.定义或选择相关的命名实体集合
3.寻找并标注数据
4.选择有代表性的语料库
5.命名实体标记
6.实体间的关系标注
7.分词训练、测试、验证集
8.涉及特征
9.选择并训练分类器
10.评估结果
目前,用于关系抽取最多也是最有效的监督学习是深度学习的方法,所以这里就不多介绍机器学习相关的算法,我们来着重介绍深度学习的算法。
2)深度学习的方法
基于深度学习的关系抽取目前主要有两种方法:Pipline Method和Joint Method。
Pipline Method,流水线方法:输入一个句子,首先进行命名实体识别,然后对识别出来的实体进行两两组合,再进行关系分类。

流水线的方法存在蛮大的缺点,例如:
1.错误传播,实体识别模块的错误会传播到后面的分类模块;
2.忽略了两个子任务之间存在的关系。例如前面“中国的首都是北京”的例子,如果存在“首都”关系,那么前一个实体必然是国家类别,后一个实体比如是城市类别。流水线的方法,忽略了这些信息;
3.产生了没必要的冗余信息,由于需要对识别出来的实体进行两两配对,然后再进行关系分类;那些没有关系的实体对就会产生多余的信息,提高错误率。
Joint Method,即联合抽取方法,则跟流水线的方法不同,基于流水线方法的诸多缺陷,Joint Method能够通过一个实体识别和关系分类的联合模型,直接得到有关系的实体三元组。
Joint Method主要分为两个流派,基于参数共享(Parameter Sharing)和基于标注策略(Tagging Policy)两类。
基于基于参数共享(Parameter Sharing)的联合抽取方法,可参考这一篇论文:
Suncong, Zheng, Yuexing, et al. Joint entity and relation extraction based on a hybrid neural network[J]. Neurocomputing, 2017.
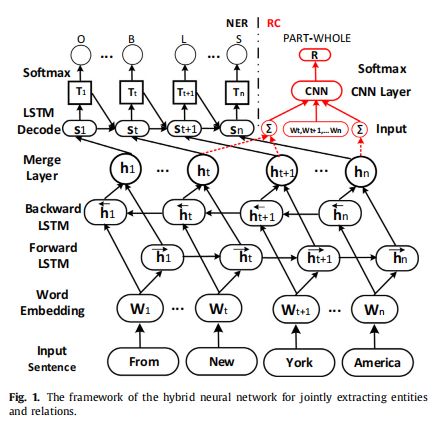
如上图所示,是这种方法的网络结构框图。每个词都会被映射到一个实体标记(BILOS:Begin Inside Last Outside Single),它包含了改字在实体中的位置信息。NER模块没有用CRF,而是额外用了一层LSTM来解码双向LSTM编码出来的Hidden state,并建模它和实体标记之间的关系。该模块的损失函数如下:
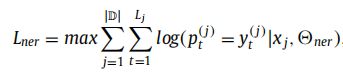

关系分类模块采用CNN模型,处理BiLSTM的Hidden state并输出关系类别。该模块的损失函数如下:
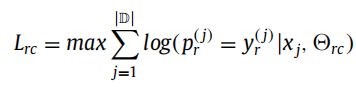
基于标注策略(Tagging Policy)的联合抽取方法,可参考这一篇论文:
S. Zheng, F. Wang, H. Bao, Y. Hao, P. Zhou, B. Xu, Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme, Acl. (2017).
在这篇论文中,将实体识别和关系分类两个问题,转化为一个序列标注的问题,然后通过一个端对端的神经网络模型直接得到关系实体三元组。
他们提出的这种新的标注策略主要由下图中三部分组成:
1)实体中词的位置信息{B(实体开始),I(实体内部),E(实体结尾),S(单个实体)};
2)关系类型信息{根据预先定义的关系类型进行编码};
3)实体角色信息{1(实体1),2(实体2)}。注意,这里只要不是实体关系三元组内的词全部标签都为"O"。

如上图所示,“B-CP-1"表示这个词是一个实体的begin,同时这个实体属于关系CP的第一个实体。
与典型的用LSTM进行实体抽取的模型差异在于,这个模型对损失做了一定的修改,如下图所示:

当标签为"O"时,就是正常的目标函数,当标签不是"O"时,即涉及到了关系实体标签,则通过α来增大标签的影响。实验结果表明,这个带偏置的目标函数能够更准确的预测实体关系对。
关于关系抽取的基本方法,到这里就介绍的差不多,希望读者能有所收获,下篇我们继续介绍最新的关系抽取模型。
总结
文本信息抽取与结构化是目前NLP中最为实际且效益最大的任务,熟悉这个任务是一个NLP算法工程师必需要做的事情。
读者们可以留言,或者加入我们的NLP群进行讨论。感兴趣的同学可以微信搜索jen104,备注"加入有三AI NLP群"。
下期预告:最新的关系抽取模型介绍
知识星球推荐

扫描上面的二维码,就可以加入我们的星球,助你成长为一名合格的自然语言处理算法工程师。
知识星球主要有以下内容:
(1) 聊天机器人;
(2) 知识图谱;
(3) NLP预训练模型。
转载文章请后台联系
侵权必究


往期精选
【完结】 12篇文章带你完全进入NLP领域,掌握核心技术
【年终总结】2019年有三AI NLP做了什么,明年要做什么?
【NLP-词向量】词向量的由来及本质
【NLP-词向量】从模型结构到损失函数详解word2vec
【NLP-NER】什么是命名实体识别?
【NLP-NER】命名实体识别中最常用的两种深度学习模型
【NLP-NER】如何使用BERT来做命名实体识别
【NLP-ChatBot】我们熟悉的聊天机器人都有哪几类?
【NLP-ChatBot】搜索引擎的最终形态之问答系统(FAQ)详述
【NLP-ChatBot】能干活的聊天机器人-对话系统概述
【知识图谱】人工智能技术最重要基础设施之一,知识图谱你该学习的东西
【知识图谱】知识表示:知识图谱如何表示结构化的知识?
【知识图谱】如何构建知识体系:知识图谱搭建的第一步
【知识图谱】获取到知识后,如何进行存储和便捷的检索?
【知识图谱】知识推理,知识图谱里最“人工智能”的一段
【文本信息抽取与结构化】目前NLP领域最有应用价值的子任务之一
【文本信息抽取与结构化】详聊文本的结构化【上】
【文本信息抽取与结构化】详聊文本的结构化【下】
【NLP实战】tensorflow词向量训练实战
【NLP实战系列】朴素贝叶斯文本分类实战
【NLP实战系列】Tensorflow命名实体识别实战
【NLP实战】如何基于Tensorflow搭建一个聊天机器人
【NLP实战】基于ALBERT的文本相似度计算
【每周NLP论文推荐】从预训练模型掌握NLP的基本发展脉络
【每周NLP论文推荐】 NLP中命名实体识别从机器学习到深度学习的代表性研究
【每周NLP论文推荐】 介绍语义匹配中的经典文章
【每周NLP论文推荐】 对话管理中的标志性论文介绍
【每周NLP论文推荐】 开发聊天机器人必读的重要论文
【每周NLP论文推荐】 掌握实体关系抽取必读的文章
【每周NLP论文推荐】 生成式聊天机器人论文介绍
【每周NLP论文推荐】 知识图谱重要论文介绍