【知识星球】图像生成玩腻了?视频生成技术何不来了解一下
欢迎大家来到《知识星球》专栏,近些年生成对抗网络技术发展的非常快,图像的生成可以达到以假乱真的效果,而视频生成则是图像生成应用的拓展,研究还非常不成熟,我们星球已经开始更新相关专栏。
作者&编辑 | 言有三
1 GAN与视频生成
视频生成不仅仅是要生成多张逼真的图像,而且要保证运动的连贯性,Video-GAN可以认为是图像生成鼻祖DCGAN的视频版。
有三AI知识星球-网络结构1000变
Video-GAN
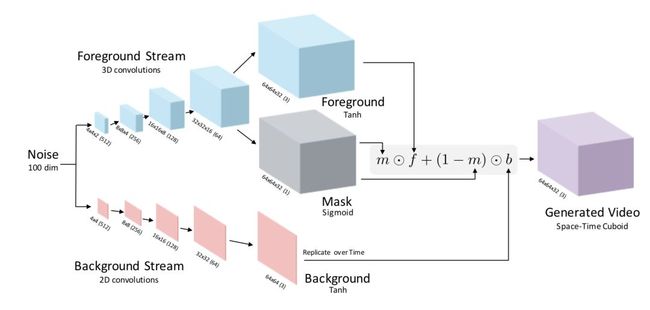
Video-GAN是一个视频生成GAN网络,它通过3D卷积从随机噪声中生成连续的视频帧。
作者/编辑 言有三
近些年生成对抗网络技术发展的非常快,图像的生成可以达到以假乱真的效果,而视频生成则是图像生成应用的拓展,拥有更高的难度,当前仍然处于发展早期。
这次介绍的Video-GAN是一个视频生成模型,它的输入是随机噪声,输出是视频。
为了简化问题,该框架不考虑相机本身的运动,因此背景是不会发生运动的,那么整个视频由静态的背景和动态的前景构成,因此论文设计了一个双路(two-stream)的架构来分别生成背景(Background)前景(Foreground),整个架构如上图所示。
因为背景是静态的,所以它是一个2D卷积组成的生成网络,输入为4*4特征,输出64*64的图像。而前景是动态的,所以它是一个3D卷积组成的生成网络,输入为4*4*2特征,输出64*64*32的视频,包括了32帧图像。生成器都采用了与DCGAN中的生成器相同的架构。
前景f(z)和背景b(z)融合的方式如下,即采用了一个掩膜m(z)进行线性融合。
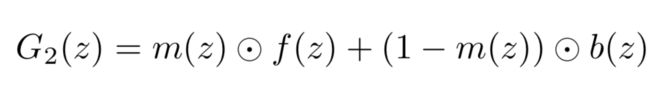
因此前景预测网络有一个分支,也输出64*64*32的视频,在网络训练完之后分别取出前背景可视化的结果如下,可知实现了前背景的分别生成。

以下展示了一些生成案例,可知道模型生成的视频质量虽然不高,但是运动比较逼真。

当然,整个模型也可以被用于做视频预测,通过在网络前端添加编码器将输入图转换为特征替换掉噪声向量,后续的模型结构不需要进行调整。
开源GitHub链接如下:https://github.com/cvondrick/videogan,读者可以自行验证。
参考文献
[1] Vondrick C, Pirsiavash H, Torralba A. Generating videos with scene dynamics[C]//Advances in neural information processing systems. 2016: 613-621.
2 GAN与视频预测
相比于直接生成视频,更加有用的一个场景是输入一帧图像,对接下来的帧进行预测,那它又会有何不同。
有三AI知识星球-网络结构1000变
MD-GAN
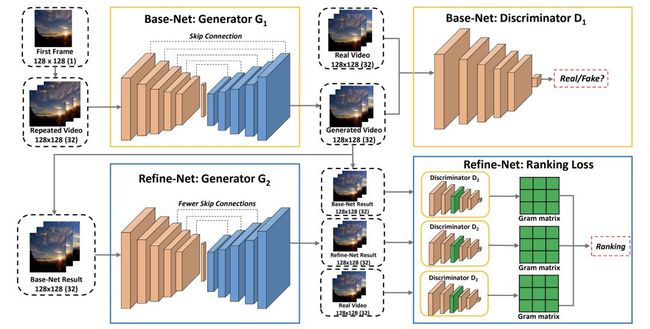
MD-GAN是一个使用生成对抗网络来生成time-lapse(延时)视频的网络,它通过2步来提升生成效果。
作者/编辑 言有三
上图是整个网络结构,整个框架分为两个阶段:
第一阶段(Base-Net):生成每一帧的内容,它要注重每一帧内容的真实性。
第二阶段(Refine-Net):重点优化帧与帧之间物体的运动,使得生成结果更加平滑。
首先我们来看Base-Net,它包含生成器G1和判别器D1:
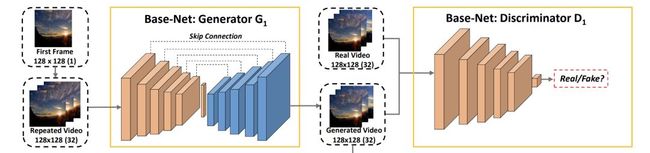
G1采用的是encoder-decoder这种结构,它包含了多个3D卷积层-反卷积层对,使用了跳层连接,这是一个典型的U-Net结构,实现对视频内容的建模,优化目标为逐像素的L1重建损失。
D1采用了G1中的编码器部分网络,最后一层用sigmoid激活函数替换ReLU。
然后我们来看Refine-Net,它包含生成器G2和判别器D2:
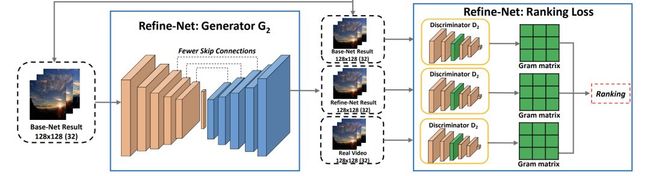
G2和G1很像,不过移除了部分跳层连接,因为作者发现有所有的过高抽象级别和过低抽象级别的连接对视频的动态性不能很好的建模。
D2包含了三个判别器,其中每一个和D1的结构一样,
它重点需要建模Gram matrix和ranking loss。
我们需要解析一下Gram矩阵,它是特征之间的协方差矩阵,非常适合对图像的纹理特征进行表征,在风格化领域中被广泛应用。
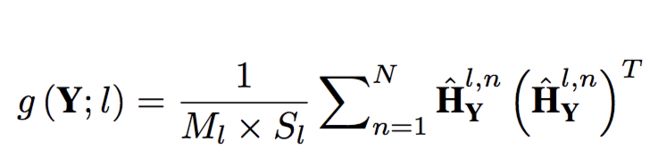
得到了Gram矩阵后,将其用于计算ranking loss。从Base-Net输出的视频为Y1 ,Refine-Net输出的视频为Y2,真实的视频为Y。ranking loss就是要约束Y2与真实视频的距离比Y1更小,定义如下,这是一个经典的contrastive loss。

当然为了约束细节,训练Refine-Net时也需要加上重建损失,与Base-Net相同,不再赘述。
下图展示了两个阶段的生成结果,其中红色圈出部分表示变化的部分,生成分辨率为128*128。

作者开源了实现,https://github.com/weixiong-ur/mdgan,读者可以自行复现。
参考文献
[1] Xiong W, Luo W, Ma L, et al. Learning to generate time-lapse videos using multi-stage dynamic generative adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2364-2373.
3 关于更多GAN的内容
GAN几乎在所有的视觉领域中都在大展宏图,如何系统性地学习GAN呢?请看下文的介绍。
【杂谈】如何系统性地学习生成对抗网络GAN
有三AI知识星球是我们的私密原创知识学习社区,目前的网络结构1000变板块正在更新GAN相关的内容,已经超过50期了,将近30多个研究领域,下面是一些内容预览。


完整的有三AI知识星球生态介绍可以参考我们的一周年总结,了解详细必看。



以上所有内容
加入有三AI知识星球即可获取
添加微信Longlongtogo加入
可享优惠
更多精彩
每日更新
不见不散

转载文章请后台联系
侵权必究


往期精选
【年终总结】2019年有三AI知识星球做了什么,明年又会做什么
【杂谈】有三AI知识星球一周年了!为什么公众号+星球才是完整的?
【杂谈】有三AI知识星球最近都GAN了哪些内容?
【知识星球】分组卷积最新进展,全自动学习的分组有哪些经典模型?
【知识星球】卷积核和感受野可动态分配的分组卷积
【知识星球】剪枝量化初完结,蒸馏学习又上线
【知识星球】有没有网络模型是动态变化的,每次用的时候都不一样?
【知识星球】视频分析/光流估计网络系列上线
【知识星球】几个人像分割数据集简介和下载
【知识星球】颜值,自拍,美学三大任务简介和数据集下载
【知识星球】Attention网络结构上新,聚焦才能赢
【知识星球】这几年人脸都有哪些有意思的数据集?
【知识星球】总有些骨骼轻奇,姿态妖娆的模型结构设计,不知道你知不知道,反正我知道一些match